




java8实战 随笔摘抄备忘
lambda基本上是一个没有声明名称的方法
可以十分简明的传递代码
lambda隐含return语句
对于 ()-> 42 这段代码 无入参,但会返回int类型值42
在函数式接口中使用 lambda
lambda表达式为函数式接口的抽象方法提供实现.
lambda表达式可以赋值给一个变量 Runnable r1 = () -> System.out.println("Hello World 1"); -----r1是个变量
lambda表达式可以为函数式接口生成一个实例,然而,lambda表达式本身并不包含它在实现哪个函数式接口的信息.
同样的lambda,不同的函数式接口
自动推断类型,所以入参可以写成 e
lambda使用局部变量
要求:局部变量显示声明为final,或事实上最终的
因为:实例变量存储在堆中,局部变量保存在栈上.(方法保存在栈里,局部变量在方法中)
目的:防止线程不安全
方法引用
方法引用就是让你根据已有的方法实现来创建lambda表达式,方法引用就是lambda表达式的快捷写法
使用流
数值流,文件流,数组流,无限流
filter:结果是两类 一类满足筛选条件,一类不满足筛选条件
筛选各异的元素,就是去重,用distinct方法:
截短流,limit
跳过元素 skip(n)方法.扔掉前n个元素
映射
map和flatmap方法,类似于SQL中选择某一列
map方法会接受一个函数作为参数
map 不光是对对象流进行单字段的“截取”,还可以做“映射”,传一个函数进map(Function f).
流的扁平化 flatmap
flatmap方法让你把一个流中的每个值都换成另一个流,然后把所有的流连接起来成为一个流
例题: (2) 给定两个数字列表,如何返回所有的数对呢?例如,给定列表[1, 2, 3]和列表[3, 4],应
该返回[(1, 3), (1, 4), (2, 3), (2, 4), (3, 3), (3, 4)]。为简单起见,你可以用有两个元素的数组来代
表数对。
答案:你可以使用两个map来迭代这两个列表,并生成数对。但这样会返回一个Stream-
<Stream<Integer[]>>。你需要让生成的流扁平化,以得到一个Stream<Integer[]>。这
正是flatMap所做的:
List<Integer> numbers1 = Arrays.asList(1, 2, 3);
List<Integer> numbers2 = Arrays.asList(3, 4);
List<int[]> pairs =
numbers1.stream()
.flatMap(i -> numbers2.stream()
.map(j -> new int[]{i, j})
)
.collect(toList());
(3) 如何扩展前一个例子,只返回总和能被3整除的数对呢?例如(2, 4)和(3, 3)是可以的。
答案:你在前面看到了, filter可以配合谓词使用来筛选流中的元素。因为在flatMap
操作后,你有了一个代表数对的int[]流,所以你只需要一个谓词来检查总和是否能被3整除
就可以了:
List<Integer> numbers1 = Arrays.asList(1, 2, 3);
List<Integer> numbers2 = Arrays.asList(3, 4);
List<int[]> pairs =
numbers1.stream()
.flatMap(i ->
numbers2.stream()
.filter(j -> (i + j) % 3 == 0)
.map(j -> new int[]{i, j})
)
.collect(toList());
其结果是[(2, 4), (3, 3)]。
切片和筛选
filter distinct(可以使用Collect.toSet()代替) limit skip
查找和匹配
find 和 match
是否至少匹配一个 anyMatch() 返回boolean
是否匹配所有 allMatch()
是否无匹配 noneMatch()
findAny() 只返回一个值,可以与其他流操作结合使用
注意: 在串行的流中,findAny和findFirst返回的,都是第一个对象;而在并行的流中,findAny返回的是最快处理完的那个线程的数据,所以说,在并行操作中,对数据没有顺序上的要求,那么findAny的效率会比findFirst要快的

findAny()之后这个流就会关闭,ifPresent()是Optional类的方法.
findFirst() 有序流查找第一个元素
归约(将流归约成一个值)
将流中的元素组合起来,使用reduce操作来表达更复杂的查询
元素求和
reduce接受两个参数:
一个初始值,
一个BinaryOperator<T> 可以是lambda表达式,可以是Function 接口.对于求和可以用Integer::sum
reduce还有一个重载的变体,它不接受初始值,所以返回可能为空,因此返回一个Optional对象.
最大值和最小值
Optional<Integer> max = numbers.stream().reduce(Integer::max);
Optional<Integer> min = numbers.stream().reduce(Integer::min);
流支持min和max方法:
stream.min(comparing(Function f));
map-reduce模式,因Google用它来进行网络搜索而出名,因为它很容易进行并行化。
统计个数
long count = menu.stream().count();
使用场景模拟:
如果涉及对字符串的连接,使用collect(joining())
数值流
原始类型流特化,避免封装类型的性能损耗
映射到数值流:
stream().mapToInt(Function f).sum();
.max()
.min()
.average()
转换为对象流:
stream.mapToInt().boxed()
默认值OptionalInt
数值范围
IntStream.range(start,end)和rangeClosed(start,end).前一个不包含结束值,后一个包含结束值end
作用是,生成从start到end的数值流
从值序列、数组、文件来创建流,甚至由生成函数来创建无限流
由值创建流 Stream.of()
由数组创建流 Arrays.stream()
由文件生成流 Files.lines()
由函数生成流
迭代 Stream.iterate(初始值,lambda表达式).limit();
应用:如何取数组流中每个数组中的第一个元素 stream.map(e->e[0])
生成 Stream.generate(Math::random).limit()
第六章 用流收集数据
collect是一个归约操作,就像reduce一样可以接
受各种做法作为参数,将流中的元素累积成一个汇总结果。具体的做法是通过定义新的
Collector接口来定义的,因此区分Collection、 Collector和collect是很重要的。
分组
多级分组
把不同的收集齐结合起来,对每个子组进行进一步归约
预定义收集器提供了三大功能:
流元素归约,元素分组,元素分区
归约和汇总
stream().collect(Collectors.counting());
这样写不如stream().count(),有多个收集器的时候才能起作用
menu.stream().collect(summingInt(Dish::getCalories)) 求和
menu.stream().collect(averagingInt(Dish::getCalories)); 求平均
map()操作之后也可以求和求平均,还能求最值
如果要一次性获取多个统计数据,可以用summarizingInt(Dish::getCalories)
连接字符串
joining工厂方法返回的收集器会把对流中每一个对象应用toString方法得到的所有字符串连接成一个字符串。
这意味着你把菜单中所有菜肴的名称连接起来,如下所示:
String shortMenu = menu.stream().map(Dish::getName).collect(joining());
但该字符串的可读性并不好。幸好, joining工厂方法有一个重载版本可以接受元素之间的分界符,
这样你就可以得到一个逗号分隔的菜肴名称列表:
String shortMenu = menu.stream().map(Dish::getName).collect(joining(", "));
collect方法和reduce方法的对比,collect方法更适合并行操作
collect在归约的时候要传3个参数,初始值,转换函数,累积函数。reduce()其实就是它的简化版

结论:最值用mapToInt()
分组
按类型值去分组:groupingBy(类型值)
按范围去分组:自定义分组逻辑
public enum CaloricLevel { DIET, NORMAL, FAT }
Map<CaloricLevel, List<Dish>> dishesByCaloricLevel = menu.stream().collect(
groupingBy(dish -> {
if (dish.getCalories() <= 400) return CaloricLevel.DIET;
else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
} ));
多级分组
使用一个由双参数版本的Collectors.groupingBy工厂方法创建的收集器
第一个参数还是普通的分类函数,第二个参数是Collector(比如groupingBy(),里面还可以继续套groupingBy())。生成一个双层map
二级分组相当于一个二维表
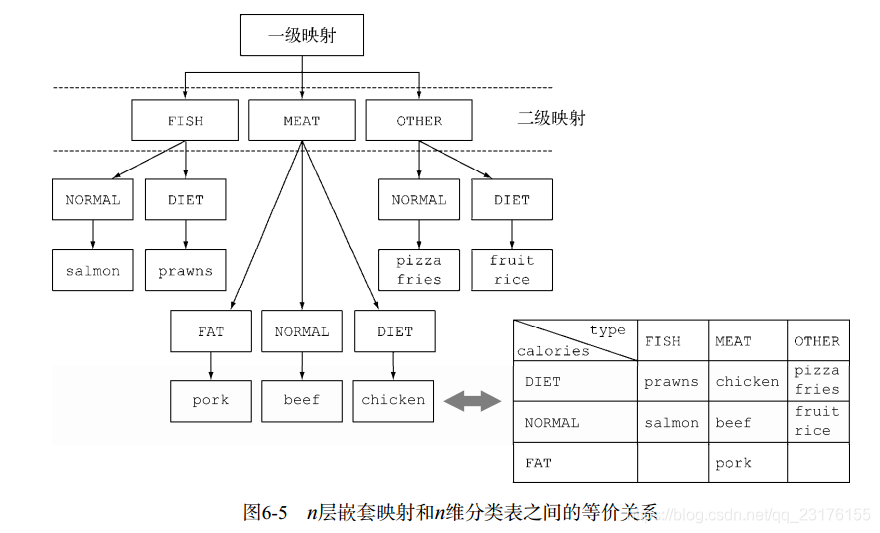
第二个参数Collector可以是groupingBy(),但不限于此。第二个收集器可以是任何类型,
比如可以是counting()。这样就可以实现分类并统计个数
也可以是maxBy(comparingInt())。这样就可以实现分类并取最大值
把收集器返回的结果转化为另一种类型
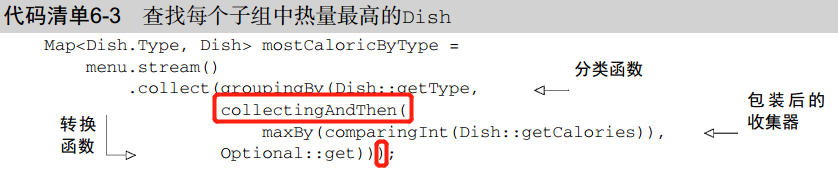
Collectors.collectingAndThen()工厂方法
接受两个参数—要转换的收集器和转换函数。
从![]()
到![]()
分区
分区是特殊的分组,由一个返回布尔值的函数作为分类函数。最多只能分两组,true一组,false一组
partitioningBy()
partitioningBy(分区函数,groupingBy()) 结果先分两类,再做细分
收集器接口
实现Collector接口从而自由创建自定义归约操作。
有点麻烦
第七章 并行数据处理与性能
在调用那个看似神奇的parallel操作时,了解背后到底发生了什么是很有必要的
多测试看看是否真的并行处理了.当操作数字流的时候一定要注意避免装箱/拆箱上的性能损耗.
使用正确的数据结构然后使其并行工作能够保证最佳的性能
避免使用共享变量
如果是较少的数据量,不建议并行
要考虑流背后的数据机构是否易于分解
要考虑合并步骤的代价是大是小
第八章 重构,测试和调试
- 使用lambda重构面向对象的设计模式
策略模式
一个算法接口, 实质是一个函数接口,定义各个函数
多个算法实现,
多个策略对象客户
对于上面的函数接口,可以用lambda表达式代替实体类
模板方法
在搭建一个框架的同时又需要一定的灵活度,能对某部分进行修改 就像函数
可修改部分就可以用lambda表达式实现
好像要麻烦一点,需要构造功能函数?要用到.accept()方法
观察者模式
需要一个观察者接口,仅有一个notify的方法.不同的观察者实现不同的方法
不太适合全盘使用lambda表达式
责任链模式
是一种创建处理对象序列的通用方案,方法A处理完了将任务传给方法B去处理,依次类推
改用lambda表达式,可以用A.andThan(B)方法来处理.
工厂模式
提供一个方法,根据传入的参数不同而创建并返回不同的对象
拓展性不强
- 测试
如何测试lambda表达式,方法栈不太方便,因为是匿名函数,所以不太好定位
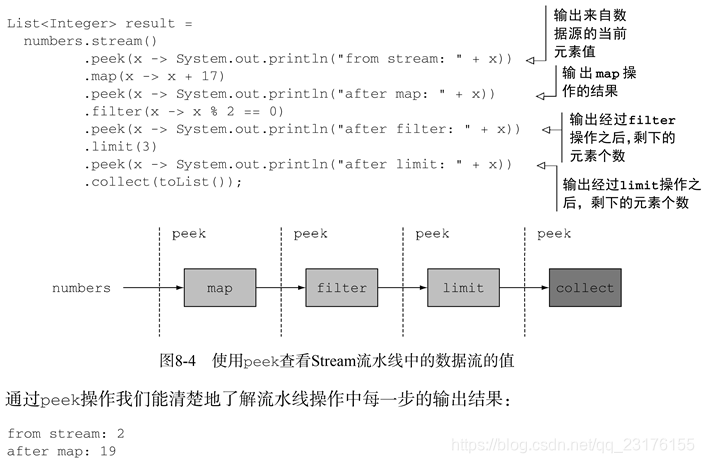
可以使用日志调试
在方法链之间插入peek(lambda表达式)方法.
第十一章 CompletableFuture:组合式异步编程
并发:单核处理多任务
并行:多核处理任务
- CompletableFuture是Future的新版实现
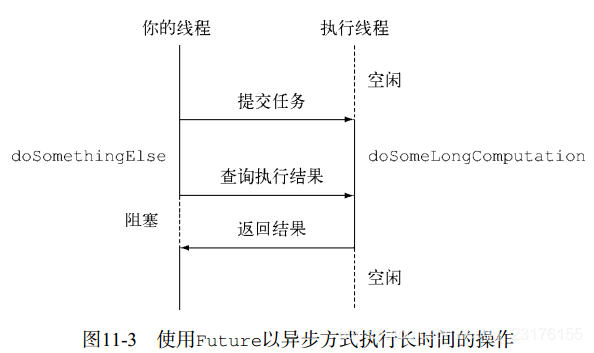
这种编程方式让你的线程可以在ExecutorService以并发方式调
用另一个线程执行耗时操作的同时,去执行一些其他的任务。接着,如果你已经运行到没有异步
操作的结果就无法继续任何有意义的工作时,可以调用它的get方法去获取操作的结果。如果操
作已经完成,该方法会立刻返回操作的结果,否则它会阻塞你的线程,直到操作完成,返回相应
的结果。
- 使用CompletableFuture构建异步应用
同步API:甲调用乙,在乙运行时甲会等待,即阻塞式调用。
异步API:甲调用乙,但是甲跟乙不在同一个线程,甲和乙是异步的,即非阻塞式调用。乙会将计算结果返回给甲。
实现异步API
Future是一个暂时还不可知值的处理器,调用其get()方法时会发生阻塞.
- 将同步方法转换为异步方法
错误处理,获取任务线程的异常信息
public Future<Double> getPriceAsync(String product) {
CompletableFuture<Double> futurePrice = new CompletableFuture<>();
new Thread( () -> {
try {
double price = calculatePrice(product);
futurePrice.complete(price);
} catch (Exception ex) {
futurePrice.completeExceptionally(ex);
}
}).start();
return futurePrice;
}
使用CompletableFuture发起异步请求
并行流默认使用的线程池大小就是机器核心数
使用定制的执行器可以自定义线程池大小


设I/O的时间是a,接口总用时是b 等待时间就是a,计算时间是(b-a)
比率是:a/(b-a)

计算密集型:处理数据量大,过程计算步骤多,使用机器的默认线程即可.
涉及I/O操作:每次计算量比较小,不能充分利用单核的计算能力,适合多创建线程.
对多个异步任务进行流水线操作
上面所说的每个Future中进行的都是单次操作,接下来会将多个异步操作结合在一起,以流水线的方式运行
使用CompletableFutures可能比使用并行流要慢一些,如果不考虑线程个数的话
因为并行流使用默认的线程数
- 使用定制的执行器
|
private final Executor executor = |
1.创建一个线 |

异步à同步à异步
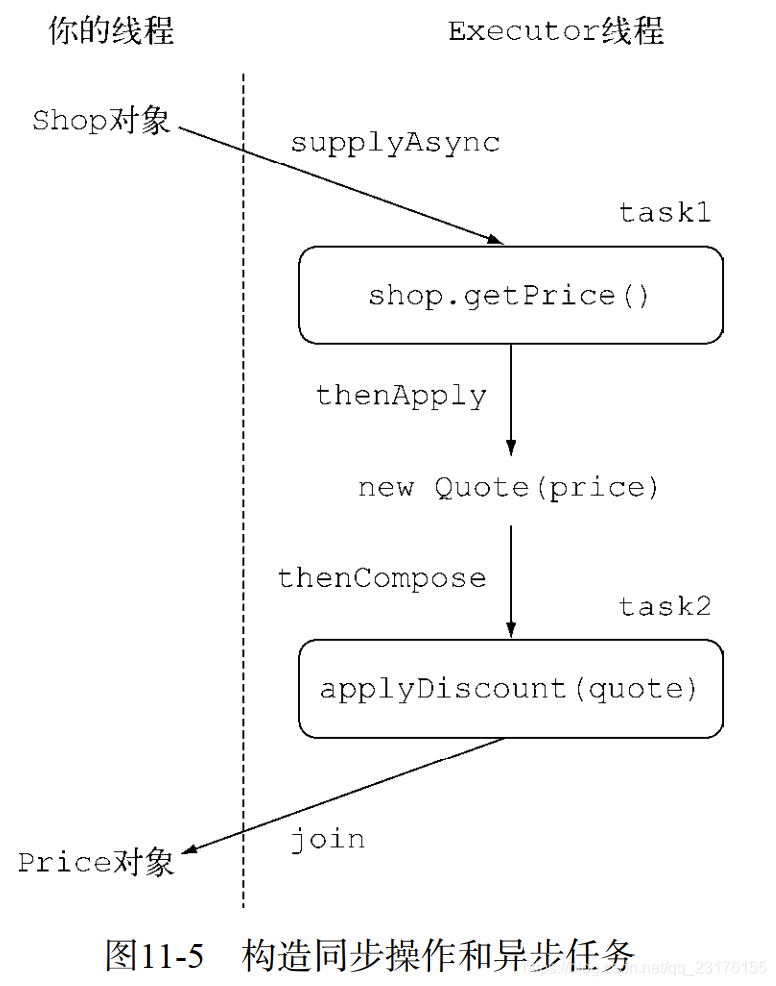
如果执行两次异步操作,用了两个不同的CompletableFuture对象,还希望将他们以级联的方式串联起来进行工作.
那么需要使用thenCompose方法.它允许你对两个异步操作进行流水线
换句话说,你可以创建两个CompletableFuture对象,对第一个CompletableFuture对象调用thencompose方法,并向其传递一个函数.
thencompose方法还有一个以Async结尾的异步方法
将两个CompletableFuture对象整合起来,无论他们是否存在依赖
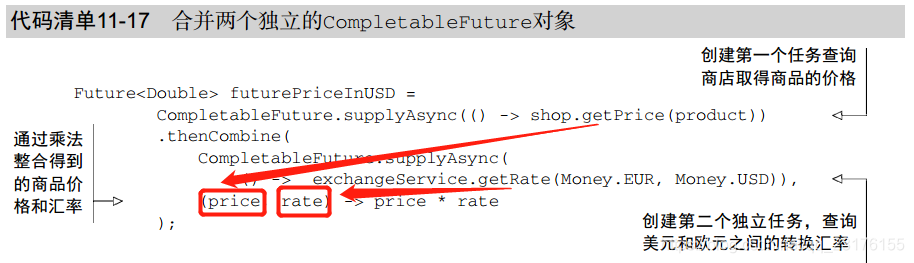
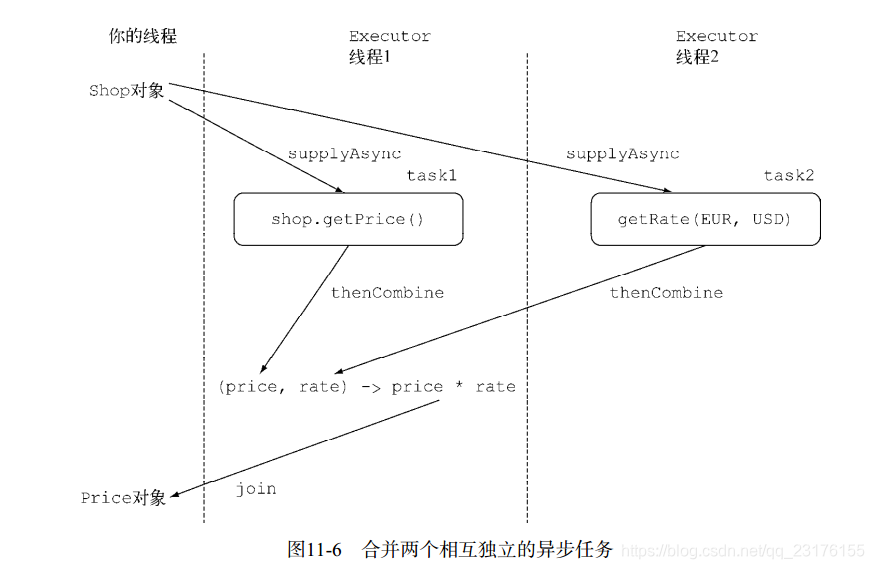
一种常见的情况是:你需要将两个完全不相关的completablefuture对象的结果整合起来。而且二者之间没有依赖性
也就是两个completablefuture之间是并联关系,用thenCombine()方法
这种情况,你应该使用thenCombine方法,它接收名为BiFunction的第二参数,这个参数
定义了当两个CompletableFuture对象完成计算后,结果如何合并。
如何处理结果作为第二个参数
响应completablefuture的completion事件

















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









