








Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.
Beautiful Soup安装
- pip安装:现在Beautiful Soup版本为4.x,建议使用最新版,3.x已经停止开发了。使用命令
pip3 install beautifulsoup4。 - wheel安装:如果由于 网络问题无法安装成功,我们可以下载wheel文件再本地离线安装。下载地址:https://pypi.org/project/beautifulsoup4/#files。
解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml .务必安装好lxml。另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:pip install html5lib。
下表列出了主要的解析器,以及它们的优缺点:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") |
|
|
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") |
|
|
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml", "xml"]) BeautifulSoup(markup, "xml") |
|
|
| html5lib | BeautifulSoup(markup, "html5lib") |
|
|
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
对象的种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment 。
直接选择节点
示例html:
html_doc = """
<html><head><title>Test Html</title></head>
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="item-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a>
"""
示例代码:
from bs4 import BeautifulSoup
html = '''
<html><head><title>Test Html</title></head>
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="item-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
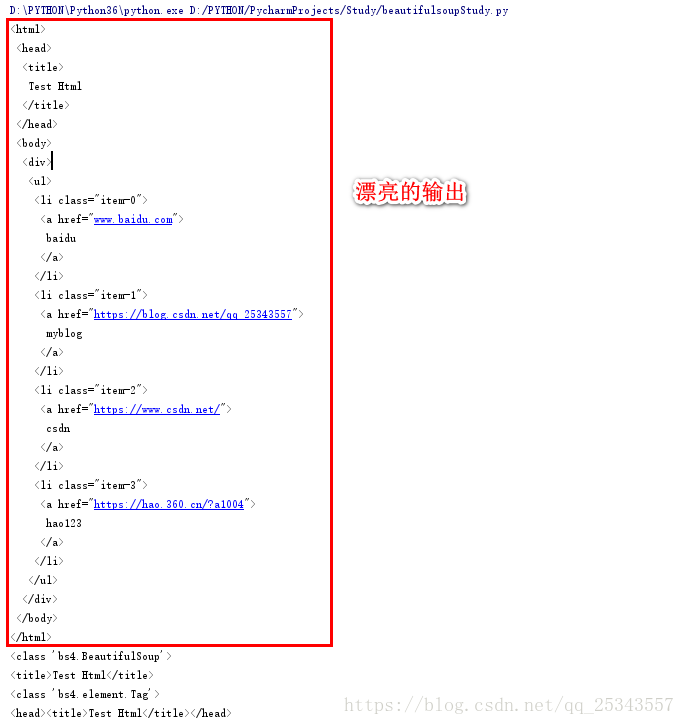
soup = BeautifulSoup(html,'lxml')#选择lxml作为解析器
print(soup.prettify())#自动更正格式,使输出更美观
print(type(soup))
print(soup.title)#选择title节点
print(type(soup.title))
print(soup.head)
可以看见soup的类型是<class 'bs4.BeautifulSoup'>,选择到的节点title的类型是<class 'bs4.element.Tag'>
Tag
Tag有很多方法和属性,现在介绍一下tag中最重要的属性: **name和attrs**。- name
每一个Tag都有自己的name,使用.name可以获取name.
from bs4 import BeautifulSoup
html = '''
<html><head><title>Test Html</title></head>
'''
soup = BeautifulSoup(html,'lxml')#选择lxml作为解析器
print(soup.title.name)#选择title节点,获取name
我们可以获取name,同时我们也可以修改name,,但是不建议这么做,这样会破坏原来的Beautiful Soup对象生成的HTML文档。
- attrs
示例代码:
from bs4 import BeautifulSoup
html = '''
<ul>
<li class="item-0" name="one"><a href="www.baidu.com">baidu</a>
'''
soup = BeautifulSoup(html,'lxml')#选择lxml作为解析器
print(soup.li.attrs)#获取所有属性,返回字典形式
print(soup.li.attrs['class'])#获取li节点的class属性值
print(soup.li['class'])#获取li节点的class属性值
print(soup.li.get('class'))#获取li节点的class属性值
print(soup.li['name'])#获取li节点的name属性值
我们可以使用.attr 获取到Tag对象的所有属性值,返回的是字典格式,所有可以使用['key'] 来获取指定的属性值。简单一点我们也可以省略attrs,直接使用tag['key'] 来获取。

- string获取内容
可以使用string属性获取节点包含的文本内容。
from bs4 import BeautifulSoup
html = '''
<ul>
<li class="item-0" name="one"><a href="www.baidu.com">baidu</a>
<li class="item-1" name="two"><a href="www.alibaba.com">alibaba</a>
'''
soup = BeautifulSoup(html,'lxml')#选择lxml作为解析器
print(soup.a.string)
同时我们也可以发现使用soup.tag所获取到的是第一个节点。
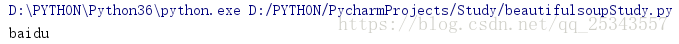
BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象。但是,因为 BeautifulSoup 对象并不是真正的HTML或XML的tag,所以它没有name和attrs属性。但有时查看它的 .name 属性是很方便的,所以 BeautifulSoup 对象包含了一个值为 “[document]” 的特殊属性 .namefrom bs4 import BeautifulSoup
html = '''
<ul>
<li class="item-0" name="one"><a href="www.baidu.com">baidu</a>
'''
soup = BeautifulSoup(html,'lxml')#选择lxml作为解析器
print(soup.name)

嵌套选择节点
Tag对象同样可以调用节点进行下一步的选择。
from bs4 import BeautifulSoup
html = '''
<ul>
<li class="item-0" name="one"><a href="www.baidu.com">baidu</a>
<li class="item-1" name="two"><a href="www.alibaba.com">alibaba</a>
'''
soup = BeautifulSoup(html,'lxml')
print(soup.li.a.string)
关联选择节点
关联选择,即寻找父节点,子节点或者兄弟节点。
1、选择子节点和子孙节点
选择直接子节点示例:
from bs4 import BeautifulSoup
html = '''
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<body>
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a></li>
<li class="item-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a></li>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a></li>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a></li>
</ul>
</div>
</body>
</html>
'''
soup = BeautifulSoup(html,'lxml')
print(soup.ul.contents)
结果如下:
['\n', <li class="item-0"><a href="www.baidu.com">baidu</a></li>, '\n', <li class="item-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a></li>, '\n', <li class="item-2"><a href="https://www.csdn.net/">csdn</a></li>, '\n', <li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a></li>, '\n']
contents 属性只返回直接子节点,也许看见a节点会疑惑,不是值返回直接子节点吗?应该只有li节点才对呀!但是,我们要注意的是a 节点并没有单独作为一项,所以确实是返回了直接子节点。还可以使用children 属性获取直接子节点。
选择子孙节点示例:
使用descendants 属性可以获取当前节点所有的子孙节点。
soup = BeautifulSoup(html,'lxml')#html内容如上
for i,child in enumerate(soup.ul.descendants):
print(i,child)
descendants 会递归查询所有的子节点,同时也获取文本内容。

2、选择父节点和祖先节点
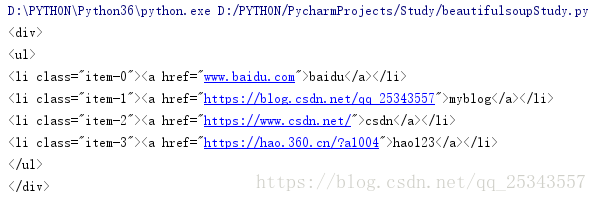
**选择父节点示例:** 使用`parent` 属性可以获取当前节点的父节点。soup = BeautifulSoup(html,'lxml')
print(soup.ul.parent)
获取到了ul 节点的父节点div 输出结果是div节点及内部的内容。
选择祖先节点示例:
使用parents 属性可以获取当前节点的祖先节点。
from bs4 import BeautifulSoup
html = '''
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<body>
<div>
<ul>
</ul>
</div>
</body>
</html>
'''
soup = BeautifulSoup(html,'lxml')
for i,parent in enumerate(soup.ul.parents):
print(i,parent)

3、选择兄弟节点
示例代码:from bs4 import BeautifulSoup
html = '<b>b</b><p>人生苦短,我学Python!</p><ul><li>li</li></ul><a href="www.baidu.com">baidu</a><i>i</i>'
soup = BeautifulSoup(html,'lxml')
print("Next sibling:",soup.ul.next_sibling)#返回相邻的下一个同级节点
print("Previous sibling:",soup.ul.previous_sibling)#返回相邻的前一个同级节点
print("Next siblings:",list(soup.ul.next_siblings))#返回下面的所有同级节点
print("Previous siblings:",list(soup.ul.previous_siblings))#返回前面的所有同级节点

使用查询方法搜索
上面选择节点的方法太单一了,不适合实际开发使用。Beautiful Soup提供了一些查询方法供我们使用。
find_all( name , attrs , recursive , text , **kwargs )
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件。 **参数介绍:**- name :查找所有名字为 name 的tag,字符串对象会被自动忽略掉;
- attrs:根据属性查询,使用字典类型;
- text :可以搜搜文档中的字符串内容.与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表, True ;
- recursive:调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False ;
- limit:find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果;
- class_ :通过 class_ 参数搜索有指定CSS类名的tag,class_ 参数同样接受不同类型的 过滤器 ,字符串,正则表达式,方法或 True。
示例代码如下:
from bs4 import BeautifulSoup
import re
html = '''
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<body>
<div>
<ul>
<li class="sp item-0" name='one'><a href="www.baidu.com">baidu</a></li>
<li class="sp item-1" name='two'><a href="https://blog.csdn.net/qq_25343557">myblog</a></li>
<li class="sp item-2" name='three'><a href="https://www.csdn.net/">csdn</a></li>
<li class="sp item-3" name='four'><a href="https://hao.360.cn/?a1004">baike</a></li>
<li class="sp item-4" name='four'><a id='lastA' href="https://hao.360.cn/?a1004">hao123</a></li>
</ul>
</div>
</body>
</html>
'''
soup = BeautifulSoup(html,'lxml')
#根据name查询节点
print("name为ul的节点:",soup.find_all(name='ul'))
#根据name嵌套查询li节点
print('根据name嵌套查询li节点:')
for ul in soup.find_all(name='ul'):
print(ul.find_all(name='li'))
#根据attrs查询节点
print('根据attr查询节点:',soup.find_all(attrs={'name':'two'}))
print('根据attr查询节点:',soup.find_all(attrs={'class':'sp item-0'}))
#对于常用的属性我们可以不需要使用attrs,使用以下方法:
#根据class_查询
print('根据class_查询节点:',soup.find_all(class_='sp item-2'))
#根据id查询
print('根据id查询节点:',soup.find_all(id='lastA'))
#根据text查询节点
print('根据text查询节点:',soup.find_all(text='baidu'))
print('根据text查询节点2:',soup.find_all(text=re.compile("bai")))
#对比设置recursive
print('recursive为True:',soup.div.find_all(name='li',recursive=True))#默认为True
print('recursive为False:',soup.div.find_all(name='li',recursive=False))
#设置limit
print('不设置limit:',soup.ul.find_all(name='li'))
print('设置limit为2:',soup.ul.find_all(name='li',limit=2))
find_all() 几乎是Beautiful Soup中最常用的搜索方法,所以我们定义了它的简写方法. BeautifulSoup 对象和 tag 对象可以被当作一个方法来使用,这个方法的执行结果与调用这个对象的 find_all() 方法相同,下面两行代码是等价的:

soup.find_all("a")
soup("a")
这两行代码也是等价的:
soup.title.find_all(text=True)
soup.title(text=True)
find( name , attrs , recursive , text , **kwargs )
find\_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果.比如文档中只有一个标签,那么使用 find_all() 方法来查找标签就不太合适, 使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法.下面两行代码是等价的:soup.find_all('title', limit=1)
soup.find('title')
唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果.find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None .
其他方法
- find_parents()和find_parent():前者返回所有祖先节点,后者返回直接父节点。
- find_next_siblings()和find_next_sibling():前者返回后面所有的兄弟节点,后者返回后面第一个兄弟节点。
- find_previous_siblings和find_previous_siblling():前者返回前面所有的兄弟节点,后者返回前面第一个兄弟节点。
- find_all_next()和find_next():前者返回节点后所有符合条件的节点,后者返回节点后第一个符合条件的节点。
- find_all_previous()和find_previous():前者返回节点前所有符合条件的节点,后者返回节点前第一个符合条件的节点。
CSS选择器
Beautiful Soup支持大部分的CSS选择器 [6] ,在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数,即可使用CSS选择器的语法找到tag。
通过tag标签逐层查找
soup = BeautifulSoup(html,'lxml')#html如上
print(soup.select('ul li a'))

查找直接子标签
soup = BeautifulSoup(html,'lxml')
print(soup.select('ul > a'))
print(soup.select('li > a'))

通过CSS的类名查找
soup = BeautifulSoup(html,'lxml')
print(soup.select('.item-0'))
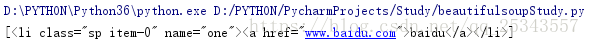
通过属性的值来查找
soup = BeautifulSoup(html,'lxml')
print(soup.select('li[name="one"]'))
获取文本内容
可以调用string和get_next()方法获取文本内容。soup = BeautifulSoup(html,'lxml')
for a in soup.select('a'):
print(a.string)
for a in soup.select('a'):
print(a.get_text())
获取属性值
soup = BeautifulSoup(html,'lxml')
for a in soup.select('a'):
print(a['href'])















 1261
1261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









