







在2.3版本中,spark支持以下集群管理
Standalone – 简单易用的集群管理模式。
Hadoop YARN – 应该是目前spark最常用的集群模式了,yarn是hadoop2中的资源管理器。
Apache Mesos – 一个通用的集群,可以运行Hadoop MapReduce 和 service applications。
Kubernetes – 一种用于自动化部署、缩放和管理容器化应用程序的开放源代码系统。
这里主要讲述如何部署Standalone 和 spark on yarn
Standalone模式
在Standalone中,主要分为master与worker,master主要负责资源调度与作业监控,worker负责进行作业,从2.0开始只使用基于netty的RPC通信。
1、如何配置Standalone
1.1 进入 ${SPARK_HOME}/conf 目录,添加如下信息
JAVA_HOME=/usr/java/jdk1.8.0_45 #JDK路径
SPARK_MASTER_HOST=hadoop001 #Master的IP地址,默认的端口为7077
SPARK_WORKER_CORES=4 #节点中允许spark程序使用的最大核数(默认为所有核)
SPARK_WORKER_MEMORY=2g #节点中允许spark程序使用的最大内存(默认为1G),提交spark任务时可以通过设置属性 spark.executor.memory 指定申请需要的内存。1.2 在slaves中添加集群节点IP。
注意(在Standalone下,每个节点的目录信息应该保持一致)
1.3 启动master进程,./sbin/start-master.sh
[root@hadoop001 spark]# ./sbin/start-master.sh
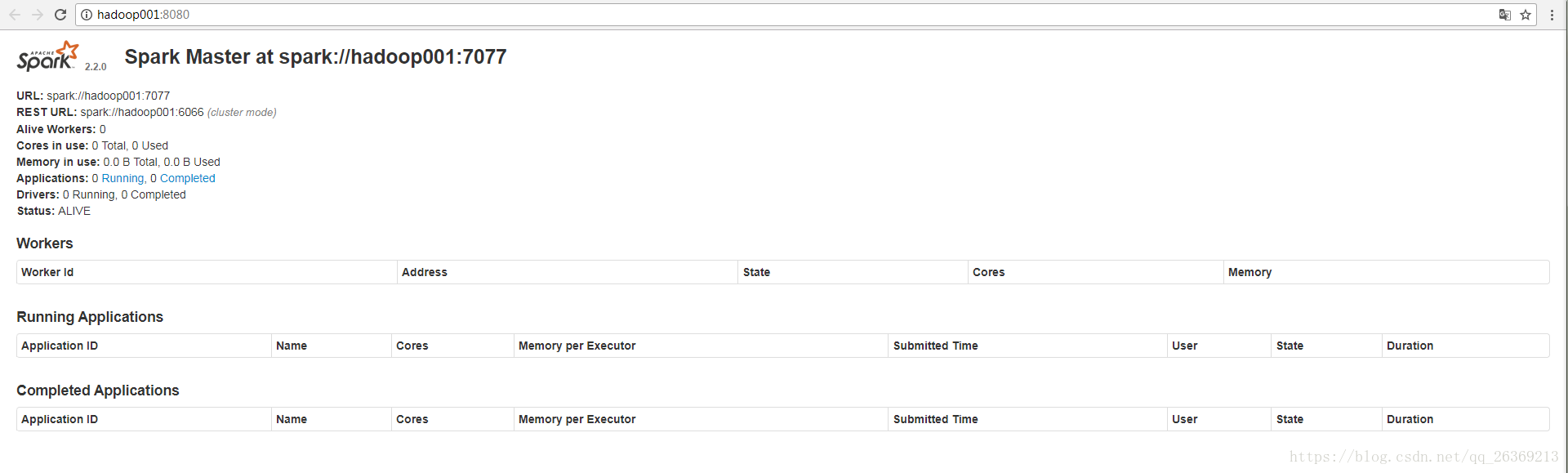
starting org.apache.spark.deploy.master.Master, logging to /opt/software/spark/logs/spark-hadoop001-org.apache.spark.deploy.master.Master-1-hadoop001.out检查日志是否报错,没报错的就可以到web页面看看,默认端口为8080,IP为master的IP。
1.3启动worker
./sbin/start-slave.sh <master-spark-URL>
[root@hadoop001 spark]# ./sbin/start-slave.sh spark://hadoop001:7077
starting org.apache.spark.deploy.worker.Worker, logging to /opt/software/spark/logs/spark-hadoop001-org.apache.spark.deploy.worker.Worker-1-hadoop001.out
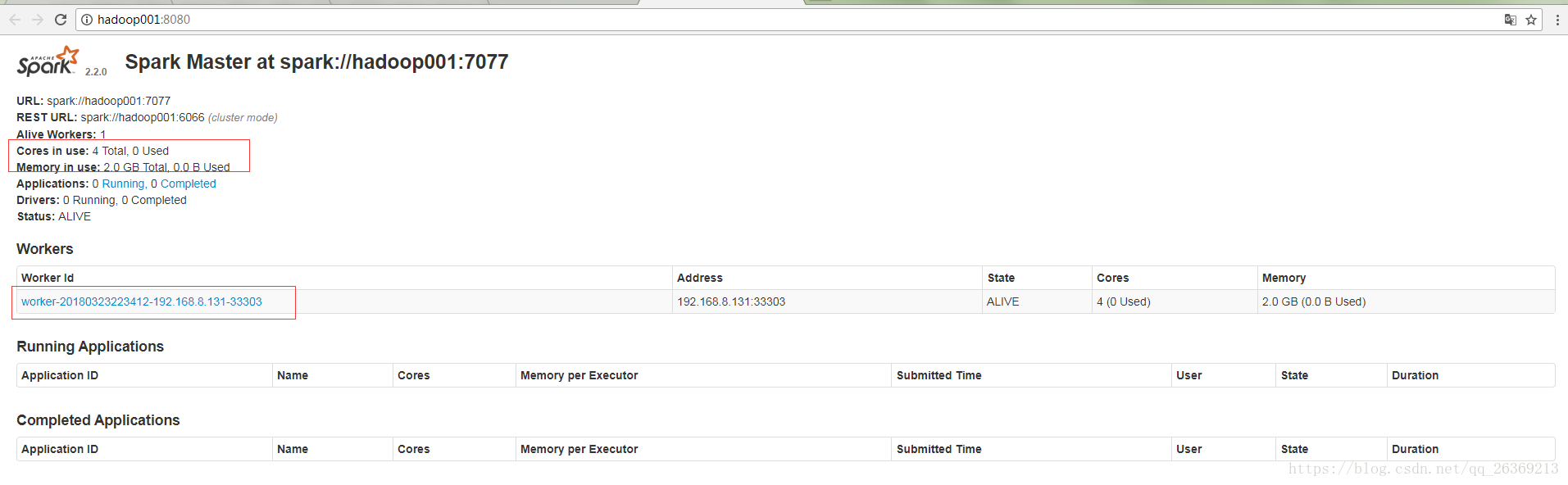
成功将worker添加至集群。
spark on yarn
1、配置spark on yarn
1.1、确保HADOOP_CONF_DIR或YARN_CONF_DIR指向包含Hadoop集群(客户端)配置文件的目录(可以在系统环境变量 或者 spark-env.sh 中配置)。这些配置用于写入HDFS并连接到YARN ResourceManager。
1.2、启动yarn 和 hdfs。
1.3、在一个yarn集群中启动程序
$ ./bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options] <app jar> [app options]
For example
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
--queue thequeue \
lib/spark-examples*.jar \
10
2、spark on yarn有2种部署模式,分别是 client 和 cluster,通过参数 --deploy -mode指定。
在cluster模式中,spark driver 会运行在AM中,它是被yarn管理的,当初始化成功后 客户端就能分离。在client模式中,driver运行在客户端中,AM只负责向yarn申请资源。














 2091
2091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









