




 本文是关于使用Docker学习Redis的笔记,涵盖了Nosql概述、Redis的特点、五大数据类型等内容。通过Docker在Linux环境下安装Redis,讨论了Redis作为缓存的优势,如高性能和丰富的数据类型。此外,文章还探讨了Redis的单线程模型以及其如何通过内存操作实现高效性能。
本文是关于使用Docker学习Redis的笔记,涵盖了Nosql概述、Redis的特点、五大数据类型等内容。通过Docker在Linux环境下安装Redis,讨论了Redis作为缓存的优势,如高性能和丰富的数据类型。此外,文章还探讨了Redis的单线程模型以及其如何通过内存操作实现高效性能。
Redis
参考B站狂神说视频写的笔记,喜欢的可以去B站搜索狂神说
菜鸟成长之路,不喜勿喷,想交流的评论一起交流
Nosql概述
单机MySql
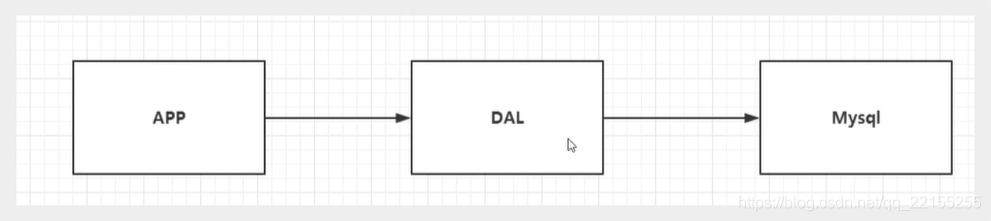
更多的使用静态的HTML~服务器根本没有压力,单机Mysql完全够用
这个情况下:网站的瓶颈:
1.数据量如果太大,一个机器放不下了!
2.数据的索引 单表数据超过300万就要建立索引
(B+Tree),一个机器内存也存不下了
3.访问量(读写混合),一个服务器承受不了
只要出现其中之一,网站就必须要升级了
缓存
Memcached(缓存)+MySQL+垂直拆分(读写分离)
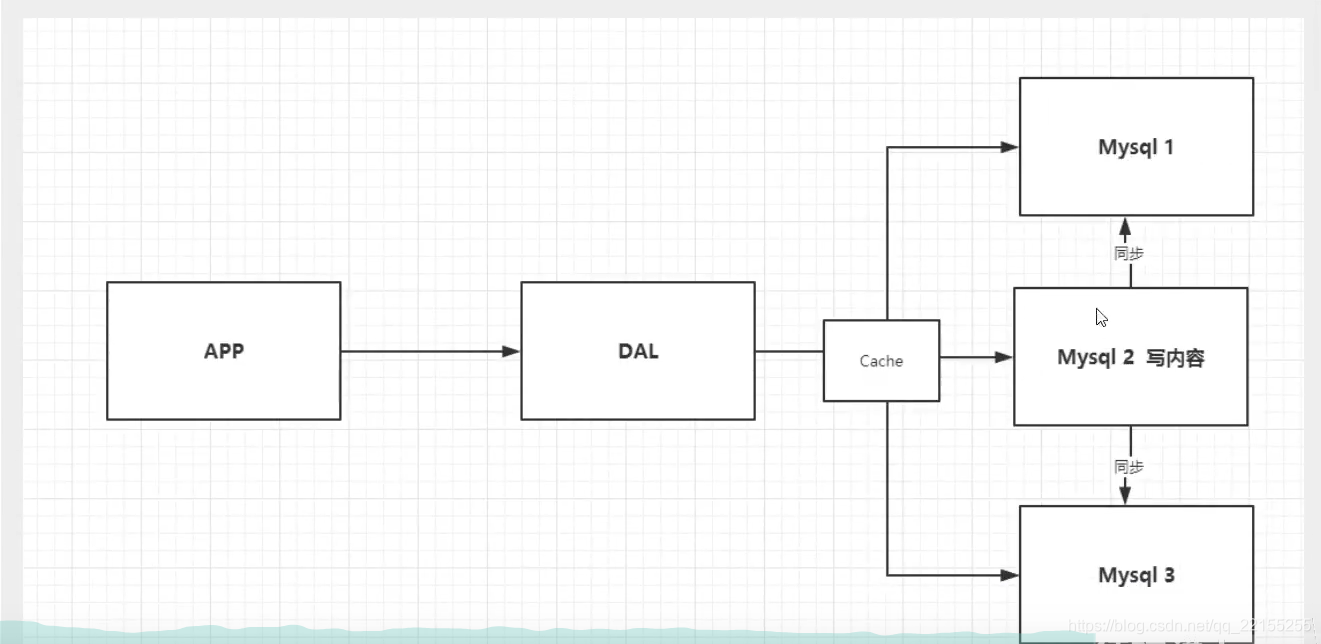
每次查询数据库会很麻烦,所以我们希望减轻数据压力
发展过程:优化数据结构和索引—>文件缓存(IO)---->Memcached
分库分表+水平拆分+MYSQL集群
每个集群存一部分数据
本质:数据库(读,写)
MyISAM:表锁(100万条数据 查一个数据锁一张表)
高并发下就会出现严重的问题
Innodb:行锁
慢慢就开始使用分库分表来解决写的压力!
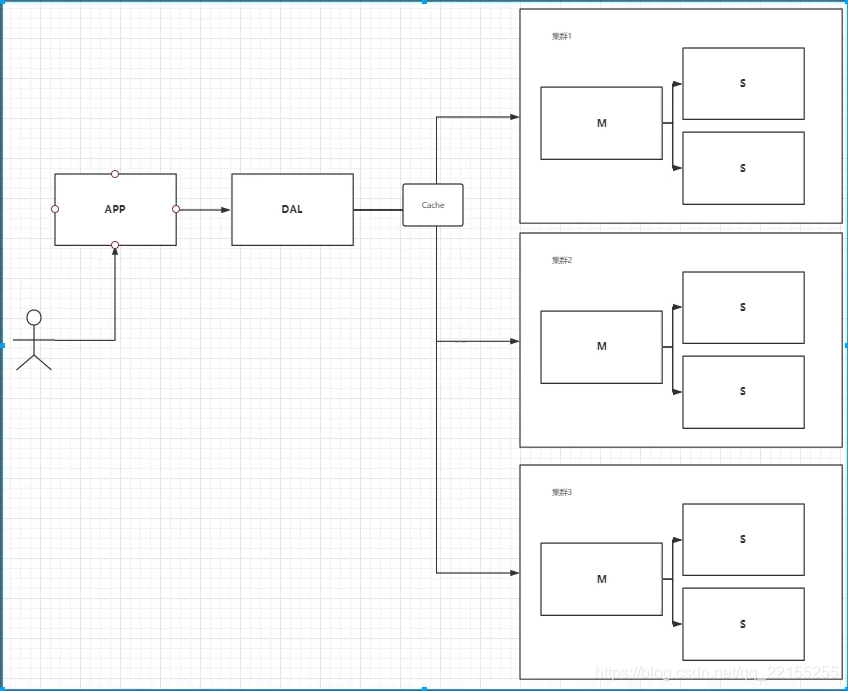
到如今
MYSQL关系型数据库就不够用了!数据量很多,变化很快
图形 JSON
MYSQL有的使用它来存储比较大的文件,博客,图片。。。数据库表很大,效率低
有一种数据库用来专门处理这种数据
MYSQL压力就变小了
大数据的IO压力 下 表几乎没办法更大
如今的服务器架构
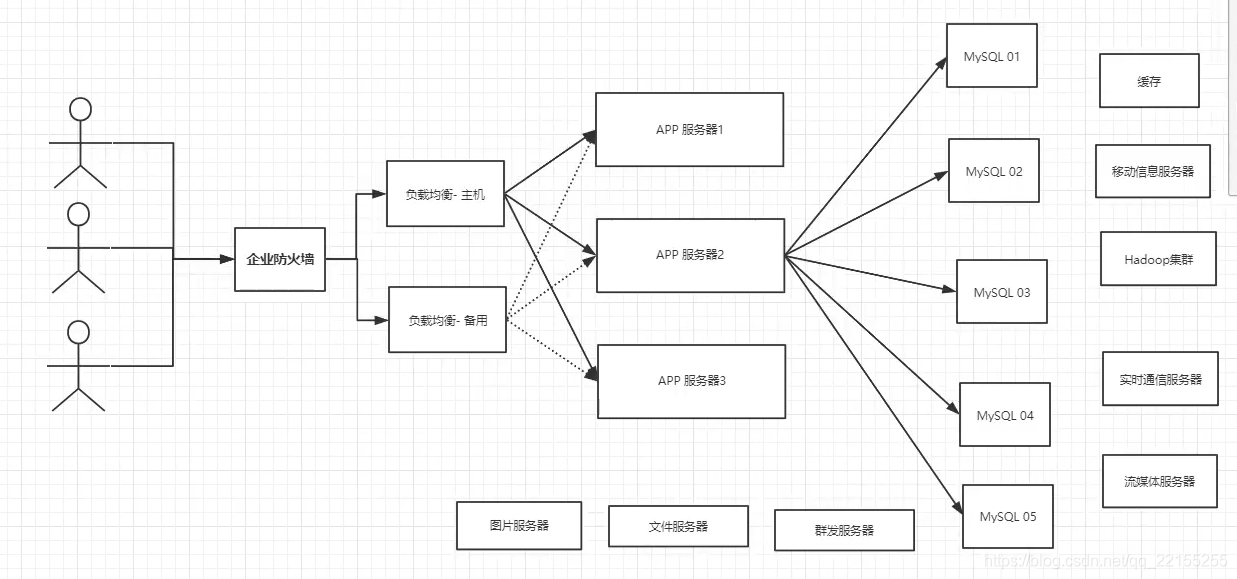
Nosql = Not Only SQL
泛指非关系型数据库,随着web2.0诞生,传统型的关系型数据库很难对付web2.0时代!尤其是超大规模的高并发场景
关系型数据库: 表格 行 列
NoSQL特点
1.方便扩展(数据之间没有关系,很好扩展)
2.大数据量高性能
Redis一秒可以写8万次,读取11万条数据
NoSQL的缓存记录集,是一种细粒度的缓存,性能比较高
3.数据类型多类型
不需要事先设计数据库!:随取随用
4.传统RDBMS和NOSQL区别
传统的RDBMS
-结构化组织
-SQL
-数据和关系都存在单独的表中
-操作 数据定义语言
-严格的一致性
-基础的事务操作
NoSQL
-不仅仅是数据
-没有固定的查询语言
-键值对存储,列存储,文档存储,图形数据库(社交关系)
-最终一致性
-CAP定理和BASE理论 (异地多活)
-高性能,高可用,高可扩
-。。。
大数据了解3V+3高

阿里巴巴演进分析
此处省略,有兴趣的可以去百度看看O
NoSql的四大分类
KV键值对
- 新浪:Redis
- 美团:Redis+Tair
- 阿里、百度:Redis+Memecache
文档型数据库bson格式(和json一样)
-
MongoDB
是一个基于分布式文件存储的数据库,C++编写,主要处理大量的文档
MongoDB是一个介于关系型数据库与非关系型数据库的中间产品,MongoDB是非关系型数据库中功能最丰富功能最像关系型数据库的!!
-
ConthDB
列存储数据库
- HBase(大数据)
- 分布式文件系统
图形关系数据库
- 存储关系的拓扑图,朋友圈社交网络之间的关系,广告推荐。。。。
- Neo4j,InfoGrid
Redis入门
概述
Redis是什么
远程字典服务,支持网络,C语言编写,KV数据库
Redis能做什么
1.内存存储、持久化(内存是断电即失rdb、aof)
2.效率高,可用于高速缓存
3.发布订阅系统
4.地图信息分析
5.计时器、计数器(浏览量!)
6……
特性
1.多样的数据类型
2.持久化
3.集群
4.支持事务
……
Linux安装redis
1.下载安装包
2.解压Redis的安装包
[root@bogon opt]# tar -zxvf redis-6.0.9.tar.gz

3.进入Redis
[root@bogon opt]# cd redis-6.0.9/

4.基本的环境安装
[root@bogon redis-6.0.9]# yum install gcc-c++
make
我以前已经安装过了,这里就省略了
镜像安装
教程网络很多跟着做就行
docker start redis#这个地方名字些什么我们启动的时候些什么
连接客户端语句
docker exec -it myredis redis-cli
关闭myredis服务
docker stop redis
查看当前涉及到redis的进程
[root@bogon docker]# ps -ef|grep redis
工具使用
redis-benchmark压力测试工具
| 序号 | 选项 | 描述 | 默认值 |
|---|---|---|---|
| 1 | -h | 指定服务器主机名 | 127.0.0.1 |
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 50 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -P | 通过管道传输 请求 | 1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | –csv | 以 CSV 格式输出 | |
| 12 | -l | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表。 | |
| 14 | -I | Idle 模式。仅打开 N 个 idle 连接并等待。 |
我们简单测试一下
#测试是否连接正常
[root@bogon docker]# docker exec -it myredis redis-cli
127.0.0.1:6379> ping
PONG
#测试100个并发连接 100000请求
docker exec -it myredis redis-benchmark -h localhost -p 6379 -c 100 -n 100000
分析
====== SET ======
100000 requests completed in 3.56 seconds #10万个请求3.56s
100 parallel clients #100个并发客户端
3 bytes payload #每次写入3个字节
keep alive: 1 #只有一台服务器来处理这些请求,单机性能
host configuration "save":
host configuration "appendonly": yes
multi-thread: no
6.49% <= 1 milliseconds #第一毫秒处理了
44.88% <= 2 milliseconds
80.50% <= 3 milliseconds
93.31% <= 4 milliseconds
98.07% <= 5 milliseconds
99.48% <= 6 milliseconds
99.73% <= 7 milliseconds
99.80% <= 8 milliseconds
99.85% <= 9 milliseconds
99.88% <= 10 milliseconds
99.90% <= 11 milliseconds
99.90% <= 12 milliseconds
99.92% <= 15 milliseconds
99.92% <= 16 milliseconds
99.94% <= 17 milliseconds
99.98% <= 18 milliseconds
100.00% <= 18 milliseconds
28074.12 requests per second #每秒处理多少请求
基础的知识
redis默认的有16个数据库
默认使用的是第0个数据库
可以使用select切换数据库
127.0.0.1:6379> select 3 #切换数据库
OK
127.0.0.1:6379[3]> DBSIZE #查看数据库大小
(integer) 0
127.0.0.1:6379[3]> set name wangqinghua
OK
127.0.0.1:6379[3]> DBSIZE #只针对于3号数据库,其他数据库没有
(integer) 1
查看当前数据库所有的key
127.0.0.1:6379[3]> keys *
1) "name"
127.0.0.1:6379[3]> get name
"wangqinghua"
清除当前的数据库
127.0.0.1:6379[3]> flushdb
OK
127.0.0.1:6379[3]> keys *
(empty array)
清除全部数据库的内容
127.0.0.1:6379> select 3
OK
127.0.0.1:6379[3]> 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











