







我们知道 利用BeautifulSoup解析网页可以根据树以及各个标签来爬去 ,但是有个问题我们不能忽略,比如
1 BeautifulSoup
只要目标信息的旁边或者附近有标签就可以调用 ,,不用管是几层标签(父辈 后代辈 的都可以)。
Soup.html.body.h1
Soup.body.h1
Soup.html.h1
Soup.h1
从上述可以看出来 我们存在以下疑问:
1为什么一个标签会有这么多表示的形式,有啥用?
2一个网页可能有很多相同的标签(如网页 d标签可能存在10个以上),那我们怎么能定位到自己想要的标签中?
想想这些问题确实棘手,但是如果认真品读的话,你会发现这两个问题相辅相成,可以互为答案。两个问题,结合再一起,可以解决彼此的问题了
我们再遍历标签时,需要提取自己需要的关键信息,并且需要用独一无二的方式表达出该标签与其他同类标签不同,那么问题就迎刃而解了。
多说无益 我们来个几个例子。
例子1:

我们来看下经典案例 中国最好大学排名。
我们要爬去 大学名字 tbody→tr→ td (找到tbody也挺重要的 因为可能文章中出现多个tr,如果没有tbody限制,可能爬去的内容会过多,或者出现爬去不到的结果)。
我们这里根据上面的方法可以有两种方案 一种是直接爬去(更直观,但是需要自己分出每个标签的关系):
这里我们注意到 奇数和偶数不一样 奇数项多了个tr的class 而偶数则没有 所有不能通过这个class来提取tr
方案一:
a=soup.find("tbody").findAll("tr") for i in a: tds = i("td")#不能用tr.attrs["td"] 因为这是个列表了 而不是BeatutifulSoup类型的数据了 ulist.append([tds[0].string])
即先找到tbody标签 然后再爬去tbody下的标签tr有了限制,然后再把tr标签下的td标签的string爬去出来就可以了。此方法一目了然,但是需要自行分析。
方案二:
soup = BeautifulSoup(html, "html.parser") for tr in soup.find('tbody').children: if isinstance(tr, bs4.element.Tag): tds = tr('td') ulist.append([tds[0].string])
这个方法就是直接在tbody中提取标签tr 加了一个判断 如果是标签再执行,如果不是我们就不用过问
这样的好处就是可以很快的提取我们想要的标签,并且淘汰掉我们不用的标签。
例子2
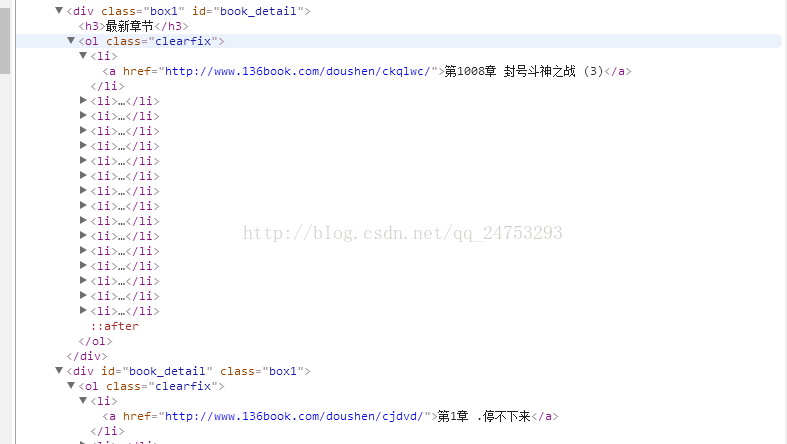
例如这个例子中,我们可以观察到,我们要按顺序爬去每一章节的小说,div→o1→li→a 如果按这个顺序可以。但是我们运行完毕才会发现
爬去的是993-1008章节的数据。 为什么呢 我们返回来看一下小说原来的目录
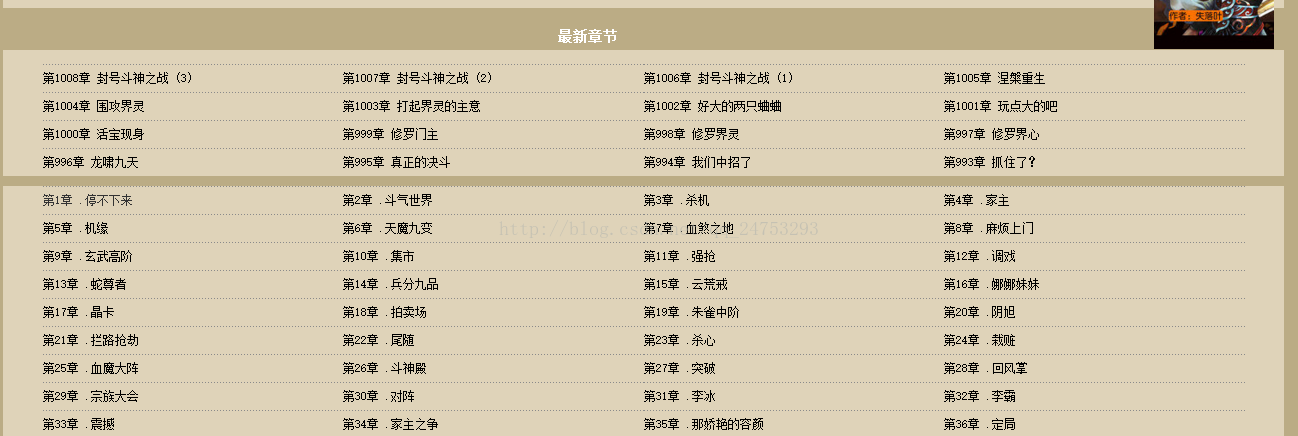
原来他吧最新更新都放在了前面了
方案一
我们要按顺序爬去只能爬第二个div
soup = BeautifulSoup(r.content, "lxml") soup_texts = soup.find("ol", {"class":"clearfix"}).find_next("div") for link in soup_texts.findAll("li"): # if link != '\n':#滤除回车 print(link.a.string +":",link.a.attrs['href'])
这里先找到01这个标签 然后把包含01这个标签的div找到 ,并且是找到第二个
意思就是 找到第二个div标签下的01标签 命名为soup_texts
然后遍历01这个标签 找到所有的li标签 输出a标签下的string和href
然后就可以吧章节和章节连接找到了。
方案二
soup = BeautifulSoup(html, 'lxml') soup_texts = soup.find('div', id = 'book_detail', class_= 'box1').find_next('div') for link in soup_texts.ol.children: if link != '\n': print(link.text + ': ', link.a.get('href'))
直接找div标签 然后在找第二个标签
找到div标签之后 遍历所有的孩子标签,组成了一个set集合 说明children是一个集合 并不是beautifulSoup的索引项 并不能利用遍历的方法索引
在集合中每一个章节内容都存在set集合里面
我们要通过set集合索引找出来所有的有用信息,必须过滤出去换行,才能把每个内容都涵盖
children集合是这样的
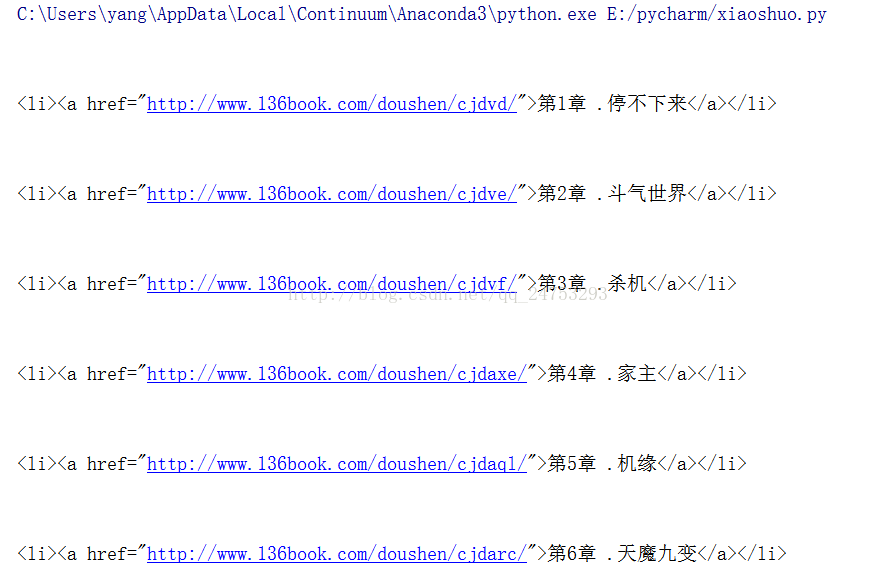
所以我们要避免换行符引起的干扰。
这里我们来看下children里面到底是怎么样的
我们知道单独一行 <li><a href="http://www.136book.com/doushen/cjekxe/">第196章 .边境小镇</a></li>
我们是可以用BeautifulSoup分析的 但是如果索引children这个集合则不能用了,
但是我们link遍历的时候每一个都是一个小的子集 类似上面单独一行,而这小小的一行则是BeautifulSoup中的元素
则 link.string link.text都是可以用的














 675
675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









