




图像Inpainting(图像修复)是一种利用算法对图像中缺失、损坏或不需要的部分进行智能填充或修复的技术,旨在恢复图像的完整性和视觉自然度。其核心是通过分析图像上下文信息,推断并生成与周围区域在颜色、纹理和结构上一致的内容,使修复后的区域无明显人工痕迹。下面我将复现图像修复模型LaMa的过程和遇到的问题记录下来。
一、前言
LAMA Inpaint,即Large Mask Inpainting,是一种基于深度学习的图像修复技术。它充分利用了深度学习在特征提取和图像生成方面的优势,结合独特的网络结构和损失函数设计,实现了对大型掩模的高效和高质量修复。
LaMa能够在高分辨率图像的情况下,随意删除图像中的各种元素。最大的优势是支持自定义输入尺寸进行推理(而非必须固定输入尺寸)。
LaMa 在远高于训练时所见分辨率(~2k,相较于训练时的 256x256)下表现出更良好的泛化能力,并且即使在具有挑战性的场景(如周期性结构的补全)中也能取得出色的表现。
LaMa的训练全部是以配置文件.yaml的方式进行的,所以针对不同数据集的预训练模型所使用的yaml也是不同的。总体上作者是在PLACES和CelebA上进行了预训练,同时也包含了Big-Lama、Lama-fourier等多种模型细节的配置。
官方开源的模型中提供了一个名为Big-Lama的模型权重,效果最优。因为相比普通Lama,其生成器结构更复杂、训练数据规模更大。该模型是根据来自Places Challenge数据集的4.5M张图像的子集进行训练的,在八台NVidia V100 GPU上接受了约240小时的train。
二、环境
按照作者给的requirements.txt里面的库版本进行安装,hydra-core、pytorch-lightning、pillow、numpy、albumentations等最新版本在LaMa项目代码上均会报错无法运行。
系统:Ubuntu-22.04
Python:3.10
CUDA:11.8(cuda-repo-wsl-ubuntu-11-8-local_11.8.0-1_amd64)
CUDNN:8.9.7(cudnn-linux-x86_64-8.9.7.29_cuda11-archive)
PyTorch: 2.0.1
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia注:我在windows系统上配置环境失败
detectron2比较难安装成功,这里给出一个从源码安装的方法:
# 若安装失败,尝试从源码安装
git clone https://github.com/facebookresearch/detectron2.git
cd detectron2
pip install -e .验证安装是否成功
import detectron2
print(detectron2.__version__) # 应输出类似0.6gdal安装链接如下
https://github.com/cgohlke/geospatial-wheels/releases
下载对应的版本,使用下面的命名进行安装
pip install GDAL-3.4.3-cp310-cp310-win_amd64.whl
Package Version Editable project location
----------------------- ------------------ ------------------------------------------------
absl-py 2.2.2
aiohappyeyeballs 2.6.1
aiohttp 3.11.16
aiosignal 1.3.2
albucore 0.0.23
albumentations 0.5.2
annotated-types 0.7.0
antlr4-python3-runtime 4.8
async-timeout 5.0.1
attrs 25.3.0
black 25.1.0
braceexpand 0.1.7
Brotli 1.0.9
causal-conv1d 1.0.0
certifi 2025.1.31
charset-normalizer 3.3.2
click 8.1.8
cloudpickle 3.1.1
cmake 4.0.0
contourpy 1.3.1
cycler 0.12.1
detectron2 0.6 /home/qqxt/image-inpainting/lama-main/detectron2
easydict 1.13
einops 0.8.1
filelock 3.17.0
fonttools 4.57.0
frozenlist 1.5.0
fsspec 2025.3.2
future 1.0.0
fvcore 0.1.5.post20221221
gmpy2 2.2.1
grpcio 1.71.0
huggingface-hub 0.30.2
hydra-core 1.1.0
idna 3.7
imageio 2.37.0
imgaug 0.4.0
iopath 0.1.9
Jinja2 3.1.6
joblib 1.4.2
kiwisolver 1.4.8
kornia 0.8.0
kornia_rs 0.1.8
lazy_loader 0.4
lit 18.1.8
mamba-ssm 1.0.1
Markdown 3.8
MarkupSafe 3.0.2
matplotlib 3.10.1
mkl_fft 1.3.11
mkl_random 1.2.8
mkl-service 2.4.0
mpmath 1.3.0
multidict 6.4.3
mypy-extensions 1.0.0
networkx 3.4.2
ninja 1.11.1.4
numpy 1.23.5
omegaconf 2.1.2
opencv-python 4.11.0.86
opencv-python-headless 4.11.0.86
packaging 24.2
pandas 2.2.3
pathspec 0.12.1
pillow 11.1.0
pip 25.0
platformdirs 4.3.7
portalocker 3.1.1
propcache 0.3.1
protobuf 6.30.2
pycocotools 2.0.8
pydantic 2.11.3
pydantic_core 2.33.1
pyparsing 3.2.3
PySocks 1.7.1
python-dateutil 2.9.0.post0
pytorch-lightning 1.2.9
pytz 2025.2
PyYAML 6.0.2
regex 2024.11.6
requests 2.32.3
safetensors 0.5.3
scikit-image 0.25.2
scikit-learn 1.6.1
scipy 1.15.2
setuptools 75.8.0
shapely 2.1.0
simsimd 6.2.1
six 1.17.0
stringzilla 3.12.4
sympy 1.13.3
tabulate 0.9.0
tensorboard 2.19.0
tensorboard-data-server 0.7.2
termcolor 3.0.1
threadpoolctl 3.6.0
tifffile 2025.3.30
tokenizers 0.21.1
tomli 2.2.1
torch 2.0.1
torchaudio 2.0.2
torchmetrics 0.2.0
torchvision 0.15.2
tqdm 4.67.1
transformers 4.51.2
triton 2.0.0
typing_extensions 4.12.2
typing-inspection 0.4.0
tzdata 2025.2
urllib3 2.3.0
webdataset 0.2.111
Werkzeug 3.1.3
wheel 0.45.1
yacs 0.1.8
yarl 1.19.0
上面是我配置的虚拟环境情况,可以作为参考,在训练的时候会出现警告,但仍然可以有效训练。
三、数据集制作
-
数据集的路径和结构主要在 LaMa 的配置文件(通常是 .yaml 文件)中定义,例如 configs/training/location/ 目录下的配置文件。
-
训练、验证和测试集通常位于同一个主数据目录下,并分别存放在名为 train、val 和 test(或类似名称,如 visual_test, evaluation)的子目录中
1.训练数据集
一个包含所有训练图像的文件夹(注:LaMa 在训练过程中通常是动态生成掩码的(例如,随机生成各种形状和大小的掩码),所以训练集目录一般不包含预定义的掩码文件。训练配置会指定掩码生成策略)。本博客下文中讲到的数据集制作方法生成的训练集就是没有掩码的。
2.验证数据集
验证时,有时也使用动态生成的掩码,但为了评估的稳定性和可重复性,更常见的是使用预定义的一组图像和对应的掩码。
3.测试数据集
测试集几乎总是使用预定义的图像和掩码对,以确保评估的公平性和一致性。结构通常包含分开存放图像和掩码的子目录,或者将图像和掩码放在同一目录下并按文件名对应
示例结构 (常见方式):
<test_data_root_dir>/ # 例如 LaMa_test_images
images/ # 或者直接放在根目录,没有 images 子目录
test_image_001.png
test_image_002.png
...
masks/ # 对应的掩码,文件名通常与图像名一致或有规律对应
test_image_001.png # 掩码文件名可能与图像名相同
test_image_002.png
...或者 (图像和掩码在同一目录,推理脚本通常需要指定图像和掩码的路径模式):
<test_data_root_dir>/
test_image_001.png
test_image_001_mask.png # 掩码可能有后缀
test_image_002.png
test_image_002_mask.png
...官方提供的 LaMa_test_images 压缩包解压后,通常直接包含图像和对应的掩码(通常掩码文件名带有 _mask 后缀或存放在 masks 子目录)
下面是 官方提供的 LaMa_test_images 压缩包解压后的情况
下面是我自己制作的
4.下载Places365-Standard数据
训练集(105GB)、测试集(19GB)和验证集(2.1GB)
wget http://data.csail.mit.edu/places/places365/train_large_places365standard.tar
wget http://data.csail.mit.edu/places/places365/val_large.tar
wget http://data.csail.mit.edu/places/places365/test_large.tar我是自己制作自己的数据集,并将数据集中三个文件夹的名字设置成与Places365-Standard的一样,即train_large_places365standard(训练集)、val_large(验证集)、test_large(测试集)。在后续的转换中我发现数据集中的图像格式最好都是jpg的,不然在使用下面的命令之后无法生成掩码。
下载的三个压缩包如下(如果是自己的数据集,也压缩为tar格式):
# 压缩包存放在lama-main文件夹内
train_large_places365standard.tar
val_large.tar
test_large.tar5.解包并配置数据
在lama-main文件夹中创建一个名为places_standard_dataset的文件夹,依次运行下面的命令
bash fetch_data/places_standard_train_prepare.sh
bash fetch_data/places_standard_test_val_prepare.sh下面是执行命令之后的输出
上面的图片只是示例,并不是我真实使用的数据集
6.样本图像与掩膜生成
bash fetch_data/places_standard_test_val_sample.sh
# 可以在places_standard_test_val_gen_masks更改脚本
bash fetch_data/places_standard_test_val_gen_masks.sh4月27号更新:我原先的数据集大小是512x512大小的,现在(第二次训练)数据集大小是256x256的。此时在掩膜生成的时候就需要修改第二条命令:
bash fetch_data/places_standard_test_val_gen_masks.sh
将places_standard_test_val_gen_masks.sh里面的random_thick_512.yaml(两个地方)改为random_thick_256.yaml。修改完之后执行命令即可。
修改前
mkdir -p places_standard_dataset/val/
mkdir -p places_standard_dataset/visual_test/
python3 bin/gen_mask_dataset.py \
$(pwd)/configs/data_gen/random_thick_512.yaml \
places_standard_dataset/val_hires/ \
places_standard_dataset/val/
python3 bin/gen_mask_dataset.py \
$(pwd)/configs/data_gen/random_thick_512.yaml \
places_standard_dataset/visual_test_hires/ \
places_standard_dataset/visual_test/修改后
mkdir -p places_standard_dataset/val/
mkdir -p places_standard_dataset/visual_test/
python3 bin/gen_mask_dataset.py \
$(pwd)/configs/data_gen/random_thick_256.yaml \
places_standard_dataset/val_hires/ \
places_standard_dataset/val/
python3 bin/gen_mask_dataset.py \
$(pwd)/configs/data_gen/random_thick_256.yaml \
places_standard_dataset/visual_test_hires/ \
places_standard_dataset/visual_test/下面是执行命令之后的输出

运行完即可,在places_standard_dataset文件夹中可以看到结果
7.以下内容是网上了解的
7.1 val_hires文件夹
hires 是 high resolution(高分辨率)的缩写。这个目录有可能是一个高分辨率版本的验证集。它可能包含与 val 目录中图像对应的更高分辨率版本,或者是一个独立的高分辨率验证图像集。其用途可能包括:
-
专门评估模型在高分辨率图像上的修复效果。
-
用于某些需要高分辨率输入的特定评估流程或模型变体。
-
在标准验证(可能在较低分辨率上进行以节省时间)之外,提供更细致的视觉质量评估。
-
它属于验证阶段的一部分,但侧重于高分辨率场景。
7.2 visual_test 文件夹
visual_test 指的是“可视化测试”。这个目录是用于模型训练完成后进行最终性能评估的测试集。与验证集不同,测试集的结果不应该用于指导模型训练或选择过程,而仅仅是为了报告模型在完全未见过的数据上的最终表现。"visual"(可视化)可能暗示这个集合特别适合用于生成修复结果图像,供人眼直观评估修复质量,当然它也完全可以用来计算定量的评估指标。这是主要的测试数据集。进行预测(predict.py)或评估(evaluate_predicts.py)时,通常会指定使用这个目录下的图像,并且往往需要配合预定义的掩码(Masks)一起使用(掩码文件可能在同一目录,或在单独的 masks 目录,或根据文件名规则查找)。
7.3 visual_test_hires 文件夹
visual_test_hires 。类似于 val_hires,这个目录很可能是一个高分辨率版本的测试集。它用于在模型训练完成后,专门评估模型在高分辨率图像上的最终测试性能,同样常用于生成高分辨率的可视化结果。它与 visual_test 一样,属于测试阶段,但专注于高分辨率场景。
四、配置文件讲解
1.lama-main/configs/training/trainer中的三个配置文件
(1)lama-main/configs/training/trainer/any_gpu_large_ssim_ddp_final.yaml
# @package _group_ 表示此配置属于某个特定的包或组。
kwargs:
gpus: -1 # 使用所有可用的GPU。
accelerator: ddp # 使用分布式数据并行(DDP)进行训练。
max_epochs: 40 # 最大训练轮数为40。
gradient_clip_val: 1 # 梯度裁剪值,防止梯度爆炸。
log_gpu_memory: None # 设置为 min_max 或 all 用于调试。记录GPU内存使用情况以供调试。
limit_train_batches: 25000 # 最大训练批次数量为25000。
# val_check_interval: ${trainer.kwargs.limit_train_batches} # 验证检查间隔。当前被注释掉。
# fast_dev_run: True # 解除注释以实现更快的调试模式。启用快速开发模式以加速调试。
# track_grad_norm: 2 # 解除注释以跟踪L2梯度范数。跟踪L2梯度范数以供调试。
log_every_n_steps: 250 # 每250步记录一次指标和梯度。
precision: 32 # 训练精度。当前设置为32位精度。
# precision: 16 # 解除注释以使用16位精度。
# amp_backend: native # 解除注释以使用原生AMP后端。
# amp_level: O1 # 解除注释以设置AMP优化级别为O1。
# resume_from_checkpoint: path # 通过命令行覆盖路径以恢复检查点。指定恢复训练的检查点路径。
terminate_on_nan: False # 如果遇到NaN值,则终止训练。
# auto_scale_batch_size: True # 解除注释以找到最大的批量大小。自动调整批量大小以找到最大可能的批量大小。
check_val_every_n_epoch: 1 # 每1个epoch执行一次验证。
num_sanity_val_steps: 8 # 在开始训练之前,执行8步验证作为合理性检查。
# limit_val_batches: 1000000 # 最大验证批次数量。当前被注释掉。
replace_sampler_ddp: False # 是否在使用DDP时替换采样器。
checkpoint_kwargs:
verbose: True # 启用详细模式以显示检查点信息。
save_top_k: 5 # 根据指定的监控指标保存表现最好的前5个模型。
save_last: True # 保存最后一个模型。
period: 1 # 检查和保存模型的时间间隔为1。
monitor: val_ssim_fid100_f1_total_mean # 监控的指标名称。
mode: max # 根据最大化监控指标保存模型。该配置文件适合处理非规则几何形状的破损区域修复
(2)lama-main/configs/training/trainer/any_gpu_large_ssim_ddp_final_benchmark.yaml
多GPU支持(ddp(Distributed Data Parallel)表明使用PyTorch分布式训练框架)
anyGPU表示配置文件适配不同显存容量显卡
基准测试场景下的标准训练配置
典型用途:模型性能横向对比测试
(3)lama-main/configs/training/trainer/any_gpu_large_ssim_ddp_final_celeba.yaml
CelebA特指使用CelebA人脸数据集,CelebA人脸数据集专用配置
人脸图像修复专项训练
适用场景:人脸图像修复专项训练
2.lama-main/configs/training中的配置文件
(1)ABL-V2实验组配置(ablv2_record_*)
如:ablv2_work_no_segmpl_csirpl_celeba_csirpl03_new.yaml
测试多尺度注意力机制在CelebA数据集上的融合效果
(2)BIG-LAMA系列配置
big-lama-regular-celeba.yaml # 标准版模型
big-lama-fourier-celeba.yaml # 傅里叶域增强版- 架构差异:
regular: 基础卷积+注意力模块fourier: 集成Fast Fourier Convolution层(参考FFC论文)
- 参数量级:
big前缀表明参数量在200M以上(基础版约150M)
特别地,这里详解big-lama.yaml和big-lama-regular.yaml的区别:
(a)生成器架构(Generator)
-
big-lama.yaml
使用ffc_resnet作为生成器类型,这是LaMa论文中提出的核心创新模块,包含 快速傅里叶卷积(FFC) 和 大感受野感知损失。其关键参数包括:
generator:
kind: ffc_resnet
n_blocks: 18 # 更深的网络结构
resnet_conv_kwargs:
ratio_gin: 0.75 # 傅里叶通道比例
enable_lfu: false # 低频单元控制该设计通过傅里叶卷积扩大感受野,适合处理大尺寸掩膜(如论文中256x256训练后泛化到2k分辨率)
-
big-lama-regular.yaml
使用传统生成器pix2pixhd_global(基于全卷积网络),参数为:
generator:
kind: pix2pixhd_global
n_blocks: 15 # 较浅的网络结构
conv_kind: default # 普通卷积层此架构缺乏FFC模块,感受野受限,可能在大掩膜修复时表现较弱。
(b)训练目标与损失函数
-
big-lama.yaml
通过resnet_pl损失(权重30)强化感知质量,与论文中的 高感受野感知损失 一致。同时:
losses:
adversarial:
kind: r1 # 使用R1正则化的对抗损失更复杂的对抗训练策略有助于生成细节更逼真的修复结果。
-
big-lama-regular.yaml
虽然损失函数部分与前者相同,但由于生成器架构差异,实际训练时无法充分利用FFC带来的全局上下文建模能力,可能导致修复区域与周围内容的一致性下降。
3. 网络深度与参数配置
big-lama.yaml的n_blocks为18层,而big-lama-regular.yaml为15层。更深的网络能捕捉更复杂的纹理和结构信息,尤其适合大掩膜修复。
(3)评估配置文件(eval*)
eval2_gpu.yaml # GPU加速评估(batch_size=64)
eval2_cpu.yaml # CPU兼容模式(batch_size=8)
eval2_jpg.yaml # JPEG压缩伪影专项测试
eval2_segm_test.yaml # 分割引导掩膜评估五、LaMa模型训练
1.训练命令
python train.py -cn lama-fourier location=places_standard data.batch_size=10(a)-cn 参数的含义
定义:-cn 是 --config-name 的缩写,用于指定 主配置文件名称
作用:该参数会加载项目配置目录(通常是 config 文件夹)下名为 big-lama-regular.yaml 的配置文件。该文件定义了模型架构、损失函数、优化器等核心参数
扩展用法:-cn 可快速切换不同的实验配置(例如 big-lama.yaml 与 big-lama-regular.yaml 的区别在于生成器架构选择 ffc_resnet 或 pix2pixhd_global)
(b)data.batch_size 参数的含义
定义:data.batch_size 控制 每个训练步骤(step)中送入模型的样本数量。
作用与影响:显存占用:Batch_size 越大,单次计算所需显存越高(网页7提到显存不足时应减小该值;收敛速度:较大的 batch_size 通常能加速训练(更多样本参与梯度计算),但可能降低模型泛化能力(网页8指出过大的 batch_size 可能导致陷入局部最优;训练稳定性:较小的 batch_size(如10)会使梯度更新更频繁,噪声更多,但可能增强模型鲁棒性(网页7中讨论的 loss 震荡问题
优化建议:根据 GPU 显存调整(例如 V100 16GB 可尝试 batch_size=16-32);若训练不稳定(loss 震荡),可尝试 梯度累积(通过 gradient_accumulation_steps 参数模拟大 batch_size 效果,参考网页5中训练参数配置
(c)补充说明
参数覆盖机制:Hydra 框架允许通过 key=value 格式覆盖配置文件中的默认值(例如 location=places_standard 覆盖数据集路径配置)。
LaMa 相关配置:在 LaMa 的配置文件中(如 big-lama-regular.yaml),data.batch_size 默认值可能为其他数值(需查看具体文件),而命令行参数 data.batch_size=10 会直接覆盖该值。
其实我挺好奇为什么data.batch_size的值为什么可以为10。GPU 的并行计算架构对 2 的幂次方数值更友好(如 2,4,8,16,32,64),因其内存对齐和矩阵运算效率较高,所以深度学习模型的训练一般要求为2的幂次方。我网上了解了一下,说这并非强制要求,有实际测试表明非 2 幂次值(如 10、12)的性能差异通常较小。
2.train.py代码
我将lama-main/bin文件夹中的train.py脚本文件复制粘贴到了lama-main文件夹中,train.py文件一般不用做修改。
注意:这里@hydra.main(config_path='../lama-main/configs/training', config_name='lama-fourier.yaml')可能需要根据自己的路径情况进行修改,看报错输出进行修改即可
#!/usr/bin/env python3
import logging
import os
import sys
import traceback
os.environ['OMP_NUM_THREADS'] = '1'
os.environ['OPENBLAS_NUM_THREADS'] = '1'
os.environ['MKL_NUM_THREADS'] = '1'
os.environ['VECLIB_MAXIMUM_THREADS'] = '1'
os.environ['NUMEXPR_NUM_THREADS'] = '1'
import hydra
from omegaconf import OmegaConf
from pytorch_lightning import Trainer
from pytorch_lightning.callbacks import ModelCheckpoint
from pytorch_lightning.loggers import TensorBoardLogger
from pytorch_lightning.plugins import DDPPlugin
from saicinpainting.training.trainers import make_training_model
from saicinpainting.utils import register_debug_signal_handlers, handle_ddp_subprocess, handle_ddp_parent_process, \
handle_deterministic_config
LOGGER = logging.getLogger(__name__)
@handle_ddp_subprocess()
# config_path可能需要根据自己的路径情况修改,看报错输出进行修改即可
@hydra.main(config_path='../lama-main/configs/training', config_name='lama-fourier.yaml')
def main(config: OmegaConf):
try:
need_set_deterministic = handle_deterministic_config(config)
if sys.platform != 'win32':
register_debug_signal_handlers() # kill -10 <pid> will result in traceback dumped into log
is_in_ddp_subprocess = handle_ddp_parent_process()
config.visualizer.outdir = os.path.join(os.getcwd(), config.visualizer.outdir)
if not is_in_ddp_subprocess:
LOGGER.info(OmegaConf.to_yaml(config))
OmegaConf.save(config, os.path.join(os.getcwd(), 'config.yaml'))
checkpoints_dir = os.path.join(os.getcwd(), 'models')
os.makedirs(checkpoints_dir, exist_ok=True)
# there is no need to suppress this logger in ddp, because it handles rank on its own
metrics_logger = TensorBoardLogger(config.location.tb_dir, name=os.path.basename(os.getcwd()))
metrics_logger.log_hyperparams(config)
training_model = make_training_model(config)
trainer_kwargs = OmegaConf.to_container(config.trainer.kwargs, resolve=True)
if need_set_deterministic:
trainer_kwargs['deterministic'] = True
trainer = Trainer(
# there is no need to suppress checkpointing in ddp, because it handles rank on its own
callbacks=ModelCheckpoint(dirpath=checkpoints_dir, **config.trainer.checkpoint_kwargs),
logger=metrics_logger,
default_root_dir=os.getcwd(),
**trainer_kwargs
)
trainer.fit(training_model)
except KeyboardInterrupt:
LOGGER.warning('Interrupted by user')
except Exception as ex:
LOGGER.critical(f'Training failed due to {ex}:\n{traceback.format_exc()}')
sys.exit(1)
if __name__ == '__main__':
main()
3.lama-fourier.yaml配置文件
lama-fourier是指lama-main/configs/training路径中的lama-fourier.yaml配置文件
注意:需要提前下载encoder_epoch_20.pth(损失函数预训练权重)权重并设置好路径。下载最后存放在路径lama-main\models\ade20k\ade20k-resnet50dilated-ppm_deepsup中,即

代码中设置路径如下(到models文件夹即可):
# 损失函数预训练权重的路径
weights_path: "/home/qqxt/image-inpainting/lama-main/models" # ${env:TORCH_HOME}# 定义运行的标题,留空以待后续指定
run_title: ''
# 配置模型训练的相关参数
training_model:
# 指定模型的类型为默认类型
kind: default
# 每1000次迭代后生成可视化结果
visualize_each_iters: 100
# 是否在输出时合并掩码图像
concat_mask: true
# 是否存储判别器输出以用于可视化
store_discr_outputs_for_vis: true
# 定义损失函数及其权重
losses:
# L1损失,用于度量预测图像与真实图像的差异
l1:
# 缺失区域的损失权重设为0,表示不考虑此部分损失
weight_missing: 0
# 已知区域的损失权重设为10,强调已知区域的重建质量
weight_known: 10
# 感知损失,用于捕捉高级特征,当前未使用
perceptual:
weight: 0
# 对抗损失,推动生成器生成更真实的图像
adversarial:
# 使用R1类型的对抗损失
kind: r1
# 对抗损失的权重
weight: 10
# 梯度惩罚系数,用于稳定训练
gp_coef: 0.001
# 将掩码作为假目标,以指导生成器
mask_as_fake_target: true
# 允许缩放掩码,以适应不同尺度的输入
allow_scale_mask: true
# 特征匹配损失,帮助生成器产生具有相似特征的图像
feature_matching:
weight: 100
# resnet持久化损失,用于保持图像的细节
resnet_pl:
weight: 30
# 损失函数预训练权重的路径
weights_path: "/home/qqxt/image-inpainting/lama-main/models" # ${env:TORCH_HOME}
# 默认配置列表,定义了多个组件的默认设置
defaults:
- _self_ # 声明自身配置的继承优先级[7](@ref)
- location: docker
- data: abl-04-256-mh-dist
- generator: ffc_resnet_075
- discriminator: pix2pixhd_nlayer
- optimizers: default_optimizers
- visualizer: directory
- evaluator: default_inpainted
- trainer: any_gpu_large_ssim_ddp_final
- hydra: overrides我自己的数据集太小,图像数量不足,将 visualize_each_iters从1000改为了100。
4.places_standard.yaml配置文件
places_standard是指/lama-main/configs/training/location中的places_standard.yaml配置文件。下面是我使用的配置文件
package: _group_
data_root_dir: /home/qqxt/image-inpainting/lama-main/places_standard_dataset
out_root_dir: /home/qqxt/image-inpainting/lama-main/experiments/
tb_dir: /home/qqxt/image-inpainting/lama-main/tb_logs/
pretrained_models: /home/qqxt/image-inpainting/lama-main/places_standard.yaml配置文件中的内容似乎在制作数据集的时候会自动生成(还没有仔细核查过),所有在训练的时候可能报错,报错的话检查这个配置文件的内容,看看内容是不是多了
下面是原始places_standard.yaml配置文件
# @package _group_
data_root_dir: /home/user/inpainting-lama/places_standard_dataset/
out_root_dir: /home/user/inpainting-lama/experiments
tb_dir: /home/user/inpainting-lama/tb_logs
pretrained_models: /home/user/inpainting-lama/我将# @package _group_修改为了package: _group_。(如何加载预训练权重我还在测试当中)
5.any_gpu_large_ssim_ddp_final.yaml配置文件
该配置文件位于lama-main/configs/training/trainer下,
# 表示此配置属于某个特定的包或组。
# @package _group_
kwargs:
gpus: -1 # 使用所有可用的GPU。
accelerator: ddp # 使用分布式数据并行(DDP)进行训练。
max_epochs: 100 # 最大训练轮数为40。
gradient_clip_val: 1 # 梯度裁剪值,防止梯度爆炸。
log_gpu_memory: None # 设置为 min_max 或 all 用于调试。记录GPU内存使用情况以供调试。
limit_train_batches: 25000 # 最大训练批次数量为25000。
# 验证检查间隔。当前被注释掉。
# val_check_interval: ${trainer.kwargs.limit_train_batches}
# 解除注释以实现更快的调试模式。启用快速开发模式以加速调试。
# fast_dev_run: True # uncomment for faster debug
# 解除注释以跟踪L2梯度范数。跟踪L2梯度范数以供调试。
# track_grad_norm: 2 # uncomment to track L2 gradients norm
log_every_n_steps: 250 # 每250步记录一次指标和梯度。
precision: 32 # 训练精度。当前设置为32位精度。
# precision: 16 # 解除注释以使用16位精度。
# amp_backend: native # 解除注释以使用原生AMP后端。
# amp_level: O1 # 解除注释以设置AMP优化级别为O1。
# 通过命令行覆盖路径以恢复检查点。指定恢复训练的检查点路径。
# resume_from_checkpoint: path # override via command line trainer.resume_from_checkpoint=path_to_checkpoint
# 如果遇到NaN值,则终止训练。
terminate_on_nan: False
# 解除注释以找到最大的批量大小。自动调整批量大小以找到最大可能的批量大小。
# auto_scale_batch_size: True # uncomment to find largest batch size
# 每1个epoch执行一次验证。
check_val_every_n_epoch: 1
# 在开始训练之前,执行8步验证作为合理性检查。
num_sanity_val_steps: 8
# 最大验证批次数量。当前被注释掉。
# limit_val_batches: 1000000
# 是否在使用DDP时替换采样器。
replace_sampler_ddp: False
checkpoint_kwargs:
verbose: True # 启用详细模式以显示检查点信息。
save_top_k: 5 # 根据指定的监控指标保存表现最好的前5个模型。
save_last: True # 保存最后一个模型。
period: 1 # 检查和保存模型的时间间隔为1。
monitor: val_ssim_fid100_f1_total_mean # 监控的指标名称。
mode: max # 根据最大化监控指标保存模型。修改max_epochs为自己需要的训练轮数。
六、LaMa模型验证
1 验证命令以后再补充(因为我还没看懂......)
在训练的时候有验证输出
[2025-04-22 13:09:21,770][saicinpainting.training.trainers.base][INFO] - Validation metrics after epoch #199, total 69399 iterations:
ssim lpips fid ssim_fid100_f1
mean std mean std mean mean
0-10% 0.967817 0.017678 0.028346 0.012440 6.686008 NaN
10-20% 0.913807 0.031680 0.076306 0.017663 18.378413 NaN
20-30% 0.855455 0.047373 0.129790 0.019880 30.118225 NaN
30-40% 0.804447 0.053882 0.179277 0.020653 40.386344 NaN
40-50% 0.737072 0.068769 0.233439 0.024463 53.657197 NaN
total 0.849281 0.091467 0.135212 0.072386 17.620312 0.835845在训练的时候的测试输出
[2025-04-22 13:10:28,157][saicinpainting.training.trainers.base][INFO] - Test metrics after epoch #199, total 69399 iterations:
ssim lpips fid ssim_fid100_f1
mean std mean std mean mean
0-10% 0.968023 0.017938 0.028223 0.013524 5.946503 NaN
10-20% 0.916305 0.029018 0.077825 0.016502 14.151865 NaN
20-30% 0.854883 0.045015 0.128413 0.018943 24.167353 NaN
30-40% 0.803578 0.057882 0.178522 0.020908 32.791396 NaN
40-50% 0.738225 0.074371 0.233865 0.024189 44.287522 NaN
total 0.850045 0.090942 0.135008 0.070524 12.771710 0.8605212.核心评估指标解析
2.1 SSIM(结构相似性指数)
定义:衡量修复图像与真实图像在亮度、对比度、结构三方面的相似性,范围在0到1之间,值越高表示结构越接近。
意义:高SSIM值反映模型能有效恢复图像的整体轮廓和纹理结构。
2.2 LPIPS(学习感知图像块相似度)
定义:基于深度学习特征提取的感知相似性指标,值越低表示人眼感知差异越小。
意义:低LPIPS值说明修复结果在细节上更符合人类视觉感知,尤其在纹理和边缘处理上较优。
2.3 FID(弗雷歇初始距离)
定义:评估修复图像与真实图像在特征分布上的差异,值越低表示分布越接近。
意义:低FID值反映模型生成图像的多样性和真实性较好,尤其在整体分布层面。
七、LaMa模型推理
1.推理命令
python predict.py model.path=/home/qqxt/image-inpainting/lama-main/lama-fourier indir=/home/qqxt/image-inpainting/lama-main/predict-images outdir=/home/qqxt/image-inpainting/lama-main/predict-results model.checkpoint=last.ckptmodel.path是指模型训练的时候生成的一个包含了config.yaml和权重的路径,比如说我在训练的时候会在experiments文件夹下生成一个qqxt_2025-04-17_23-17-12_train_lama-fourier_的文件夹(qqxt用户名,2025-04-17_23-17-12是时间戳,train是指训练,lama-fourier是指训练的模型),文件夹里面会有下面的内容
我在lama-main文件夹中新建了一个名为lama-fourier的文件夹,将qqxt_2025-04-17_23-17-12_train_lama-fourier_里面的文件(我测试了一下,只需要复制config.yaml配置文件和models文件夹即可)复制到了lama-fourier文件夹中,然后将model.path指向lama-fourier文件夹。当然也可以将model.path直接指向qqxt_2025-04-17_23-17-12_train_lama-fourier_,在我这里就是
model.path=/home/qqxt/image-inpainting/lama-main/experiments/qqxt_2025-04-17_23-17-12_train_lama-fourier_indir是指向需要预测的图像的输入路径(/home/qqxt/image-inpainting/lama-main/predict-images)
outdir是指向需要预测之后图像的输出路径(/home/qqxt/image-inpainting/lama-main/predict-results )
model.checkpoint是指向训练好的权重(last.ckpt),如果你想使用models里面的其他权重,修改权重名字即可,比如说model.checkpoint=epoch=51-step=28859.ckpt
运行推理命令之后,脚本会找到位于lama-fourier文件夹下的config.yaml配置文件(这个配置文件是训练脚本在运行的时候打印的最终的模型配置 (OmegaConf.to_yaml(config)) )和models文件夹中的名为last.ckpt的训练权重。
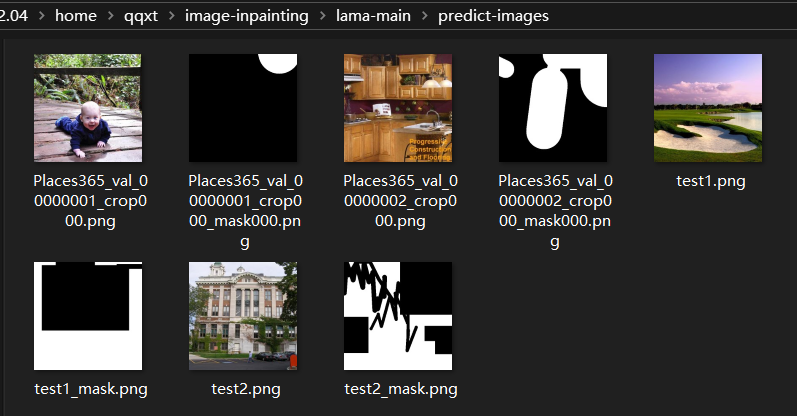
推理数据文件夹predict-images中存放的数据如下
2.predict.py代码
我将lama-main/bin文件夹中的predict.py脚本文件复制粘贴到了lama-main文件夹中,predict.py文件一般不用做修改。
#!/usr/bin/env python3
# Example command:
# ./bin/predict.py \
# model.path=<path to checkpoint, prepared by make_checkpoint.py> \
# indir=<path to input data> \
# outdir=<where to store predicts>
import logging
import os
import sys
import traceback
from saicinpainting.evaluation.utils import move_to_device
from saicinpainting.evaluation.refinement import refine_predict
os.environ['OMP_NUM_THREADS'] = '1'
os.environ['OPENBLAS_NUM_THREADS'] = '1'
os.environ['MKL_NUM_THREADS'] = '1'
os.environ['VECLIB_MAXIMUM_THREADS'] = '1'
os.environ['NUMEXPR_NUM_THREADS'] = '1'
import cv2
import hydra
import numpy as np
import torch
import tqdm
import yaml
from omegaconf import OmegaConf
from torch.utils.data._utils.collate import default_collate
from saicinpainting.training.data.datasets import make_default_val_dataset
from saicinpainting.training.trainers import load_checkpoint
from saicinpainting.utils import register_debug_signal_handlers
LOGGER = logging.getLogger(__name__)
@hydra.main(config_path='../configs/prediction', config_name='default.yaml')
def main(predict_config: OmegaConf):
try:
if sys.platform != 'win32':
register_debug_signal_handlers() # kill -10 <pid> will result in traceback dumped into log
device = torch.device("cpu")
train_config_path = os.path.join(predict_config.model.path, 'config.yaml')
with open(train_config_path, 'r') as f:
train_config = OmegaConf.create(yaml.safe_load(f))
train_config.training_model.predict_only = True
train_config.visualizer.kind = 'noop'
out_ext = predict_config.get('out_ext', '.png')
checkpoint_path = os.path.join(predict_config.model.path,
'models',
predict_config.model.checkpoint)
model = load_checkpoint(train_config, checkpoint_path, strict=False, map_location='cpu')
model.freeze()
if not predict_config.get('refine', False):
model.to(device)
if not predict_config.indir.endswith('/'):
predict_config.indir += '/'
dataset = make_default_val_dataset(predict_config.indir, **predict_config.dataset)
for img_i in tqdm.trange(len(dataset)):
mask_fname = dataset.mask_filenames[img_i]
cur_out_fname = os.path.join(
predict_config.outdir,
os.path.splitext(mask_fname[len(predict_config.indir):])[0] + out_ext
)
os.makedirs(os.path.dirname(cur_out_fname), exist_ok=True)
batch = default_collate([dataset[img_i]])
if predict_config.get('refine', False):
assert 'unpad_to_size' in batch, "Unpadded size is required for the refinement"
# image unpadding is taken care of in the refiner, so that output image
# is same size as the input image
cur_res = refine_predict(batch, model, **predict_config.refiner)
cur_res = cur_res[0].permute(1,2,0).detach().cpu().numpy()
else:
with torch.no_grad():
batch = move_to_device(batch, device)
batch['mask'] = (batch['mask'] > 0) * 1
batch = model(batch)
cur_res = batch[predict_config.out_key][0].permute(1, 2, 0).detach().cpu().numpy()
unpad_to_size = batch.get('unpad_to_size', None)
if unpad_to_size is not None:
orig_height, orig_width = unpad_to_size
cur_res = cur_res[:orig_height, :orig_width]
cur_res = np.clip(cur_res * 255, 0, 255).astype('uint8')
cur_res = cv2.cvtColor(cur_res, cv2.COLOR_RGB2BGR)
cv2.imwrite(cur_out_fname, cur_res)
except KeyboardInterrupt:
LOGGER.warning('Interrupted by user')
except Exception as ex:
LOGGER.critical(f'Prediction failed due to {ex}:\n{traceback.format_exc()}')
sys.exit(1)
if __name__ == '__main__':
main()
注意:这里@hydra.main(config_path='../configs/prediction', config_name='default.yaml')可能需要根据自己的路径情况进行修改,看报错输出进行修改即可
lama-main/configs/prediction中的default.yaml配置文件内容如下
indir: no # 需要在命令行界面(CLI)中覆盖此值
outdir: no # 需要在命令行界面(CLI)中覆盖此值
model:
path: no # 需要在命令行界面(CLI)中覆盖此值
checkpoint: best.ckpt # 模型的检查点文件名
dataset:
kind: default # 数据集类型,默认为“default”
img_suffix: .png # 图像文件的后缀,默认为“.png”
pad_out_to_modulo: 8 # 输出图像的填充对齐值
device: cuda # 使用的计算设备,默认为“cuda”(GPU)
out_key: inpainted # 输出结果的关键字,默认为“inpainted”
refine: False # 如果设置为True,将运行细化器
refiner:
gpu_ids: 0 # 使用的GPU ID,如果仅使用单个GPU,格式为“0,”
modulo: ${dataset.pad_out_to_modulo} # 继承自数据集配置的填充对齐值
n_iters: 15 # 每个尺度上的细化迭代次数
lr: 0.002 # 学习率
min_side: 512 # 图像在所有尺度上的一边应大于等于 min_side / sqrt(2)
max_scales: 3 # 图像-掩码金字塔的最大下采样尺度数
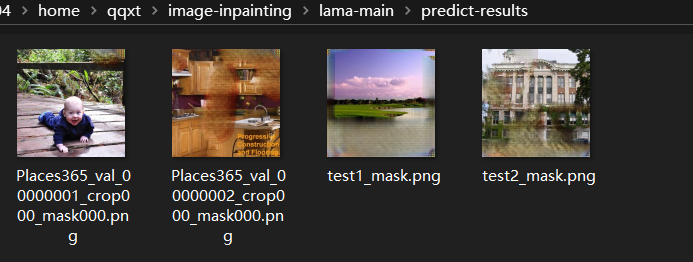
px_budget: 1800000 # 像素预算,任何图像都会调整大小以满足 height*width <= px_budget进行predict之后的结果如下
参考文献
https://gitcode.com/gh_mirrors/la/lama/?utm_source=artical_gitcode&index=bottom&type=card

















 2492
2492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









