






本文主要是对前一段时间的深度学习进行归纳总结,其中有参考几位主要博主的理解,也有自己对大神论文的一些翻译及看法,如有问题,欢迎大家指正;
深度学习
深度学习主要是对人工神经网络的延伸,它的目的主要是模拟人脑的机制来解释图像,深度学习通过组织底层特征来形成更加高级的高层特征来表示属性和类别,深度学习算法包括限制波尔兹曼机和CNN网络等,本文主要讲解CNN网络,其实就是在看完个博主文章后还有很多不懂的地方的进一步梳理。
1. CNN 网络
CNN即convolutional Neutral Network, 也叫卷积神经网络,类似于认得神经元,不同神经元有不同的功能,卷积神经网络中主要有两类神经元,一类是C元,一类是S元,C代表convolution, 即卷积,卷积操作主要用于特征提取,S代表subsampling,就是下采样,也叫特征映射,其实就是池化操作;因此卷积神经网络也主要由C层和S层组成,C层为特征提取层,每个神经元的输入与前一层的局部感受野相连,并提取该局部的特征,一旦该局部特征被提取后,它与其他特征间的位置关系也随之确定下来;S层是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。同时,也包括一个激活函数,主要就是将特征进行分类,可以为sigmoid激活函数或RELU函数,Sigmoid的优点是输出范围有限,所以数据在传输过程中不易发散。
卷积神经网络概论图
卷积神经网络中卷积和下采样都是通过窗口实现的,卷积层一帮为3*3或5*5的窗口,依次划过原图,从而产生一系列特征图,下采样层一般为2*2的窗口,可以进行均值采样或者最大值采样等,下面就已LeNet为力,重点说一下卷积神经网络,我可能更加注重那些没有在其他自己很容易糊涂的细节。
INPUT:输入图片,32*32像素;
C1: 6个5*5的卷积核,产生6个28*28的特征图;
S2:用2*2的窗口进行下采样,产生6个14*14的特征图;
C3:用16个5*5的卷积核,每层以不定个数的S2层特征图为输入,产生16层10*10的特征图;(这里的不定个数指的是可能是两个如1,3,也3个,1,3,5)
S4:用2*2的窗口进行下采样,产生16个5*5的特征图;
C5:用120个5*5的卷积核,每层以S4层全部16个特征图为输入,产生120个1*1的特征图;(这里全部的特征图作为输入不是必须,如果特征图过多,也可以选择部 分作为输入,所以C5层不是全链接层)
F6:用84个1*1的卷积核,每层以C5层全部120个特征图为输入,产生84个1*1的特征图;
(这里才是必须适用上一层所有的图作为输入,故称为全连接层,用来把前面提取到的特征综合起来,需要固定大小的输入)
这里说到以部分或者全部的卷积特征图作为输入,那么具体过程是什么呢,以C3层的产生为例子,假设现在以S2的3个特征图作为输入,那我们就可以进行选择,比如选择特征图1,3,5;那么现在你就拿着这16个卷积核中其中一个分别对特征图1,3,5进行卷积,这样就可以得到三个结果,其实就是三个矩阵,然后对这些矩阵分配权值,就是分配他们所占的比重,加入偏置后得到一个矩阵,这个矩阵就是C3的一个特征图;
一直提到权值和偏置,这里插入一张自己总结的图片,同时也奉上一个讲解很清楚的链接:
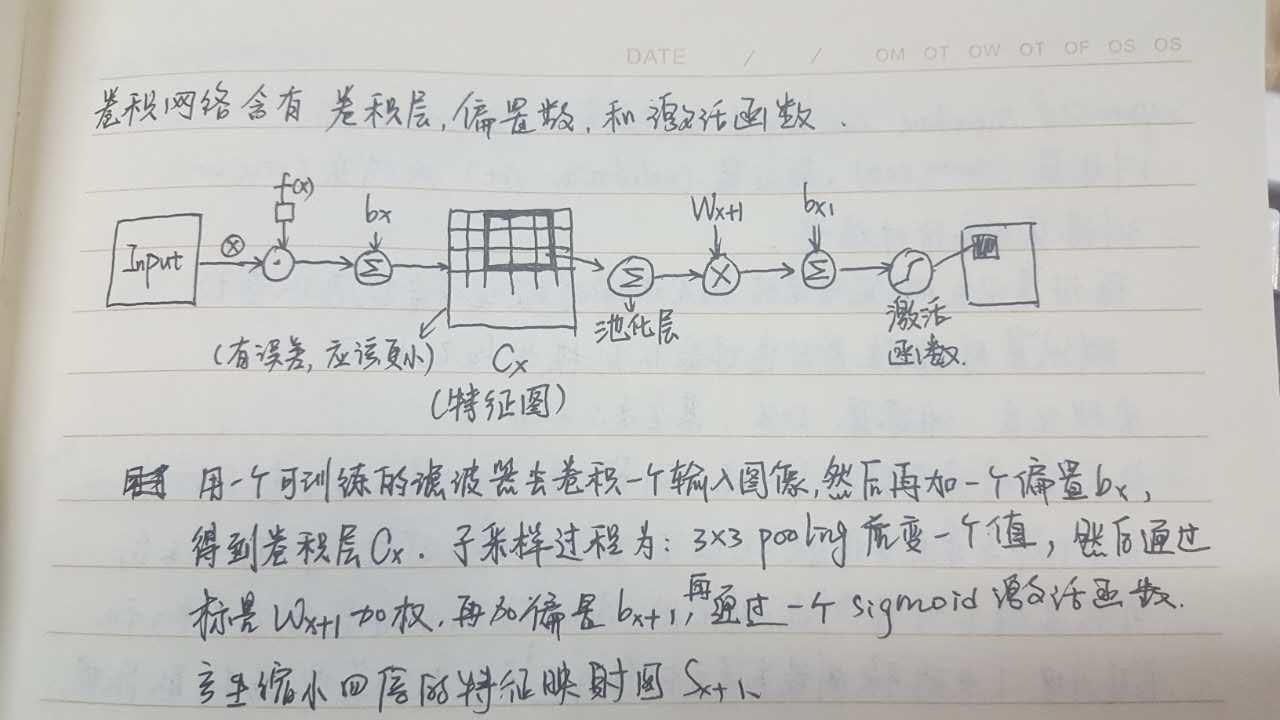
由于CNN是针对于整个图片进行滑动卷积,没有针对性,因此就诞生了RCNN,即基于Region的CNN,它的原理主要是先用selective search的方法选取出可能的区域,就是有关键信息的区域进行裁剪或者拉伸,这里裁剪和拉伸的目的主要是生成固定大小的图片用于全链接层的输入,为了方便计算,全链接层处需要每个区域都是固定大小的图片,但是实际上裁剪和拉伸都会造成图片信息的流失,这里先大概介绍RCNN的过程:
•步骤:
•1. 用selectivesearch 将一张图像生成1K~2K个候选区域
2. 对每个候选区域,wrap 或crop成固定大小(227*227)的图像输入到CNN中,使用深度网络提取特征 (因为FC层的输入需要固定的大小,因此预处理是必须的)
3. 特征送入每一类的SVM 分类器,判别是否属于该类
4. 使用回归器(bounding-box regression)精细修正候选框位置,即对于SVM分好类的RegionProposal做边框回归
这里我在学习的时候遇到的问题是如何定位,其实这就是边框回归的作用,在selective search时会保留图片的坐标,在分好类后,又会利用边框回归返回区域的精确位置,从而从原图中圈出,具体如下:
bounding box 用于对前期选定的region proposal做微调,虽然图中region proposal 圈定了目标,但如果跟ground truth的对比IOU小于0.5, 也是属于错误圈定,因此会根据ground truth做出调整。
假设蓝色为之前圈定的region proposal,粉色为手动标注的ground truth(因为CNN为监督学习的深度网络,所以需要手动输入参考数据,这个手动输入的数据就是ground truth),黑色为最后修订的结果,
则设划定的region proposal P 坐标为(Px,Py,Pw,Ph),x,y代表窗口中心点坐标,w,h表示举行的长和宽,
手动标定的Ground Truth G 坐标为(Gx,Gy,Gw,Gh),则边框回归几位找到黑色的框G',
根据给定的P,求取函数映射使得f(P)=G'约等于G;更详细的讲解参见此;















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









