







storm是流式处理框架
Storm有如下特点:
编程简单:开发人员只需要关注应用逻辑,而且跟Hadoop类似,Storm提供的编程原语也很简单
高性能,低延迟:可以应用于广告搜索引擎这种要求对广告主的操作进行实时响应的场景。
分布式:可以轻松应对数据量大,单机搞不定的场景
可扩展: 随着业务发展,数据量和计算量越来越大,系统可水平扩展
容错:单个节点挂了不影响应用
消息不丢失:保证消息处理
不过Storm不是一个完整的解决方案。使用Storm时你需要关注以下几点:
如果使用的是自己的消息队列,需要加入消息队列做数据的来源和产出的代码
需要考虑如何做故障处理:如何记录消息队列处理的进度,应对Storm重启,挂掉的场景
需要考虑如何做消息的回退:如果某些消息处理一直失败怎么办?
Storm的应用
跟Hadoop不一样,Storm是没有包括任何存储概念的计算系统。这就让Storm可以用在多种不同的场景下:非传统场景下数据动态到达或者数据存储在数据库这样的存储系统里(或数据是被实时操控其他设备的控制器(如交易系统)所消费)
Storm有很多应用:实时分析,在线机器学习(online machine learning),连续计算(continuous computation),分布式远程过程调用(RPC)、ETL等。Storm处理速度很快:每个节点每秒钟可以处理超过百万的数据组。它是可扩展(scalable),容错(fault-tolerant),保证你的数据会被处理,并且很容易搭建和操作。
简单介绍一下,个个组件:
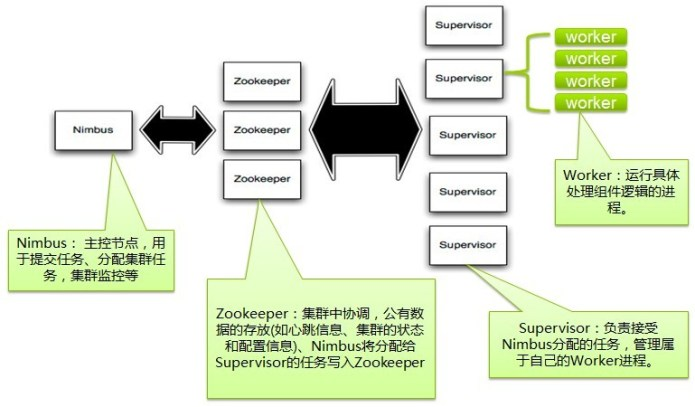
- Topology:一个实时应用的计算任务被打包作为Topology发布,这同Hadoop的MapReduce任务相似。
- Spout:Storm中的消息源,用于为Topology生产消息(数据),一般是从外部数据源(如Message
Queue、RDBMS、NoSQL、Realtime Log)不间断地读取数据并发送给Topology消息(tuple元组)。 - Bolt:Storm中的消息处理者,用于为Topology进行消息的处理,Bolt可以执行过滤,聚合,
查询数据库等操作,而且可以一级一级的进行处理。 - Stream:产生的数据(tuple元组)。
- Stream grouping:在Bolt任务中定义的Stream进行区分。
- Task:每个Spout或者Bolt在集群执行许多任务。
- Worker:Topology跨一个或多个Worker节点的进程执行。
storm 架构图:
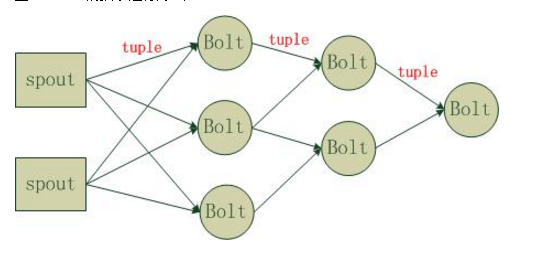
Strom在运行中可分为spout与bolt两个组件,其中,数据源从spout开始,数据以tuple的方式发送到bolt,多个bolt可以串连起来,一个bolt也可以接入多个spot/bolt.运行时原理如下图:
公司使用storm和kafka,下篇将进行整合。
参考:
https://blog.csdn.net/weiyongle1996/article/details/77142245














 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









