







欢迎访问我的个人博客:guqing’s blog
Lucene7.7.1&Solr7.7.1学习笔记
1.Lucene起步
1.1 lucene介绍
Lucene是一个全文检索引擎工具包,最初是apache软件基金会jakarta项目组的一个子项目,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,以及部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能例如站内搜索,或者是以此为基础建立起完整的全文检索引擎。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
1.2 Lucen的功能
可扩展的高性能索引
- 在现代硬件上超过150GB /小时
- 小RAM要求 - 只有1MB堆
- 增量索引与批量索引一样快
- 索引大小约为索引文本大小的20-30%
强大,准确,高效的搜索算法
- 排名搜索 - 首先返回最佳结果
- 许多强大的查询类型:短语查询,通配符查询,邻近查询,范围查询等
- 现场搜索(例如标题,作者,内容)
- 按任何领域排序
- 使用合并结果进行多索引搜索
- 允许同时更新和搜索
- 灵活的分面,突出显示,连接和结果分组
- 快速,记忆效率高和错误容忍的建议
- 可插拔排名模型,包括矢量空间模型和Okapi BM25
- 可配置存储引擎(编解码器)
跨平台解决方案
- 可作为Apache许可下的开源软件 使用,它允许您在商业和开源程序中使用Lucene
- 100%-pure Java
- 可用的其他编程语言中的实现是索引兼容的
Lucene文档地址:
http://lucene.apache.org/core/7_7_1/index.html
1.2 lucene全文检索的应用场景
对于数据量大,数据结果不固定的数据可采用全文检索方式搜索,比如百度、google等搜索引擎,电商网站站内搜索,论坛站内搜索等。
1.3 Lucen实现全文索引的流程
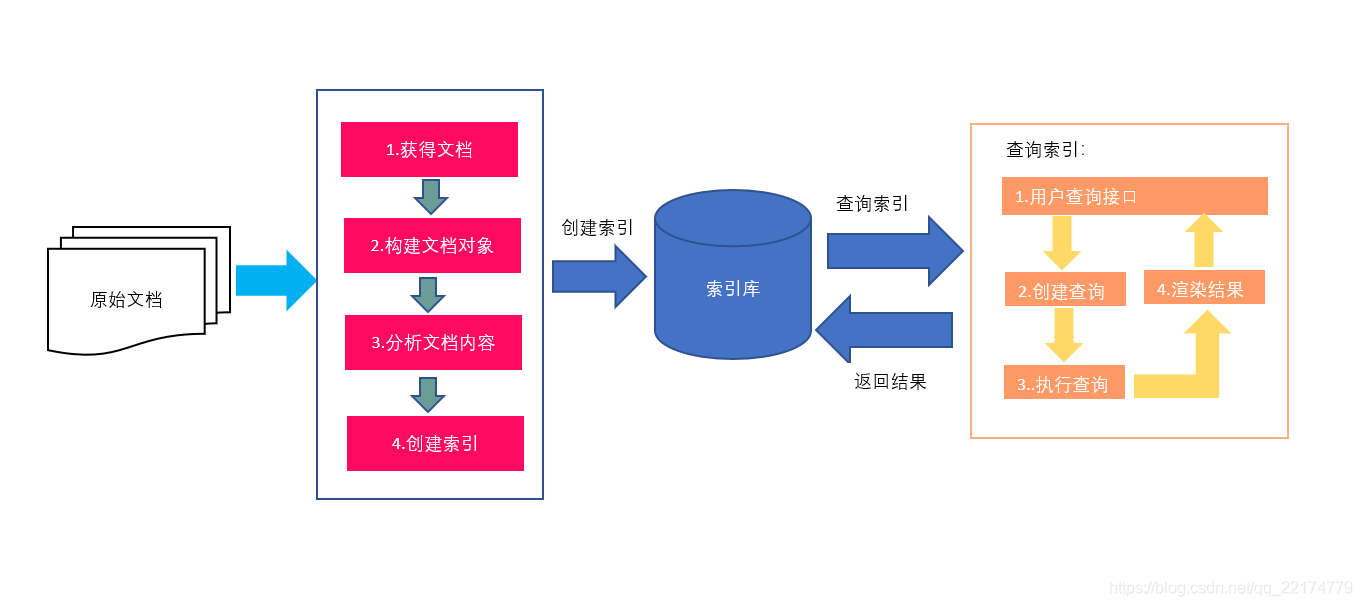
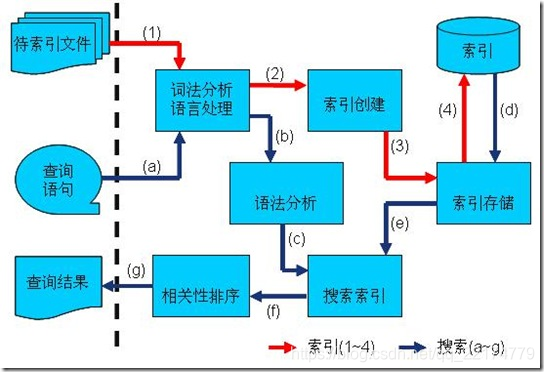
1.红色表示所有过程,对要搜索的原始内容进行索引,构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容 --> 采集文档 --> 创建文档 --> 分析文档 --> 索引文档
2.橙色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面 --> 创建查询 --> 执行搜索,从索引库查询 --> 渲染搜索结果
1.4 创建索引
1.4.1 获得原始文档
原始文档是指要索引和搜索的内容,原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等
本例中的原始内容就是磁盘上的文件,如下图所示:
- 从互联网上、数据库、文件系统中等获取需要搜素的原始信息,这个过程就是信息采集,信息采集的目的是为了对原始内容进行索引。
- 在Internet上采集信息的软件通常称为爬虫或蜘蛛,称为网络机器人,爬虫访问互联网上的每一个网页,将获取到的网页内容存储起来。
- Lucene 不提供信息采集的类库,需要自己编写一个爬虫程序实现信息采集,也可以通
过一些开源软件实现信息采集,如下: - Nutch(http:/lucene.apache.org/nutch),Nutch是apache的一个子项目,包括大规模爬虫工具,能够抓取和分辨web网站数据。
- jsoup(http://jsoup.org/),jsoup是一款Java的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的APl,可通过DOM,CSS以及类似于iQuery的操作方法来取出和操作数据。
- heritrix(http:/sourceforge.net/proiects/archive-crawler/files/),Heritrix 是一个由 java开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良
好的可扩展性,方便用户实现自己的抓取逻辑。 - 本案例我们要获取磁盘上文件的内容,可以通过文件流来读取文本文件的内容,对于
pdf、doc、xls等文件可通过第三方提供的解析工具读取文件内容,比如Apache POl 读取doc和xs的文件内容。
1.5创建文档对象
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。
这里我们可以将磁盘上的一个文件当成一个 document,Document 中包括一些Field
(filename 文件名称、fle_path 文件路径、flesize文件大小、file_content文件内容),如下图:
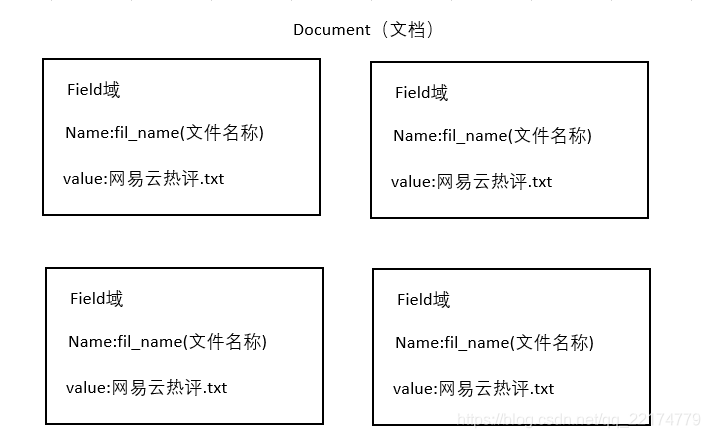
在Lucene中的域就相当于数据库中的字段,可以有多个域,且域名称可以相同,一个域由域名称,域值组成类似域K,V键值对。每一个文档都有一个唯一的编号就是文档的id,与数据库的id类似,但是无法手动指定,是Lucene自增的。
1.6 分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词。
比如下边的文档经过分析如下:
原文档内容:
Lucene is a Java full-text search engine.Lucene is not a complete application,but rather a code library and API that can easily be used to add search capabilities to applications.…
分析后得到的语汇单元为:
lucene、java、full、search、engine....
每个单词叫做一个Term,不同的域中拆分出来的相同的单词被当作是不同的term。tem中包含两部分一部分是文档的域名,另一部分是单词的内容。例如:文件名中包含apache和文件内容中包含的apache是不同的 term。
1.7 创建索引
对所有文档分析得出的语汇单元进行素引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。
假设有文档A和文档B,文档A经过分词后包含spring,文档B经过分词后也包含spring,那么索引词spring会有一个count来计数,为了在搜索这个索引时能将count个文档返回,创建索引时就会多一个域来存储分词后对应的文档id。
注意:创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。传统方法是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大、搜索慢。
倒排索引结构是根据内容(词语)找文档,如下图:
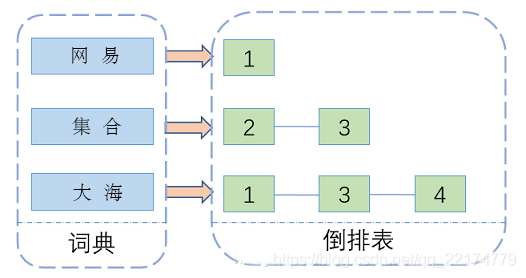
倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
1.8查询索引
全文检索系统提供用户搜索的界面供用户提交搜索的关键字,搜索完成展示搜索结果。
1.9 创建查询
用户输入查询关键字执行搜索之前需要先构建一个查询对象,查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法,例如:语法fileName:lucene表示要搜索Field域的内容为lucene的文档。
1.10 执行查询
搜索索引过程:
根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档链表。
1.11 渲染结果
Lucene 不提供制作用户搜索界面的功能,需要根据自的需求开发搜索界面。
2. 配置开发环境
2.1 Lucene下载
http://lucene.apache.org
版本:7.7.1
IDE:eclipse
2.2 创建工程
新建名为lucene的项目
导入jar包:
必须jar包:
commons-io-2.6.jar
lucene-analyzers-common-7.7.1.jar
lucene-core-7.7.1.jar
lucene-memory-7.7.1.jar
可选jar包:
IK分词器
IK-Analyzer-7.2.1.jar
关键词高亮插件包:
lucene-highlighter-7.7.1.jar
lucene-queries-7.7.1.jar
lucene-queryparser-7.7.1.jar
lucene-join-7.7.1.jar
创建LuceneStarting类并写创建索引方法:
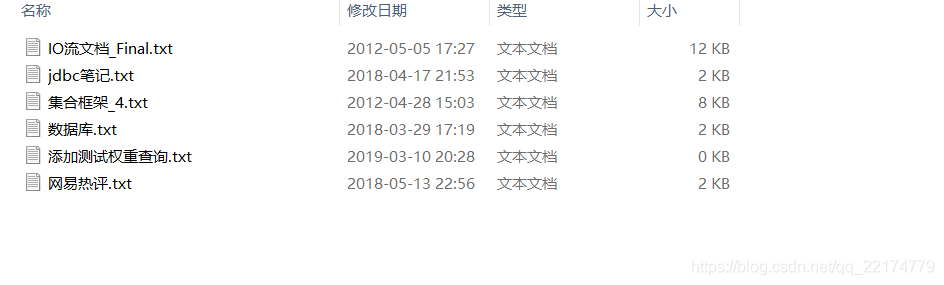
设置索引存放位置为:F:/testData/luceneIndex
测试文件存放位置为:F:/testData/lucenetestdata,可以自己弄几个文档测试一下。
2.3 实现步骤
第一步:创建一个java工程,并导入jar包。第二步:创建一个indexwriter对象。
1)指定索引库的存放位置Directory对象
2)指定一个分析器,对文档内容进行分析。
第三步:创建 document对象。
第三步:创建eld 对象,将field添加到document对象中。
第四步:使用indexwriter 对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库。
第五步:关闭Indexwriter对象。
Field域的属性:
是否分析:是否对域的内容进行分词处理。前提是我们要对域的内容进行查询。
是否索引:将Field分析后的词或整个Field值进行索引,只有索引方可搜索到。比如:商品名称、商品简介分析后进行索引,订单号、身份证号不用分析但也要索引,这些将来都要作为查询条件。
是否存储:将Field值存储在文档中,存储在文档中的Field 才可以从Document中获取。
比如:商品名称、订单号,凡是将来要从Document 中获取的Field 都要存储。
/**
* @ClassName: LuceneStarting
* @Description: lucen入门
* 创建索引
* 查询索引
* @author: guqing
* @date: 2019年3月10日 下午2:14:53
*
*/
public class LuceneStarting {
/**
* @throws IOException
* @Description: 测试创建索引
* @param:
* @return: void
* @throws
*/
@Test
public void testCreateIndex() throws IOException{
//第一步:创建一个java工程,并导入jar包
//第二步:创建一个indexwriter对象
// (1)指定索引库存放位置Directory对象
// (2)指定一个分析器,对文档内容进行分析
//File indexrepository_file = new File("F:/testData/luceneIndex");
//Path path = indexrepository_file.toPath();
//Directory directory = FSDirectory.open(path);//使用path
//索引建立在内存中
//Directory directory01=new RAMDirectory();
//设置索引存放位置
Path path = FileSystems.getDefault().getPath("F:/testData/luceneIndex");
Directory directory = FSDirectory.open(path);
//Analyzer analyzer = new StandardAnalyzer();
Analyzer analyzer = new IKAnalyzer();
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
IndexWriter inedxWriter = new IndexWriter(directory, indexWriterConfig);
/*
* 第三步:创建document对象
* Field域的属性:
* 是否分析:是否对域的内容进行分词处理,前提是我们要对域的内容进行查询
* 是否索引:将Field分析后的词或整个Field值进行索引,只有索引方可以搜索到
* 比如商品名称商品简介分析后进行索引
* 是否存储:将Field值存储到文档中,存储到Field才可以从document中获取,
* 是否存储的标准是否要展示给用户看
* --------------------------------------------------------------------------
* Field类 数据类型 是否分析 是否索引 是否存储
* StringField 字符串 N Y Y/N
* LongField Long型 Y Y Y/N
* StoredField 支持多种类型 N N Y
* TextField 字符串或流 Y Y Y/N
* LongField现已废弃由LongPoint取代,所有数值类型都是Point
*/
File file = new File("F:/testData/lucenetestdata");
File[] listFiles = file.listFiles();
for(File listFile : listFiles){
Document document = new Document();
//文件名称
String fileName = listFile.getName();
//创建域用于存储,域名 域值 是否存储
Field fileNameField = new TextField("fileName", fileName, Store.YES);
//文件大小
long fileSize = FileUtils.sizeOf(listFile);
Field fileSizeField = new LongPoint("fileSize", fileSize);//new StoredField("fileSize", fileSize);
//文件路径
String filePath = listFile.getAbsolutePath();
Field filePathField = new StoredField("filePath", filePath);
//文件内容
String fileContent = FileUtils.readFileToString(listFile, "GBK");//txt文件是GBK编码
Field fileContentField = new TextField("fileContent", fileContent, Store.YES);
//第四步:创建field对象,将field添加到document
document.add(fileNameField);
document.add(fileSizeField);
document.add(filePathField);
document.add(fileContentField);
//第五步:使用indexwriter对象将document对象写入索引库,此过程进行索引创建,并将索引和document对象写入索引库
inedxWriter.addDocument(document);
}
//第六步:关闭IndexWriter对象
inedxWriter.close();
}
2.4 精确查询方法:
第一步:创建一个Directory对象,也就是索引库存放的位置。
第二步:创建一个indexReader对象,需要指定Directory对象。
第三步:创建一个indexsearcher对象,需要指定IncdexReader对象第四步:创建一个TermQuery对象,指定查询的域和查询的键词。
第五步:执行查询。
第六步:返回查询结果。遍历查询结果并输出。第七步:关闭IndexReader 对象
/**
* @Description: 分词搜索
* @param: @throws IOException
* @return: void
* @throws
*/
@Test
public void testSearch() throws IOException{
//第一步:创建一个Directory对象,也就是索引库存放的位置
Path path = FileSystems.getDefault().getPath("F:/testData/luceneIndex");
Directory directory = FSDirectory.open(path);
//第二步:创建一个indexReader对象,需要执行Directory对象
IndexReader indexReader = DirectoryReader.open(directory);
//第三步:创建一个indexSearcher对象,需要指定IndexReader对象
IndexSearcher indexSearch = new IndexSearcher(indexReader);
//第四步:创建一个TermQuery对象,指定查询的域和查询的关键词,精准查询
Query query = new TermQuery(new Term("fileName", "ant"));
TopDocs topDoecs = indexSearch.search(query, 4);
//第五步:返回查询
ScoreDoc[] scoreDocs = topDoecs.scoreDocs;
//第六步:返回查询结果,遍历查询结果并输出
for(ScoreDoc scoreDoc : scoreDocs){
int docID = scoreDoc.doc;
Document document = indexSearch.doc(docID);
String fileName = document.get("fileName");
String fileSize = document.get("fileSize");
String filePath = document.get("filePath");
String fileContent = document.get("fileContent");
System.out.println("--------------->fileName:" + fileName +",fileSize:" + fileSize + ",filePath:" + filePath);
}
//第七步:关闭IndexReader对象
indexReader.close();
}
@Test
public void testTokenStream() throws Exception {
// 创建一个分析器对象
//Analyzer analyzer = new StandardAnalyzer();
//Analyzer analyzer = new CJKAnalyzer();
//Analyzer analyzer = new SmartChineseAnalyzer();
Analyzer analyzer = new IKAnalyzer();
// 获得tokenStream对象
// 第一个参数:域名,可以随便给一个
// 第二个参数:要分析的文本内容
File file = new File("F:/testData/lucenetestdata/网易热评.txt");
String content = FileUtils.readFileToString(file, "GBK");
TokenStream tokenStream = analyzer.tokenStream("test",content);
// 添加一个引用,可以获得每个关键词
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
// 添加一个偏移量的引用,记录了关键词的开始位置以及结束位置
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
// 将指针调整到列表的头部
tokenStream.reset();
// 遍历关键词列表,通过incrementToken方法判断列表是否结束
while (tokenStream.incrementToken()) {
// 关键词的起始位置
System.out.println("start->" + offsetAttribute.startOffset());
// 取关键词
System.out.println(charTermAttribute);
// 结束位置
System.out. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









