







说明:Spark可以在只安装了JDK、Scala的机器上直接单机安装,但是这样的话只能使用单机模式运行不涉及分布式运算和分布式存储的代码,例如可以单机安装Spark,单机运行计算圆周率的Spark程序。但是我们要运行的是Spark集群,并且需要调用Hadoop的分布式文件系统,所以请你先安装Hadoop,Hadoop集群的安装可以参考该博文:Hadoop完全分布式安装(Centos7+Hadoop2.5.0);安装单机版的Spark可以参考该博文
Spark集群的最小化安装只需要安装这些东西:JDK 、Scala 、Hadoop 、Spark
壹 、安装Spark依赖的Scala
Hadoop的安装请参考上面提到的博文,因为Spark依赖scala,所以在安装Spark之前,这里要先安装scala。在每个节点上都进行安装。
1、 下载和解压缩Scala
(1) 官网下载地址。目前最新版是2.13.6,我就安装该版本。

(2)在Linux服务器的/usr/local目录下新建一个名为scala的文件夹,并将下载的压缩包上传上去。如图:(使用的FinalShell)

(3)cd到该目录,执行命令进行解压缩:
cd /usr/local/scala
tar -xvf scala-2.13.62、 配置环境变量
编辑/etc/profile这个文件,在文件中增加配置:
export SCALA_HOME="/usr/local/scala/scala-2.13.6"
export PATH=.:$PATH:${SCALA_HOME}/bin环境变量配置完成后,执行下面的命令:
source /etc/profile
3、验证Scala
scala -version
如图:
![]()
贰、 下载和解压缩Spark
注意:每个spark节点都需要下载、解压缩spark安装包
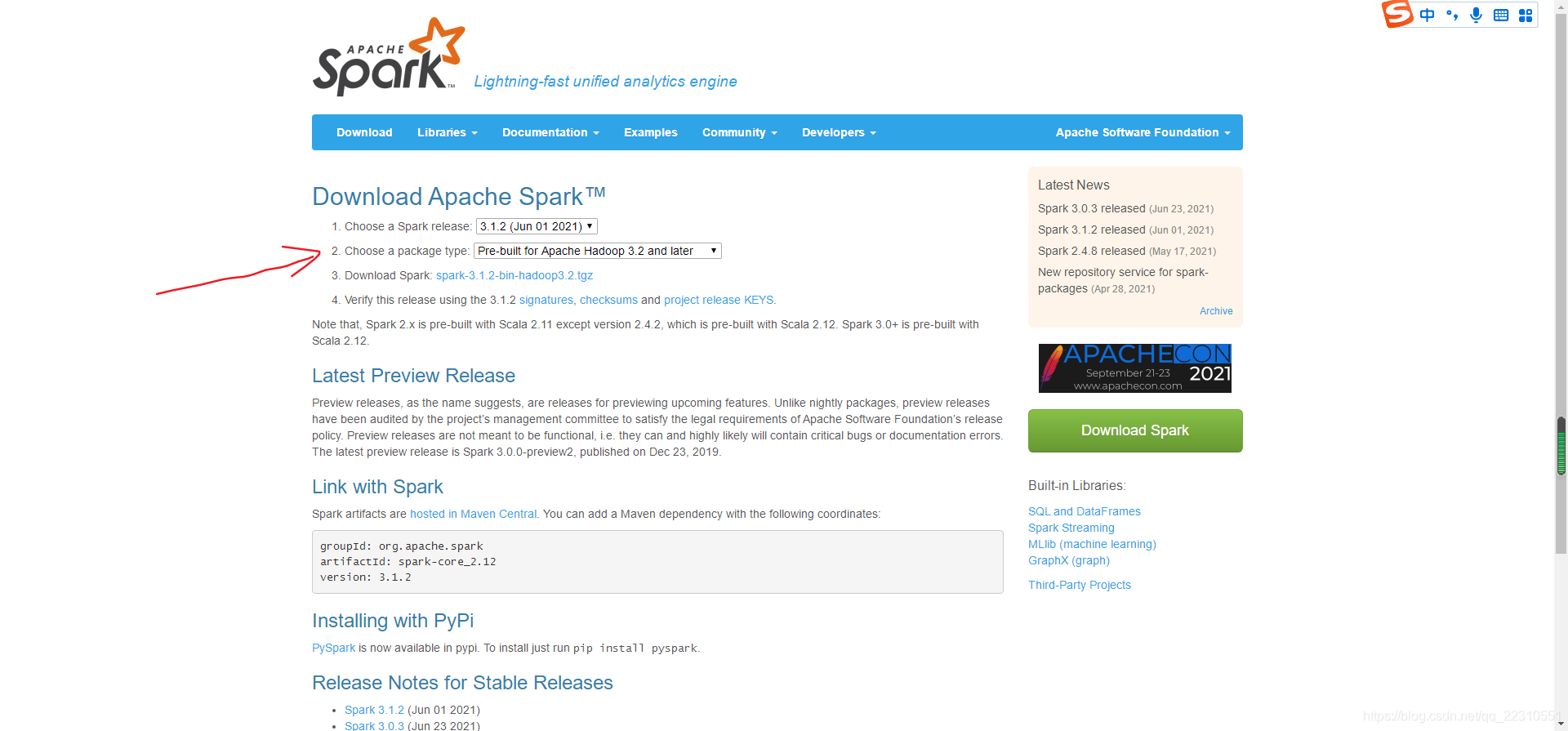
(1) 下载Spark压缩包
官网下载spark压缩包,下载后得到了大约200M的文件: spark-2.1.1-bin-hadoop2.7
(2) 解压缩Spark
下载完成后,在Linux服务器的/usr/local目录下新建一个名为spark的文件夹,把刚才下载的压缩包上传上去。

进入到该目录内,执行解压缩命令:
cd /usr/local/spark
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz(3)Spark相关的配置
说明:因为我们搭建的是基于hadoop集群的Spark集群,所以每个hadoop节点上我都安装了Spark,都需要按照下面的步骤做配置,启动的话只需要在Spark集群的Master机器上启动即可,我这里是在hserver1上启动。
1、 配置SPARK_HOME环境变量
编辑/etc/profile文件,增加
export SPARK_HOME="/usr/local/spark/spark-3.1.2-bin-hadoop3.2"
export PATH=.:$PATH:${SPARK_HOME}/bin
注意:因为$SPARK_HOME/sbin目录下有一些文件名称和$HADOOP_HOME/sbin目录下的文件同名,为了避免同名文件冲突,这里不在PATH变量里添加$SPARK_HOME/sbin只添加了$SPARK_HOME/bin。
编辑完成后,执行命令使配置生效。
source /etc/profile2、 配置conf目录下的文件
对/usr/local/spark/spark-3.1.2-bin-hadoop3.2/conf目录下的文件进行配置。
新建spark-env.h文件
(1)执行命令,进入到/opt/spark/spark-2.1.1-bin-hadoop2.7/conf目录内:
cd /usr/local/spark/spark-3.1.2-bin-hadoop3.2/conf以spark为我们创建好的模板创建一个spark-env.h文件,命令是:
cp spark-env.sh.template spark-env.sh编辑spark-env.h文件,在里面加入配置(具体路径以自己的为准):vi spark-env.sh
export SCALA_HOME=/usr/local/scala/scala-2.13.6 export JAVA_HOME=/usr/java/jdk1.8.0_301 export HADOOP_HOME=/usr/local/hadoop/hadoop-2.10.1 export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export SPARK_HOME=/usr/local/spark/spark-3.1.2-bin-hadoop3.2 export SPARK_MASTER_IP=fang1.fri.com export SPARK_EXECUTOR_MEMORY=1G
新建slaves文件
执行命令,进入到/opt/spark/spark-2.1.1-bin-hadoop2.7/conf目录内:
cd /usr/local/spark/spark-3.1.2-bin-hadoop3.2/conf创建一个slaves文件,命令是:
touch slaves vi slaves编辑slaves文件,里面的内容为子节点的域名:
slave1
slave2
(4)将配置文件分发到子节点
在主节点执行如下命令,将配置文件分发到slave1,slave2同。
scp /usr/local/spark/spark-3.1.2-bin-hadoop3.2/conf/spark-env.sh slave1:/usr/local/spark/spark-3.1.2-bin-hadoop3.2/conf/scp /usr/local/spark/spark-3.1.2-bin-hadoop3.2/conf/slaves slave1:/usr/local/spark/spark-3.1.2-bin-hadoop3.2/conf/
叁、启动和测试Spark集群
(1) 启动Spark
因为spark是依赖于hadoop提供的分布式文件系统的,所以在启动spark之前,先确保hadoop在正常运行。
在hadoop正常运行的情况下,在master(也就是hadoop的namenode,spark的master节点)上执行命令:
cd /opt/spark/spark-2.1.1-bin-hadoop2.7/sbin执行启动脚本:
./start-all.sh注意:上面的命令中有./这个不能少,./的意思是执行当前目录下的start-all.sh脚本。
(2) 测试和使用Spark集群
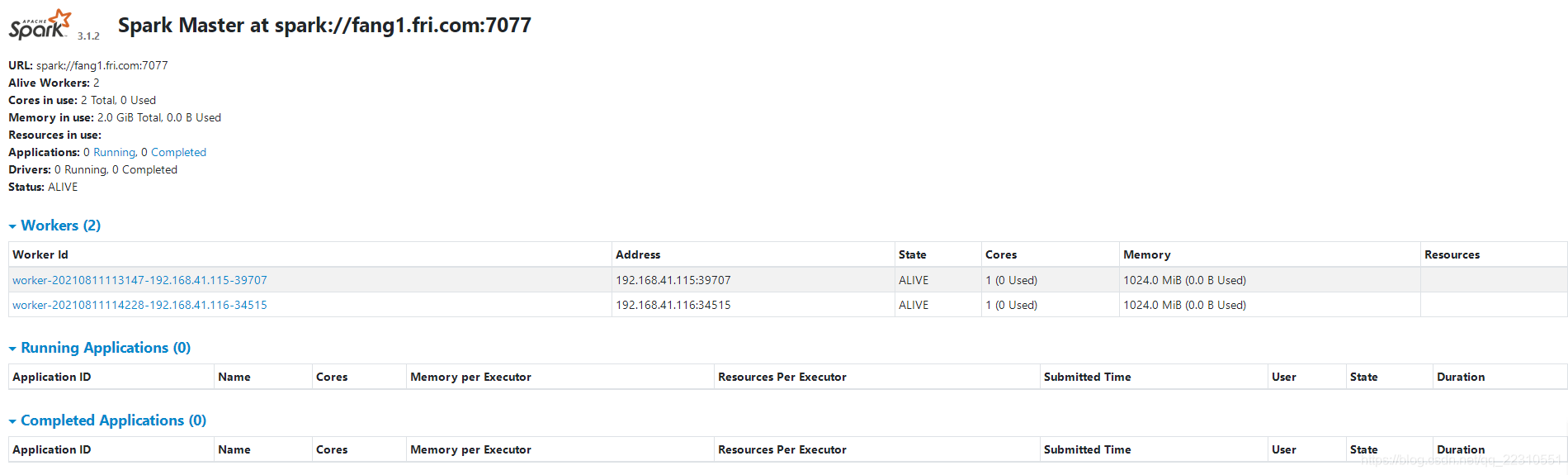
访问Spark集群提供的URL
在浏览器里访问Mster机器,我的Spark集群里Master机器是master,IP地址是192.168.41.252,访问8080端口,URL是:http://192.168.41.252:8080/
运行Spark提供的计算圆周率的示例程序
第一步,进入到Spark的根目录,也就是执行下面的脚本:
cd /opt/spark/spark-2.1.1-bin-hadoop2.7第二步,调用Spark自带的计算圆周率的Demo,执行下面的命令:
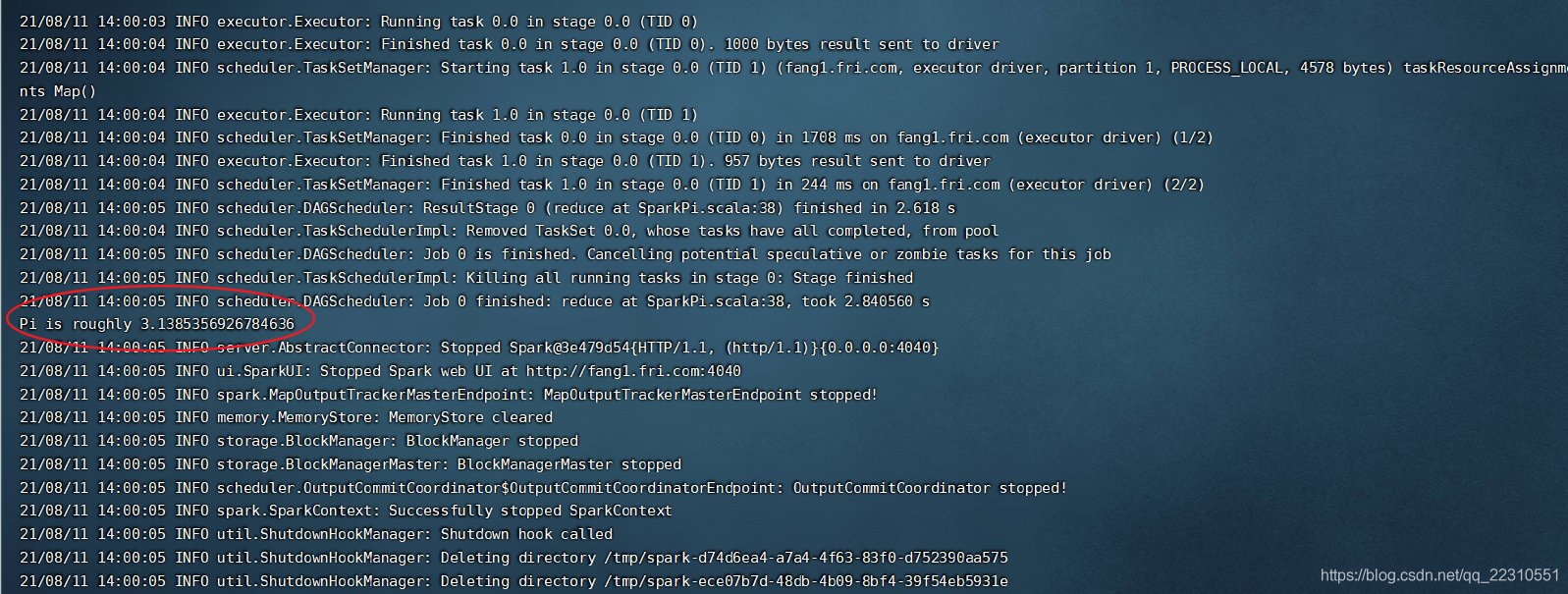
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local examples/jars/spark-examples_2.11-2.1.1.jar命令执行后,spark示例程序已经开始执行,很快执行结果出来了,执行结果我用红框标出来了
注意:上面只是使用了单机本地模式调用Demo,使用集群模式运行Demo,请参考该博文
参考资料















 1959
1959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











