







20180816
20180829
转载参考:
https://www.nowcoder.com/courses/190
https://www.jikexueyuan.com/course/3651_2.html?ss=1
人工智能
In computer science, the field of AI research defines itself as the study of “intelligent agents”: any device that perceives its environment and take actions that maximize its chance of success at some goal.
Colloquially, the term “artificial intelligence” is applied when a machine mimics “cognitive” functions that humans associate with other human minds, such as “learning” and “problem solving”.
人工智能 > 机器学习 > 神经网络 > 深度学习
监督学习Supervised Learning:learn from labeled data(标签数据)
| 用途 |
|---|
| classification |
| regression |
| ranking |
感知器 Perceptron
- 受到来自神经元(neuron)启示
最简单(两层)的前馈神经网络(no hidden layer, a single output unit)
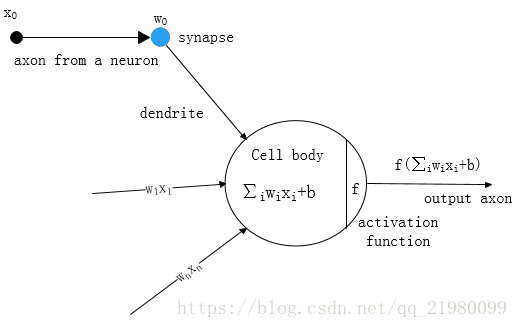
神经元
细胞核(nucleus)周围有很多树突(dendrites),dendrites负责接收信号,而后通过突触(synapse)进行信号放大或缩小,处理过的信号传递给nucleus,nucleus将进行一些处理,再通过一些非线性变换(nonlinear),再通过轴突(axon),再传递给后面的nucleus。
一个nucleu接收很多输入( x 0 x_0 x0 ~ x n x_n xn),synapes有个weight对信号进行变换,在nucleu内部进行线性加权: ∑ i w i x i + b \sum_{i} w_i x_i + b ∑iwixi+b ,再通过**f非线性变换(激活函数 activation function)**作为output, 传递给后面的nucleus。
分类器
Classification
通过使用一些描述物体的基本特征,来把物体归类的过程。
逻辑斯蒂回归 logistic regression / 支持向量机 SVM / 朴素贝叶斯 naive bayes / neural net
识别简单模式patterns:逻辑斯蒂回归 logistic regression 、支持向量机 SVM
neural net:用于一个物体可以归属为至少2个不同类别的分类任务。
分类器的激活输出,会得到一个分数(置信分): s o f t m a x ( y ) i = e x p ( y i ) ∑ j e x p ( y j ) softmax(y)_i = \frac{exp(y_i)}{\sum_j exp(y_j)} softmax(y)i=∑jexp(yj)exp(yi)
神经网络 Neural Net
神经网络的诞生是为了解决早期perceptron分类器的分类效果差(inaccuracy)的问题。
神经网络由网中相互连接的称为神经元节点和连接他们的边组成。
主要功能是接收一组输入,进行一些逐渐复杂的计算,然后使用输出来解决问题。
一个neural net可以看做把多个分类器一层一层连起来,hidden/output layers 的每个节点都有自己的分类器,分类结果由output层各个节点的分数决定。
多层感知机MLP
把perceptron建成多层网络,提升预测效果。
向前传播 Forward propagation:用于对输入数据分类
从输入层开始,每个激活都会被送到下一层,以及它们的下一层,直到到达最后的输出。
每一节点都有相同的分类器,没有一个会被随机激活。
每组输入都会被唯一的权重和偏差(unique weights and biases)修改 => hidden layer的每一mode对相同输入会得到不同的结果
每个激活组合唯一(每个边有唯一weight,每个node有唯一biases) => 不同节点会激活出不同的值
预测准确度(神经网络output与真实output尽量接近)依赖于weights & biases。
training:提高neural net’s accuracy.
每一层节点数随模式的复杂成指数增长 =》 整个训练过程很耗时,训练结果inaccuracy =》 对一个复杂的模式,简单的分类引擎engines和浅层的神经网络就不够有效。
deep net 能够把复杂的pattern分解成一系列小的简单pattern。首先检测简单模式,然后将其组合起来,来处理复杂的模式。
深度学习(Deep Learning)
An end-to-end learning approach that uses a highly complex(nonlinear, multi-layer) model to fit the training daata from scratch.
单到单的学习方式,多层组织结构,每层有非线性变换(activation function)存在。
浅层neural net需节点数多,导致参数复杂度高。deep neural net 在某种程度上降低模型复杂度,减少参数个数。
训练
代价 cost
为训练网络,Forward propagation得到的输出会和正确的输出进行比较,两个差值被定义成代价cost.
训练目的:使所有训练样本的代价综合越小越好 =》需要一步步修改weigths/biases,直到prediction尽量接近真实输出值。
训练集:用来求解神经网络的weight,最后形成模型。
测试集:用来验证模型的准确度。
输入(图像)确定的情况下,只有调整参数weight\bias(有默认的网络模型和参数)才能改变输出的值。
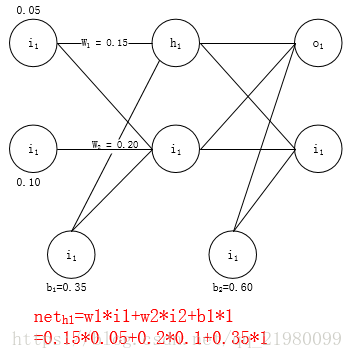
每个参数都有一个默认值,对每个参数加上一定数值Δ,目标是差距bias变小:如果参数调大,差距也变大 => 减小Δ;
为把参数调整到最佳,需要了解误差对每个参数的变化率(即求误差对于某参数的偏导数)。
deep learning 刚开始定义一个标准参数,然后不断修正,得出每个节点间的height。
隐藏层中激活函数(Sigmoid\Hyperbolic Tangent\Relu):让整个网络具有非线性特征
使用原因:
- 很多情况下,线性函数(linear function)没办法对输入进行适当的分类;
- 让每个节点的输出值在一个可控的范围内,方便计算(每个节点的输出在[0,1]内,而后再结果上再做一层一对一映射);
注:不一定每层都要加激活函数。
基本函数
| name | function | 备注 |
|---|---|---|
| Sigmoid | s ( x ) = 1 1 + e − x s(x) = \frac{1}{1+e^{-x}} s(x)=1+e−x1; s ′ ( x ) = s ( x ) ( 1 − s ( x ) ) s'(x) = s(x)(1-s(x)) s′(x)=s(x)(1−s(x)); { 输入值非常小﹣∞ , - > 0 输入值非常大∞ , - > 1 \begin{cases} \text{输入值非常小﹣∞}, & ->0 \\ \text{输入值非常大∞}, & ->1 \end{cases} {输入值非常小﹣∞,输入值非常大∞,->0->1 | 一个output,一个input,把输入的信号作整形变换(单调),输入信号变化到0~1之间 |
| Tanh | t a n h ( x ) = 2 σ ( 2 x ) − 1 = e x − e − x e x + e − x tanh(x) = 2\sigma(2x)-1 = \frac{e^x-e^{-x}}{e^x+e^{-x}} tanh(x)=2σ(2x)−1=ex+e−xex−e−x | (-1,1)之间,均值为0。 输入信号/绝对值很大/负得多/正得多时,激活函数输出值非常接近于两极端,而深度神经网络的训练靠共享传播算法,面临梯度消失问题(梯度=0) |
| Relu(Rectified Linear Units) | f ( x ) = m a x ( 0 , z ) = { 0 , z < 0 w T x + b , z ≥ 0 f(x) = max(0,z) = \begin{cases}0, & z<0 \\ w^T x+b, & z\geq0 \end{cases} f(x)=max(0,z)={0,wTx+b,z<0z≥0 | 正值部分,导数始终存在,可加速训练过程 |
others: Leaky ReLU(Parametric ReLU)、ELU等
训练结尾
- 输出单元与最后一个隐藏层也是线性变换 Linear output unites: y = w T h + b y = w^T h+b y=wTh+b
-
s
o
f
t
m
a
x
(
y
)
i
=
e
x
p
(
y
i
)
∑
j
e
x
p
(
y
j
)
softmax(y)_i = \frac{exp(y_i)}{\sum_j exp(y_j)}
softmax(y)i=∑jexp(yj)exp(yi)
将每个y值作指数变换,归一化,相加为1 => 概率分布
得到当前输入属于每个类的概率为多少,作为output。
学习系数
随着训练深入,系数可以改变。
SGD:随机梯度下降
mini batch
epoch:用于训练集的选择
训练模型:调参(权重weights\偏差biases)
遵守goldilocks原则
易出现问题:
欠拟合:低准确率的模型
训练不够,数据不足。
模型不能对重要的数据特征给到足够的权重。
Solution:
增加能够区分样本的更多数据特征。
过拟合:模型对新样本的泛化能力差
训练集效果好,但测试集不行。
当输入的特征数量太多,或者模型的结构过于复杂,每一层节点和隐含层的层次数比实际需要的多很多。
所有特征分析,得到对训练数据描述准确的一大堆主观规则,但对于新样本数据没有什么泛化能力。不能够识别出真正能够区别不同类别数据的规则。
通过网络结构的height\bias显示出来(训练过程中,neural net分配不同的bias给各个特征,决定了特征的重要程度以及它们结合的方式)。过拟合时,模型会给特征分配不需要的weight,造成得到过于复杂的模型。
Solution:
- 把数据分割成三份:一个训练数据集,一个测试数据集,和一个交叉验证集。
- 与参数平均一起使用,确保模型不过于依赖整个数据集的某个部分子集。
- 对于特定的neural net:
2.1. 正则化 Regularization:
模型的height\bias太大的话会受到惩罚。
2.2. Max Norm constraints:
对height\bias进行大小限制。
2.3. dropout:
随即关掉neural net中的某些特定的神经元(neuron),从而阻止模型过于依赖某一组neuron,以及它关联的height、bias。
(Data augmentation 增大数据量、Dropout/Dropconnect 随机扔节点/边、Batch normalization 批量归一化、weight decay / early stopping 未收敛即停止)
简单前馈神经网络
##三层结构
- 输入层 Input Layer
- 隐藏层 Hidden Layer
- 输出层 Output Layer
每相邻两层之间为全连接,且为线性变换,隐藏层中自带非线性变换(可以使用不同的activation function)。
全连接
上一层的一个节点会连接到下一层的每个节点,不相邻的层之间无连接。
Universal Approximately Theorem 通用近似定理
A feed-forward-network with a single hidden layer containing a finite number of neurons can approximate continuous functions on compact subsets of R n R^n Rn, under mild assumptions on the activation function.
如果一个前馈神经网络具有线性输出层和至少一层具有任何一种‘‘挤压’’ 性质的激活函数(例如logistic sigmoid激活函数)的隐藏层,只要给予网络足够数量的神经元,便可以实现以足够高精度来逼近任意一个在 R n R^n Rn的紧子集 (Compact subset) 上的连续函数。
万能近似定理意味着无论我们试图学习什么函数,我们知道一个大的MLP 一定能够表示这个函数。然而,我们不能保证训练算法能够学得这个函数。即使MLP能够表示该函数,学习也可能因两个不同的原因而失败。①用于训练的优化算法可能找不到用于期望函数的参数值。②训练算法可能由于过拟合而选择了错误的函数。
总之,具有单层的前馈网络足以表示任何函数,但是网络层可能大得不可实现,并且可能无法正确地学习和泛化。在很多情况下,使用更深的模型能够减少表示期望函数所需的单元的数量,并且可以减少泛化误差。
深度神经网络(Deep Neural Networks,DNN)训练
KaTeX parse error: \cr valid only within a tabular/array environment
参数初始化:限定在某一范围内(取决于每层节点数目),可能出现参数值溢出,损失函数不可计算。
SGD:每次随机采样一小批,计算损失函数loss function,对参数求导,更新模型。
Regularization:防止过拟合(针对测试数据处理)
大数据分析
目标:理解无结构的文本数据
自然语言处理NLP
- 词形还原Lemmatization
- 命名体识别Name Entity Recognition
- 语言词性标注 Part of Speech Tagging
- 句法分析 Syntactic Parsing
- 事实提取 Fact Extraction
- 情感分析 Sentiment Analysis
- 机器翻译 Machine Translation
都依赖于语言模型(计算在自然语言中出现某一个部分的概率)
Deep Learning
区别于NLP:使用向量。
one-hot Vector:词。
每个单词表示成了向量,向量的长度是整个词汇表的大小。对应于单词位置的值是1,向量中的所有其他值都是0。
降维
- continuous bag of words(CBOW)模型。
- skip grams:用隐含层的激活值作为目标单词的表示。
工具:
单词转换成向量Word2vec 、Glove
句法分析 text analytics
使用回归神经张量网络(Recursive Neural Tensor Networks,RNTN)
RNTN:一个RNTN包含一个根节点与它相连的两个叶节点。2个单词会作为输入分别传给两个叶子节点,叶子节点把单词传给根节点,根节点处理这些单词并产生一个中间解析以及一个分数,这个解析和句子中的下个单词会输入给叶子节点。在每一步递归过程中网络需要分析所有可能的子解析,而不是单单处理下一个单词。














 8421
8421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









