






MySQL架构的特点:
基于C/S 架构模型
基于线程工作
同时MySQL 是一个独立的进程
客户端:需要专门的客户端工具 可能是SQL的接口访问Mysql
要执行SQL语句操作需要用到SQL接口 客户端可能有N多种 对于用户需要提供驱动
Connetort 客户端通过连接器连接到服务器上 服务器上有专门的组件用于响应
客户端发起的请求 这个组件的名称叫 连接/线程处理

服务器端 :包含以下几部分
连接/线程处理
查询缓存
分析器
优化器
存储引擎
每一个客户端发起一个新的请求都由服务器端的连接/线程处理工具负责接收客户端的请求并开辟一个新的内存空间 在服务器端的内存中生成一个新的线程, 当每一个用户连 接到服务器端的时候就会在进程地址空间里生成一个新的线程 用于响应客户端请求 用户发起的查询请求都在线程空间内运行, 结果也在这里面缓存并返回给服务器端.线程的 重用和销毁 都是由连接/线程处理管理器实现的
综上所述:用户发起请求 连接/线程处理器 开辟内存空间 开始提供查询的机制
接下来用户发起SQL 查询语句 用户的SQL语句 在连接/线程处理器接收 接收下来后 开始交给服务器端的核心组件来查询 为了加速 MySQL 的查询速度 提供了一个查询缓存 空间 如果同一个SQL语句此前被查询过了结果符合某个特定条件 就会保存在查询缓存空间里 因此第二次执行这条语句的时候 就直接返回结果 这样大大的提高了MySQL检 索响应速度。 如果缓存中没有响应的语句(缓存未命中)此时就交给分析器
分析器分析用户发起的SQL语句 把语句进行切片 该分析器包括词法分析和语法分析两部分 语法分析器用来分析接收到的语句语法是否正确 如果语法是错误的就不用执行这 条语句了 如果语法分析无误 (syntex 0K !) 接下来就做词法分析, 词法分析 就是把接收到的语句进行切片 一段一段用空格分开 因为分析器分析的结果要送达给解释器 进行 执行的 【命令 选项 参数】
为什么要进行词法分析呢?
SQL 有个最重要的特点 在数据库的表中的检索特定字段的数据时 不同数据库不同表 是不一样的 字段不一样 就必须要把接收到的语句进行切片才能找到特定的字段值
词法分析后的结果发现没有问题
分析的结果交给优化器进行优化 怎么进行优化呢
有N中执行办法 N中执行路径 是否用到数据库 执行路径中哪个速度最快 都是优化过程需要考虑的问题 优化器的主要目的就是从N中执行路径中选择一种最快的 并生成对应 的可执行的二进制格式 并进行执行 ,选一个最优的执行
执行就是从存储在磁盘中的文件中检索一个最优的数据
真正存储在磁盘上的数据是由存储引擎管理的, 存储在文件系统或者是裸设备上的数据管理程序
本身能提供给上层应用不同的功能 不同的存储引擎具有不同的特性
--------------------------------------------------------------------------------------------------------------
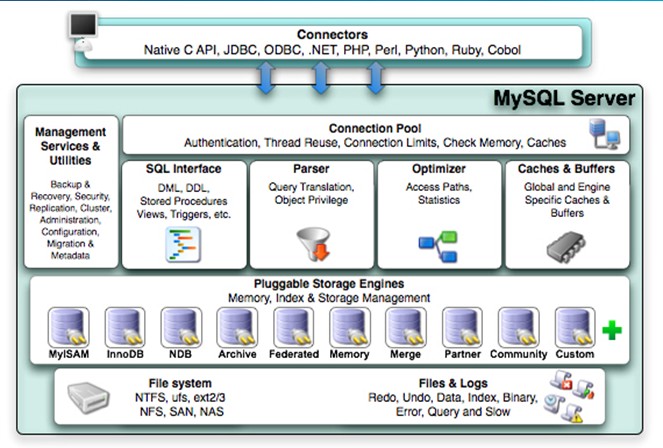
核心组件包含
SQL interface
用户发过来的SQL命令都由SQL接口接收
本地API发送来的请求则是由其他机制接收
DML 数据操作语言 data manipulation language
update,delete,
e.g. 查询一行数据、删除一行数据、修改一行数据 // 实现数据本身的操作
DDL 数据定义语言 data difinition language
CREATE,DROP
e.g. 创建一个新的数据库、创建一个新的表、创建一个新的索引
help CREATE TABLE
存储过程
视图
触发器
Parser 分析器
查询事情
对象权限
词法分析句法分析
Optimizer 优化器
访问路径 执行路径 实现统计
Caches&Buffers 缓存和缓冲
全局定义
特定的缓存缓冲
Pluggable Storage Engines 插件式存储引擎
数据库提供了大量的数据
MySQL是提供数据库的管理软件 管理数据库中的数据
数据库的物理结构是一个个的文件 逻辑上看是一个个的表
如何组织 对应的表怎么转化成物理文件 靠MySQL 提供的存储引擎来实现 一一对应起来
用户可以自己选择 因为是插件式的存储引擎 把表和数据文件对应起来
存储引擎:将逻辑结构转换成物理结构的程序
MySQL 插件式存储引擎 使用灵活 最终形成的文件要保存在磁盘分区上 分区上与文件系统相关
数据库对象 :
表,二维关系 // 逻辑上是以表的形式存储
记录
字段
索引
视图
触发器
存储过程
存储函数
时间调度器
用户
游标
元数据库信息保存在数据中
// 物理上对应于一个文件存储















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









