







机器学习-分类和聚类、分类和回归、逻辑回归和KNN
分类和聚类的概念:
**
1、分类:使用已知的数据集(训练集)得到相应的模型,通过这个模型可以划分未知数据。分类涉及到的数据集通常是带有标签的数据集,分类是有监督学习。一般分为两步,训练数据得到模型,通过模型划分未知数据。
**2.聚类:**直接使用聚类算法将未知数据分为两类或者多类。聚类算法可以分析数据之间的联系,一般分为一步,是无监督学习。
**常见的分类算法:**KNN、逻辑回归、支持向量机、朴素贝叶斯、决策树、随机森林、
**常见的聚类算法:**K均值(K-means)、FCM(模糊C均值聚类)、均值漂移聚类、DBSCAN、SPEAK、Mediods、Canopy
逻辑回归:
逻辑回归是一种分类算法,而不是回归算法。分类和回归的区别如下:分类的输出数据类型为离散型数据,回归输出为连续性数据;分类的目的是寻找决策边界,回归的目的是找到最优拟合;分类的评价方法一般为精度、混淆矩阵,回归的评价方法为sum of square errors(SSE)或拟合优度;分类是一种定性预测,回归是一种定量预测。
判断分类和回归的主要方法是观察输出类型为离散型还是连续数据,离散型是分类问题,连续数据是回归问题。
现在回到逻辑回归,逻辑回归首先拟合数据,最开始的想法是对数据进行线性拟合,但是线性拟合很容易受到离群值(异常值)的影响,因此选择sigmod函数作为逻辑回归的回归函数,sigmod函数的表达式和图像如下:
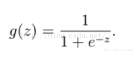
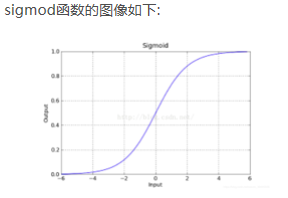
sigmod函数可以有效解决离群值的干扰问题。因为sigmod函数具有很强的鲁棒性,也就是Robust。接着要选定阈值,阈值要具体情况具体分析,不是一上来就是将阈值规定为0.5,有时候阈值规定0.5确实不错,但是在很多情况下,阈值应该偏小或者偏大,比如癌症的预测问题,为了尽量避免小概率事件的发生,尽量选择较小的阈值。
我们在上面已经知道用sigmod函数作为回归函数,接着就是要寻找一组W,使得函数正确的概率最大,也叫做最大似然估计。求解函数最优的函数我们通过数学推导得到一个叫做交叉熵损失函数,这个函数也就是逻辑回归的损失函数。求解损失函数的方法还是使用梯度下降法。
总结:逻辑回归----sigmod函数----选定阈值----最大似然估计----交叉熵损失函数----梯度下降法
KNN(K最近邻分类算法)
KNN算法的核心思想:确定一个临近度的度量,相似性越高,相异性越低的数据样本,可以认为是同一类数据类别。
KNN的算法步骤:
- 数据清洗:数据规范化;例如身高不超过180cm
- 确定临近值的度量,计算临近度(数据中心的点与其他点之间的距离)
- 按照临近度递增次序排序
- 选取与当前点距离最小的k个点
- 返回前k个点所在类别的出现频率;
- 返回前k个点出现频率最高的类别作为当前点的预测分类














 3732
3732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









