







博客参考书籍:《Machine Learing in Action》 Peter Harrington
使用语言:Python
Python需要装载的库有:numpy ,matplotlib。安装参考博客:
学习中使用到的Python函数说明及用法:
- shape:shape函数是numpy.core.fromnumeric中的函数,它的功能是读取矩阵的长度,比如shape[0]即指读取矩阵第一维度的长度。以此类推,比如矩阵[[1,1,1], [1,1,1], [1,1, 1],[1,1,1]]则为二维4*3矩阵,shape[0]=4,shape[1]=3。同理[[[1,1,1], [1,1,1]], [[1,1, 1],[1,1,1]]]为三维2*2*3矩阵,shape[0]=2。
- tile:tile函数的功能为重复某个数组,用法:tile(A,reps)。A为输入的数组,reps为各个维度重复的次数。比如tile([3,2],(2,1)),则可得到矩阵[[3, 2], [3, 2]]。
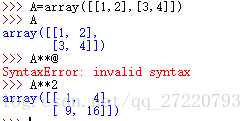
- A**n:A为矩阵,n为任意数。表示对矩阵中的每个元素进行n次幂运算。比如
- sum(iterable[, start],axis=1):iterable为可迭代的对象。如果是矩阵,则A.sum(axis = 1)则表示将矩阵进行每一行相加。比如sum([[2,2],[3,3]],axis=1)=[4,6]。
- argsort():argsort()函数是将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y。比如array([1,3,2]).argsort()=[0,2,1]。
- 数据结构,映射/字典:{}
- dict.get(key,default = None):返回给定键值的值,比如get(‘a’,0)。
- dict.iteritems():迭代输出字典的键值对。
- operator.itemgetter(n):获取迭代对象的n个值,比如operator.itemgetter(1),表示获取对象的第一个域的值。
- sorted(iterable[, cmp[, key[, reverse]]]):排序函数,可以对list或者iterable进行排序。iterable:指定要排序的list或者iterable;cmp为函数,指定排序时进行比较的函数,可以指定一个函数或者lambda函数;key为函数,指定取待排序元素的哪一项进行排序;reverse参数就不用多说了,是一个bool变量,表示升序还是降序排列,默认为false(升序排列),定义为True时将按降序排列。
- strip():去掉字符串的首尾空格。
- split(char):找到char字符,并将字符串切取。
kNN算法介绍:
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
优点:
1.简单,易于理解,易于实现,无需估计参数,无需训练;
2. 适合对稀有事件进行分类;
3.特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
缺点:
算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
可理解性差,无法给出像决策树那样的规则。
算法流程:
1. 准备数据,对数据进行预处理
2. 选用合适的数据结构存储训练数据和测试元组
3. 设定参数,如k
4.维护一个大小为k的的按距离由大到小的优先级队列,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列
5. 遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax
6. 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。
7. 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
8. 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练,最后取误差率最小的k 值。
相关Python实现算法:
# coding=utf-8
from numpy import *
import operator
from os import listdir
'''
kNN: k Nearest Neighbors
Input: inX: vector to compare to existing dataset (1xN)
dataSet: size m data set of known vectors (NxM)
labels: data set labels (1xM vector)
k: number of neighbors to use for comparison (should be an odd number)
Output: the most popular class label
@author: JiangXin
'''
def classify(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]#样本的个数
diffMat = tile(inX, (dataSetSize, 1))#每个样本向量与待测向量做差
squDiffMat = diffMat**2 #每个元素做平方
squDiffMatSum = squDiffMat.sum(axis=1)#求每一行的和,形成新的矩阵
distances = squDiffMatSum**0.5#形成一维距离矩阵
dataSetRank = distances.argsort()#排序
classCount = {}#创建映射
for i in range(k):
voteLabel = labels[dataSetRank[i]]#取出前k个样本对应的标签
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1;
sortedClassCount = sorted(classCount.iteritems(), key = operator.itemgetter(1), reverse = True)
#按照降序排序
return sortedClassCount[0][0] #取出第一个映射的第一个对象
def createDataSet():
dataSet = array([[1,1],[0,1],[1,1.1],[2,2]])
groups = ['A','B','A','B']
return dataSet, groups
'''
将文件数据转化为样本矩阵
有三个影响因素
'''
def file2matrix(filename):
file = open(filename)
numberOfData = len(file.readlines())
returnMat = zeros((numberOfData, 3))
classLabelVector = []
file = open(filename)
index = 0
for line in file.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat, classLabelVector
'''
将样本数据归一化
'''
def autoNorm(dataSet):
dataSetSize = dataSet.shape[0]
dataSet0 = zeros(shape(dataSet))
normDataSet = zeros(shape(dataSet))
dataSetMin = dataSet.min(0)#求每一列的最小值
dataSetMax = dataSet.max(0)#求每一列的最大值
dataSetRange = dataSetMax - dataSetMin
dataSet0 = dataSet - tile(dataSetMin, (dataSetSize, 1))
normDataSet = dataSet0 / tile(dataSetRange, (dataSetSize, 1))
return normDataSet
def datingClassTest():
hoRatio = 0.50 #hold out 10%
datingDataMat,datingLabels = file2matrix('F:\\Python_WORKSPACE\\20170217\\datingTestSet2.txt') #load data setfrom file
normMat = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount
同时,kNN算法可进行简单的字迹识别,本文以一个‘0’~‘9’的字迹图片进行识别。所有相关资源皆来自《Machine Learing in Action》
相关思路:
首先将图片转化为单色图片,然后将图片转化为颜色矩阵,最后将颜色矩阵转化为1维矩阵。比如图片矩阵为32*32,则将其转化为1*1024的矩阵,将该一维矩阵当作为一个样本,对算法进行训练。
图片矩阵如下图所示:

则首先需要一个矩阵转化函数,代码如下:
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect之后,则将数据转化为训练矩阵即可,相关测试代码如下(其中各个文件的保存形式如下:0_23.txt表示字迹表示的是0,是关于0的第23组样本)
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits') #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))以上即为kNN相关算法及代码。














 1022
1022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









