







什么是线程池
线程池的概念大家应该都很清楚,帮我们重复管理线程,避免创建大量的线程增加开销。
除了降低开销以外,线程池也可以提高响应速度,了解点 JVM 的同学可能知道,一个对象的创建大概需要经过以下几步:
- 检查对应的类是否已经被加载、解析和初始化
- 类加载后,为新生对象分配内存
- 将分配到的内存空间初始为 0
- 对对象进行关键信息的设置,比如对象的哈希码等
- 然后执行 init 方法初始化对象
创建一个对象的开销需要经过这么多步,也是需要时间的嘛,那可以复用已经创建好的线程的线程池,自然也在提高响应速度上做了贡献。
线程池的处理流程
创建线程池需要使用 ThreadPoolExecutor 类,它的构造函数参数如下:
public ThreadPoolExecutor(int corePoolSize, //核心线程的数量
int maximumPoolSize, //最大线程数量
long keepAliveTime, //超出核心线程数量以外的线程空余存活时间
TimeUnit unit, //存活时间的单位
BlockingQueue<Runnable> workQueue, //保存待执行任务的队列
ThreadFactory threadFactory, //创建新线程使用的工厂
RejectedExecutionHandler handler // 当任务无法执行时的处理器
) {...}参数介绍如注释所示,要了解这些参数左右着什么,就需要了解线程池具体的执行方法ThreadPoolExecutor.execute:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//1.当前池中线程比核心数少,新建一个线程执行任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//2.核心池已满,但任务队列未满,添加到队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command)) //如果这时被关闭了,拒绝任务
reject(command);
else if (workerCountOf(recheck) == 0) //如果之前的线程已被销毁完,新建一个线程
addWorker(null, false);
}
//3.核心池已满,队列已满,试着创建一个新线程
else if (!addWorker(command, false))
reject(command); //如果创建新线程失败了,说明线程池被关闭或者线程池完全满了,拒绝任务
}可以看到,线程池处理一个任务主要分三步处理,代码注释里已经介绍了,我再用通俗易懂的例子解释一下:
(线程比作员工,线程池比作一个团队,核心池比作团队中核心团队员工数,核心池外的比作外包员工)
- 有了新需求,先看核心员工数量超没超出最大核心员工数,还有名额的话就新招一个核心员工来做
- 需要获取全局锁
- 核心员工已经最多了,HR 不给批 HC 了,那这个需求只好攒着,放到待完成任务列表吧
- 如果列表已经堆满了,核心员工基本没机会搞完这么多任务了,那就找个外包吧
- 需要获取全局锁
- 如果核心员工 + 外包员工的数量已经是团队最多能承受人数了,没办法,这个需求接不了了
结合这张图,这回流程你明白了吗?
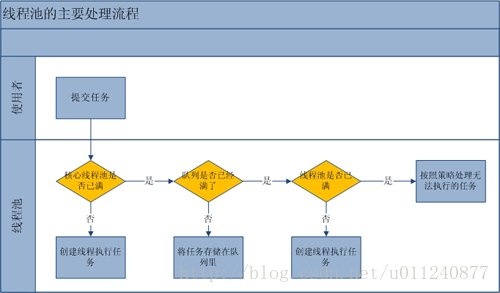
由于 1 和 3 新建线程时需要获取全局锁,这将严重影响性能。因此 ThreadPoolExecutor 这样的处理流程是为了在执行 execute() 方法时尽量少地执行 1 和 3,多执行 2。
在
ThreadPoolExecutor完成预热后(当前线程数不少于核心线程数),几乎所有的execute()都是在执行步骤 2。
前面提到的 ThreadPoolExecutor 构造函数的参数,分别影响以下内容:
- corePoolSize:核心线程池数量
- 在线程数少于核心数量时,有新任务进来就新建一个线程,即使有的线程没事干
- 等超出核心数量后,就不会新建线程了,空闲的线程就得去任务队列里取任务执行了
- maximumPoolSize:最大线程数量
- 包括核心线程池数量 + 核心以外的数量
- 如果任务队列满了,并且池中线程数小于最大线程数,会再创建新的线程执行任务
- keepAliveTime:核心池以外的线程存活时间,即没有任务的外包的存活时间
- 如果给线程池设置 allowCoreThreadTimeOut(true),则核心线程在空闲时头上也会响起死亡的倒计时
- 如果任务是多而容易执行的,可以调大这个参数,那样线程就可以在存活的时间里有更大可能接受新任务
- workQueue:保存待执行任务的阻塞队列
- 不同的任务类型有不同的选择,下一小节介绍
- threadFactory:每个线程创建的地方
- 可以给线程起个好听的名字,设置个优先级啥的
- handler:饱和策略,大家都很忙,咋办呢,有四种策略
- CallerRunsPolicy:只要线程池没关闭,就直接用调用者所在线程来运行任务
- AbortPolicy:直接抛出 RejectedExecutionException 异常
- DiscardPolicy:悄悄把任务放生,不做了
- DiscardOldestPolicy:把队列里待最久的那个任务扔了,然后再调用 execute() 试试看能行不
我们也可以实现自己的 RejectedExecutionHandler 接口自定义策略,比如如记录日志什么的
保存待执行任务的阻塞队列
当线程池中的核心线程数已满时,任务就要保存到队列中了。
线程池中使用的队列是 BlockingQueue 接口,常用的实现有如下几种:
- ArrayBlockingQueue:基于数组、有界,按 FIFO(先进先出)原则对元素进行排序
- LinkedBlockingQueue:基于链表,按FIFO (先进先出) 排序元素
- 吞吐量通常要高于 ArrayBlockingQueue
- Executors.newFixedThreadPool() 使用了这个队列
- SynchronousQueue:不存储元素的阻塞队列
- 每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态
- 吞吐量通常要高于 LinkedBlockingQueue
- Executors.newCachedThreadPool使用了这个队列
- PriorityBlockingQueue:具有优先级的、无限阻塞队列
如何合理地选择或者配置
- CachedThreadPool 用于并发执行大量短期的小任务,或者是负载较轻的服务器。
- FixedThreadPool 用于负载比较重的服务器,为了资源的合理利用,需要限制当前线程数量。
- SingleThreadExecutor 用于串行执行任务的场景,每个任务必须按顺序执行,不需要并发执行。
- ScheduledThreadPoolExecutor 用于需要多个后台线程执行周期任务,同时需要限制线程数量的场景。
附带链接:https://blog.csdn.net/u011240877/article/details/73440993














 2171
2171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









