



目录
8. 统计/etc/fstab文件中每个文件系统类型出现的次数
一. awk命令简介
1. awk版本
AWK:原先来源于 AT & T 实验室的的AWK
NAWK:New awk,AT & T 实验室的AWK的升级版
GAWK:即GNU AWK。所有的GNU/Linux发布版都自带GAWK,它与AWK和NAWK完全兼容
在centos7中默认使用的是gawk。

2. awk与vim的区别
awk:文本处理工具,加载一行,处理一行
vim:文本处理工具,将整个文件加载到内存中处理,内存不足文件大小时,打不开文件
3. awk与sed的区别
awk:处理文件内容时,一般以行为处理单位
sed:处理文件内容时,一般以列为处理单位
4. awk工作原理
①. 执行BEGIN{action;… }语句块中的语句
②. 从文件或标准输入(stdin)读取一行,然后执行pattern{ action;… }语句块,它逐行扫描文件,
从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
③. 当读至输入流末尾时,执行END{action;…}语句块
BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块
pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块
5. awk格式
awk [选项] '模式 {处理动作}'
特别注意:awk命令需要使用单引号
6. awk常用选项
| 选项 | 说明 |
| - F | 指定分隔符 |
| - v | 指定自定义变量 |
| - f | 脚本 |
二. awk基础用法
1. awk基础用法

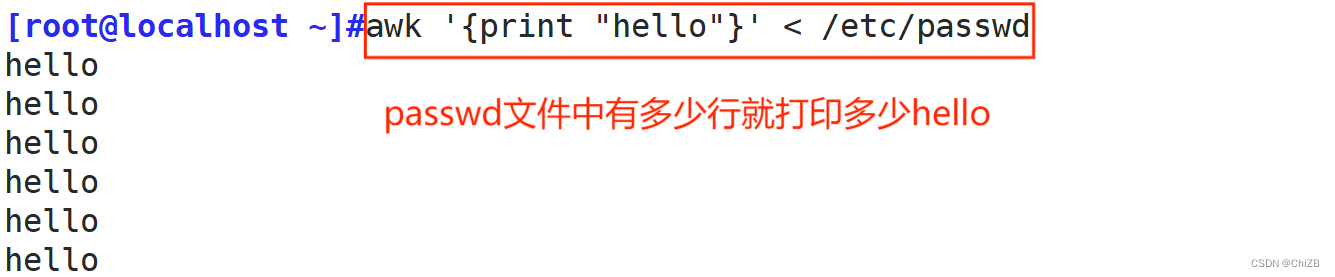
注意点:
①. 可以不加导向符,默认读取后面的文件内容
②. 打印的字符串需要加双引号,否则不识别
2. BEGIN和END语句块
①. BEGIN代码块:
在读取文件之前执行,且执行一次
在BEGIN代码块中,无法使用$0或其他一些特殊变量
②. END代码块:
在读取文件完成之后执行,且执行一次
有END代码块,必须有要读取的数据(可以是标准输入)
END代码块中可以使用$0等一些特殊变量,只不过这些特殊变量保存的是最后一轮awk循环的数据
③. main代码块
读取文件时循环执行,默认情况下每读取一行,就执行一次main代码块
main代码块可以有多个

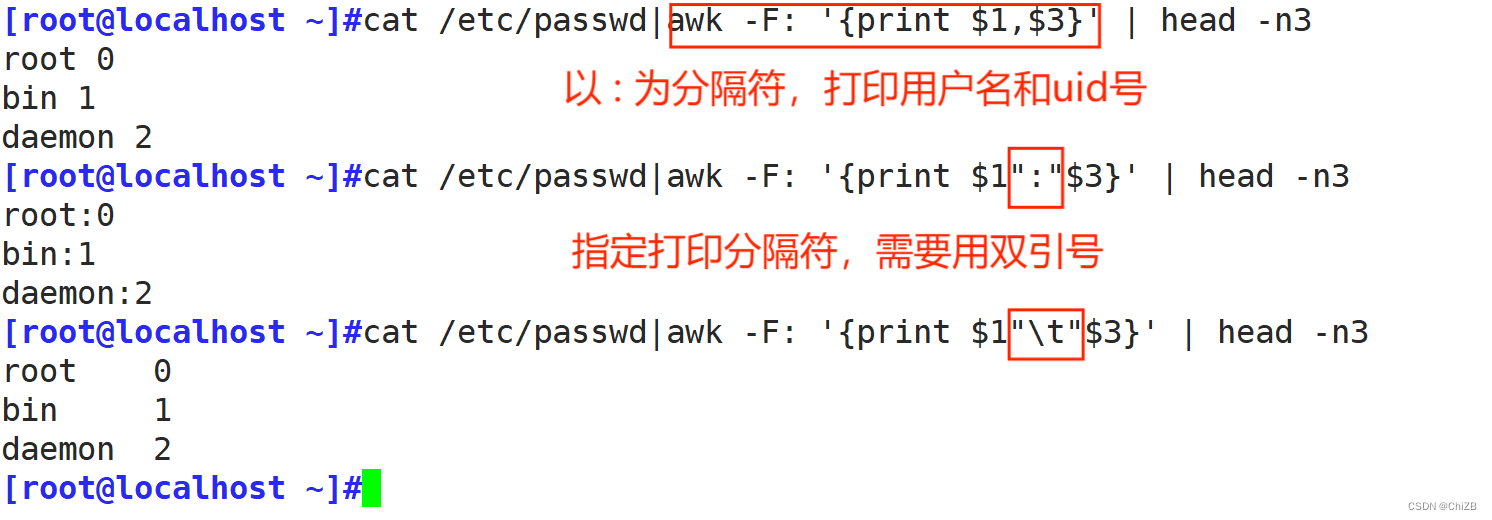
3. 指定分隔符
4. 首尾关键字
^加关键字是以这个关键字为开头过滤
关键字加&是以这个关键字为结尾过滤

三. awk内置变量
| 内置变量 | 说明 |
| FS | 指定每行文本的字段分隔符,缺省为空格或制表符(tab)。与 “-F”作用相同 -v "FS=:" |
| OFS | 输出时的分隔符 |
| NF | 当前处理的行的字段个数 |
| NR | 当前处理的行的行号(序数) |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| FILENAME | 被处理的文件名 |
| RS | 行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是\n |
1. FS变量
指定每行文本的字段分隔符,缺省(默认)为空格或制表符(tab)。
"-F" 作用与 -v "FS=:" 相同

注意:-F 与 -FS 一起使用时,-F 的优先级高
2. OFS变量

3. RS变量
在一个文件中,默认的换行符是$,RS的作用是把默认换行符换成指定换行符

4. NF变量
NF的作用是打印每一行有多少个字段

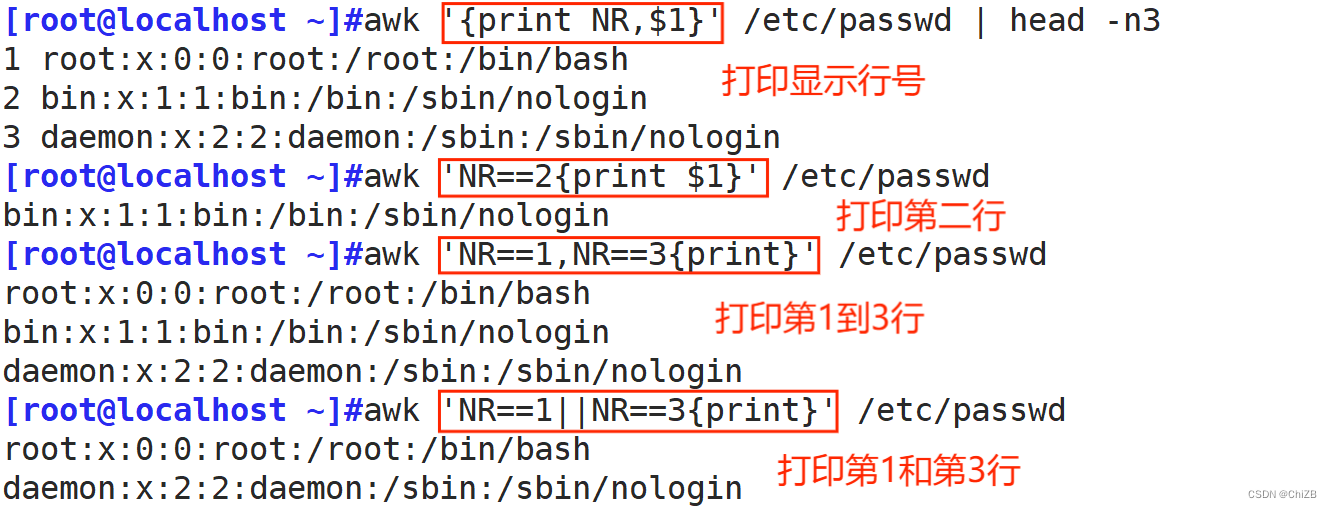
5. NR变量
NR的作用是显示行号
①. 打印出限定行
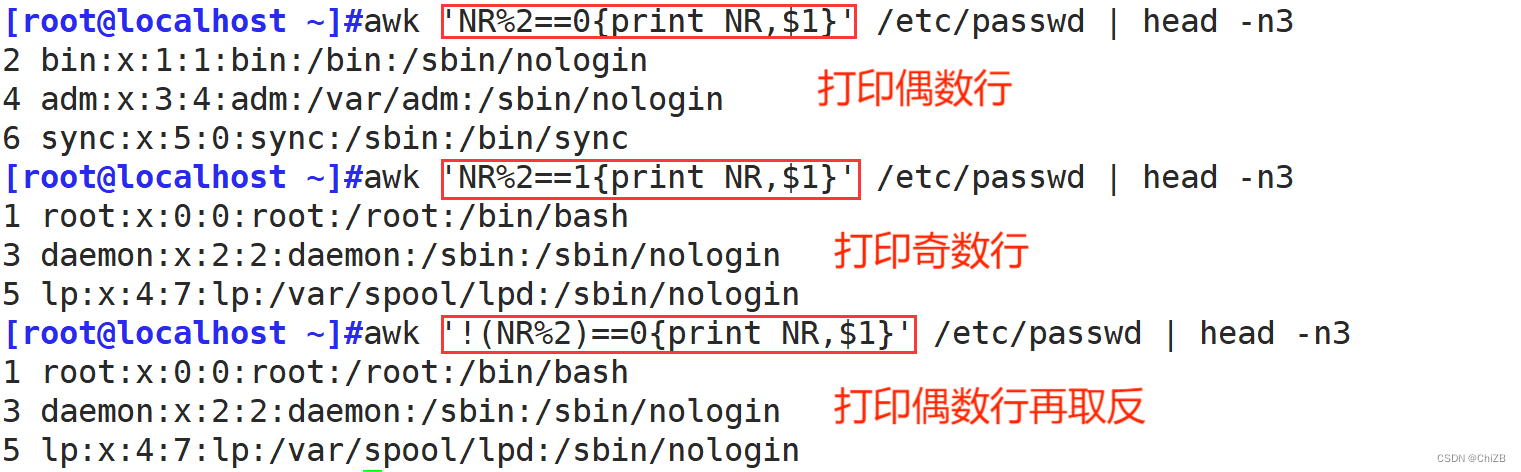
②. 打印出偶数或奇数行
③. 打印出范围行

6. 自定义变量

四. awk匹配模式
awk '模式{处理动作}'
PATTERN:根据pattern条件,过滤匹配的行,再做处理
1. 模式为空
如果模式为空,表示每一行都匹配成功,相当于没有额外条件
awk -F: '{print $1,$3}' /etc/passwd
2. 正则匹配
/regular expression/:仅处理能够模式匹配到的行,需要用/ /括起来,固定搭配
模糊匹配,用~表示包含,!~表示不包含
#匹配从以root开头的行到以adm开头的行
awk -F: '/^root/,/^adm/{print NR,$1"\t"$3}' /etc/passwd3. NR范围行匹配
#比较操作符
==, !=, >, >=, <, <=
#逻辑
与:&&,并且关系
或:||,或者关系
非:!,取反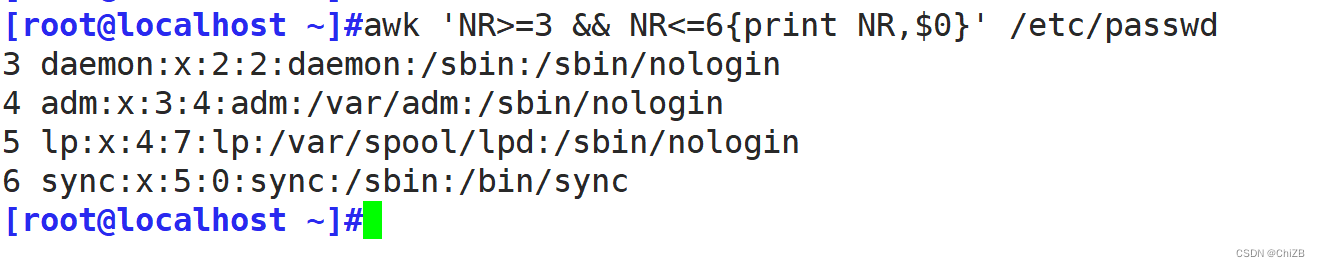
4. 关系表达式
关系表达式结果为“真”才会被处理
真:结果为非0值,非空字符串
假:结果为空字符串或0值
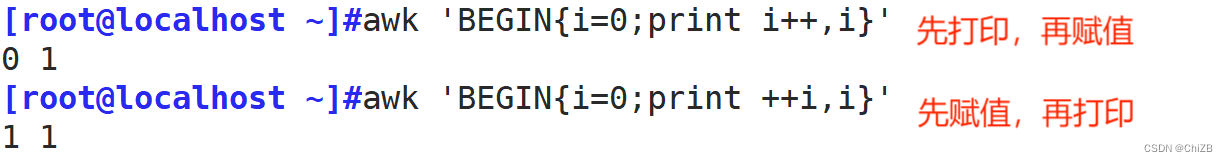

五. 条件判断

六. for循环
for(expr1;expr2;expr3) {statement;…}
for(variable assignment;condition;iteration process) {for-body}
for(var in array) {for-body}
awk 'BEGIN{sum=0;for(i=1;i<=100;i++){sum+=i};print sum}'
5050
for((i=1,sum=0;i<=100;i++));do let sum+=i;done;echo $sum
5050七. 关联数组
awk的数组为关联数组
awk 'BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Tuesday";print weekdays["mon"]}'
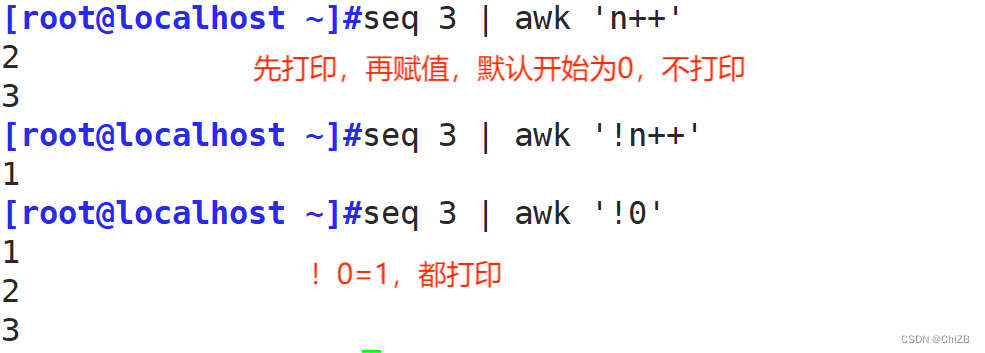
awk '!line[$0]++' dupfile
awk '{print !line[$0]++, $0, line[$0]}' dupfile
awk '{!line[$0]++;print $0, line[$0]}' dupfile遍历数组:
for(var in array) {for-body}
awk 'BEGIN{students[1]="lizong";students[2]="liuzong";students[3]="kunzong";for(x in students){print x":"students[x]}}'ss -nta|awk 'NR!=1{print $1}'|sort
ss -nta|awk 'NR!=1{state[$1]++}'
ss -nta|awk 'NR!=1{state[$1]++}END{for(i in state){print i,state[i]}}'八. awk脚本
将awk程序写成脚本,直接调用或执行
[root@centos7 ~]#vim passwd.awk
{if($3>=1000)print $1,$3}
[root@localhost data]#awk -F: -f passwd.awk /etc/passwd
nfsnobody 65534
zhangsan 1000
mysql 1001
[root@centos7 ~]#cat test.awk
#!/bin/awk -f
#this is a awk script
{if($3>=1000)print $1,$3}
[root@centos8 ~]#chmod +x test.awk
[root@centos8 ~]#./test.awk -F: /etc/passwd
nobody 65534
wang 1000
mage 1001九. awk案例
1. 提取分区利用率
#提取分区利用率
df | awk '{print $5}'
#去除%,以多位空格和%为分隔符提取
df | awk -F"( +|%)" '{print $5}'
df | awk -F"[[:space:]]+|%" '{print $5}'
df | awk -F"[ %]+" '{print $5}'
df | awk -F"[ %]+" '{print $(NF-1)}'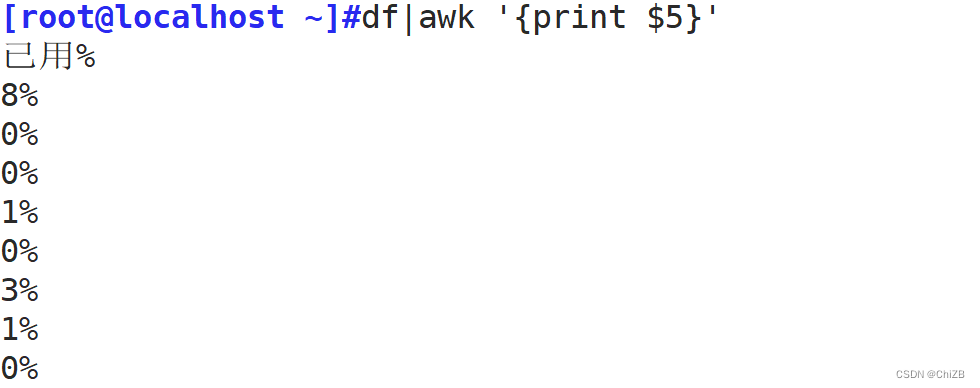
2. 提取用户名和uid号
#提取用户名和uid号
awk -F: '{print $1,$3}' /etc/passwd
awk -v "FS=:" '{print $1,$3}' /etc/passwd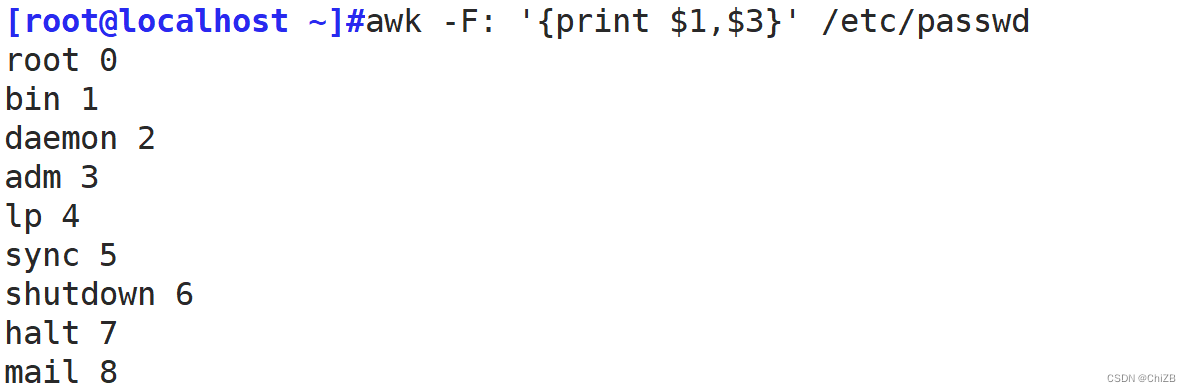
3. 提取/bin/bash结尾的用户并统计个数
#过滤以/bin/bash结尾的行并统计个数
awk 'BEGIN {x=0};/\/bin\/bash$/;{x++};END{print x}' /etc/passwd
#过滤以非/bin/bash结尾的行并统计个数
awk 'BEGIN {x=0};/\/bin\/bash$/ {x++;print x,$0};END{print x}' /etc/passwd
4. 提取IP地址
#提取当前主机IP地址
hostname -I | awk '{print $1}'
ifconfig ens33 | sed -n '2p' |awk '{print $2}'
ifconfig ens33 | grep mask | awk '{print $2}'
ifconfig ens33 | awk 'NR==2{print $2}'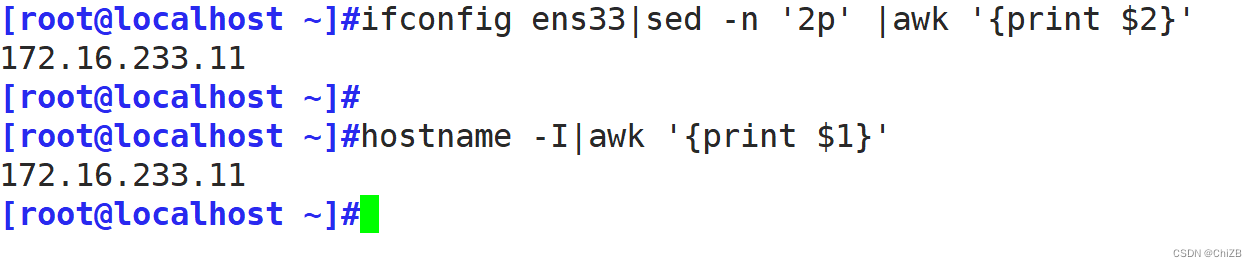
5. 提取出所有普通用户
#提取出普通用户
awk -F: '$3>=1000{print NR,$0}' /etc/passwd
#过滤出uid号大于等于1000的用户
6. 提取10:00 到 11:00 之间的日志
#提取10:00到12:00之间的日志
awk '/10:00/,/12:00/{print $0}' 日志文件7. 提取状态次数
ss -nta|awk 'NR!=1{print $1}'|sort
ss -nta|awk 'NR!=1{state[$1]++}'
ss -nta|awk 'NR!=1{state[$1]++}END{for(i in state){print i,state[i]}}'
8. 统计/etc/fstab文件中每个文件系统类型出现的次数
cat /etc/fstab | grep -v '^#' | grep -v '^$' | awk '{print $3}' | sort | uniq -c
9. 统计/etc/fstab文件中每个单词出现的次数
grep -Eo "\b[a-zA-Z]+\b" /etc/fstab | wc -l

















 2729
2729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









