







之所以要写这篇博客,是因为前几天在实现AdaBoost方法的过程中,想把感知机模型作为基分类器,但编码过程中才发现最原始的感知机学习算法仅仅对于线性可分的训练集是收敛的,而我所期望的基学习器要对线性不可分的训练集也是收敛的(或者说我希望的是数据集在线性不可分的情形下,通过有限次的迭代能使算法能够几乎分类准确)。通过这个小波折发现以前看书还是太囫囵吞枣了!
1、感知机算法原理
感知机是二分类的线性模型,其判别函数为:
f(x)=sign(w⋅x+b)
感知机模型对应于特征空间中的分离超平面 w⋅x+b=0 .
感知机学习的策略是极小化损失函数:
minw,bL(w,b)=−∑xi∈Myi(w⋅xi+b)
其几何意义是损失函数对应于误分类点到分离超平面的总距离。我们可以基于随机梯度下降法对损失函数进行极小化。
2、Matlab代码实现
function [w, me] = perceptron(x, y)
[m, n] = size(x);
x = [ones(m, 1), x]; %把输入数据写成增广矩阵的形式
w = rand(n + 1, 1); %增广权值向量
alpha = 1; %学习率
error = 0; %误差
eps = 0.01;
%T = 40; %迭代次数
while( 1 )
o = sign(x * w); %输出,需要注意的是matlab中sign(0)=0
o(o==0,:)=-1;
er =error;
me = o .* y; %输出lambel和目标label的点乘向量
mc = find(me == -1); %误分类样本点
error = -1 * sum(x(mc, :) * w .* y(mc, :));
if(size(mc,1) == 0||abs(error-er)<eps)
break;
end
j = mc(1,:);
w = w + alpha * y(j, :)*(x(j, :))'; %梯度下降法更新权值
% for i = 1:size(mc, 1)
% j = mc(i,:);
% w = w + alpha * y(j, :)*(x(j, :))' %梯度下降法更新权值
% end
%T = T-1;
end
%%如果特征向量是二维的,画图
if(n==2)
po = x(y==1, 2:end);
scatter(po(:, 1),po(:, 2));
hold on;
ne = x(y==-1, 2:end);
scatter(ne(:, 1),ne(:,2),'*');
hold on;
x = 1:.5:10;
y = 1/w(3)*(-1*w(1)-x.*w(2));
plot(x,y);
end运行结果:
x = [3,2;6,3;3,3;4,3;1,1]
y = [-1;-1;1;1;-1]
则分类超平面为:
−3.7823−5.9915x1+9.3006x2=0
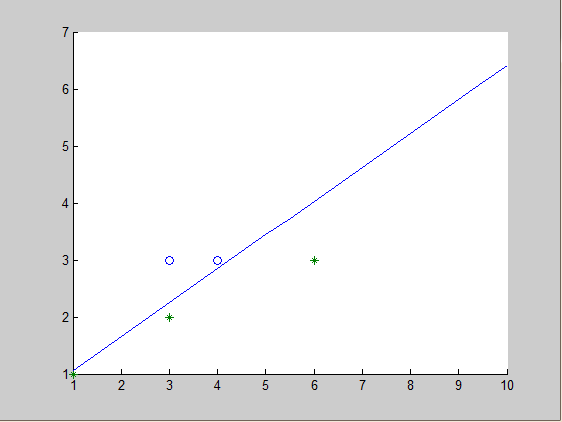
最后,值得思考的是当数据集线性不可分时,如何改进感知机算法使模型收敛,如同非线性支持向量机一样。















 3079
3079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









