







自动装箱和拆箱从Java 1.5开始引入,目的是将原始类型值转自动地转换成对应的对象。自动装箱与拆箱的机制可以让我们在Java的变量赋值或者是方法调用等情况下使用原始类型或者对象类型更加简单直接。
如果你在Java1.5下进行过编程的话,你一定不会陌生这一点,你不能直接地向集合(Collections)中放入原始类型值,因为集合只接收对象。通常这种情况下你的做法是,将这些原始类型的值转换成对象,然后将这些转换的对象放入集合中。使用Integer,Double,Boolean等这些类我们可以将原始类型值转换成对应的对象,但是从某些程度可能使得代码不是那么简洁精炼。为了让代码简练,Java 1.5引入了具有在原始类型和对象类型自动转换的装箱和拆箱机制。但是自动装箱和拆箱并非完美,在使用时需要有一些注意事项,如果没有搞明白自动装箱和拆箱,可能会引起难以察觉的bug。
本文将介绍,什么是自动装箱和拆箱,自动装箱和拆箱发生在什么时候,以及要注意的事项。
什么是自动装箱和拆箱
自动装箱就是Java自动将原始类型值转换成对应的对象,比如将int的变量转换成Integer对象,这个过程叫做装箱,反之将Integer对象转换成int类型值,这个过程叫做拆箱。因为这里的装箱和拆箱是自动进行的非人为转换,所以就称作为自动装箱和拆箱。原始类型byte,short,char,int,long,float,double和boolean对应的封装类为Byte,Short,Character,Integer,Long,Float,Double,Boolean。
自动装箱拆箱要点
- 自动装箱时编译器调用valueOf将原始类型值转换成对象,同时自动拆箱时,编译器通过调用类似intValue(),doubleValue()这类的方法将对象转换成原始类型值。
- 自动装箱是将boolean值转换成Boolean对象,byte值转换成Byte对象,char转换成Character对象,float值转换成Float对象,int转换成Integer,long转换成Long,short转换成Short,自动拆箱则是相反的操作。
何时发生自动装箱和拆箱
自动装箱和拆箱在Java中很常见,比如我们有一个方法,接受一个对象类型的参数,如果我们传递一个原始类型值,那么Java会自动讲这个原始类型值转换成与之对应的对象。最经典的一个场景就是当我们向ArrayList这样的容器中增加原始类型数据时或者是创建一个参数化的类,比如下面的ThreadLocal。
|
1
2
3
4
5
6
7
8
9
|
ArrayList<Integer> intList =
new
ArrayList<Integer>();
intList.add(
1
);
//autoboxing - primitive to object
intList.add(
2
);
//autoboxing
ThreadLocal<Integer> intLocal =
new
ThreadLocal<Integer>();
intLocal.set(
4
);
//autoboxing
int
number = intList.get(
0
);
// unboxing
int
local = intLocal.get();
// unboxing in Java
|
举例说明
上面的部分我们介绍了自动装箱和拆箱以及它们何时发生,我们知道了自动装箱主要发生在两种情况,一种是赋值时,另一种是在方法调用的时候。为了更好地理解这两种情况,我们举例进行说明。
赋值时
这是最常见的一种情况,在Java 1.5以前我们需要手动地进行转换才行,而现在所有的转换都是由编译器来完成。
|
1
2
3
4
5
6
7
|
//before autoboxing
Integer iObject = Integer.valueOf(
3
);
Int iPrimitive = iObject.intValue()
//after java5
Integer iObject =
3
;
//autobxing - primitive to wrapper conversion
int
iPrimitive = iObject;
//unboxing - object to primitive conversion
|
方法调用时
这是另一个常用的情况,当我们在方法调用时,我们可以传入原始数据值或者对象,同样编译器会帮我们进行转换。
|
1
2
3
4
5
6
7
8
|
public
static
Integer show(Integer iParam){
System.out.println(
"autoboxing example - method invocation i: "
+ iParam);
return
iParam;
}
//autoboxing and unboxing in method invocation
show(
3
);
//autoboxing
int
result = show(
3
);
//unboxing because return type of method is Integer
|
show方法接受Integer对象作为参数,当调用show(3)时,会将int值转换成对应的Integer对象,这就是所谓的自动装箱,show方法返回Integer对象,而int result = show(3);中result为int类型,所以这时候发生自动拆箱操作,将show方法的返回的Integer对象转换成int值。
自动装箱的弊端
自动装箱有一个问题,那就是在一个循环中进行自动装箱操作的情况,如下面的例子就会创建多余的对象,影响程序的性能。
|
1
2
3
4
|
Integer sum =
0
;
for
(
int
i=
1000
; i<
5000
; i++){
sum+=i;
}
|
上面的代码sum+=i可以看成sum = sum + i,但是+这个操作符不适用于Integer对象,首先sum进行自动拆箱操作,进行数值相加操作,最后发生自动装箱操作转换成Integer对象。其内部变化如下
|
1
2
|
sum = sum.intValue() + i;
Integer sum =
new
Integer(result);
|
由于我们这里声明的sum为Integer类型,在上面的循环中会创建将近4000个无用的Integer对象,在这样庞大的循环中,会降低程序的性能并且加重了垃圾回收的工作量。因此在我们编程时,需要注意到这一点,正确地声明变量类型,避免因为自动装箱引起的性能问题。
重载与自动装箱
当重载遇上自动装箱时,情况会比较有些复杂,可能会让人产生有些困惑。在1.5之前,value(int)和value(Integer)是完全不相同的方法,开发者不会因为传入是int还是Integer调用哪个方法困惑,但是由于自动装箱和拆箱的引入,处理重载方法时稍微有点复杂。一个典型的例子就是ArrayList的remove方法,它有remove(index)和remove(Object)两种重载,我们可能会有一点小小的困惑,其实这种困惑是可以验证并解开的,通过下面的例子我们可以看到,当出现这种情况时,不会发生自动装箱操作。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public
void
test(
int
num){
System.out.println(
"method with primitive argument"
);
}
public
void
test(Integer num){
System.out.println(
"method with wrapper argument"
);
}
//calling overloaded method
AutoboxingTest autoTest =
new
AutoboxingTest();
int
value =
3
;
autoTest.test(value);
//no autoboxing
Integer iValue = value;
autoTest.test(iValue);
//no autoboxing
Output:
method with primitive argument
method with wrapper argument
|
要注意的事项
自动装箱和拆箱可以使代码变得简洁,但是其也存在一些问题和极端情况下的问题,以下几点需要我们加强注意。
对象相等比较
这是一个比较容易出错的地方,”==“可以用于原始值进行比较,也可以用于对象进行比较,当用于对象与对象之间比较时,比较的不是对象代表的值,而是检查两个对象是否是同一对象,这个比较过程中没有自动装箱发生。进行对象值比较不应该使用”==“,而应该使用对象对应的equals方法。看一个能说明问题的例子。
原始值与对象进行比较时,对象发生自动拆箱,比较原始值。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
public
class
AutoboxingTest {
public
static
void
main(String args[]) {
// Example 1: == comparison pure primitive – no autoboxing
int
i1 =
1
;
int
i2 =
1
;
System.out.println(
"i1==i2 : "
+ (i1 == i2));
// true
// Example 2: equality operator mixing object and primitive
Integer num1 =
1
;
// autoboxing
int
num2 =
1
;
System.out.println(
"num1 == num2 : "
+ (num1 == num2));
// true
// Example 3: special case - arises due to autoboxing in Java
Integer obj1 =
1
;
// autoboxing will call Integer.valueOf()
Integer obj2 =
1
;
// same call to Integer.valueOf() will return same
// cached Object
System.out.println(
"obj1 == obj2 : "
+ (obj1 == obj2));
// true
// Example 4: equality operator - pure object comparison
Integer one =
new
Integer(
1
);
// no autoboxing
Integer anotherOne =
new
Integer(
1
);
System.out.println(
"one == anotherOne : "
+ (one == anotherOne));
// false
}
}
Output:
i1==i2 :
true
num1 == num2 :
true
obj1 == obj2 :
true
one == anotherOne :
false
|
值得注意的是第三个小例子,这是一种极端情况。obj1和obj2的初始化都发生了自动装箱操作。但是处于节省内存的考虑,JVM会缓存-128到127的Integer对象。因为obj1和obj2实际上是同一个对象。所以使用”==“比较返回true。
容易混乱的对象和原始数据值
另一个需要避免的问题就是混乱使用对象和原始数据值,一个具体的例子就是当我们在一个原始数据值与一个对象进行比较时,如果这个对象没有进行初始化或者为Null,在自动拆箱过程中obj.xxxValue,会抛出NullPointerException,如下面的代码
|
1
2
3
4
5
6
|
private
static
Integer count;
//NullPointerException on unboxing
if
( count <=
0
){
System.out.println(
"Count is not started yet"
);
}
|
缓存的对象
这个问题就是我们上面提到的极端情况,在Java中,会对-128到127的Integer对象进行缓存,当创建新的Integer对象时,如果符合这个这个范围,并且已有存在的相同值的对象,则返回这个对象,否则创建新的Integer对象。
在Java中另一个节省内存的例子就是字符串常量池,感兴趣的同学可以了解一下。
生成无用对象增加GC压力
因为自动装箱会隐式地创建对象,像前面提到的那样,如果在一个循环体中,会创建无用的中间对象,这样会增加GC压力,拉低程序的性能。所以在写循环时一定要注意代码,避免引入不必要的自动装箱操作。
如想了解垃圾回收和内存优化,可以查看本文Google IO:Android内存管理主题演讲记录
总的来说,自动装箱和拆箱着实为开发者带来了很大的方便,但是在使用时也是需要格外留意,避免引起出现文章提到的问题。
转自:http://blog.csdn.net/cflys/article/details/75143809
Java的==和equals()以及自动装箱拆箱
抛一个问题
大家先看下面的代码,先不要看答案自己做一下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
然后和正确答案对比一下:
如果全部正确证明你这块知识掌握的很牢固,没有必要在看下去了,如果你发现自己有做错的地方法,那么耐心的看下去吧。
先说一说 == 和 equals()方法
==
- 对于基本类型,不包含基本类型的包装类型,比较的是基本类型的值。
- 对于对象来说,== 比较的是两个对象在内存中的地址。
equals()方法
equals()是Object对象中的方法:
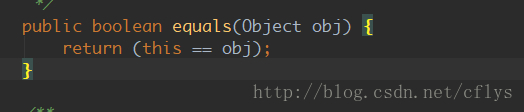
这是在Object对象中的实现,因为所有的类都继承于Object类,一般都会重写这个方法,实现不同,比较的方式就不同,这个方法主要就是实现对象在逻辑上的相等,而这个逻辑是由你决定的。
下面是Integer类中的equals()方法:
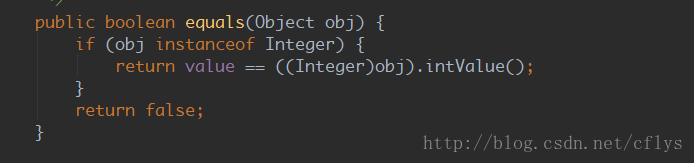
这里首先判断比较的对象是否是Integer,如果是则强制转换成Integer,然后比较它们的值,如果类型不同直接返回false。
再说一下Integer的缓存机制
从Java1.5 开始,Integer类型是有缓存对象的:
缓存对象IntegerCache是Integer中的一个静态内部类,缓存的范围是-128~127。
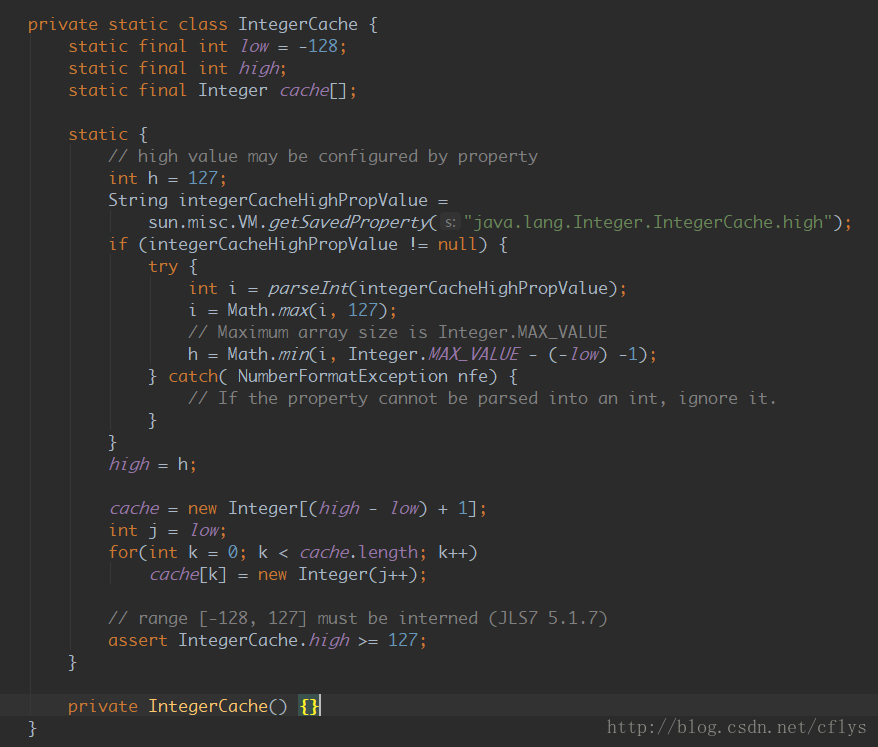
经过我对源码的探究,发现并不是只用Integer有缓存机制,所有整数类型的类都有类似的缓存机制。
| Class | CachaClass | Range |
|---|---|---|
| Character | CharacterCache | 0~127 |
| Byte | ByteCache | -128~127 |
| Short | ShortCache | -128~127 |
| LongCache | LongCache | -128~127 |
| Integer | IntegerCache | -128~127 |
除了 Integer 可以通过参数改变范围外,其它的都不行。
通过CharacterCache和IntegerCache的初始化源码可以说明这个问题。

自动装箱和自动拆箱
自动装箱
当你用基本类型的值给它的包装类赋值时,系统会自动将基本类型转换成它的包装类型。
例如:Integer i = 1,这时候系统就将1赋值给Integer类型的i。使用的时Integer的valueOf()方法。

首先会判断值是否在low和high之前,也就是说是否已经存在一个缓存对象的值和当前的值相同,如果存在直接返回该对象,否则重新new一个对象。
自动拆箱
和自动装箱相反,当你需要基本类型的时候,系统也会自动的将包装类转换成基本类型。
例如:
- 1
- 2
这个时候系统调用的是Integer的intValue()方法:
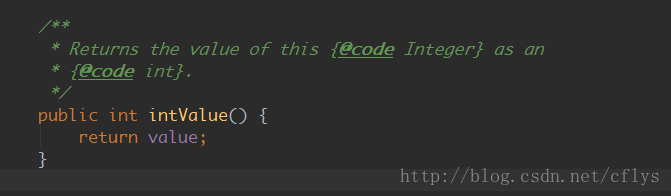
就是直接返回值。
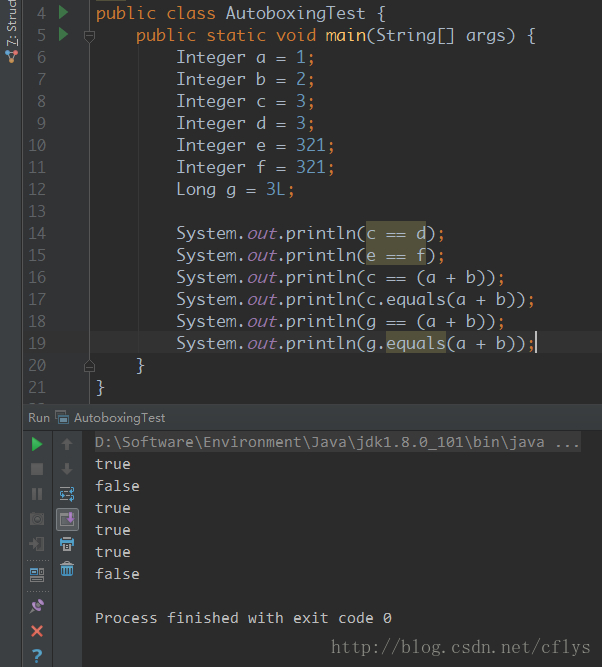
再来看之前那个问题就很简单了
-
c==d 是true。c和d都是缓存对象3,就是同一个对象,所以相等。
-
e==f 是false。e和f都超出缓存对象的范围,都是new的新的对象,是不同的对象所以在内存中的地址肯定不同,所以是false。
-
c == (a + b) ,这个就要注意了,在含有算术运算的时候,会进行自动拆箱的操作,也就是说这里比较的是c的值和a+b的值的关系。
开始的时候我以为a+b的值是3,然后这个3是缓存对象,所以相等,但是我在Debug跟进的时候,发现调用了3次Integer.intValue(),然后去查了查,发现在算术运算的时候,会进行自动拆箱的操作。
-
c.equals(a + b) 这个就是调用Integer的equals()方法,先对a和b进行了自动拆箱的操作,然后将他们的和进行自动装箱操作,然后调用equals()方法比较,因为Integer的equals()方法已经重写过了,上面已经介绍过了,比较的是两个对象的值,所以返回true。
-
g == (a + b) 这个首先会像第4个一样,首先会对g进行自动拆箱,然后对a和b进行自动拆箱的操作,之后进行它们值的比较,这时候还会发生隐式类型转换,int → long。因为值一样,所以返回true。
-
g.equals(a + b) 这个调用Long的equals()方法,而a+b的类型是Integer,所以会返回false。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









