




 本文详细介绍了JMeter工具的性能测试应用场景,包括CSVDataSetConfig参数化、随机数与时间戳函数的使用、JSON提取器与正则表达式提取器的数据提取,以及聚合报告的指标解读。此外,还讨论了定时器的类型和逻辑控制器的作用,并推荐了一些实用插件,如BasicGraph和PerfMon,以提升测试效率和监控性能。
本文详细介绍了JMeter工具的性能测试应用场景,包括CSVDataSetConfig参数化、随机数与时间戳函数的使用、JSON提取器与正则表达式提取器的数据提取,以及聚合报告的指标解读。此外,还讨论了定时器的类型和逻辑控制器的作用,并推荐了一些实用插件,如BasicGraph和PerfMon,以提升测试效率和监控性能。
一、参数化
CSV Data Set Config组件
第一步:新建元件
线程组-添加-配置原件-CSV Data Set Config
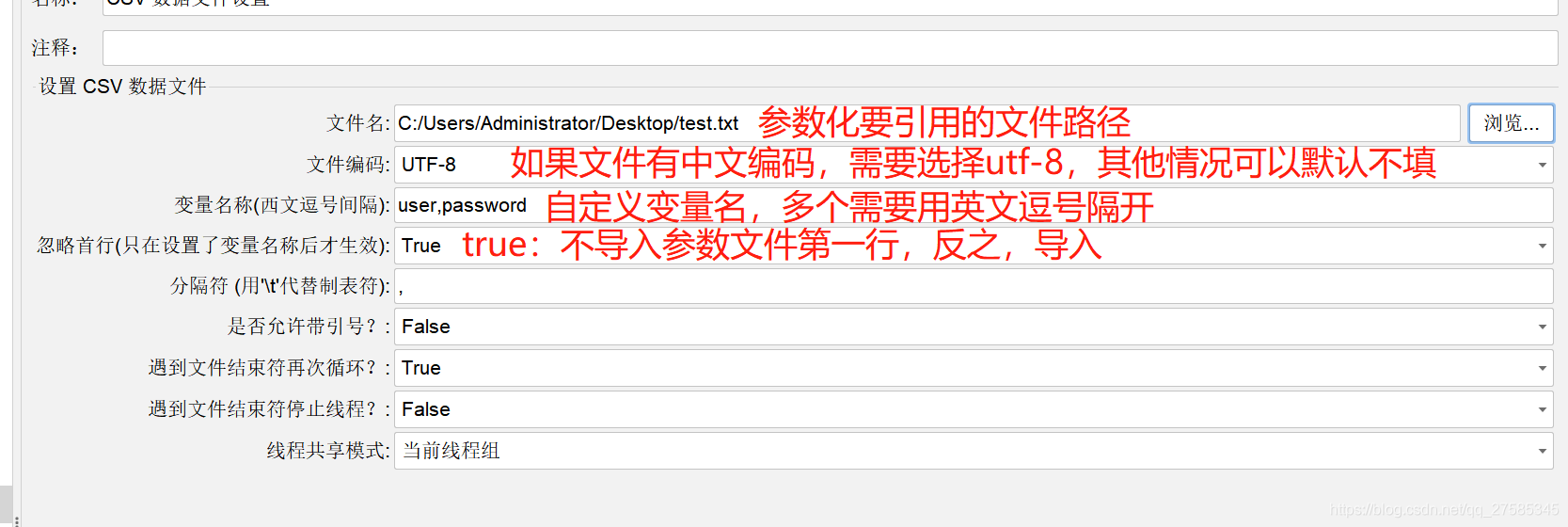
文件名:参数要应用的文件名和路径,文件格式举例如下:
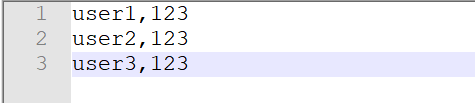
其中:
△遇到文件结束符再次循环为true,遇到文件结束符停止线程为false,共享模式为当前线程组,参数效果:可重复利用参数文件中的数据,直到设置的线程数结束为止
△遇到文件结束符再次循环为false,遇到文件结束符停止线程为true,共享模式为所有线程组、共享线程组,参数效果:参数文件中的每条数据只能应用一次,已经使用过了,就不可以重复运用,直接结束
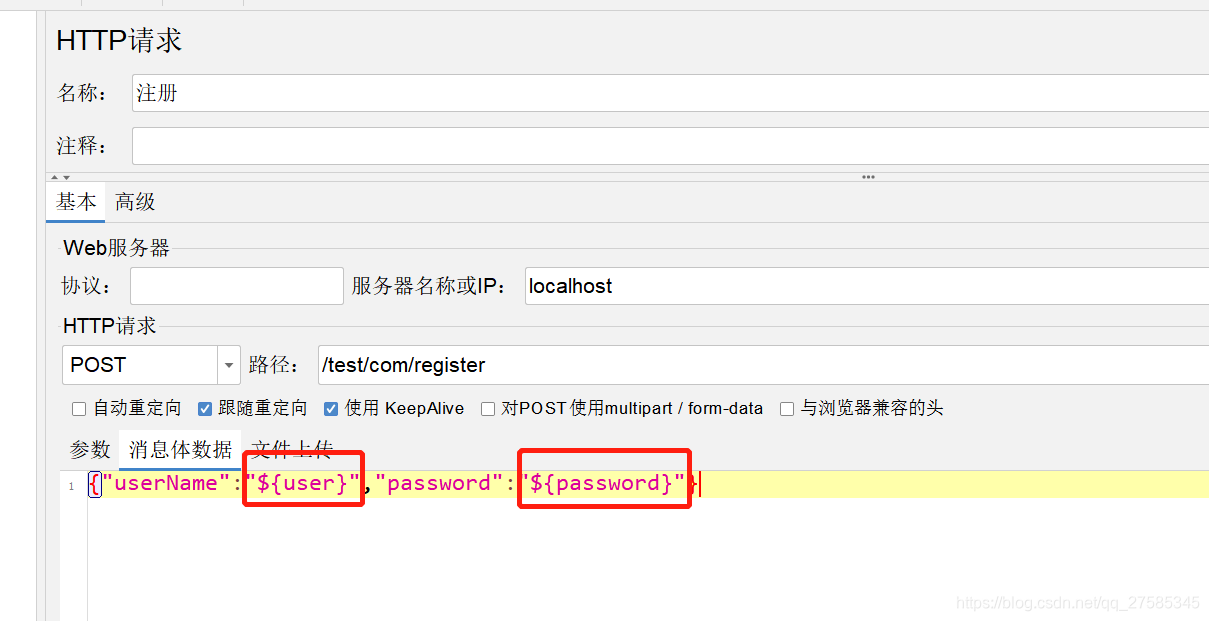
第二步:引用参数
随机数函数
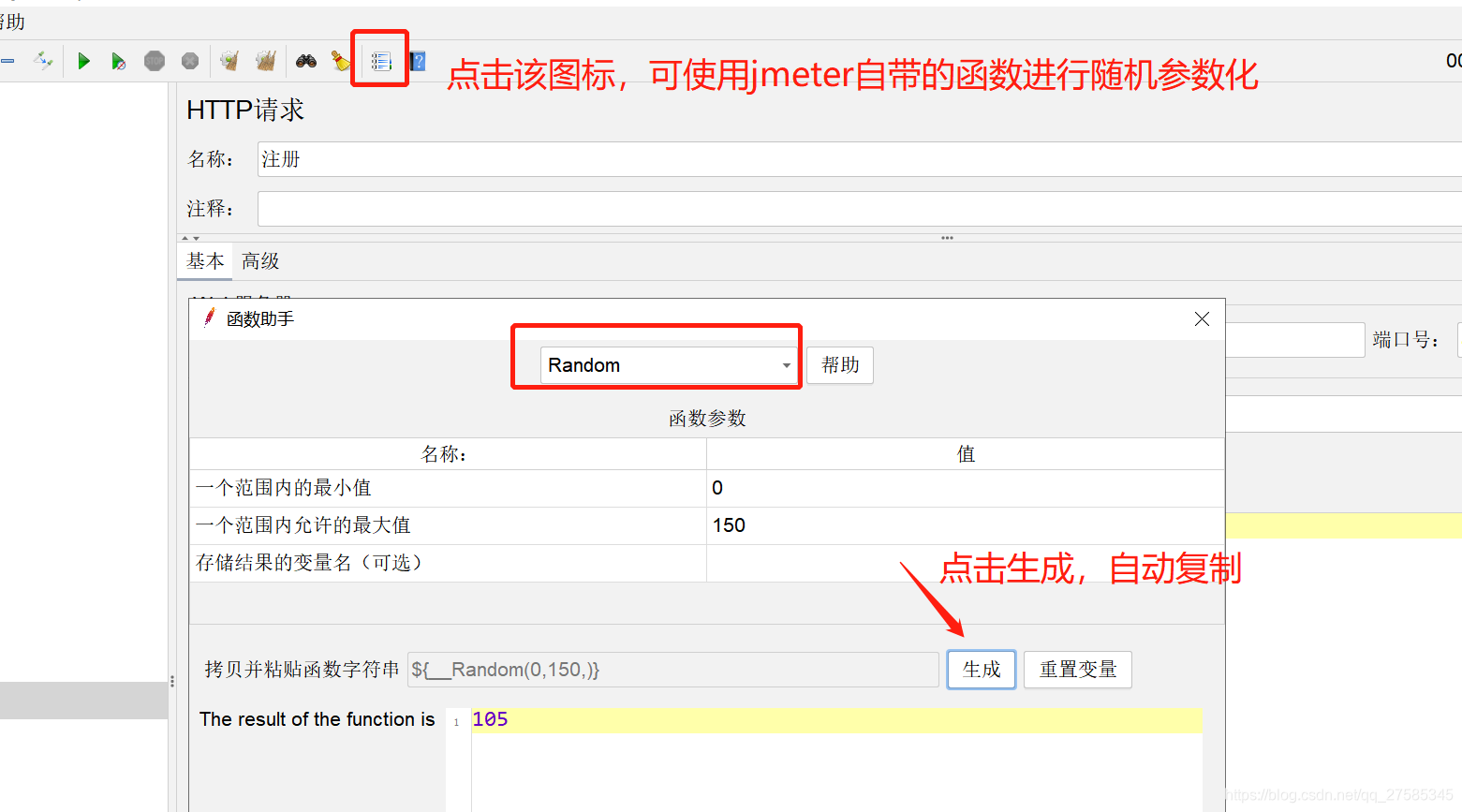
复制好的函数,直接放到需要进行参数化的位置即可,如:
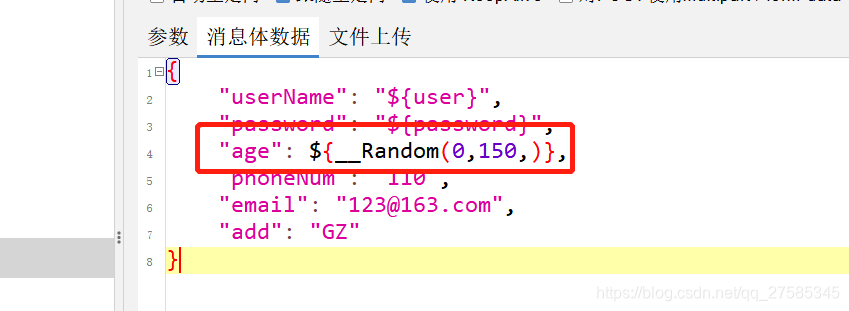
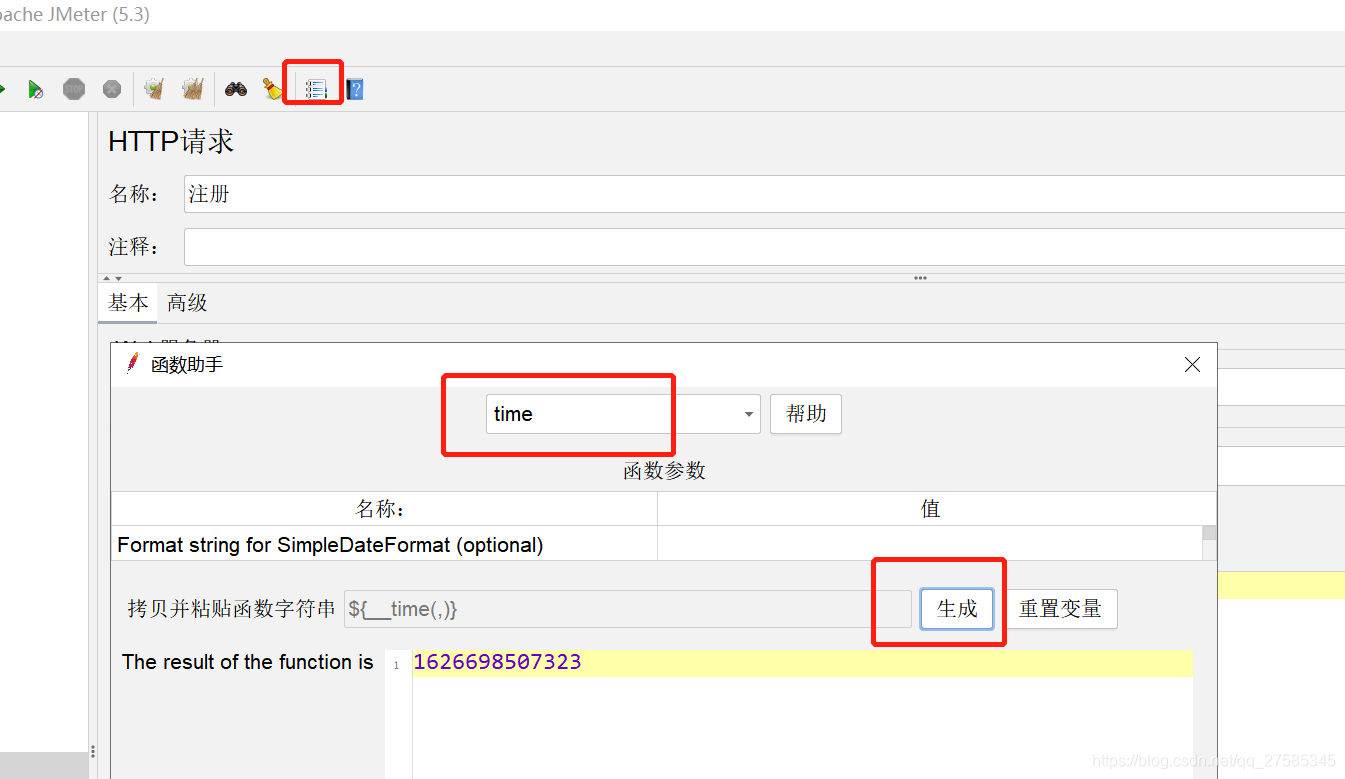
时间戳函数
生成唯一uid函数
△如果并发量过大,如千万级别,还是会有重复(听说)

counter计数器
△该函数是针对全局计数,即线程数*循环次数

二、json提取器
如:将第一个接口的返回值作为第二个接口的入参
后置处理器-JSON提取器
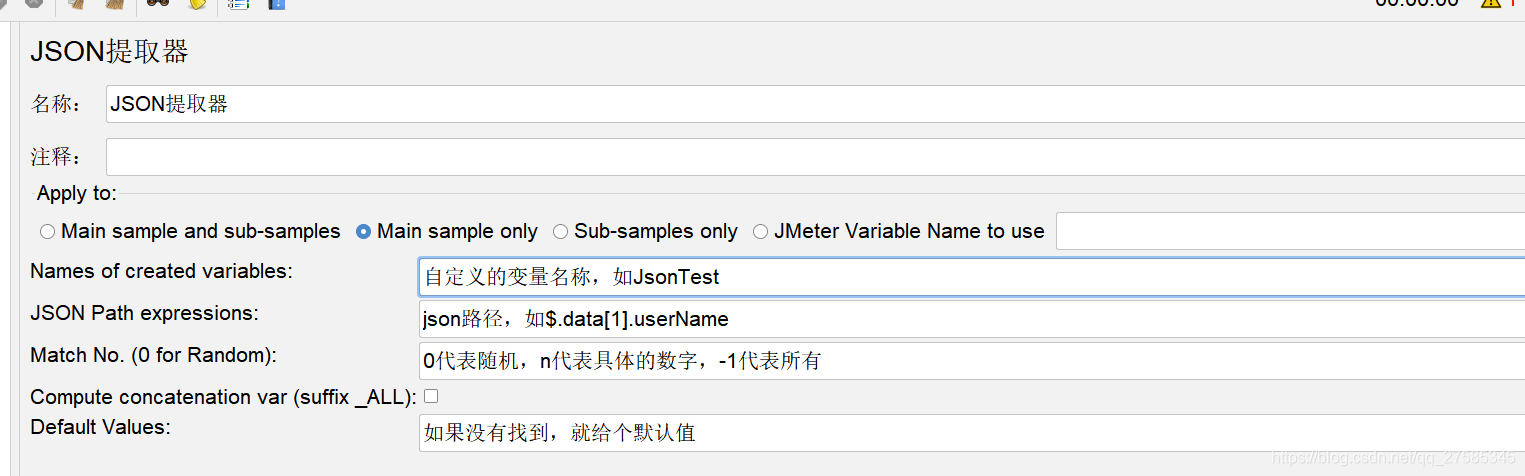 注:json路径的获取可参照以下,分为数组和非数组,数组直接一层层找即可,非数组加上中括号,括号中的下标从0开始
注:json路径的获取可参照以下,分为数组和非数组,数组直接一层层找即可,非数组加上中括号,括号中的下标从0开始
响应数据为数组:
{
"code": "0",
"message": "success",
"data": [
{
"id": 0,
"userName": "王二小",
"password": 123456,
"age": 20,
"gender": 100,
"phoneNum": "11923",
"email": "123@163.com",
"address": "广州天河"
},{
"id": 1,
"userName": "王大小",
"password": 234123,
"age": 90,
"gender": 40,
"phoneNum": "0938403",
"email": "123@163.com",
"address": "广州番禺"
},
]
}
通过JsonPath方式获取“王大小”:$.data[1].userName,保存好后,将自定义的变量名称,如JsonTest放到下一个请求体的参数里即可,如:

三、正则表达式提取器
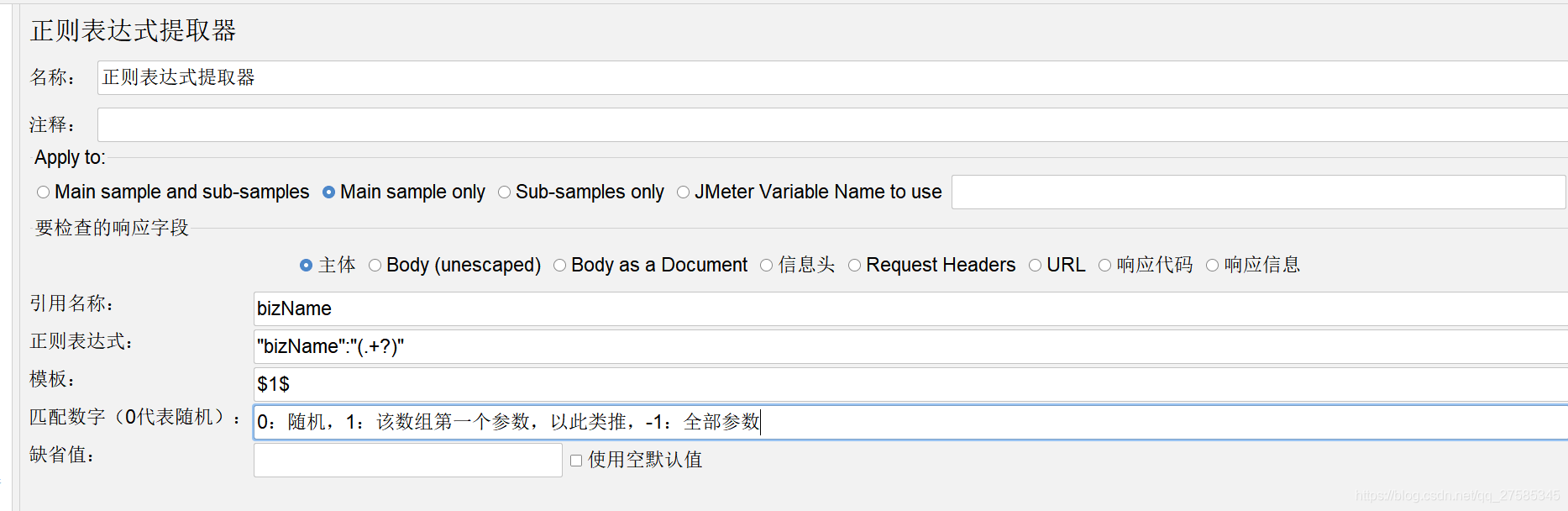
后置处理器-正则表达式提取器
万能正则:.+?
步骤:
1、拷贝响应数据中你需要的值,如"bizName":"夹克一号"
2、将需要的数据用英文括号括起来,比如想要夹克一号,"bizName":"(夹克一号)"
3、再将需要的数据用.+?代替,如:"bizName":"(.+?)"
△如果获取的数据有换行,加上\n,有的系统是\r,或者\r\n
Test-rex: (.+?)\n
四、聚合报告
#Samples:一共发了多少次请求
Average:平均响应时间
Median:中位数,相当于50%
90% Line:90%用户的响应时间
Min:最小响应时间
Max:最大响应时间
Error:错误率
Throughput:吞吐量
KB/Sec:每秒从服务器端接收到的数据量
五、常用插件
使用方法:
1、下载plugins-manager.jar包,到http://jmeter-plugins.org/downloads/all下载即可,然后放在jmeter的lib/ext目录下
2、打开jmeter,选项-插件管理器,即最右上角的图标
3、勾选对应的插件,等待下载完成,点击apply,等待重启jmeter,即可使用
4、监听器-选择下载成功的插件,如

几个好用的插件:
△ 3 Basic Graph:windows下可用的vu、实时tps和响应时间的插件
△ Custom JMeter Functions,函数库,在函数助手查看使用
△ Random CSV Data Set Config,和CSV Data Set Config用法一样,但多了个随机获取
△ PerfMon :服务端性能实时监控插件
△ Custom Thread Groups
△ Dummy Sampler
六、定时器
固定定时器:
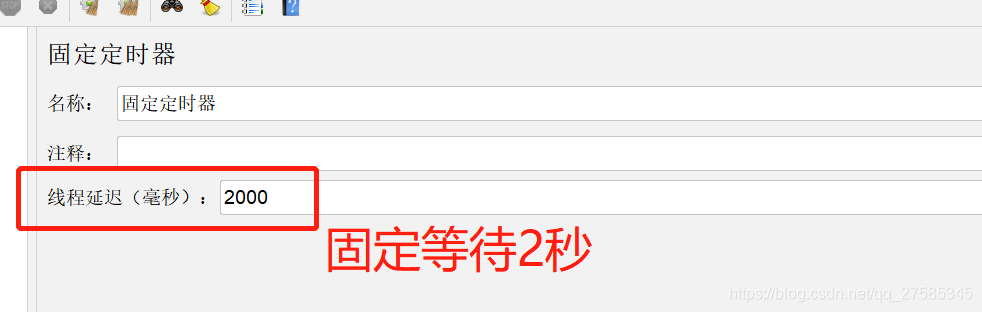
同步定时器:
在该定时器处,使线程等待,一直到指定的线程个数达到后,再一起释放。可以在瞬间制造出很大的压力。相当于LoadRunner的集合点
常数吞吐量定时器:
当找到tps拐点时,为了防止tps过高导致请求异常,可常数吞吐量定时器控制tps

















 3366
3366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









