







最近几天在公司一直在抓别的网站的数据, 今天闲来无事, 想写一个简单的node爬虫教程, 简单易学, 简单几步就可以实现, 可以控制并发, 请求频率等, 我是使用的node-cralwer这个框架写的, 当然使用原生的request模块也是可以的, 使用框架简单高效, 比自己写要效率好.
爬虫无非就是分析网页, 分析接口, 取得你想要的数据, 取得数据有两种方式
- 对于直接请求得到的是静态页面, 直接分析html, 取得自己需要的数据
- 还有就是通过api接口获取到的数据, 这样分析下参数, 就行
分析页面数据结构
今天我们以易车网为例子, 因为该网站两种方式都有易车网所有车型
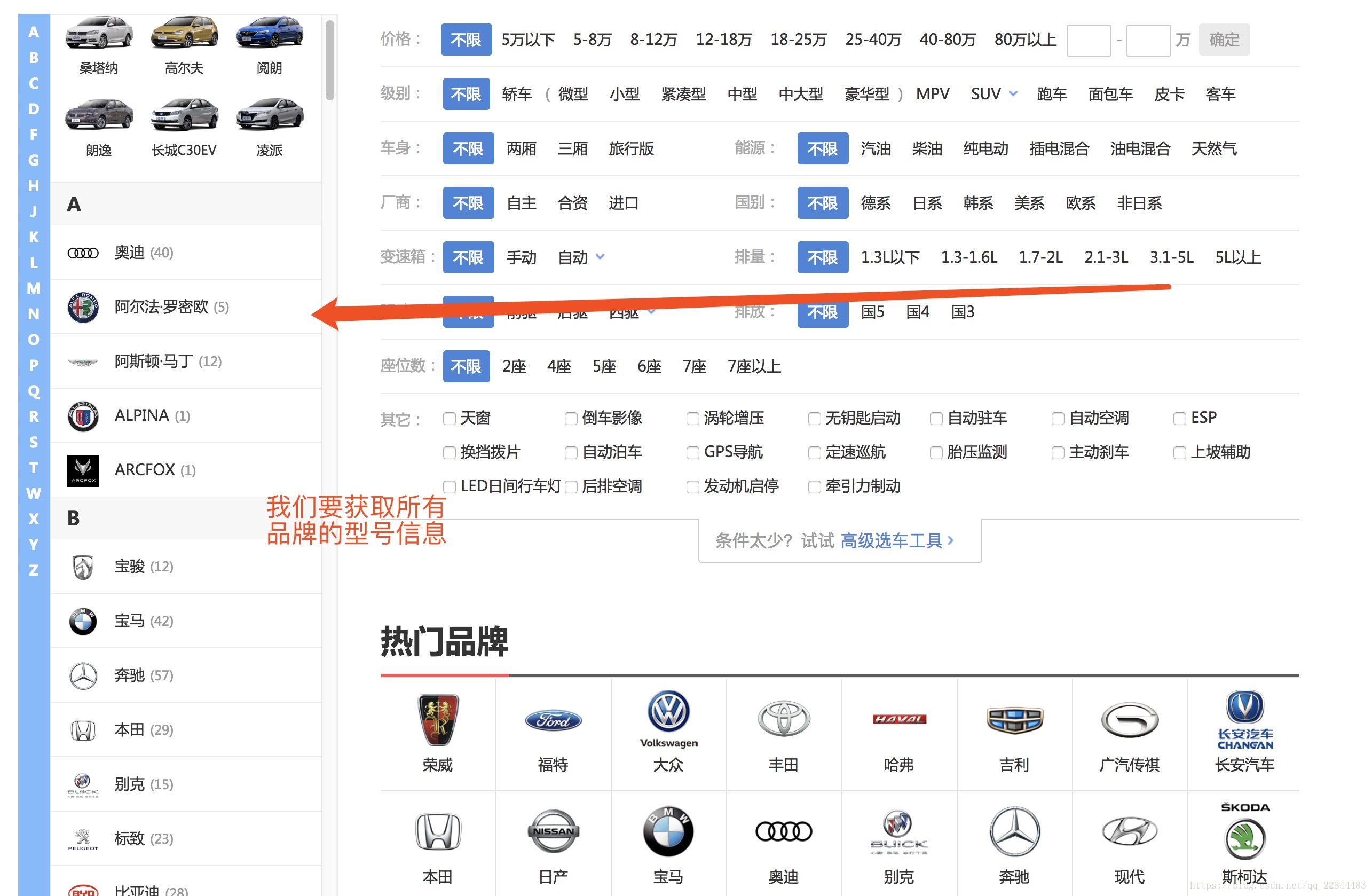
如图我们要获取所有品牌的型号信息, 点击左侧的导航, 会进入, 品牌车型列表页, 我们按F12会看到, 这部分的信息是后来js通过ajax请求到的, 所以这个就要请求接口获取数据了, 这里判断页面数据是ajax动态请求还是静态的数据, 可以右键查看网页源代码, 如果代码中有就是静态的, 如果没有就是ajax动态请求的数据
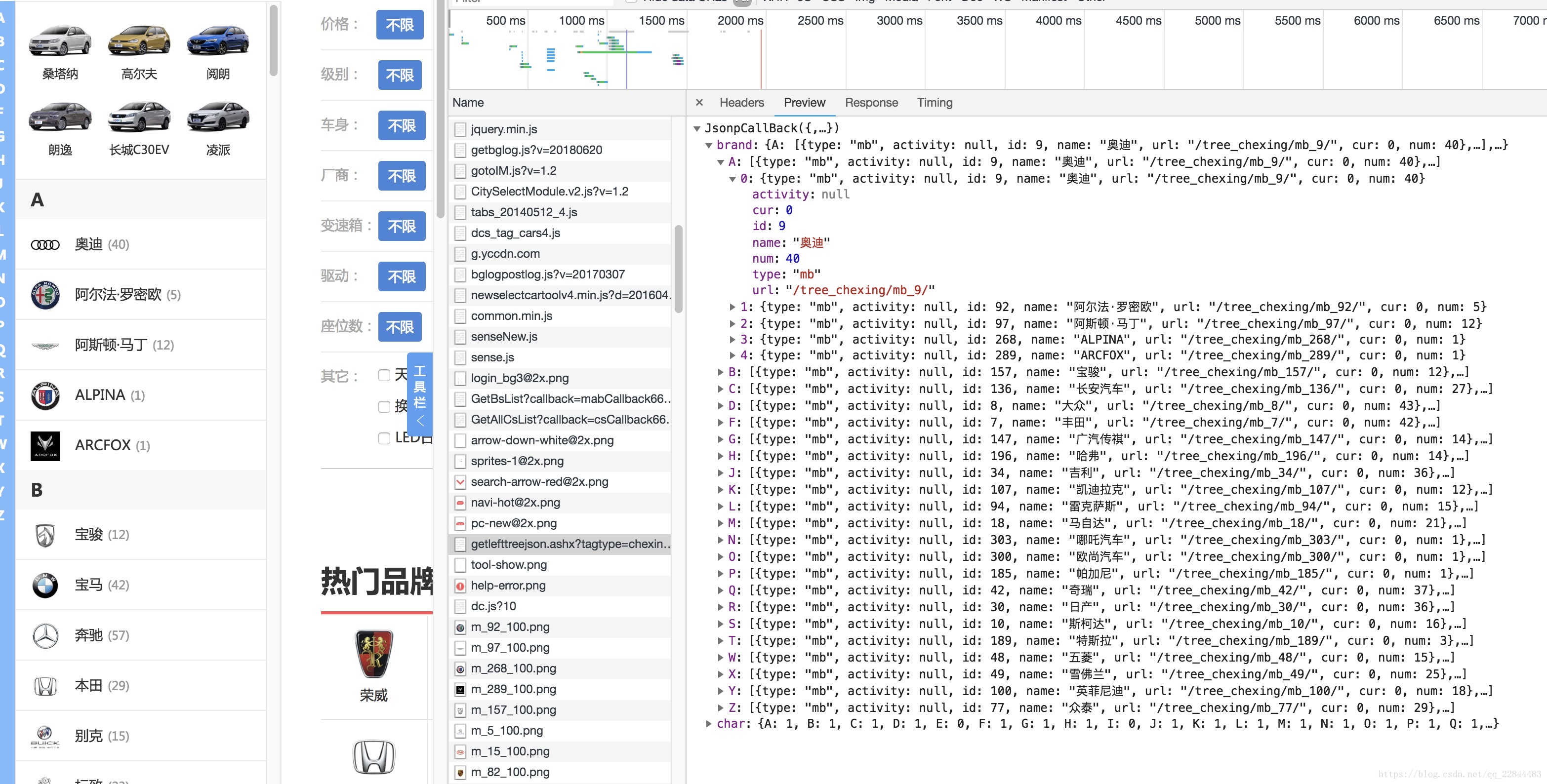
找到接口后我们就可以请求接口拿数据了, 可以看到每一项有一个url字段, 我们进入到品牌车型列表页之后会发现这个url加上根域名就是这个品牌的型号列表;
接下来我们在去进入品牌车型列表页, 这里我们可以看到, 这里的数据都是静态的(seo的原因),所以我们只需分析html就可以了
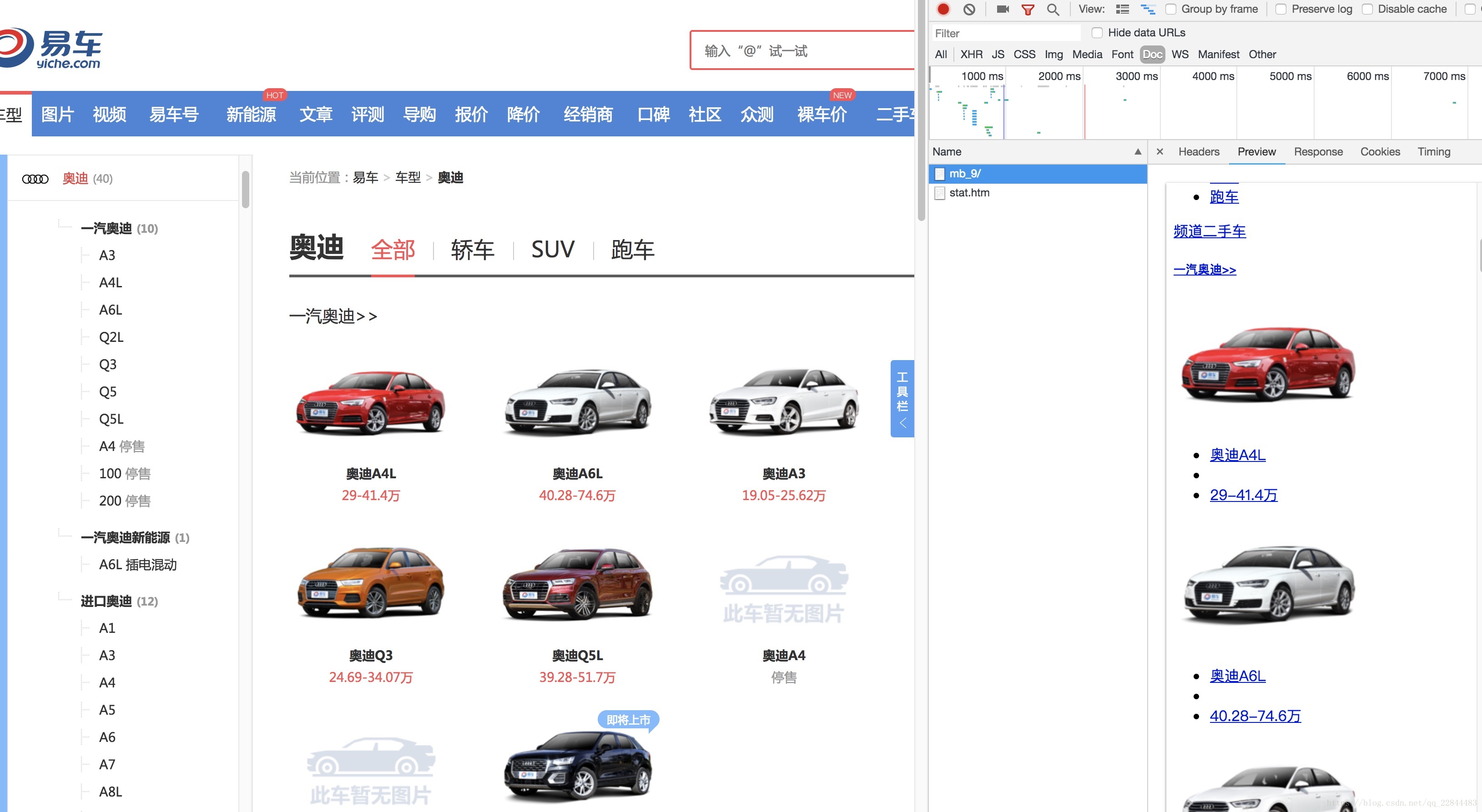
编写爬虫
页面数据结构我们已经分析完了
抓取步骤就是
- 先ajax请求首页的所有品牌的车型,
- 然后进入品牌车型列表页,
- 分析html取得自己想要的数据
我采用的是node-crawler这个框架, 使用方法我就不一一赘述了, 有中文文档
因为每个爬虫都需要初始化一个crawler对象, 所以这里我把crawler又封装了一下, 我的代码已经传到github上, 感兴趣的可以去clone下来看一下
const< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 735
735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









