






新建eshop-strom项目
1、kafka consumer spout
单独的线程消费,写入队列
nextTuple,每次都是判断队列有没有数据,有的话再去获取并发射出去,不能阻塞
2、日志解析bolt
3、商品访问次数统计bolt
基于LRUMap完成统计
1、storm task启动的时候,基于分布式锁将自己的taskid累加到一个znode中
2、开启一个单独的后台线程,每隔1分钟算出top3热门商品list
3、每个storm task将自己统计出的热数据list写入自己对应的znode中
1.服务启动的时候,进行缓存预热
2.从zk中读取taskid列表
3.一次遍历每个taskid,尝试获取分布式锁,如果获取不到,快速报错,不要等待,因为说明已经其他服务实例在预热了
4.直接尝试获取下一个taskid的分布式锁
5.即时获取到了分布式锁,也要检查一下这个taskid的预热状态,如果已经被预热过了,就不要再预热
6,执行预热操作,遍历productid列表,查询数据,然后写ehcache和redis
7.预热完成后,设置taskid对应的预热状态

将项目eshop-storm mvn package,打包产生
storm jar eshop-storm-0.0.1-SNAPSHOT.jar com.example.eshop.storm.HotProductTopology HotProductTopology
停止
storm kill HotProductTopology
执行zkCli.sh进入到zk客户端中
执行命令get
[zk: localhost:2181(CONNECTED) 0] get
ZooKeeper -server host:port cmd args
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:port
[zk: localhost:2181(CONNECTED) 1]
查看/taskid-list节点
[zk: localhost:2181(CONNECTED) 1] get /taskid-list
4,5 ---- 发现节点是4和5
cZxid = 0x700000785
ctime = Wed Aug 24 21:07:59 CST 2022
mZxid = 0x7000007a0
mtime = Wed Aug 24 21:08:09 CST 2022
pZxid = 0x700000785
cversion = 0
dataVersion = 2
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 0

执行步骤 1
1.启动三台节点的zk集群
2.启动三台节点的kafka集群
我的启动脚本是放在了node1上
sh start-zk.sh
sh start-kafka.sh
在node1上执行
storm nimbus >/dev/null 2>&1 &
然后在node1、node2、node3上执行
storm supervisor >/dev/null 2>&1 &
然后为了查看三个节点的日志输出,需要在node1、node2、node3上执行
storm logviewer >/dev/null 2>&1 &
然后在node1节点上启动界面
storm ui >/dev/null 2>&1 &
执行步骤2
将eshop-strom 编译打包产生jar,并将jar上传到node1的/usr/local下
[root@node1 local]# cd /usr/local/
[root@node1 local]# ll |grep storm
-rw-r--r--. 1 root root 27941176 8月 26 11:26 eshop-storm-0.0.1-SNAPSHOT.jar
drwxr-xr-x. 13 root root 268 8月 10 14:22 storm
[root@node1 local]#
将jar丢入到storm中
[root@node1 local]# storm jar eshop-storm-0.0.1-SNAPSHOT.jar com.example.eshop.storm.HotProductTopology HotProductTopology
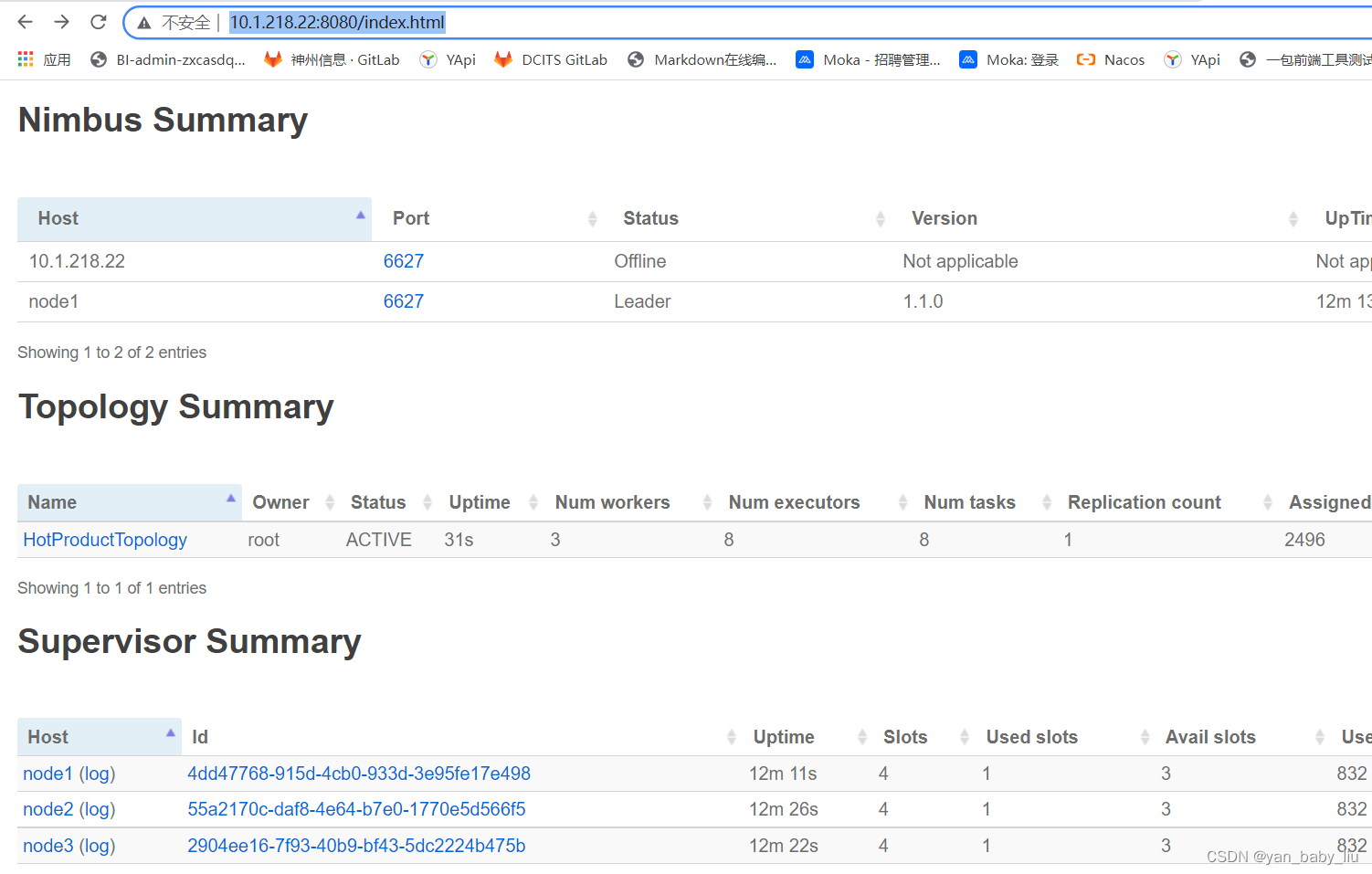
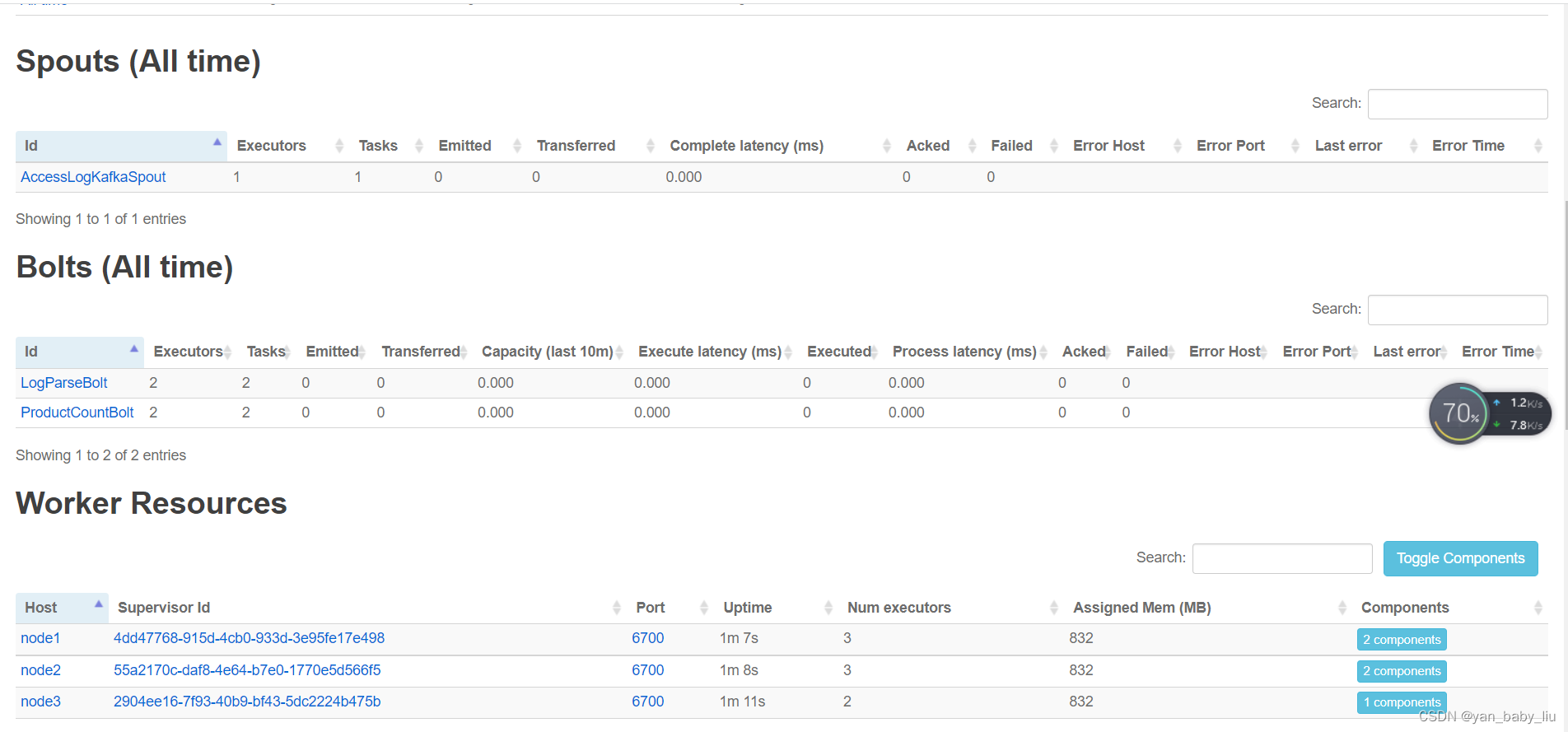
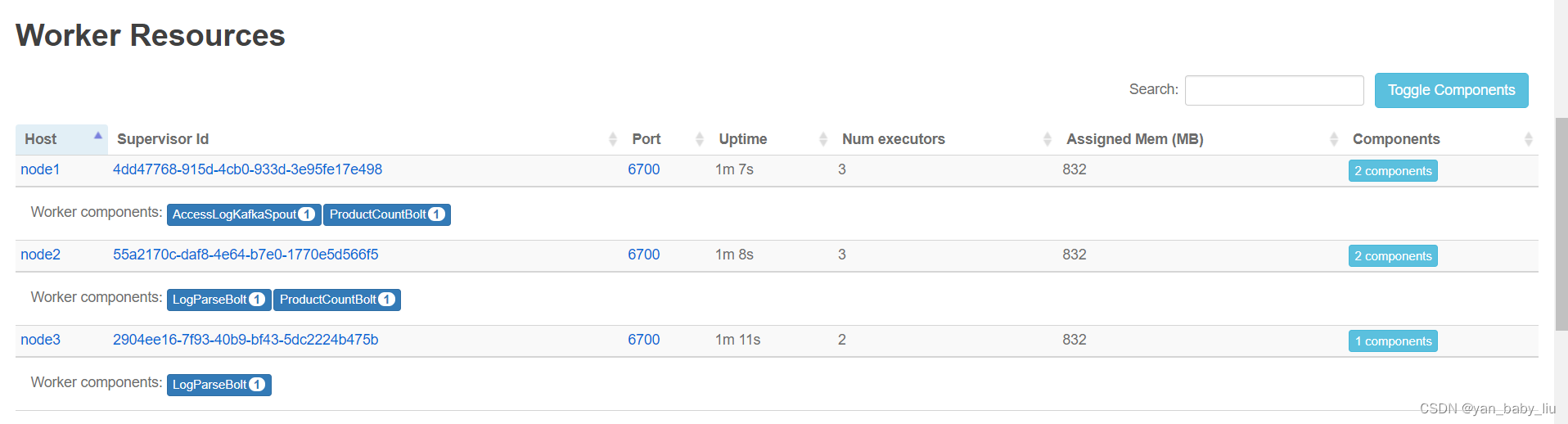
启动以后,访问界面
http://10.1.218.22:8080/index.html
点击HotProductTopology进去
在node1上,登录zkCli.sh
[zk: localhost:2181(CONNECTED) 0]
get /taskid-list
4,5
cZxid = 0x800000d3b
ctime = Fri Aug 26 12:16:41 CST 2022
mZxid = 0x800000d45
mtime = Fri Aug 26 12:16:43 CST 2022
pZxid = 0x800000d3b
cversion = 0
dataVersion = 2
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 0
如果之前已经启动过storm,运行过jar程序,那么/staskid-list会有历史数据 在启动jar程序以前,可以删除该节点
rmr /taskid-list
退出zkCli 用命令quit
正常情况,应该是访问nginx请求,由nginx的lua脚本发送访问产品的消息到kafka的topic :access-log中,lua发送出来的消息格式为:
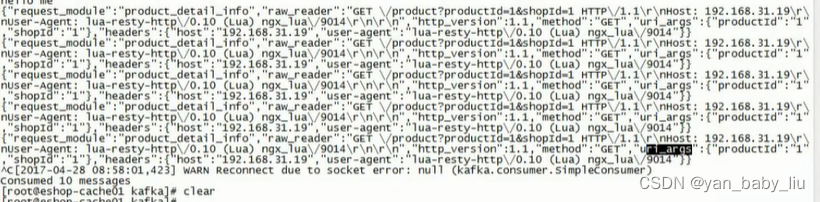
,但是由于我本地lua脚本发送的消息,无法到达kafka,所以,改为手动发送模拟消息到kafka上
public static void main(String[] args) throws IOException {
Properties props = new Properties();
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "10.1.218.22:9092");
ProducerConfig producerConfig = new ProducerConfig(props);
Producer kafkaProducer = new Producer(producerConfig);
// Use random partitioner. Don't need the key type. Just set it to Integer.
// The message is of type String.
JSONObject message = new JSONObject();
JSONObject productId = new JSONObject();
productId.put("productId", 2);
message.put("uri_args", productId);
kafkaProducer.send(new KeyedMessage("access-log", JSONObject.toJSONString(message)));
kafkaProducer.close();
System.in.read();
}
查看storm日志,发现已经开始统计了
业务流程: 1.请求发送到nginx,nginx的lua脚本发送请求商品的消息,到kafka,strom消费kafka中消息,并统计每个商品的访问次数,将热门商品id保存到zk中
2.storm的ProductCountBolt任务,每个任务启动,都会将自己的任务id追加添加到zk的/taskid-list节点中,例如我们设置了2个ProductCountBolt任务,则/taskid-list 保存为[4,5],每个ProductCountBolt任务zk中创建热门商品节点/ask-hot-product-list-{taskid}
例如:/task-hot-product-list-4 [3,5,7]
/task-hot-product-list-5 [2,4,6]
3.通过controller的方式,预热处理/task-hot-product-list-4、/task-hot-product-list-5节点的热门商品,将产品信息保存到redis和local cache中
git地址
https://gitee.com/yanweiling/redis-eshop-struct.git
预热入口 CacheTestController .prewarm()
热门商品统计 strom程序:eshop-storm
shell脚本
start-zk.sh内容
#!/bin/bash
for I in {node1,node2,node3}
do
echo "$I 上的zk 正在启动"
ssh root@$I "source /etc/profile; /usr/local/zk/bin/zkServer.sh start"
echo "$I 上的zk 启动成功"
done
--------------------------------------
start-kafka.sh内容
#!/bin/bash
KAFKA_HOME=/usr/local/kafka
for number in {1..3}
do
host=node${number}
echo ${host}
/usr/bin/ssh ${host} "cd ${KAFKA_HOME};source /etc/profile;${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties >>/dev/null 2>&1 &"
echo "${host} started"
done
stop-zk.sh
#!/bin/bash
for I in {node1,node2,node3}
do
echo "$I 上的kafka 正在关闭"
ssh root@$I "source /etc/profile; /usr/local/zk/bin/zkServer.sh stop"
echo "$I 上的kafka 关闭完成"
done
stop-kafka.sh
#!/bin/bash
KAFKA_HOME=/usr/local/kafka
for number in {1..3}
do
host=node${number}
echo ${host}
/usr/bin/ssh ${host} "cd ${KAFKA_HOME};source /etc/profile;${KAFKA_HOME}/bin/kafka-server-stop.sh"
echo "${host} stoped"
done
start-redis-cluster.sh
#!/bin/bash
for number in {1..3}
do
echo "关闭 node${number}上的redis port 6379"
server=node${number}
declare -i num1=$number*2-1
declare -i num2=$number*2
port1="700$num1"
port2="700$num2"
echo "${server}"
echo $port1 $port2
ssh root@$server "redis-cli -p 6379 -a 123456 shutdown"
ssh root@$server "cd /etc/init.d;./redis_$port1 start;./redis_$port2 start "
done















 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









