




1、一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个
没有Shuffle关系的Task组成
2、任务调度的首要环节,是 DAGScheduler 以 Shuffle 为边界,把计算图 DAG 切割为多个执行阶段Stages。显然,Shuffle 是这个环节的关键,由于 Shuffle 的计算几乎需要消耗所有类型的硬件资源,比如 CPU、内存、磁盘与网络,在绝大多数的 Spark 作业中,Shuffle 往往是作业执行性能的瓶颈,因此,我们必须要掌握 Shuffle 的工作原理,从而为 Shuffle 环节的优化打下坚实础。
3、Shuffle 的本意是扑克的“洗牌”,在分布式计算场景中,它被引申为集群范围内跨节点、跨进程的数据分发
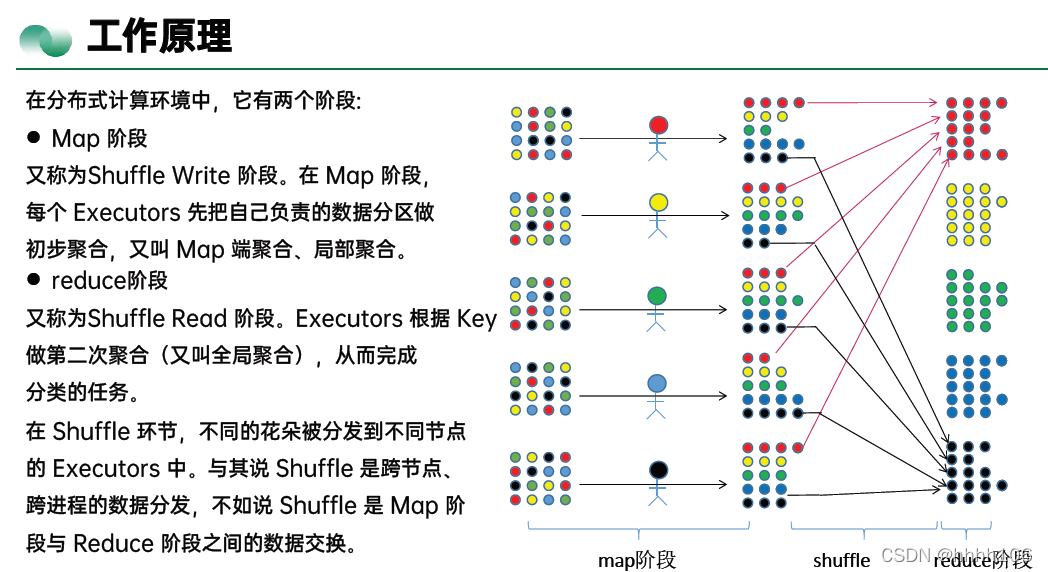
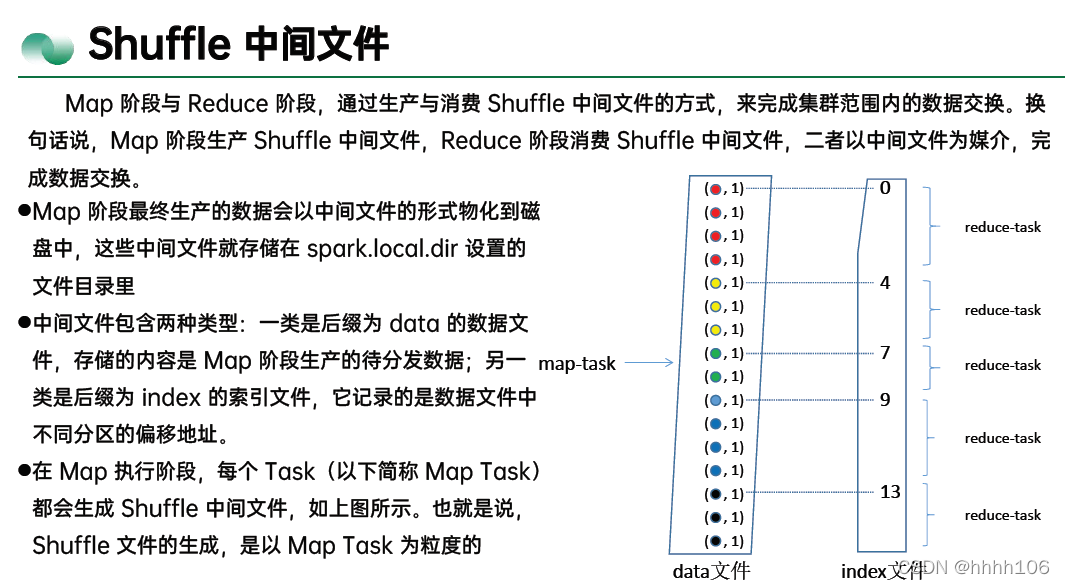

4、Shuffle 在 Reduce 阶段是主动地从 Map 端的中间文件中拉取数据,Reduce 阶段不同的 Reduce Task 拉取数据的过程,往往也被叫做 Shuffle Read。
shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
5、对于图中的 Shuffle 0 来说,Stage 0 是 Map 阶段,Stage 1 是 Reduce 阶段。但是,对于后面的Shuffle 1 来说,Stage 1 就变成了 Map 阶段。因此你看,当我们把视角拉宽,Map 和 Reduce 这两个看似对立的东西,其实有很多地方都是相通的

6、应对Shuffle
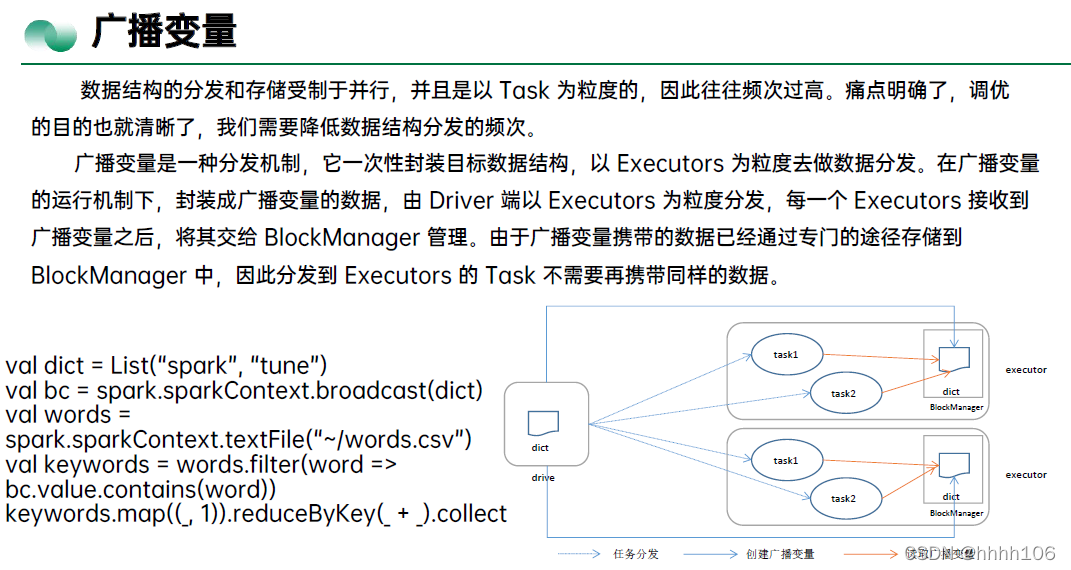
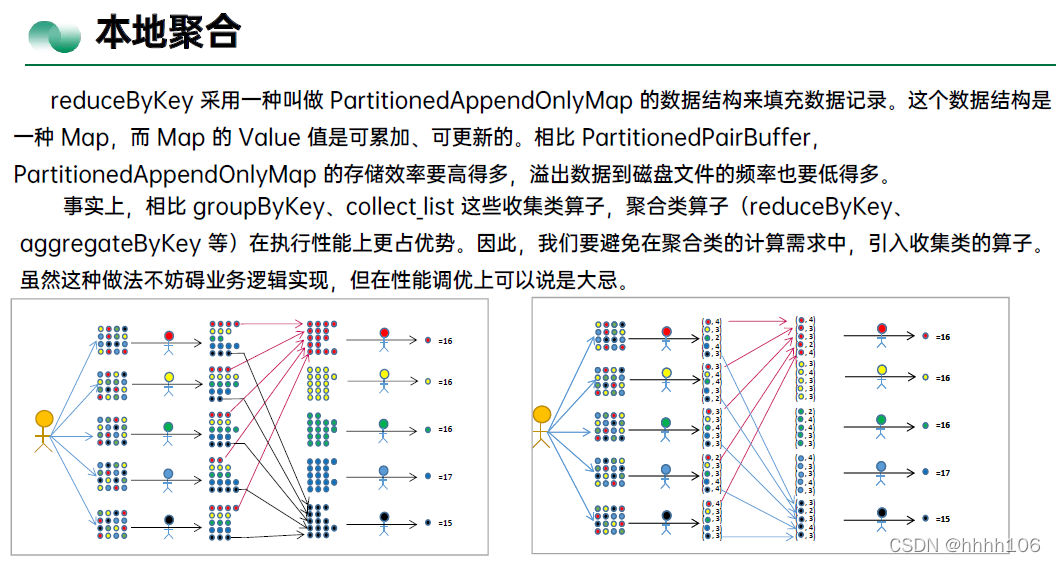
- 消灭shuffle:广播变量


















 2494
2494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









