









- 本次的问题是从网页中提取url产生的。地址http://beijing.anjuke.com/sale/
- xpath介绍自己百度,这里有两个重点,提取文本内容/text(),提取属性内容/@xxx
- 下面举例说明使用介绍,前提条件有lxml模块
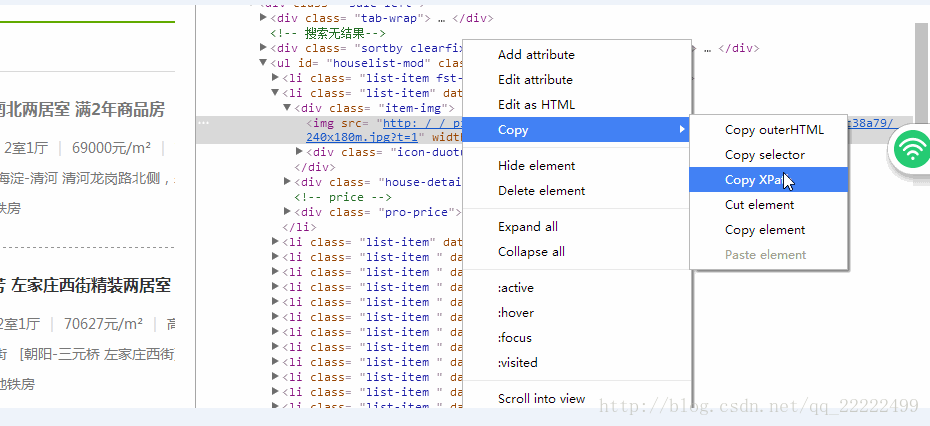
首先点击图片,查看元素,得到xpath
5.得到的是原始是”//[@id=”houselist-mod”]/li[2]/div[1]/img” 这里我要提取的img里面的src,从结构中我们很容易得到修改后的结果”//[@id=”houselist-mod”]/li/div[1]/img/@src”
6.这里最好把页面的源代码保存下来,放在一个本地文件中,因为我试了,直接通过代码得到源代码的,中间最重要的部分,得不到。下面的代码展示
#coding:utf-8
import re
from lxml import etree
class splider:
def printurl(self):
te=open("3.txt")
cont=te.read()
selector=etree.HTML(cont)
texturl=selector.xpath('//*[@id="houselist-mod"]/li/div[1]/img/@src')
print "符合条件个数" +str(len(texturl))
for text in texturl:
print text
if __name__ == '__main__':
sp=splider()
sp.printurl()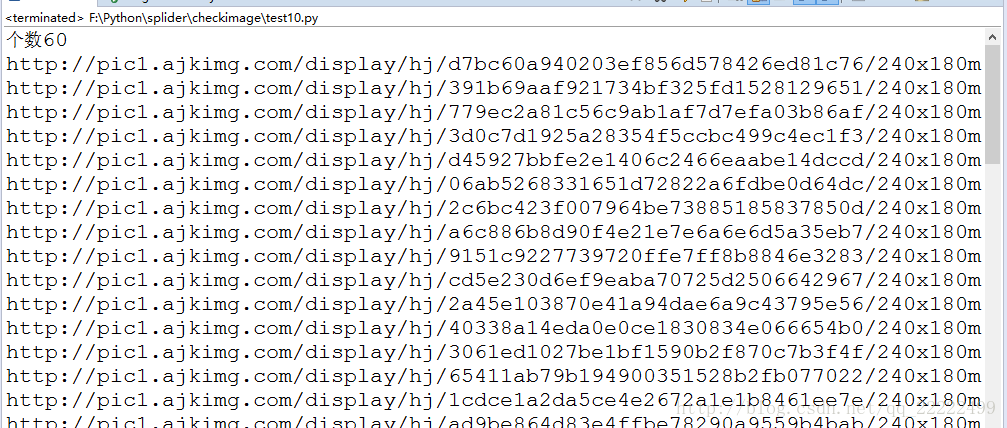
7.再举一个得到内容的例子
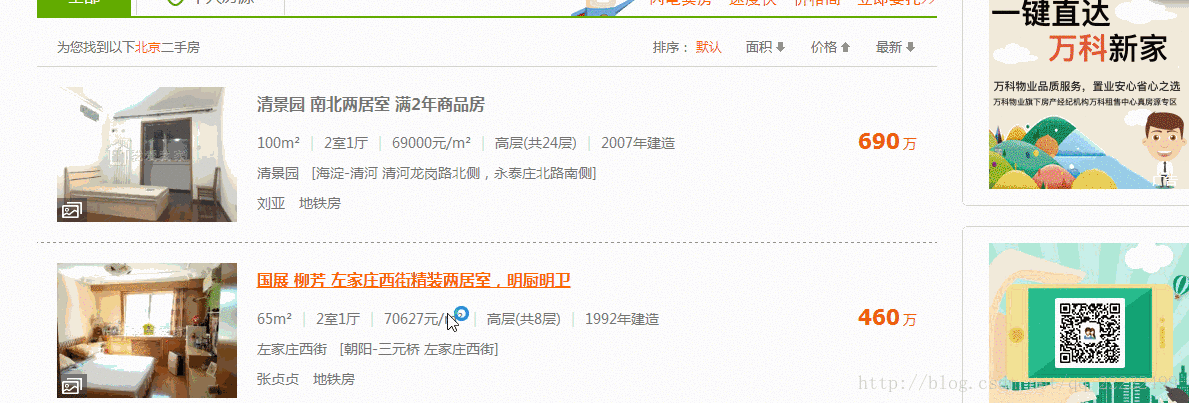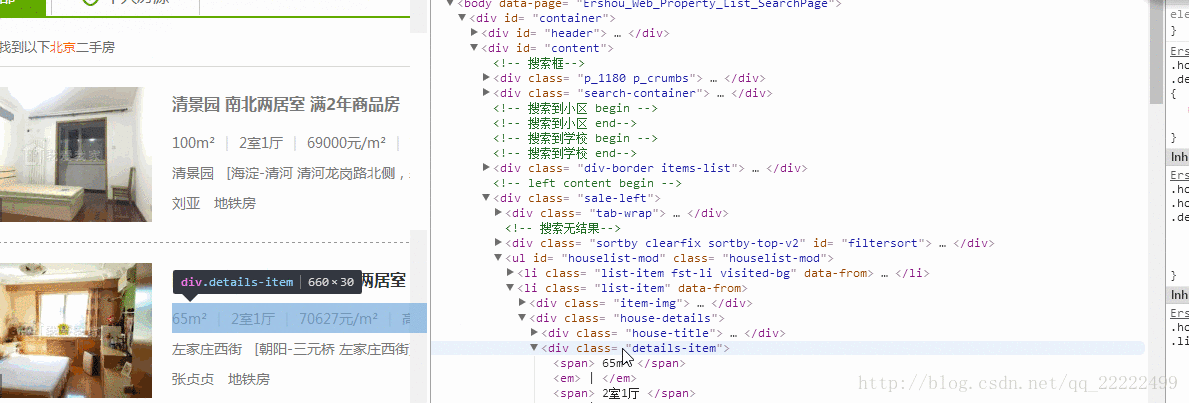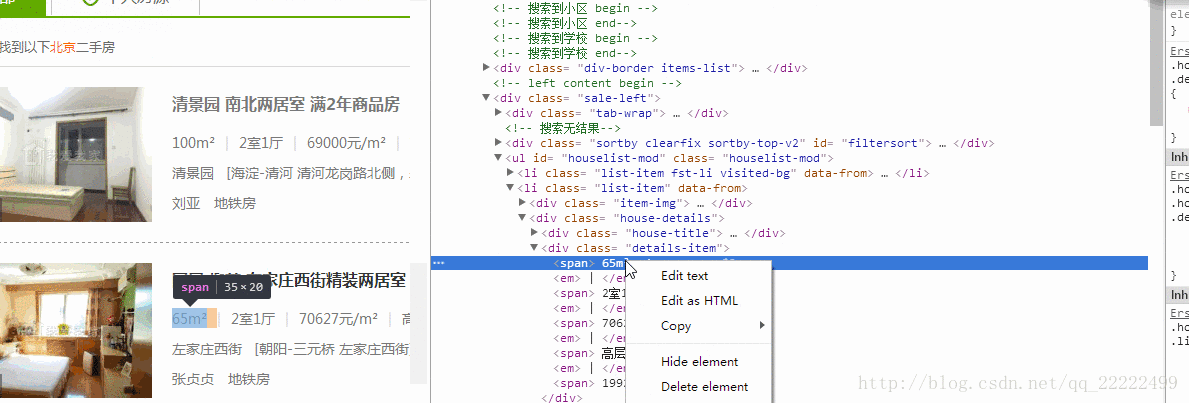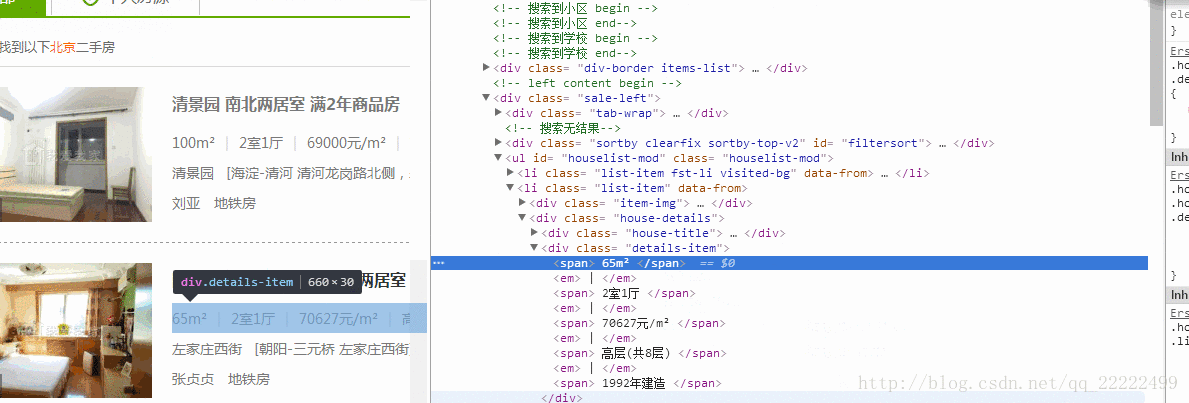
得到的原始内容是//[@id=”houselist-mod”]/li[2]/div[2]/div[2]/span[1]分析得到//[@id=”houselist-mod”]/li/div[2]/div[2]/span/text() 这里我做了点处理。信息成条显示。
#coding:utf-8
import re
from lxml import etree
class splider:
def printurl(self):
te=open("3.txt")
cont=te.read()
selector=etree.HTML(cont)
texturl=selector.xpath('//*[@id="houselist-mod"]/li/div[2]/div[2]/span/text()')
i=0;
detail=""
for text in texturl:
if i==5:
print detail[:-1]
i=1;
detail=text+"|"
else:
i=i+1
detail=detail+text+"|"
if __name__ == '__main__':
sp=splider()
sp.printurl()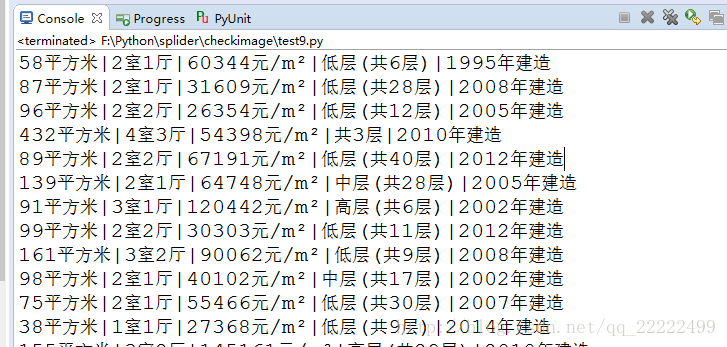















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











