







1、采集案例
结构示意图:
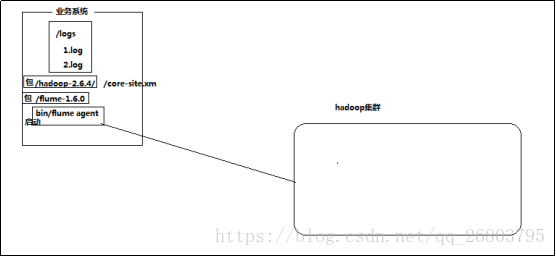
采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去
根据需求,首先定义以下3大要素
1.1、数据源组件,即source ——监控文件目录 : spooldir
spooldir特性:
1.1.1、监视一个目录,只要目录中出现新文件,就会采集文件中的内容
1.1.2、采集完成的文件,会被agent自动添加一个后缀:COMPLETED
1.1.3、所监视的目录中不允许重复出现相同文件名的文件
1.2、下沉组件,即sink——HDFS文件系统 : hdfs sink
1.3、通道组件,即channel——可用file channel 也可以用内存channel
配置文件编写:
#定义三大组件的名称
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# 配置source组件
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/hadoop/logs/
agent1.sources.source1.f 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 7195
7195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









