




 本文深入探讨了DOM的特性与操作方法,包括检测DOM支持、XML命名空间的变化、DOM节点的比较、样式设置与获取、DOM遍历与范围操作等核心内容。详细解析了如何在XHTML与SVG中使用命名空间,DOM3的节点比较方法,CSS样式的检测与应用,以及DOM遍历的多种方式和范围对象的使用技巧。
本文深入探讨了DOM的特性与操作方法,包括检测DOM支持、XML命名空间的变化、DOM节点的比较、样式设置与获取、DOM遍历与范围操作等核心内容。详细解析了如何在XHTML与SVG中使用命名空间,DOM3的节点比较方法,CSS样式的检测与应用,以及DOM遍历的多种方式和范围对象的使用技巧。
检测是否支持
document.implementation.hasFeature("Core", "2.0");
//true
document.implementation.hasFeature("Core", "3.0");
//true
document.implementation.hasFeature("HTML", "2.0");
//true
document.implementation.hasFeature("Views", "2.0");
//true
document.implementation.hasFeature("XML", "2.0");
//true
1.XML命名空间变化
使用XHTML
<html xmlns="http://www.w3.org/1999/xhtml"> //命名空间使用xmlns
<head>
<title>Example XHTML page</title>
</head>
<body>
Hello world!
</body>
</html>
在同时使用XHTML与SVG语言中
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Example XHTML page</title>
</head>
<body>
<svg xmlns="http://www.w3.org/2000/svg" version="1.1" viewBox="0 0 100 100" style="width:100%; height:100%">
<rect x="0" y="0" width="100" height="100" style="fill:red" />
</svg>
</body>
</html>
在这个例子中,通过设置命名空间,将<svg>标识为了与包含文档无关的元素。
此时,<svg>元素的所有子元素,以及这些元素的所有特性,
都被认为属于 http://www.w3.org/2000/svg 命名空间。
即使这个文档从技术上说是一个 XHTML文档,
但因为有了命名空间,其中的 SVG代码也仍然是有效的.
node类型变化
<html xmlns="http://www.w3.org/1999/xhtml">
//localName = "html";tagName = "html" namespaceURI="w3..1999..."; prefix = null
<head>
<title>Example XHTML page</title>
</head>
<body>
//localName = "svg"; tagName = "s:svg"; namespaceURI = "w3..2000...";prefix = "s"
<s:svg xmlns:s="http://www.w3.org/2000/svg" version="1.1"
viewBox="0 0 100 100" style="width:100%; height:100%">
<s:rect x="0" y="0" width="100" height="100" style="fill:red"/>
</s:svg>
</body>
</html>
DOM3比较节点方法
var div1 = document.createElement("div")
div1.setAttribute("class", "box")
var div2 = document.createElement("div")
div2.setAttribute("class", "box")
1.isSameNode()
div1.isSameNode(div2)
//falsej
div1.isSameNode(div1)
//true
2.isEqualNode()
div1.isEqualNode(div2)
//true
div1.isEqualNode(div1)
//true
样式
检测是否支持DOM2级定义的CSS能力
document.implementation.hasFeature("CSS", "2.0");
//true
document.implementation.hasFeature("CSS2", "2.0");
//true
设置style
element.style,backgroundColor = "red" //css中的短折线转换为驼峰形式
element.style.cssFloat = "left" //float在js中是保留字 需要用cssFloat
element.style.backgroundColor //red
在混杂模式下不设置度量单位 会自动加上px 而标准模式会忽略无单位量
cssText属性
为元素应用多项style属性 但是会将元素之前的所有style清除
eg:
<div id="app" style="background-color: aqua">
</div>
//js
app.style.border = "1px solid black"
app.style.cssText = "width: 25px; height: 100px; background-color: green"
//最后app上只有cssText的style
length getPropertyValue() removeProperty()
var prop,
value,
len = app.style.length
for (let i = 0; i < len; i++) {
prop = app.style[i]
value = app.style.getPropertyValue(prop)
console.log(`${prop} : ${value}`)
}
// background-color : aqua
// border-top-width : 1px
// border-right-width : 1px
// border-bottom-width : 1px //border属性过多未列举完....返回的属性都是css格式 带短折线
app.style.removeProperty("border") //""
计算样式 (只读)
#app {
background-color: red;
border: 1px sold blue;
width: 100px;
height: 100px;
}
<div id="app" style="background-color: aqua"></div> //rgb(0, 255, 255)
//js
app.style.border = "1px solid black"
var computedStyle = document.defaultView.getComputedStyle(app, null)
//在IE中使用 var computedStyle = app.currentStyle
//在IE中返回border都是undefined
//computedStyle.backgroundColor
//"rgb(0, 255, 255)"
//computedStyle.border
//"1px solid rgb(0, 0, 0)" //返回的颜色形式为rgb
操作样式表
检测是否支持DOM2级样式表
document.implementation.hasFeature("StyleSheets", "2.0")
//true
访问样式表
var sheet = null,
len = document.styleSheets.length
for (let i = 0; i < len; i++) {
sheet = document.styleSheets[i]
console.log(sheet.href) //只有通过link连接的样式表有href
}
取得样式表对象
const getStyleSheet = (element) => {
return element.sheet || element.styleSheet
}
var link = document.getElementsByTagName("link")[0]
//<link rel="stylesheet" href="index.css">
var sheet = getStyleSheet(link)
//CSSStyleSheet对象
元素大小
1.偏移量
偏移量,包括元素在屏幕上占用的所有可见的空间。元素
的可见大小由其高度、宽度决定,包括所有内边距、滚动条和边框大小(注意,不包括外边距)
取得元素的左偏移量(其他方向修改offsetLeft即可)
const getElementLeft = (element) => {
let actualLeft = element.offsetLeft,
current = element.offsetParent
while (current !== null) {
actualLeft += current.offsetLeft
current = current.offsetParent
}
return actualLeft
}
//利用 offsetParent 属性在 DOM 层次中逐级向上回溯,将每个层次中的偏移量属性
//合计到一块
//对于使用表格和内嵌框架布局的页面 不大精确
2.客户区大小 = 元素内边距 + 内容 (padding + content)
clientWidth clientHeight 分别返回对应值
客户区大小就是元素内部的空间大小,因此滚动条占用的空间不计算在内
document.body.clientWidth //可获取视口的宽 IE7
document.documentElement.clientHeight //多数浏览器 获取高度
3.滚动大小
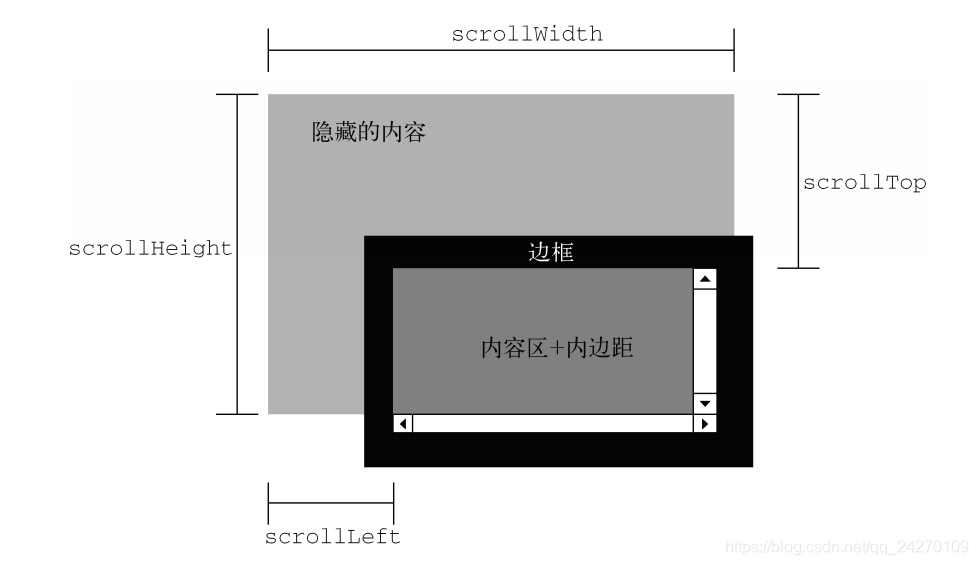
4.元素大小getBoundingClientRect()
这个方法返回会一个矩形对象,包含 4 个属性:left、top、right 和 bottom
IE8 及更早版本认为文档的左上角坐
标是(2, 2),而其他浏览器包括 IE9 则将传统的(0,0)作为起点坐标。因此,就需要在一开始检查一下位于
(0,0)处的元素的位置,在 IE8 及更早版本中,会返回(2,2),而在其他浏览器中会返回(0,0)。
const getBoundClientRect = (element) => { // 跨浏览器使用
let scrollTop = document.documentElement.scrollTop
scrollLeft = document.documentElement.scrollLeft
if (element.getBoundClientRect) {
if (typeof arguments.callee.offset != "number") {
let scrollTop = document.documentElement.scrollTop
temp = document.createElement("div")
temp.style.cssText = "position:absolute;left:0;top:0;"
document.body.appendChild(temp)
arguments.callee.offset = -temp.getBoundClientRect().Top - scrollTop
document.body.removeChild(temp)
temp = null
}
let rect = element.getBoundClientRect()
offset = arguments.callee.offset
return {
left: rect.left + offset,
right: rect.right + offset,
top: rect.top + offset,
bottom: rect.bottom + offset
}
} else {
var actualLeft = getElementLeft(element)
var actualTop = getElementTop(element)
return {
left: actualLeft - scrollLeft,
right: actualLeft + element.offsetWidth - scrollLeft,
top: actualTop - scrollTop,
bottom: actualTop + element.offsetHeight - scrollTop
}
}
}
最终的 offset 会被设置为新元素上坐标的负值,实际上就是在 IE 中设置为-2,在
Firefox 和 Opera 中设置为-0。为此,需要创建一个临时的元素,将其位置设置在(0,0),然后再调用其
getBoundingClientRect()。而之所以要减去视口的 scrollTop,
是为了防止调用这个函数时窗口被滚动了
再在传入的元素上调用这个方法并基于新的计算公式创建一个对象。
遍历
检测
document.implementation.hasFeature("Traversal", "2.0") //true
(typeof document.createNodeIterator == "function") //true
(typeof document.createTreeWalker == "function") //true
DOM树结构
<!DOCTYPE html>
<html>
<head>
<title>Example</title>
</head>
<body>
<p><b>Hello</b> world!</p>
</body>
</html>
相应结构图
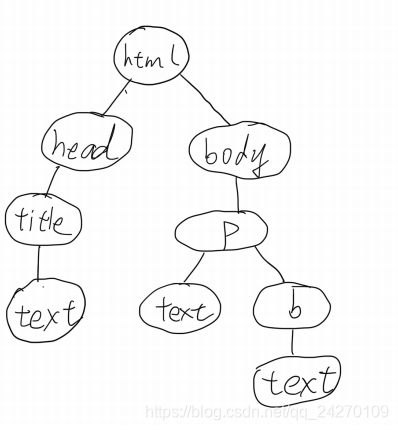
遍历结果为 html-head-title-text-body-p-b-text-text 为深度优先遍历
1.NodeIterator Firefox3.5之前不支持
1.创建一个显示p节点的迭代器
let filter = (node) => {
return node.tagName.toLowerCase() == "p" ?
NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP
}
//args[0] 开始的根节点 args[1]显示元素
//args[2]过滤函数 args[3]false因为在HTML5中不能扩展实体引用
let iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false)
let iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, null, false)//显示所有元素
NodeIterator 类型的两个主要方法是 nextNode()和 previousNode()。顾名思义,在深度优先
的 DOM 子树遍历中,nextNode()方法用于向前前进一步,而 previousNode()用于向后后退一步。
在刚刚创建的 NodeIterator 对象中,有一个内部指针指向根节点,因此第一次调用 nextNode()会
返回根节点。当遍历到 DOM 子树的最后一个节点时,nextNode()返回 null。previousNode()方法
的工作机制类似。当遍历到 DOM 子树的最后一个节点,且 previousNode()返回根节点之后,再次调
用它就会返回 null。
eg:
//DOM结构
<div id="div1">
<p><b>Hello</b> world!</p>
<ul>
<li>List item 1</li>
<li>List item 2</li>
<li>List item 3</li>
</ul>
</div>
//js
let div = document.getElementById("div1"),
iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, null, false),
node = iterator.nextNode()
while (node !== null) {
console.log(node.tagName)
node = iterator.nextNode()
}
//log
//DIV P B UL 3*LI
//加上filter过滤选择li的话
// let filter = (node) => {
// return node.tagName.toLowerCase() == "li" ?
// NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP
// }
// iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, filter, false) //3*LI
2.TreeWalker (iterator升级版) IE不支持
新方法:
firstChild() lastChild() 当前节点的第一个子节点与最后一个子节点
nextSibling()当前节点下一个同辈节点
previousSibling()当前节点的上一个同辈节点
与iterator不同点在与创建方法:
let walker = document.createWalker(div, NodeFilter.SHOW_ELEMENT, filter, false)
在使用 NodeIterator 对象时,
NodeFilter.FILTER_SKIP 与 NodeFilter.FILTER_REJECT 的作用相同:跳过指定的节点。但在使
用 TreeWalker 对象时,NodeFilter.FILTER_SKIP 会跳过相应节点继续前进到子树中的下一个节点,
而 NodeFilter.FILTER_REJECT 则会跳过相应节点及该节点的整个子树。
TreeWalker 真正强大的地方在于能够在 DOM 结构中沿任何方向移动。使用 TreeWalker
遍历 DOM 树,即使不定义过滤器,也可以取得所有<li>元素
let div = document.getElementById("div1"),
walker = document.createTreeWalker(div, NodeFilter.SHOW_ELEMENT, null, false)
walker.firstChild() //转到div的第一个子节点p
walker.nextSibling() //转到p的同辈ul
let node = walker.firstChild() //node=ul的第一个子节点li
while (node !== null) {
console.log(node.tagName);
node = walker.nextSibling(); //转到下一个同辈节点li
}
//walker.currentNode 返回当前遍历到的节点 可修改 (即让遍历从另一个起点又开始)
4.范围 IE9之前不支持 需使用文本范围(text range)
检测
document.implementation.hasFeature("Range", "2.0")
(typeof document.createRange == "function")
let range = document.createRange() //创建DOM范围
//DOM
<!DOCTYPE html>
<html>
<body>
<p id="p1"><b>Hello</b> world!</p>
</body>
</html>
//js
let range1 = document.createRange(),
range2 = document.createRange(),
p1 = document.getElementById("p1")
range1.selectNode(p1) //range1为p1及内容
range2.selectNodeContents(p1) //range2为p1的内容 不包括p1
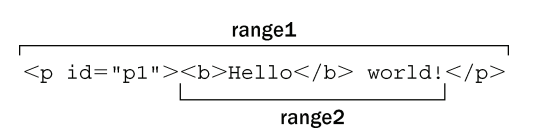
在调用 selectNode()时,startContainer、endContainer 和 commonAncestorContainer
都等于传入节点的父节点,也就是这个例子中的 document.body。
而 startOffset 属性等于给定节点在其父节点的 childNodes 集合中的索引
(在这个例子中是 1——因为兼容 DOM 的浏览器将空格算作一个文本节点)
,endOffset 等于 startOffset 加 1(因为只选择了一个节点)。
startContainer、endContainer 和 commonAncestorContainer 等于传入的节点,即这个例子中的<p>元素
而 startOffset 属性始终等于 0,因为范围从给定节点的第一个子节点开始。
最后,endOffset 等于子节点的数量(node.childNodes.length)为2
用DOM范围实现复杂选择 用 setStart()和 setEnd()方法
args[0]参照节点 args[1]偏移量
主要用来选择节点的一部分
<p id="p1"><b>hello</b> world!</p>
let p1 = document.getElementById("p1"),//先取得节点的引用
helloNode = p1.firstChild.firstChild, //"hello"
worldNode = p1.lastChild //" world"
let range = document.createRange() //创建范围
range.setStart(helloNode, 2) //起点为he后面
range.setEnd(worldNode, 3) //终点为rld前面 最后获得"llo wo"
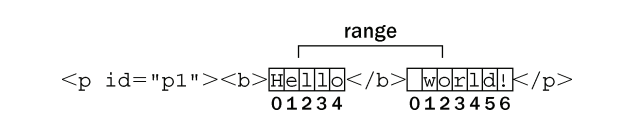
对于前面的例子而言,范围经过计算知道选区中缺少一个开始的标签,因此就会在后台动态加
入一个该标签,同时还会在前面加入一个表示结束的标签以结束"He"。于是,修改后的 DOM 就
变成了如下所示。
<p><b>He</b><b>llo</b> world!</p>
另外,文本节点"world!“也被拆分为两个文本节点,一个包含"wo”,另一个包含"rld!"
详情:
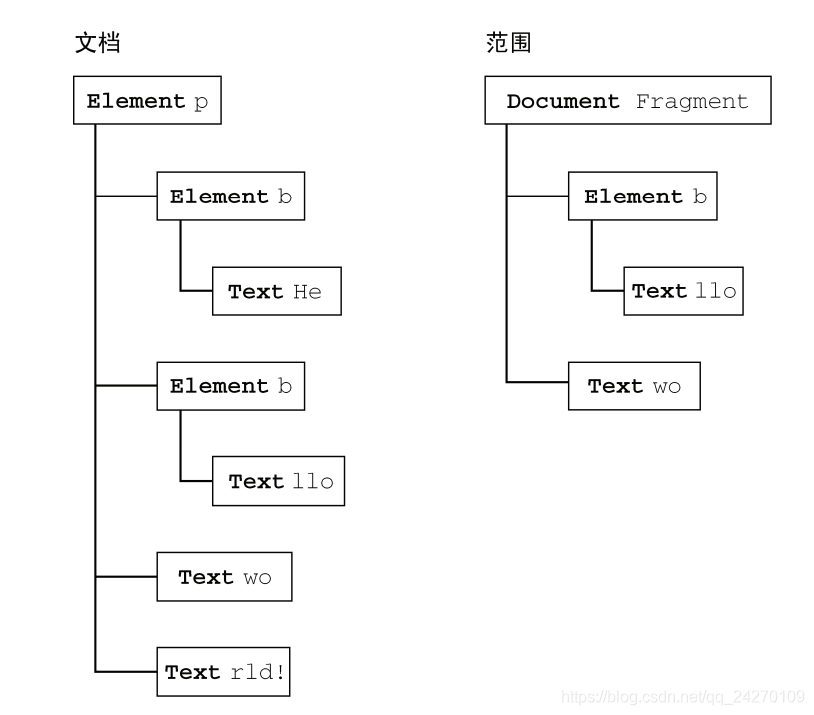
deleteContents() 删除范围内的内容
range.deleteContents();
执行以上代码后,页面中会显示如下 HTML 代码:
<p><b>He</b>rld!</p>
deleteContents()方法相似,extractContents()也会从文档中移除范围选区。但这两个方
法的区别在于,extractContents()会返回范围的文档片段。利用这个返回的值,可以将范围的内容
插入到文档中的其他地方
let fragment = range.extractContents()
p1.parentNode.appendChild(fragment)
结果得到如下HTML 代码:
<p><b>He</b>rld!</p>
<b>llo</b> wo
使用 cloneContents()创建范围对象的一个副本,然后在文档的其他地方插入该副本
let fragment = range.cloneContents()
p1.parentNode.appendChild(fragment) //结果与extractContents()一样
向范围中插入节点
插入:<span style="color: red">Inserted text</span>
let span = document.createElement("span")
span.style.color = "red"
span.appendChild(document.createTextNode("Inserted text"))
range.insertNode(span)
//插入后:<p id="p1"><b>He<span style="color: red">Inserted text</span>llo</b> world</p>
复制范围:可以使用 cloneRange()方法复制范围
let newRange = range.cloneRange()
清理范围 detach()
调用 detach()方法,以便从创建范围的文档中分离出该范围。调用
detach()之后,就可以放心地解除对范围的引用,从而让垃圾回收机制回收其内存了
range.detach() //从文档中分离
range = null //解除引用


















 1761
1761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









