






译自confluence官网: Transactional Messaging in Kafka
kafka提供了at-least-once的消息保证。duplicate会出现因为producer重试或者consumer在失败后重启。
去提供exactly-once消息语义的一个方法是实现一个idempotent producer。在idempotent producer(传送门)的
建议中已经详细介绍了这一点。一个可选择的且更普遍的方法是支持事务性消息。除了传统的idempotent producer用例之外,
还可以启用用例,例如复制日志记录以用于事务数据服务。
producer可以明确地启动transactional Session(事务会话),在这些会话中发送transactional message,并提交或中止事务。 通过列举功能要求,我们可能最好地理解我们旨在实现transaction的保证。
1、atomicity:未提交事务的message不应该暴露给consumer应用。
2、durability:broker不能丢失任何已提交的事务。
3、ordering:事务感知型的consumer应该看到每个partition内原始事务顺序的事务。
4、interleaving:每个partition应该能接收不管是不是来自transactional producer的消息。
5、在事务中不应该有重复的消息
为了实现transactional message和non-transactional message都能接收的交叉性(interleaving),
transactional message和non-transactional message的相对顺序应该基于non-transactional message的
append和transactional message的final commit的相对顺序。
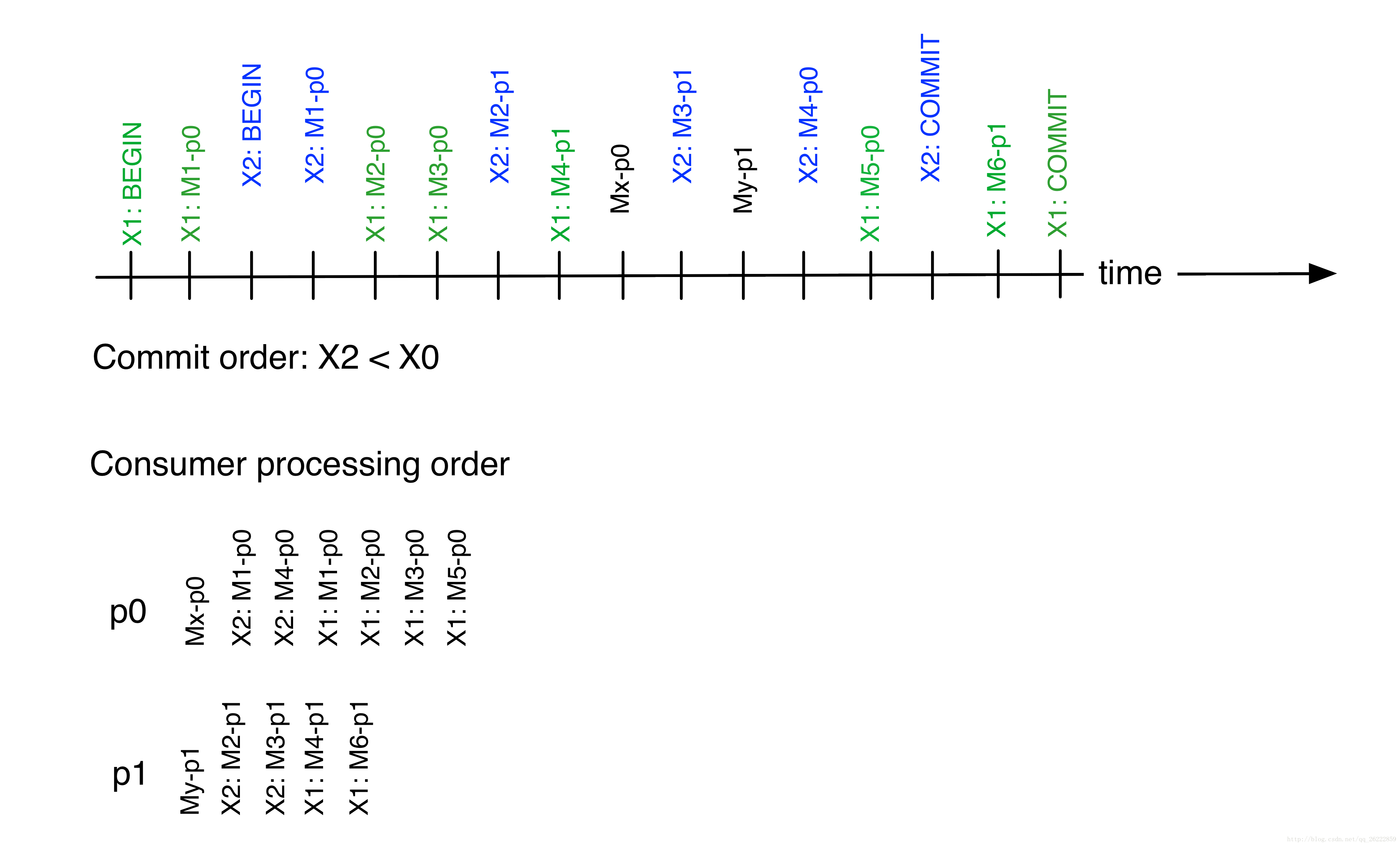
在上面的图片中,partition p0和partition p1接收来自transaction x1和x2的消息,当然也接收non-transactional message。
时间线是消息到达broker的时间。因为x2先提交,每个partition将在X1之前显示来自X2的消息。
既然non-transactional message在x1和x2的提交之前到达,这些消息会在任何transactional message之前显示。
此外,我们对性能,可用性和实现复杂性有以下要求:
1、实现应该是可扩展的。 例如,每个事务的专用日志是不可接受的。
2、performance:
a.一个transactional producer的吞吐量应该和non-transactional producer相当。
b.可接受的延迟 例如,尽可能避免复制transactional data。
c.任何实现都不应该使该partition在不合理的时间段内不可用(例如,由于锁定)。
3、client simplicity:赞成一个可以借用更简单的客户端实现的方案(即使它增加了broker的复杂性)。 例如,consumer实现(内部)缓冲并随后丢弃来自未提交事务的消息是可接受的(但不是理想的)。 即,如果选择的实现允许broker实现来自数据日志中未提交事务的消息。
最后,值得补充的是,任何实现都应该提供将每个tansaction的输入状态与事务本身相关联的能力。 这对于促进transaction的重试是必要的 - 即如果transaction需要中止和重试,则该transaction的整个输入需要重播。
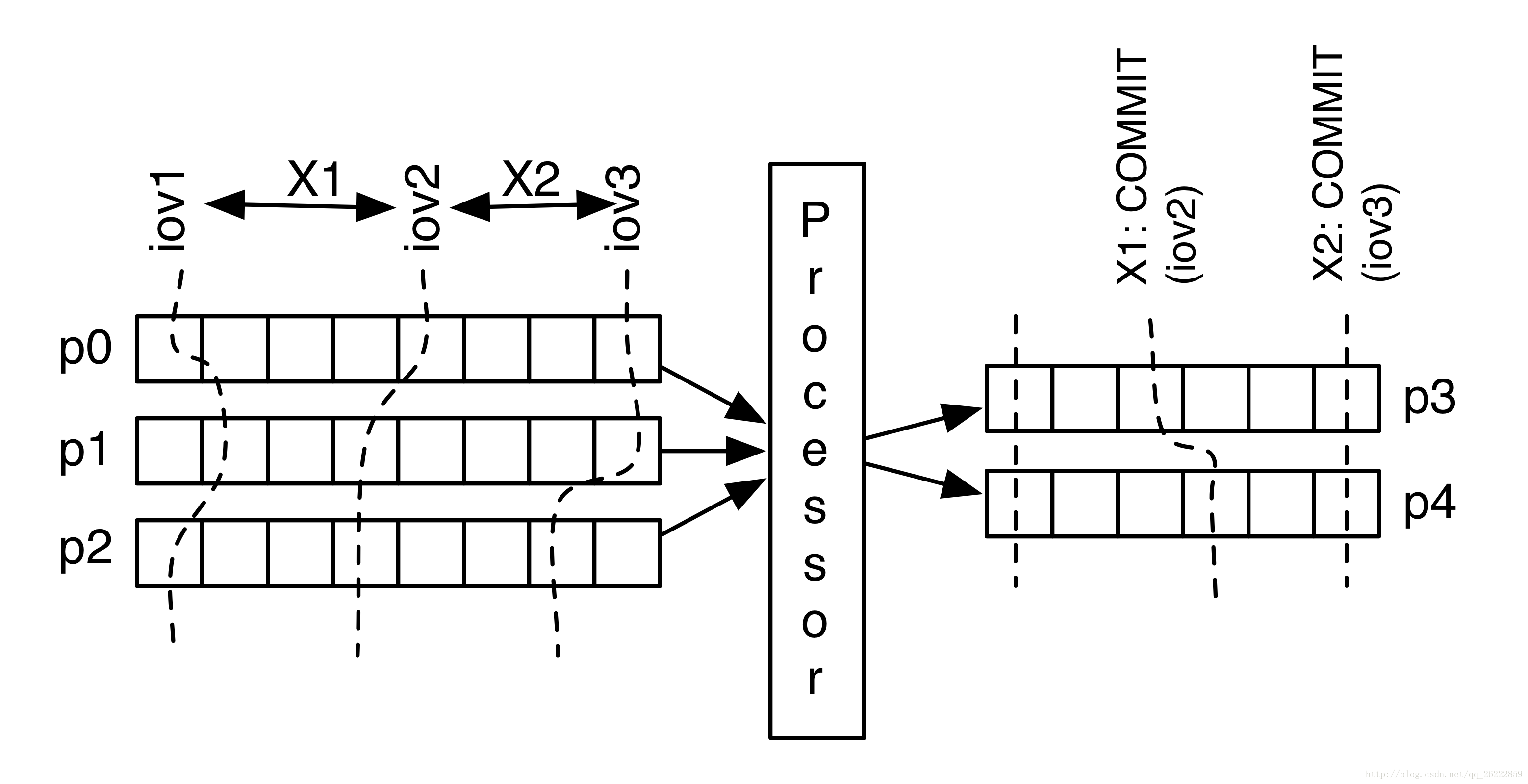
每个transaction都与一个处理后的input bloack(输入块)相关联,并产生输出(事务)。 当我们提交事务时,我们还需要将下一个输入块与该事务相关联。 如果发生故障,processor需要查询(下游Kafka集群)以确定需要处理的下一个块。 在我们的例子中,这只是针对每个事务正在处理的输入分区的输入偏移向量(input offset vector,IOV)。
Implementation overview
在该implementation propasal中,producer将tansactional control message(事务控制消息)发送给高可用性transaction coordinator(事务协调器),该消息用信号通知事务的开始/结束/中止状态,该transaction coordinator使用multi-phase protocol(多阶段协议)来管理事务。 producer将transactional control record(事务控制记录)(开始/结束/中止)发送到transaction coordinator,并将事务的payload(有效负载)直接发送到目标数据分区。 consumer需要具备事务感知能力并缓存每个挂起的事务,直到他们到达相应的结束(提交/中止)记录。
transaction group (事务组)
producer in the transaction group (事务组中的producer)
transaction coordinator for that transaction group (事务组的事务协调器)
leader broker (of that tansaction group) (事务组的leader broker)
consumers of transactions (事务的consumer)
Transaction group
transaction group用于映射到特定的transaction coordinator(例如,基于对日志分区数量的散列)。 组中的producer需要配置为使用此组。 由于这些producer的所有transaction都通过这个transaction coordinator,所以我们可以在这些transactional producer之间实现严格的排序。
Producer IDs and state groups
在本节中,我将介绍为transactional producer引入两个新参数的必要性:producer ID和producer group。 这些不一定需要成为producer配置的一部分,但可以在producer的事务API中指定为参数。
前面的概述描述了需要将producer(或者一般来说某些输入的处理器)的输入状态与最近提交的事务关联起来。 这使得processor可以重新创建一个事务(通过重新创建该事务的输入状态 - 在我们的用例中通常是一个偏移向量)。
我们可以利用consumer的offset manage功能来维持这种状态。 consumer的offset manager将每个key(consumergroup-topic-partition)关联到该分区的最后一个checkpointed offset(检查点偏移量,新概念)和metadata。 在事务处理器的情况下,我们希望保存与transactional commit point(事务提交点)关联的consumer的offset。 这个offset commit record(在__consumer_offsets主题中)应作为事务的一部分写入。 也就是说,存储着consumer group offset的__consumer_offsets主题的分区将需要参与该事务。 所以(举个例子)假设一个producer在事务中失败了(transactional coordinator随后到期); 当producer恢复时,它可以发出offset fetch request来恢复与上次提交的事务相关联的input offset并从该点恢复事务处理。














 1361
1361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









