





(NeurIPS 24)用于掩码点建模的局部约束的紧凑点云模型
向大家分享一下我们发表在NeurIPS 2024上的紧凑点云模型的工作,该工作使用基于局部约束与去冗余思想的编码器和互信息最大化的解码器来构建了一个紧凑高效的点云模型,性能大幅领先标准的Transformer且参数量降低了88%,计算量降低了73%。以下是详细内容:

原文链接:https://arxiv.org/abs/2405.17149
代码链接:https://github.com/zyh16143998882/LCM
1 摘要
基于掩蔽点建模(MPM)的预训练点云模型在多个任务中表现出了显著的改进。然而,这些模型严重依赖于Transformer,导致了二次复杂度和有限的解码器,限制了其实际应用。为了应对这一限制,我们首先对现有基于Transformer的MPM进行了全面分析,强调冗余减少对点云分析至关重要的观点。为此,我们提出了一种局部约束紧凑点云模型(LCM),该模型由局部约束紧凑编码器和局部约束基于Mamba的解码器组成。我们的编码器用局部聚合层替代了自注意力机制,实现了性能与效率之间的优雅平衡。考虑到在MPM的解码器输入中,掩蔽和未掩蔽patch的输入信息密度不同,我们引入了局部约束基于Mamba的解码器。该解码器确保了线性复杂度,同时最大化了从未掩蔽patch中提取点云几何信息的能力,这些未掩蔽patch具有更高的信息密度。广泛的实验结果表明,我们的紧凑模型在性能和效率上显著超过了现有基于Transformer的模型,特别是基于LCM的Point-MAE模型,相比基于Transformer的模型,在ScanObjectNN的三个变体上,平均准确率分别提高了1.84%、0.67%和0.60%,同时减少了88%的参数和73%的计算量。代码可在https://github.com/zyh16143998882/LCM 获取。
2 引言
3D点云感知作为深度学习的一个重要应用,在自动驾驶、机器人和虚拟现实等多个领域取得了显著成功。近年来,能够从大量未标注点云数据中学习通用表示的点云自监督学习[58; 1; 60],引起了广泛关注。其中,掩蔽点建模(MPM)[60; 37; 65; 8; 66; 62]作为一种重要的自监督范式,已经成为点云分析的主流方法,并在各种点云任务中取得了巨大成功。
经典的MPM[60; 37; 65]受掩蔽图像建模(MIM)[2; 22; 59]的启发,将点云划分为多个patch,并使用标准Transformer[46]骨干网络。它在编码器输入中随机掩蔽一些patch,并将未掩蔽的patch标记与随机初始化的掩蔽patch标记结合在解码器输入中。它通过解码器输出标记预测掩蔽patch的几何坐标或语义特征,使得模型能够学习通用的3D表示。尽管取得了显著成功,但Transformer的两个固有问题仍然限制了它们的实际部署。
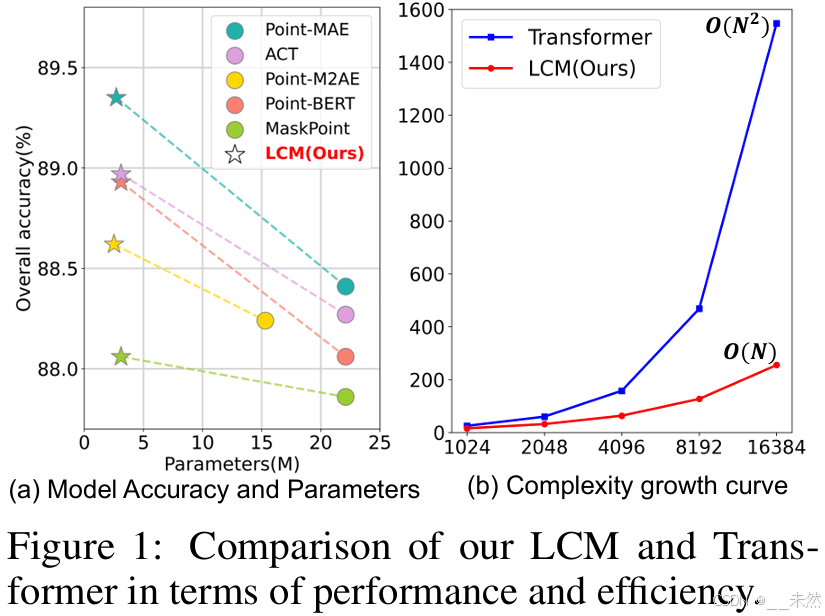
第一个问题是Transformer架构导致了二次复杂度和巨大的模型规模。如图1(a)和(b)所示,基于标准Transformer[46]的MPM方法如Point-MAE[37]需要22.1M参数,并且随着输入patch长度的增加,复杂度呈指数级增长。然而,在实际的点云应用中,模型通常部署在嵌入式设备上,如机器人或VR头盔,这些设备对模型的大小和复杂度有严格的要求。在这种情况下,像PointNet++[40]这样的轻量级网络由于其较低的参数需求(仅1.5M),在实际应用中更为流行,尽管它们可能在性能上不如Transformer模型。
另一个问题是,当Transformer[46]作为解码器用于掩蔽点建模(MPM)时,其重建信息密度较低的掩蔽patch的能力受限。在MPM的解码器输入中,通常将信息密度较低的随机初始化掩蔽标记与信息密度较高的未掩蔽标记连接,并输入到基于Transformer的解码器中。自注意力层随后根据损失约束学习处理这些信息密度不同的标记。然而,仅依赖于损失来学习这一目标是具有挑战性的,因为缺乏对不同密度的显式重要性指导。此外,在第5.1节中,我们从信息论的角度进一步解释了,自注意力机制作为一种高阶处理函数,可能限制模型的重建潜力。
为了解决上述问题,如图2所示,我们首先对不同的Top-K注意力对Transformer模型性能的影响进行了全面分析,强调冗余减少对于点云分析的重要性。为此,我们提出了一种局部约束紧凑点云模型(LCM),由局部约束紧凑编码器和局部约束基于Mamba的解码器组成,用以替代标准Transformer。具体来说,基于冗余减少的思想,我们的紧凑编码器用局部聚合层替代了自注意力机制,实现了性能与效率之间的优雅平衡。局部聚合层利用静态局部几何约束来聚合每个patch标记的最相关信息。由于静态局部几何约束只需要在开始时计算一次,并且在所有层之间共享,它避免了每层中动态注意力计算,从而显著减少了复杂度。此外,它仅使用两个MLP进行信息映射,极大地减少了网络的参数。
在我们的解码器设计中,考虑到掩蔽和未掩蔽patch在MPM输入中的信息密度不同,我们的解码器引入了来自Mamba[13; 16; 30; 71; 19]的状态空间模型(SSM)来替代自注意力机制,确保了线性复杂度,同时最大化了从信息密度较高的未掩蔽patch中提取点云几何信息的能力。然而,如第7节所讨论,直接替换的SSM层对输入patch的顺序表现出强依赖性。受到我们紧凑编码器的启发,我们将局部约束的思想迁移到基于Mamba的解码器的前馈神经网络中,提出了局部约束前馈网络(LCFFN)。这消除了在SSM层中显式考虑输入顺序的需求,因为后续的LCFFN可以根据几何相邻patch的隐式几何顺序自适应地交换信息。
我们的LCM是一个通用的点云架构,基于点云的特性设计,用以替代标准Transformer。它可以从头开始训练,或者集成到任何现有的预训练策略中,实现性能与效率之间的优雅平衡。例如,基于Point-MAE策略预训练的LCM模型仅需要2.7M参数,比原始的22.1M Transformer模型高效约10倍。此外,在性能方面,LCM相比Transformer,在ScanObjectNN的三个变体上,平均分类准确率分别提高了1.84%、0.67%和0.60%。在ScanNetV2[6]的检测任务中,AP25和AP50分别提高了+5.2%和+6.0%。
我们总结本文的贡献如下:
- 提出了局部约束紧凑编码器,利用静态局部几何约束聚合每个patch标记的最相关信息,达到了性能与效率之间的优雅平衡。
- 提出了局部约束基于Mamba的解码器,用于掩蔽点建模,替代了自注意力层,使用Mamba的SSM层,并引入局部约束前馈神经网络,消除了Mamba对输入顺序的显式依赖。
- 我们的局部约束紧凑编码器和局部约束基于Mamba的解码器共同构成了掩蔽点建模的高效骨干LCM。我们将LCM与多种预训练策略结合,预训练高效模型,并在多个下游任务中验证了我们模型在效率和性能上的优越性。
3 相关工作
点云自监督预训练。点云自监督预训练[47, 54, 55, 58, 60]在许多点云任务中取得了显著的改进。该方法首先应用预设任务来学习潜在的3D表示,然后将其转移到各种下游任务中。PointContrast [58] 和 CrossPoint [1] 最早探讨了利用对比学习[36, 43]来学习3D表示,取得了一定的成功;然而,在捕捉细粒度语义表示方面仍然存在一些不足。最近,掩蔽点建模方法[37, 60-62]通过掩蔽和重建在学习细粒度点云表示方面取得了显著的进展。许多方法[4, 8, 21, 41, 66]尝试利用多模态知识来辅助MPM学习更通用的表示,从而取得了显著的改进。在获得预训练的点云模型后,许多工作[18, 64, 67, 70]仍在探索参数高效的微调方法,以更好地将这些预训练模型适应于各种下游任务。尽管上述预训练模型取得了巨大的成功,但它们都依赖于Transformer架构。本文集中设计一种更高效的架构,以替代这些方法中的Transformer,从而显著减少计算和资源需求。
4 方法
4.1 Top-K 注意力的观察

标准的Transformer [46] 架构需要计算每个patch与所有输入patch之间的相关性,从而导致二次复杂度。尽管这种架构在语言数据中表现良好,但在点云数据中的有效性尚未被充分探索。并非所有点都同样重要。如图3所示,飞机识别的关键点主要分布在机翼上,而花瓶识别的关键点主要位于花瓶底部。因此,直接跳过不太重要的点的注意力计算提供了一种直接的解决方案。
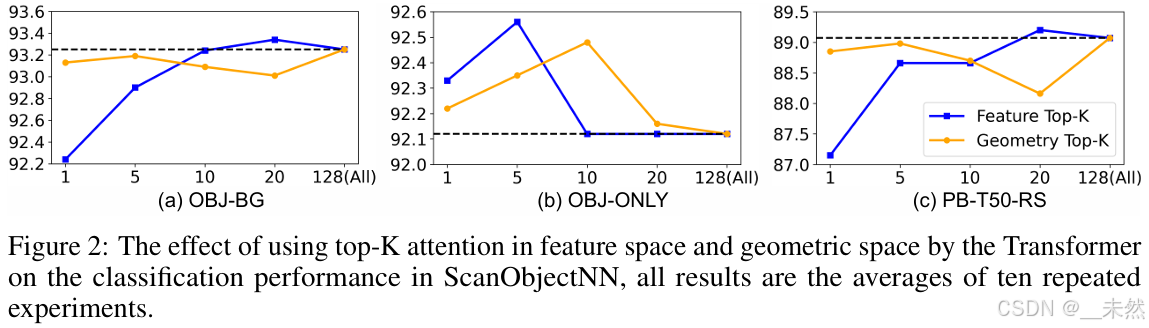
我们首先用在特征空间和几何空间中计算top-K注意力代替了对所有patch标记的全局注意力计算。如图2所示,我们的实验证据表明:1)在自注意力中,使用基于top-K最重要的patch标记的注意力权重通常比使用所有patch的效果更好;2)与在动态特征空间中使用top-K注意力相比,在静态几何空间中使用top-K注意力能够获得几乎相同的表示能力,并且具有更小的K值优势。尽管这种简单的通过掩蔽不重要的注意力计算方法仍然表现出二次复杂度,但这种冗余减少的思想不仅带来了性能的提升,还为进一步优化计算效率提供了方向。
4.2 Masking Point Modeling with LCM 的流程
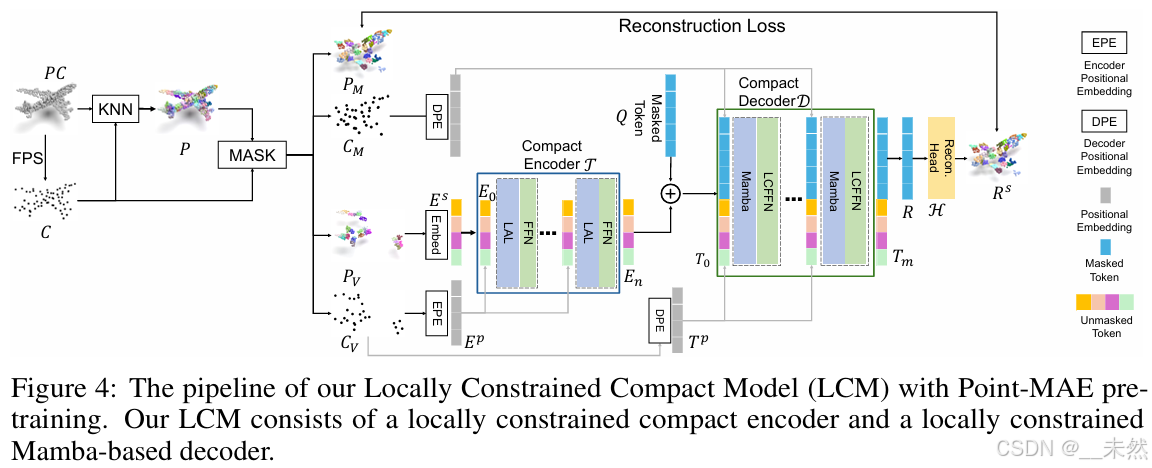
我们局部约束紧凑模型 (LCM) 的整体架构如图 4 所示。具体过程如下:
Patching、Masking 和 Embedding
给定输入点云 P C ∈ R L × 3 P_C \in \mathbb{R}^{L \times 3} PC∈RL×3,其中 L L L 为点的数量,我们首先通过最远点采样 (FPS) 下采样得到一个中心点云 C ∈ R N × 3 C \in \mathbb{R}^{N \times 3} C∈RN×3,其中 N N N 为点的数量。然后,我们对 C C C 执行 K 最近邻 (KNN) 操作,得到点块 P ∈ R N × K × 3 P \in \mathbb{R}^{N \times K \times 3} P∈RN×K×3。接着,我们随机遮蔽 C C C 和 P P P 的一部分,得到遮蔽后的元素 C M ∈ R ( 1 − r ) N × 3 C_M \in \mathbb{R}^{(1 - r) N \times 3} CM∈R(1−r)N×3 和 P M ∈ R ( 1 − r ) N × K × 3 P_M \in \mathbb{R}^{(1 - r) N \times K \times 3} PM∈R(1−r)N×K×3,以及未遮蔽的元素 C V ∈ R r N × 3 C_V \in \mathbb{R}^{r N \times 3} CV∈RrN×3 和 P V ∈ R r N × K × 3 P_V \in \mathbb{R}^{r N \times K \times 3} PV∈RrN×K×3,其中 r r r 表示未遮蔽比例。最后,我们分别使用基于 MLP 的嵌入层 (Embed) 和位置编码层 (PE) 提取未遮蔽点块的语义标记 E 0 ∈ R r N × d E_0 \in \mathbb{R}^{r N \times d} E0∈RrN×d 和中心位置嵌入 E p ∈ R r N × d E_p \in \mathbb{R}^{r N \times d} Ep∈RrN×d,其中 d d d 为特征维度。
Encoder
我们采用局部约束紧凑编码器 T \mathcal{T} T 从未遮蔽的特征 E 0 E_0 E0 中提取特征。它由 n n n 层堆叠的编码器组成,每层包含一个局部聚合层和一个前馈神经网络,具体细节见图 4。对于第 i i i 层的输入特征 E i − 1 E_{i-1} Ei−1,在添加位置编码 E p E_p Ep 后,输入到第 i i i 层编码器 T i \mathcal{T}_i Ti 中,得到特征 E i E_i Ei。因此,每层编码器的前向过程定义为:
E i = T i ( E i − 1 + E p ) , i = 1 , … , n (1) E_i = \mathcal{T}_i (E_{i-1} + E_p), \quad i = 1, \dots, n \tag{1} Ei=Ti(Ei−1+Ep),i=1,…,n(1)
Decoder
在解码阶段,尽管不同的 MPM 方法有不同的解码策略,但它们一般可以分为特征级重建或坐标级重建,其解码器大多依赖 Transformer 架构。在这里,我们以坐标级重建方法 Point-MAE [37] 为例,说明我们基于局部约束的 Mamba 解码器的解码过程。
我们首先将未遮蔽的标记 E n ∈ R r N × d E_n \in \mathbb{R}^{r N \times d} En∈RrN×d 和随机初始化的遮蔽标记 Q ∈ R ( 1 − r ) N × d Q \in \mathbb{R}^{(1 - r) N \times d} Q∈R(1−r)N×d 拼接,得到解码器的输入 T 0 ∈ R N × d T_0 \in \mathbb{R}^{N \times d} T0∈RN×d。然后,我们分别计算未遮蔽点块的位置信息 T V p ∈ R r N × d T_V^p \in \mathbb{R}^{r N \times d} TVp∈RrN×d 和遮蔽点块的位置信息 T M p ∈ R ( 1 − r ) N × d T_M^p \in \mathbb{R}^{(1 - r) N \times d} TMp∈R(1−r)N×d,然后将它们拼接在一起,得到位置嵌入 T p ∈ R N × d T_p \in \mathbb{R}^{N \times d} Tp∈RN×d,该嵌入在解码器的所有层中共享。最后,对于第 i i i 层解码器的输入特征 T i − 1 T_{i-1} Ti−1,在添加其位置嵌入 T p T_p Tp 后,输入到第 i i i 层解码器 D i \mathcal{D}_i Di 中,计算输出特征 T i T_i Ti。因此,每层解码器的前向过程定义为:
T i = D i ( T i − 1 + T p ) , i = 1 , … , m (2) T_i = \mathcal{D}_i (T_{i-1} + T_p), \quad i = 1, \dots, m \tag{2} Ti=Di(Ti−1+Tp),i=1,…,m(2)
Reconstruction
我们利用解码器解码得到的特征 R = T m [ r N : ] R = T_m[rN:] R=Tm[rN:] 执行 3D 重建。我们使用多层 MLP 构造坐标重建头 H \mathcal{H} H,我们的重建目标是恢复遮蔽点块的相对坐标 R M = H ( R ) R_M = \mathcal{H}(R) RM=H(R)。我们使用 l 2 \mathcal{l}_2 l2 Chamfer 距离 [9] ( C D \mathcal{C} \mathcal{D} CD) 作为重建损失。因此,我们的损失函数 L \mathcal{L} L 定义为:
L = C D ( R M , P M ) (3) \mathcal{L} = \mathcal{C} \mathcal{D} (R_M, P_M) \tag{3} L=CD(RM,PM)(3)
4.3 Locally Constrained Compact Encoder
经典的 Transformer [46] 依赖自注意力机制来感知所有块之间的长距离相关性,并在语言和图像领域取得了巨大成功。然而,关于是否直接迁移基于 Transformer 的编码器适用于点云数据,仍然存在不确定性。首先,点云的应用更倾向于实际嵌入式设备,如机器人或 VR 头盔。这些设备的硬件资源有限,对模型的大小和复杂度有更高的限制,而基于 Transformer 的骨干网络相比传统网络需要更多的资源,具体如表 1 所示。其次,大量研究 [40; 50; 34] 以及我们通过图 2 所示的经验观察也表明,在点云数据中,局部几何的感知远远超过了对全局感知的需求。因此,在自注意力中计算长距离相关性导致了大量冗余计算。为了解决这些实际问题,我们提出了一个局部约束的紧凑编码器。
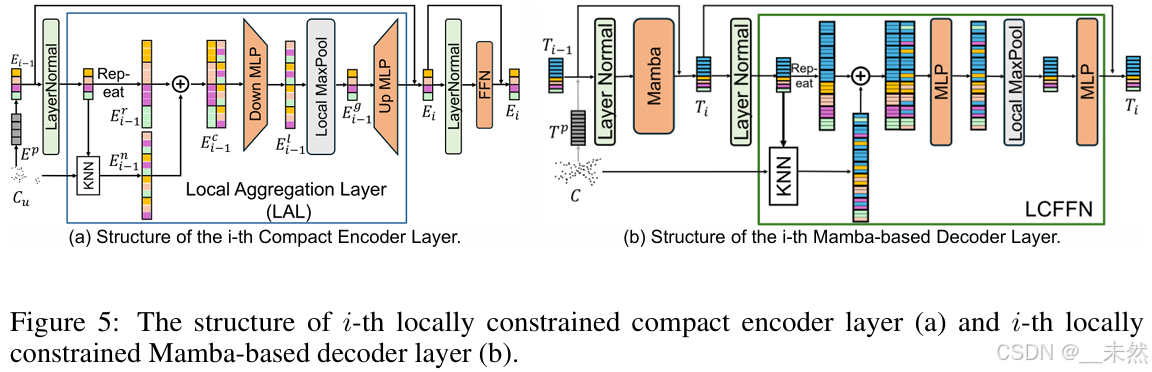
我们的紧凑编码器由 n n n 层堆叠的紧凑编码器层组成,每一层包括一个局部聚合层(LAL)和一个前馈神经网络(FFN),如图 5 (a) 所示。对于第 i i i 层,前一层的输出 E i − 1 E_{i-1} Ei−1 加上位置编码并通过层归一化后,首先送入局部聚合层(LAL)以聚合局部几何信息。之后,将结果与输入残差相加,再通过层归一化,最后送入前馈神经网络(FFN)得到最终的输出特征 E i E_i Ei。这一过程可以形式化为以下公式:
E i = E i − 1 + l i ( n i 1 ( E i − 1 ) , C u ) (4) E_i = E_{i-1} + l_i \left( n_{i1} (E_{i-1}), C_u \right) \tag{4} Ei=Ei−1+li(ni1(Ei−1),Cu)(4)
E i = E i + f i ( n i 2 ( E i ) ) (5) E_i = E_i + f_i \left( n_{i2} (E_i) \right) \tag{5} Ei=Ei+fi(ni2(Ei))(5)
其中, l i ( ⋅ ) l_i(\cdot) li(⋅) 表示局部聚合层(LAM), n i 1 ( ⋅ ) n_{i1}(\cdot) ni1(⋅) 和 n i 2 ( ⋅ ) n_{i2}(\cdot) ni2(⋅) 表示层归一化操作, f i ( ⋅ ) f_i(\cdot) fi(⋅) 表示前馈神经网络(FFN)。
在局部聚合层中,我们首先使用基于特征 E i − 1 E_{i-1} Ei−1 中的中心坐标 C u C_u Cu 的 K 最近邻算法,找到每个标记在 E i − 1 E_{i-1} Ei−1 中的 k k k 个最近邻特征 E i − 1 n ∈ R r ⋅ k ⋅ N × d E_{i-1}^n \in \mathbb{R}^{r \cdot k \cdot N \times d} Ei−1n∈Rr⋅k⋅N×d。然后,我们将 E i − 1 E_{i-1} Ei−1 中的每个标记复制 k k k 次,并将其与对应的邻居拼接,得到 E i − 1 c ∈ R r ⋅ k ⋅ N × 2 ⋅ d E_{i-1}^c \in \mathbb{R}^{r \cdot k \cdot N \times 2 \cdot d} Ei−1c∈Rr⋅k⋅N×2⋅d。接下来,Down MLP 对所有局部邻居特征进行非线性映射,以捕获局部几何信息。随后,应用局部最大池化来聚合每个块的所有局部特征。最后,Up MLP 对所有块进行映射,得到局部增强特征 E i ∈ R r ⋅ N × d E_i \in \mathbb{R}^{r \cdot N \times d} Ei∈Rr⋅N×d。
我们的 LAL 仅包含两个简单的 MLP 层,极大减少了网络的参数。此外,由于静态局部几何约束只需要在开始时计算一次,并且之后在所有层中共享,这避免了每层中的动态注意力计算,显著降低了计算需求。它仅使用两个 MLP 进行信息映射,大大减少了网络的参数。
3.4 Locally Constrained Mamba-based Decoder
用于掩码点建模的解码器需要根据从未掩码块提取的特征 E n E_n En 恢复掩码块的信息。常见的方法是将未掩码块的特征 E n E_n En 与随机初始化的掩码块特征 Q Q Q 连接,作为解码器的输入,如图 4 所示。然而,此时 E n E_n En 和 Q Q Q 之间在信息密度上存在显著差异。Transformer 架构和我们的局部聚合层都将输入中的每个标记初步视为同等重要,这在所有标记的信息密度相似时效果很好,但在输入信息密度差异较大时效果较差。
为了从未掩码特征 E n E_n En 中高效提取更多几何先验,我们受到了 Mamba [13] 模型在时间序列中的启发,提出使用基于 Mamba 的解码器。该解码器可以根据输入顺序,从前面的标记中提取更多先验信息,帮助后续标记的学习。最初,我们仅将原始基于 Transformer [46] 解码器中的自注意力层替换为 Mamba 的状态空间模型(SSM)层,并基于每个块的中心点坐标顺序对输入序列进行排序,创建了一个简单的基于 Mamba 的解码器。我们在第 8 节的实验中发现,尽管这个简单的解码器效率足够高,但简单的排序方法无法有效地建模点云的复杂空间几何,导致对输入块顺序的强依赖。
为了确保 SSM 完全感知点云的空间几何,我们进一步将局部聚合层的局部约束概念引入到解码器的前馈神经网络层中,得到局部约束前馈网络(LCFFN)。通过将 SSM 层输出的标记输入 LCFFN,LCFFN 可以基于每个标记的几何相邻块的中心坐标,隐式地交换信息。这消除了 SSM 层中显式序列输入无法完全感知复杂几何的局限性。最后,在第 5.1 节中,我们还从信息理论的角度定性解释了这一基于 Mamba 的架构相比 Transformer 在重建潜力方面具有更大的优势。
我们的基于 Mamba 的解码器由 m m m 层堆叠的解码器层组成,每一层包括一个 Mamba SSM 层和一个局部约束前馈网络(LCFFN),如图 5 (b) 所示。对于第 i i i 层解码器,我们首先将前一层的输出 T i − 1 T_{i-1} Ti−1 加上位置编码 T p T_p Tp,并通过层归一化进行标准化。然后,我们使用 Mamba SSM 层 s i ( ⋅ ) s_i(\cdot) si(⋅) 从未掩码特征中感知几何信息并预测掩码特征。最后,在 LCFFN 层 f i l ( ⋅ ) f_i^l(\cdot) fil(⋅) 中,我们进一步基于每个标记的几何相邻标记的中心坐标感知形状先验。这个过程可以形式化为以下公式:
T i = T i − 1 + s i ( n i 1 ( T i − 1 ) ) (6) T_i = T_{i-1} + s_i \left( n_{i1} (T_{i-1}) \right) \tag{6} Ti=Ti−1+si(ni1(Ti−1))(6)
T i = T i + f i l ( n i 2 ( T i ) , C ) (7) T_i = T_i + f_i^l \left( n_{i2} (T_i), C \right) \tag{7} Ti=Ti+fil(ni2(Ti),C)(7)
4 Experiments
4.1 Pre-training
我们使用五种不同的预训练策略对 LCM 进行预训练:Point-BERT [60]、MaskPoint [28]、Point-MAE [37]、Point-M2AE [65] 和 ACT [8]。为了进行公平比较,我们使用 ShapeNet [3] 作为我们的预训练数据集,包含超过 50,000 个不同的 3D 模型,覆盖 55 个常见的物体类别。在预训练阶段的超参数设置上,我们使用了与之前方法相同的设置。
4.2 Fine-tuning on Downstream Tasks
我们通过在各种下游任务上对模型进行微调,评估 LCM 的性能,包括物体分类、场景级检测和部分分割。
4.2.1 Object Classification
我们首先评估了我们预训练模型在真实扫描数据集(ScanObjectNN [44])和合成数据集(ModelNet40 [57])上的整体分类精度。ScanObjectNN 是一个广泛使用的数据集,包含来自 15 个类别的约 15,000 个真实世界扫描的点云样本。这些物体代表室内场景,通常具有杂乱的背景,并且受到其他物体遮挡的影响。对于 ScanObjectNN 数据集,我们为每个实例采样 2048 个点,并报告了没有投票机制的结果。我们在 ScanObjectNN 下游设置中应用了前期工作的简单缩放和旋转数据增强 [37; 8]。我们报告了在我们的下游设置中不同模型的结果,并用 ∙ 标记结果。对于 ModelNet40 数据集,由于篇幅限制,我们将在第 5.4 节进一步分析其结果。
为了确保公平比较,我们按照该领域的标准实践进行了实验(如之前的工作 [60; 37; 28; 65; 8] 中使用的)。对于每个点云分类实验,我们使用了 8 个不同的随机种子(0-7),以确保结果的稳健性和可靠性。表 1 中报告的性能是每个模型配置在这 8 次实验中的平均准确度。

如表 1 所示,我们的模型取得了许多令人兴奋的结果。
-
更轻、更快、更强大。在仅使用监督学习从头开始训练时,我们的 LCM 模型相较于 Transformer 架构,在三个不同数据集上分别提高了 0.82%、0.15% 和 1.10% 的性能。类似地,在预训练(例如,Point-MAE)后,我们的模型在 ScanObjectNN 数据集的三个变体上分别超越标准 Transformer 1.84%、0.67% 和 0.60%。值得注意的是,这些改进是在减少 88% 的参数和 73% 的 FLOP 后实现的。这一改进令人兴奋,因为它表明我们的架构比标准 Transformer 更适合点云数据。此外,由于其极高的效率,它为这些预训练模型的实际部署提供了强大的支持。
-
通用性。我们在五种不同的基于 MPM 的预训练方法中,替换了原始的 Transformer 架构,使用了我们的 LCM 模型。所有实验结果都非常令人振奋,因为我们的模型在参数和计算量更少的情况下,实现了通用性能的提升,突显了我们模型的多样性。未来,我们将进一步适应更多的预训练方法。
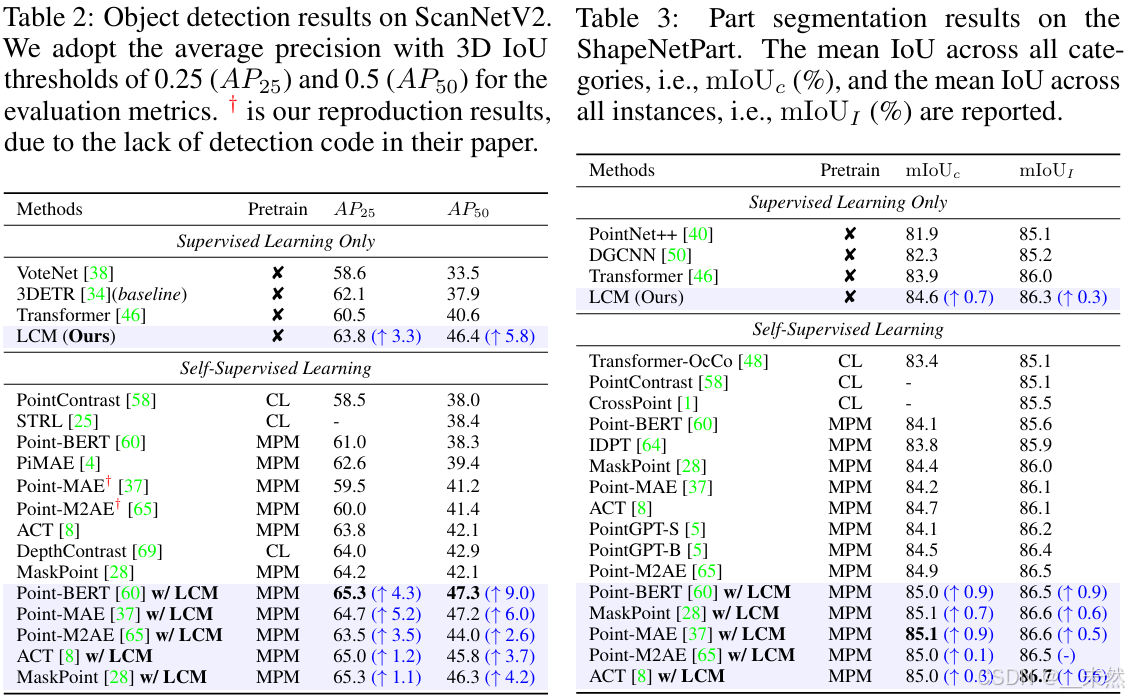
4.2.2 Object Detection
我们进一步评估了我们预训练模型在更具挑战性的场景级点云数据集 ScanNetV2 [6] 上的物体检测性能,以评估模型的场景理解能力。根据之前的预训练工作 [28; 8],我们使用 3DETR [34] 作为基准,并仅将 3DETR 中的 Transformer 编码器替换为我们预训练的紧凑型编码器。随后,整个模型被用于物体检测的微调。与之前的方法 [28; 8; 4] 需要在大规模场景级点云(如 ScanNet)上进行预训练不同,我们的方法直接利用在 ShapeNet 上预训练的模型。这进一步强调了我们预训练模型的广泛适应性。
表2 展示了我们的实验结果,紧凑型模型在场景级点云数据上表现出了显著的改进。例如,Point-MAE [37] 相较于 Transformer 在 AP25 上提高了 5.2%,在 AP50 上提高了 6.0%。这一改进非常显著,我们认为这是由于场景级点云中背景和噪声点较多。使用局部约束建模方法有效地过滤了不重要的背景和噪声,使得模型能更多地聚焦于有意义的点。
4.2.3 Part Segmentation
我们还使用 ShapeNetPart 数据集 [3] 评估了 LCM 在部分分割任务中的表现。该数据集包含 16,881 个样本,跨越 16 个类别。为了公平比较,我们在预训练编码器之后使用了与之前工作 [37; 65] 相同的分割设置。如表3 所示,我们基于 LCM 的模型相较于基于 Transformer 的模型也表现出了明显的提升。这些结果表明,我们的模型在需要更精细点云理解的任务(如部分分割)中表现优越。
4.3 Ablation Study
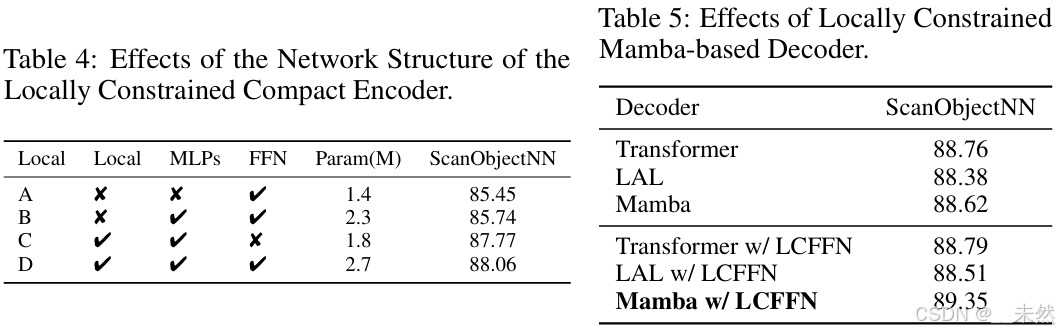
Effects of Locally Constrained Compact Encoder
我们通过与基于 Transformer 的编码器在分类、检测和部分分割任务中的比较,探索了我们局部约束紧凑型编码器的表现。从表 1、表2 和表3 可以看出,通过仅从头开始进行监督学习,局部约束紧凑型编码器相较于基于 Transformer 的编码器在性能和效率方面有了明显的优势,特别是在检测任务中,在 AP50 指标上提升了 6.0%。
这种显著改进归因于紧凑型编码器专注于每个点补丁的最关键的信息,如局部邻域,而忽略不重要的细节。这类似于减少冗余的压缩概念,这对于点云分析尤其重要,尤其是在大规模场景级点云中,常常存在大量冗余和噪声点。我们的局部约束方法使得模型能够聚焦于关键区域,从而在效率和性能上获得联合提升。此外,这一减少冗余的概念帮助我们的模型避免了对训练数据集的过拟合。我们将在第 5.5 节提供对此现象的详细解释。
Effects of the Network Structure of the Locally Constrained Encoder
如图 5(a) 所示,我们的局部约束紧凑型编码器每一层主要由三部分组成:基于 k-NN 的局部约束单元、由 Down MLP 和 Up MLP 组成的 MLP 映射单元,以及最终的 FFN 层。我们分别探索了每个单元的影响。具体地,我们在 ScanObjectNN [44] 数据集上从头开始训练具有不同结构的编码器,并测试它们的分类性能。如表 4 所示,比较 A 和 B 可以发现,简单的两层 MLP 没有局部聚合的编码器并未显著提高网络的性能。相比之下,C 和 D 与 A 和 B 的比较则显示了显著的性能提升。这一改进主要归因于引入了局部几何感知和聚合。比较 C 和 D 的结果后,FFN 的引入带来了一定的提升。因此,FFN 在我们的紧凑型编码器中不是不可或缺的,但我们选择加入 FFN 以进一步执行映射。这些实验进一步表明了局部几何感知和聚合在点云特征提取中的必要性。
Effects of Locally Constrained Mamba-based Decoder
我们进一步比较了预训练阶段不同解码器设计的影响。具体来说,我们比较了原始 Transformer 解码器、我们的 LAL-based 解码器和原始 Mamba-based 架构,以及它们在加入 LCFFN 后的性能。如表 5 所示,结果表明,原始 Transformer 在性能上稍微优于原始 Mamba,可能是由于简单的几何顺序输入对原始 Mamba 能力的限制。在加入 LCFFN 后,Mamba 解码器由于引入了隐式几何顺序,表现出了显著的改进。相比之下,Transformer 的改进则较为微小,因为几何顺序已经通过自注意力隐式捕获。
5 限制
我们的当前模型在处理动态重要性感知和长程依赖建模方面确实存在一些限制。我们的设计优先考虑效率,这可能与捕捉动态重要性和长程依赖所需的复杂度相冲突。为了提高效率,我们在某些方面简化了模型,因此,在这一版本的模型中,我们未能完全整合动态重要性感知和长程依赖建模的机制。尽管存在这些限制,当前模型在各类任务中的表现仍然显著提高。然而,我们也承认,加入动态重要性感知和长程依赖建模可能会进一步提升模型的能力,特别是在更复杂的场景中。我们正在积极探索在未来工作中解决这些限制的方法。
6 Conclusion
本文提出了一种专为掩膜点建模预训练设计的紧凑型点云模型 LCM,旨在实现性能与效率之间的优雅平衡。基于减少冗余的思想,我们提出在编码器中聚焦于最相关的点补丁,忽略不重要的部分,并引入局部聚合层替代传统的自注意力。考虑到掩膜和未掩膜点补丁之间在解码器输入中的信息密度差异,我们引入了局部约束的 Mamba-based 解码器,以确保线性复杂度,同时最大限度地感知未掩膜点补丁的点云几何信息。通过在分类和检测等任务中的广泛实验,我们证明了我们的 LCM 是一个通用模型,相较于传统的 Transformer 模型,具有显著的效率和性能提升。
7 Reference
[1]
Mohamed Afham, Isuru Dissanayake, Dinithi Dissanayake, Amaya Dharmasiri, Kanchana Thilakarathna, and Ranga Rodrigo.Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9902–9912, 2022.
[2]
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei.Beit: Bert pre-training of image transformers.arXiv preprint arXiv:2106.08254, 2021.
[3]
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al.Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015.
[4]
Anthony Chen, Kevin Zhang, Renrui Zhang, Zihan Wang, Yuheng Lu, Yandong Guo, and Shanghang Zhang.Pimae: Point cloud and image interactive masked autoencoders for 3d object detection.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5291–5301, Vancouver, Canada, Jun 18-22 2023.
[5]
Guangyan Chen, Meiling Wang, Yi Yang, Kai Yu, Li Yuan, and Yufeng Yue.Pointgpt: Auto-regressively generative pre-training from point clouds.volume 36, 2024.
[6]
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner.Scannet: Richly-annotated 3d reconstructions of indoor scenes.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5828–5839, 2017.
[7]
Tao Dai, Beiliang Wu, Peiyuan Liu, Naiqi Li, Jigang Bao, Yong Jiang, and Shu-Tao Xia.Periodicity decoupling framework for long-term series forecasting.In The Twelfth International Conference on Learning Representations, 2024.
[8]
Runpei Dong, Zekun Qi, Linfeng Zhang, Junbo Zhang, Jianjian Sun, Zheng Ge, Li Yi, and Kaisheng Ma.Autoencoders as cross-modal teachers: Can pretrained 2d image transformers help 3d representation learning?Kigali, Rwanda, May 1-5 2023.
[9]
Haoqiang Fan, Hao Su, and Leonidas J Guibas.A point set generation network for 3d object reconstruction from a single image.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 605–613, Honolulu, Hawaii, USA, July 21-26 2017.
[10]
Hao Fang, Bin Chen, Xuan Wang, Zhi Wang, and Shu-Tao Xia.Gifd: A generative gradient inversion method with feature domain optimization.In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4967–4976, 2023.
[11]
Hao Fang, Jiawei Kong, Wenbo Yu, Bin Chen, Jiawei Li, Shutao Xia, and Ke Xu.One perturbation is enough: On generating universal adversarial perturbations against vision-language pre-training models.arXiv preprint arXiv:2406.05491, 2024.
[12]
Hao Fang, Yixiang Qiu, Hongyao Yu, Wenbo Yu, Jiawei Kong, Baoli Chong, Bin Chen, Xuan Wang, and Shu-Tao Xia.Privacy leakage on dnns: A survey of model inversion attacks and defenses.arXiv preprint arXiv:2402.04013, 2024.
[13]
Albert Gu and Tri Dao.Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023.
[14]
Albert Gu, Tri Dao, Stefano Ermon, Atri Rudra, and Christopher Ré.Hippo: Recurrent memory with optimal polynomial projections.Advances in neural information processing systems, 33:1474–1487, 2020.
[15]
Albert Gu, Karan Goel, Ankit Gupta, and Christopher Ré.On the parameterization and initialization of diagonal state space models.Advances in Neural Information Processing Systems, 35:35971–35983, 2022.
[16]
Albert Gu, Karan Goel, and Christopher Ré.Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396, 2021.
[17]
Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, and Christopher Ré.Combining recurrent, convolutional, and continuous-time models with linear state space layers.Advances in neural information processing systems, 34:572–585, 2021.
[18]
Hang Guo, Tao Dai, Yuanchao Bai, Bin Chen, Shu-Tao Xia, and Zexuan Zhu.Adaptir: Parameter efficient multi-task adaptation for pre-trained image restoration models.arXiv preprint arXiv:2312.08881, 2023.
[19]
Hang Guo, Jinmin Li, Tao Dai, Zhihao Ouyang, Xudong Ren, and Shu-Tao Xia.Mambair: A simple baseline for image restoration with state-space model.arXiv preprint arXiv:2402.15648, 2024.
[20]
Meng-Hao Guo, Jun-Xiong Cai, Zheng-Ning Liu, Tai-Jiang Mu, Ralph R Martin, and Shi-Min Hu.Pct: Point cloud transformer.Computational Visual Media, 7(2):187–199, 2021.
[21]
Ziyu Guo, Renrui Zhang, Longtian Qiu, Xianzhi Li, and Pheng Ann Heng.Joint-mae: 2d-3d joint masked autoencoders for 3d point cloud pre-training.In Proceedings of International Joint Conference on Artificial Intelligence (IJCAI), Macao, China, August 19-25 2023.
[22]
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick.Masked autoencoders are scalable vision learners.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16000–16009, 2022.
[23]
Xinwei He, Silin Cheng, Dingkang Liang, Song Bai, Xi Wang, and Yingying Zhu.Latformer: Locality-aware point-view fusion transformer for 3d shape recognition.Pattern Recognition, 151:110413, 2024.
[24]
David Hilbert and David Hilbert.Über die stetige abbildung einer linie auf ein flächenstück.Dritter Band: Analysis· Grundlagen der Mathematik· Physik Verschiedenes: Nebst Einer Lebensgeschichte, pages 1–2, 1935.
[25]
Siyuan Huang, Yichen Xie, Song-Chun Zhu, and Yixin Zhu.Spatio-temporal self-supervised representation learning for 3d point clouds.In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6535–6545, 2021.
[26]
Md Mohaiminul Islam, Mahmudul Hasan, Kishan Shamsundar Athrey, Tony Braskich, and Gedas Bertasius.Efficient movie scene detection using state-space transformers.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18749–18758, 2023.
[27]
Dingkang Liang, Xin Zhou, Xinyu Wang, Xingkui Zhu, Wei Xu, Zhikang Zou, Xiaoqing Ye, and Xiang Bai.Pointmamba: A simple state space model for point cloud analysis.arXiv preprint arXiv:2402.10739, 2024.
[28]
Haotian Liu, Mu Cai, and Yong Jae Lee.Masked discrimination for self-supervised learning on point clouds.In Proceedings of the European Conference on Computer Vision (ECCV), pages 657–675, Tel Aviv, Israel, October 23-27 2022.
[29]
Jiaming Liu, Yue Wu, Maoguo Gong, Zhixiao Liu, Qiguang Miao, and Wenping Ma.Inter-modal masked autoencoder for self-supervised learning on point clouds.IEEE Transactions on Multimedia, 2023.
[30]
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, and Yunfan Liu.Vmamba: Visual state space model.arXiv preprint arXiv:2401.10166, 2024.
[31]
Jun Ma, Feifei Li, and Bo Wang.U-mamba: Enhancing long-range dependency for biomedical image segmentation.arXiv preprint arXiv:2401.04722, 2024.
[32]
Xu Ma, Can Qin, Haoxuan You, Haoxi Ran, and Yun Fu.Rethinking network design and local geometry in point cloud: A simple residual mlp framework.In Proceedings of International Conference on Learning Representations (ICLR), page 31, Online, Apr. 25-29 2022.
[33]
Harsh Mehta, Ankit Gupta, Ashok Cutkosky, and Behnam Neyshabur.Long range language modeling via gated state spaces.arXiv preprint arXiv:2206.13947, 2022.
[34]
Ishan Misra, Rohit Girdhar, and Armand Joulin.An end-to-end transformer model for 3d object detection.In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2906–2917, 2021.
[35]
Eric Nguyen, Karan Goel, Albert Gu, Gordon Downs, Preey Shah, Tri Dao, Stephen Baccus, and Christopher Ré.S4nd: Modeling images and videos as multidimensional signals with state spaces.Advances in neural information processing systems, 35:2846–2861, 2022.
[36]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals.Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018.
[37]
Yatian Pang, Wenxiao Wang, Francis EH Tay, Wei Liu, Yonghong Tian, and Li Yuan.Masked autoencoders for point cloud self-supervised learning.In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, October 23-27 2022.
[38]
Charles R Qi, Or Litany, Kaiming He, and Leonidas J Guibas.Deep hough voting for 3d object detection in point clouds.In proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9277–9286, 2019.
[39]
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas.Pointnet: Deep learning on point sets for 3d classification and segmentation.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 652–660, Honolulu, HI, USA, July 21-26 2017.
[40]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas.Pointnet++: Deep hierarchical feature learning on point sets in a metric space.In Proceedings of Advances in Neural Information Processing Systems (NeurIPS), page 30, Long Beach, CA, USA, Dec. 4-9 2017.
[41]
Zekun Qi, Runpei Dong, Guofan Fan, Zheng Ge, Xiangyu Zhang, Kaisheng Ma, and Li Yi.Contrast with reconstruct: Contrastive 3d representation learning guided by generative pretraining.In International Conference on Machine Learning, 2023.
[42]
Jimmy TH Smith, Andrew Warrington, and Scott W Linderman.Simplified state space layers for sequence modeling.arXiv preprint arXiv:2208.04933, 2022.
[43]
Yonglong Tian, Dilip Krishnan, and Phillip Isola.Contrastive multiview coding.In ECCV, pages 776–794. Springer, 2020.
[44]
Mikaela Angelina Uy, Quang-Hieu Pham, Binh-Son Hua, Thanh Nguyen, and Sai-Kit Yeung.Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data.In Proceedings of IEEE/CVF International Conference on Computer Vision (ICCV), pages 1588–1597, Seoul, Korea, Oct 27- Nov 2 2019.
[45]
Laurens Van der Maaten and Geoffrey Hinton.Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008.
[46]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin.Attention is all you need.In Proceedings of Advances in Neural Information Processing Systems (NeurIPS), page 30, Long Beach, CA, USA, Dec. 4-9 2017.
[47]
Chengyao Wang, Li Jiang, Xiaoyang Wu, Zhuotao Tian, Bohao Peng, Hengshuang Zhao, and Jiaya Jia.Groupcontrast: Semantic-aware self-supervised representation learning for 3d understanding.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4917–4928, 2024.
[48]
Hanchen Wang, Qi Liu, Xiangyu Yue, Joan Lasenby, and Matt J Kusner.Unsupervised point cloud pre-training via occlusion completion.In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9782–9792, 2021.
[49]
Jue Wang, Wentao Zhu, Pichao Wang, Xiang Yu, Linda Liu, Mohamed Omar, and Raffay Hamid.Selective structured state-spaces for long-form video understanding.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6387–6397, 2023.
[50]
Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E Sarma, Michael M Bronstein, and Justin M Solomon.Dynamic graph cnn for learning on point clouds.Acm Transactions On Graphics (TOG), 38(5):1–12, 2019.
[51]
Ziyi Wang, Xumin Yu, Yongming Rao, Jie Zhou, and Jiwen Lu.P2p: Tuning pre-trained image models for point cloud analysis with point-to-pixel prompting.In Proceedings of Advances in Neural Information Processing Systems (NeurIPS), New Orleans, Louisiana, USA, December 1-9 2022.
[52]
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao.Point transformer v3: Simpler, faster, stronger.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), volume 35, Seattle, USA, Jun 17-21 2024.
[53]
Xiaoyang Wu, Yixing Lao, Li Jiang, Xihui Liu, and Hengshuang Zhao.Point transformer v2: Grouped vector attention and partition-based pooling.In Proceedings of Advances in Neural Information Processing Systems (NeurIPS), volume 35, pages 33330–33342, New Orleans, Louisiana, USA, November 28 - December 9 2022.
[54]
Xiaoyang Wu, Zhuotao Tian, Xin Wen, Bohao Peng, Xihui Liu, Kaicheng Yu, and Hengshuang Zhao.Towards large-scale 3d representation learning with multi-dataset point prompt training.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19551–19562, 2024.
[55]
Xiaoyang Wu, Xin Wen, Xihui Liu, and Hengshuang Zhao.Masked scene contrast: A scalable framework for unsupervised 3d representation learning.In Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 9415–9424, 2023.
[56]
Yue Wu, Jiaming Liu, Maoguo Gong, Peiran Gong, Xiaolong Fan, A Kai Qin, Qiguang Miao, and Wenping Ma.Self-supervised intra-modal and cross-modal contrastive learning for point cloud understanding.IEEE Transactions on Multimedia, 26:1626–1638, 2023.
[57]
Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao.3d shapenets: A deep representation for volumetric shapes.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1912–1920, 2015.
[58]
Saining Xie, Jiatao Gu, Demi Guo, Charles R Qi, Leonidas Guibas, and Or Litany.Pointcontrast: Unsupervised pre-training for 3d point cloud understanding.In European conference on computer vision, pages 574–591. Springer, 2020.
[59]
Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu.Simmim: A simple framework for masked image modeling.In CVPR, pages 9653–9663, 2022.
[60]
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu.Point-bert: Pre-training 3d point cloud transformers with masked point modeling.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19313–19322, New Orleans, Louisiana, USA, June 21-24 2022.
[61]
Yaohua Zha, Tao Dai, Yanzi Wang, Hang Guo, Taolin Zhang, Zhihao Ouyang, Chunlin Fan, Bin Chen, Ke Chen, and Shu-Tao Xia.Block-to-scene pre-training for point cloud hybrid-domain masked autoencoders.arXiv preprint arXiv:2410.09886, 2024.
[62]
Yaohua Zha, Huizhen Ji, Jinmin Li, Rongsheng Li, Tao Dai, Bin Chen, Zhi Wang, and Shu-Tao Xia.Towards compact 3d representations via point feature enhancement masked autoencoders.In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), VANCOUVER, CANADA, February 20-27 2024.
[63]
Yaohua Zha, Rongsheng Li, Tao Dai, Jianyu Xiong, Xin Wang, and Shu-Tao Xia.Sfr: Semantic-aware feature rendering of point cloud.In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023.
[64]
Yaohua Zha, Jinpeng Wang, Tao Dai, Bin Chen, Zhi Wang, and Shu-Tao Xia.Instance-aware dynamic prompt tuning for pre-trained point cloud models.In Proceedings of IEEE/CVF International Conference on Computer Vision (ICCV), pages 14161–14170, Paris, France, October 4-6 2023.
[65]
Renrui Zhang, Ziyu Guo, Peng Gao, Rongyao Fang, Bin Zhao, Dong Wang, Yu Qiao, and Hongsheng Li.Point-m2ae: Multi-scale masked autoencoders for hierarchical point cloud pre-training.In Proceedings of Advances in Neural Information Processing Systems (NeurIPS), New Orleans, Louisiana, USA, November 28 - December 9 2022.
[66]
Renrui Zhang, Liuhui Wang, Yu Qiao, Peng Gao, and Hongsheng Li.Learning 3d representations from 2d pre-trained models via image-to-point masked autoencoders.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21769–21780, Vancouver, Canada, Jun 18-22 2023.
[67]
Taolin Zhang, Jiawang Bai, Zhihe Lu, Dongze Lian, Genping Wang, Xinchao Wang, and Shu-Tao Xia.Parameter-efficient and memory-efficient tuning for vision transformer: A disentangled approach.arXiv preprint arXiv:2407.06964, 2024.
[68]
Taolin Zhang, Sunan He, Tao Dai, Zhi Wang, Bin Chen, and Shu-Tao Xia.Vision-language pre-training with object contrastive learning for 3d scene understanding.In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7296–7304, 2024.
[69]
Zaiwei Zhang, Rohit Girdhar, Armand Joulin, and Ishan Misra.Self-supervised pretraining of 3d features on any point-cloud.In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10252–10263, October 2021.
[70]
Xin Zhou, Dingkang Liang, Wei Xu, Xingkui Zhu, Yihan Xu, Zhikang Zou, and Xiang Bai.Dynamic adapter meets prompt tuning: Parameter-efficient transfer learning for point cloud analysis.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14707–14717, 2024.
[71]
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang.Vision mamba: Efficient visual representation learning with bidirectional state space model.arXiv preprint arXiv:2401.09417, 2024.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









