






点击下面卡片,关注我呀,每天给你送来AI技术干货!
NewBeeNLP公众号原创出品
公众号专栏作者 @Maple小七
北京邮电大学·模式识别与智能系统
今天和大家来看看最近讨论度非常高的SimCSE,据说简单暴力还效果显著!

论文:SimCSE: Simple Contrastive Learning of Sentence Embeddings[1]
代码: princeton-nlp/SimCSE[2]
Demo: https://gradio.app/g/AK391/SimCSE
本文将对比学习的思想引入了sentence embedding,刷爆了无监督与有监督语义相似度计算任务SOTA,是一篇非常难得的高水平论文。
写在前面
学习自然语言的通用语义表示一直是NLP的基础任务之一,然而当2019年的SBERT出现之后,语义相似度计算和语义匹配模型似乎就没有什么突破性进展了,2020年出现的BERT-flow和BERT-whitening主要是对无监督语义匹配的改进,而有监督语义匹配的SOTA一直是SBERT。
SBERT本身并不复杂,仅仅是一个基于BERT的孪生网络而已,想要在SBERT的基础上改进指标,只能从训练目标下手,而本篇论文就将对比学习的思想引入了SBERT,大幅刷新了有监督和无监督语义匹配SOTA,更让人惊叹的是,无监督SimCSE的表现在STS基准任务上甚至超越了包括SBERT在内的所有有监督模型。
对比学习
对比学习的思想说起来很简单,即拉近相似的样本,推开不相似的样本,一种常用的对比损失是基于批内负样本的交叉熵损失,假设我们有一个数据集 ,其中 和 是语义相关的,则在大小为 的mini batch内, 的训练目标为
其中 , 和 是 和 的编码表示, 为softmax的温度超参。
正样本
使用对比损失最关键的问题是如何构造 ,对比学习最早起源于CV领域的原因之一就是图像的 非常容易构造,裁剪、翻转、扭曲和旋转都不影响人类对图像语义的理解,而结构高度离散的自然语言则很难构造语义一致的 ,前人采用了一些数据增强方法来构造 ,比如同义词替换,删除不重要的单词,语序重排等,但这些方法都是离散的操作,很难把控,容易引入负面噪声,模型也很难通过对比学习的方式从这样的样本中捕捉到语义信息,性能提升有限。
两个指标
对比学习的目标是从数据中学习到一个优质的语义表示空间,那么如何评价这个表示空间的质量呢?Wang and Isola (2020)[3]提出了衡量对比学习质量的两个指标:alignment和uniformity,其中alignment计算 和 的平均距离:

而uniformity计算向量整体分布的均匀程度:

我们希望这两个指标都尽可能低,也就是一方面希望正样本要挨得足够近,另一方面语义向量要尽可能地均匀分布在超球面上。
因为均匀分布信息熵最高,分布越均匀则保留的信息越多,“拉近正样本,推开负样本”实际上就是在优化这两个指标。在后文中,作者将会使用这两个指标来评价模型。
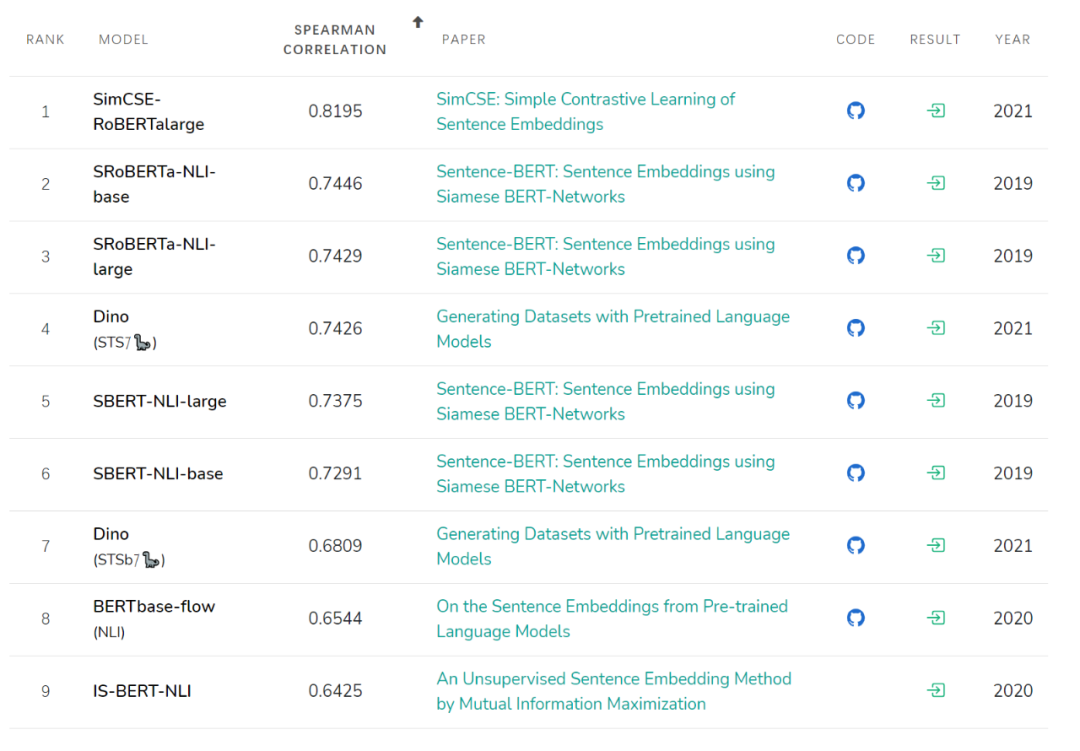
无监督版 SimCSE
众所周知,直接用BERT句向量做无监督语义相似度计算效果会很差,任意两个句子的BERT句向量的相似度都相当高,其中一个原因是向量分布的非线性和奇异性。
前不久的BERT-flow通过normalizing flow将向量分布映射到规整的高斯分布上,更近一点的BERT-whitening对向量分布做了PCA降维消除冗余信息,但是标准化流的表达能力太差,而白化操作又没法解决非线性的问题,有更好的方法提升表示空间的质量吗?
正好,对比学习的目标之一就是学习到分布均匀的向量表示,因此我们可以借助对比学习间接达到规整表示空间的效果,这又回到了正样本构建的问题上来,而本文的创新点之一正是无监督条件下的正样本构建。
本文作者提出可以通过随机采样dropout mask来生成
。回想一下,在标准的Transformer中,dropout mask被放置在全连接层和注意力求和操作上,设
,其中
是随机生成的dropout mask,由于dropout mask是随机生成的,所以在训练阶段,将同一个样本分两次输入到同一个编码器中,我们会得到两个不同的表示向量
,将
作为正样本,则模型的训练目标为
这种通过改变dropout mask生成正样本的方法可以看作是「数据增强」的最小形式,因为原样本和生成的正样本的语义是完全一致的(注意语义一致和语义相关的区别),只是生成的embedding不同而已。
Dropout 用于数据增强
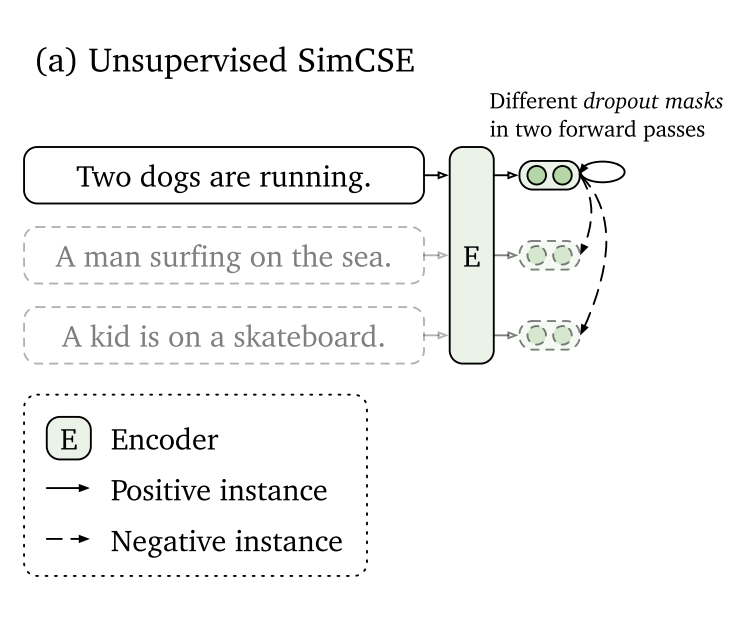
那么这种简单的正样本生成方式和其他显式的数据增强方式有明显的优势吗?作者从维基百科中随机抽取十万个句子来微调BERT模型,并在STS-B开发集上测试,实验结果如下表所示:

其中None是作者提出的随机dropout mask方法,其余方法均是在None的基础上改变 的输入。可以看到,追加显式的数据增强方法都会大幅降低性能。
作者也对比了这样的自监督方式和NSP目标的训练结果,如下表所示,将NSP作为正样本的构建方式明显很不科学,另外,做语义相似度计算一定要共享编码器。
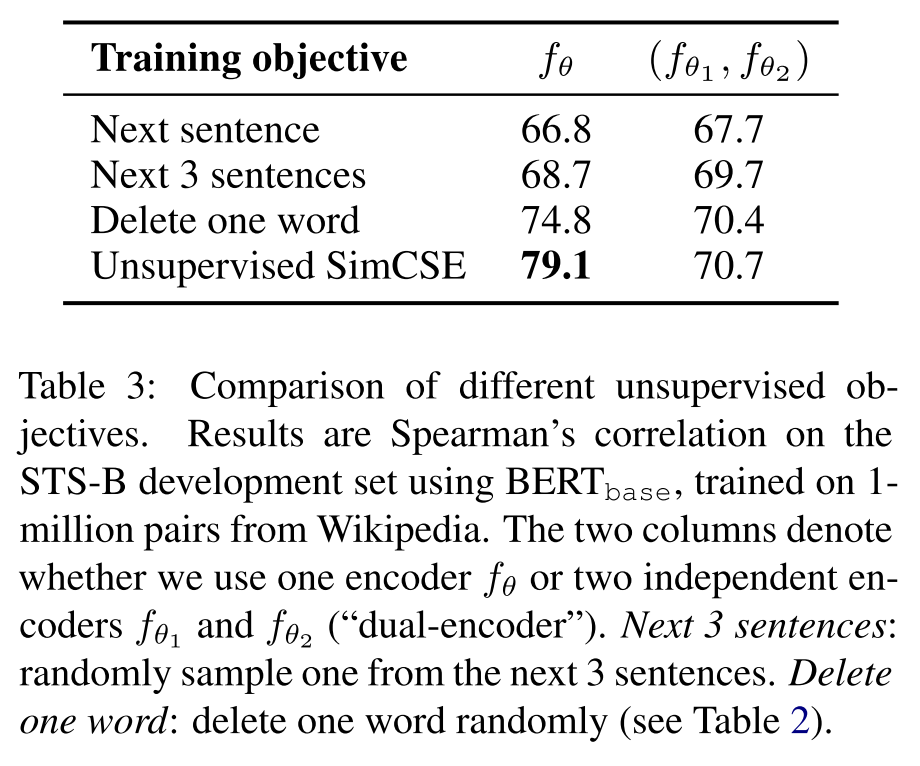
Why does it work?
为什么这样的对比训练目标能work得这么好呢?作者首先尝试改变了dropout rate,发现默认的 性能是最好的,去掉dropout或者固定dropout mask后模型性能都会出现大幅的下降,因为这时候 就和 一模一样,模型几乎什么都学不到。
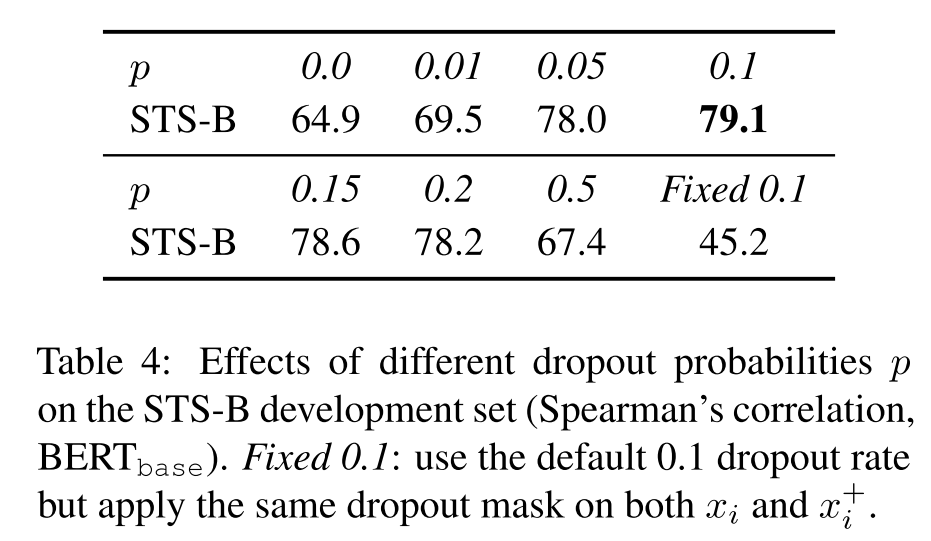
之前提到了衡量对比学习质量的指标:alignment和uniformity,作者用这两个指标测试了不同模型训练过程中保存的checkpoints,可视化结果如下图所示。
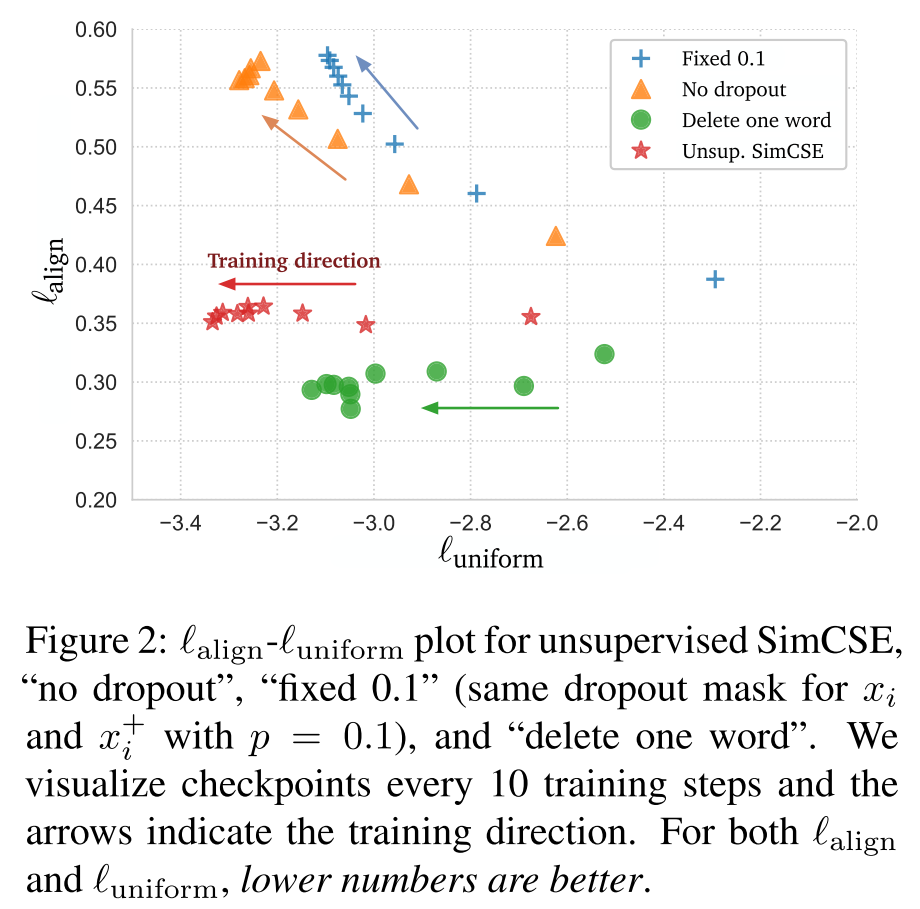
可以发现所有模型的uniformity都有所改进,表明预训练BERT的语义向量分布的奇异性被逐步减弱;而与fix dropout和no dropout相比,SimCSE能在规整分布的同时保持正样本的对齐,与Delete one word相比,虽然alignment比不上delete one word,但由于其分布更加均匀,因此SimCSE总体性能更高。另外,这幅图其实还有很多可以探讨的问题,这里不再细说。
有监督版 SimCSE
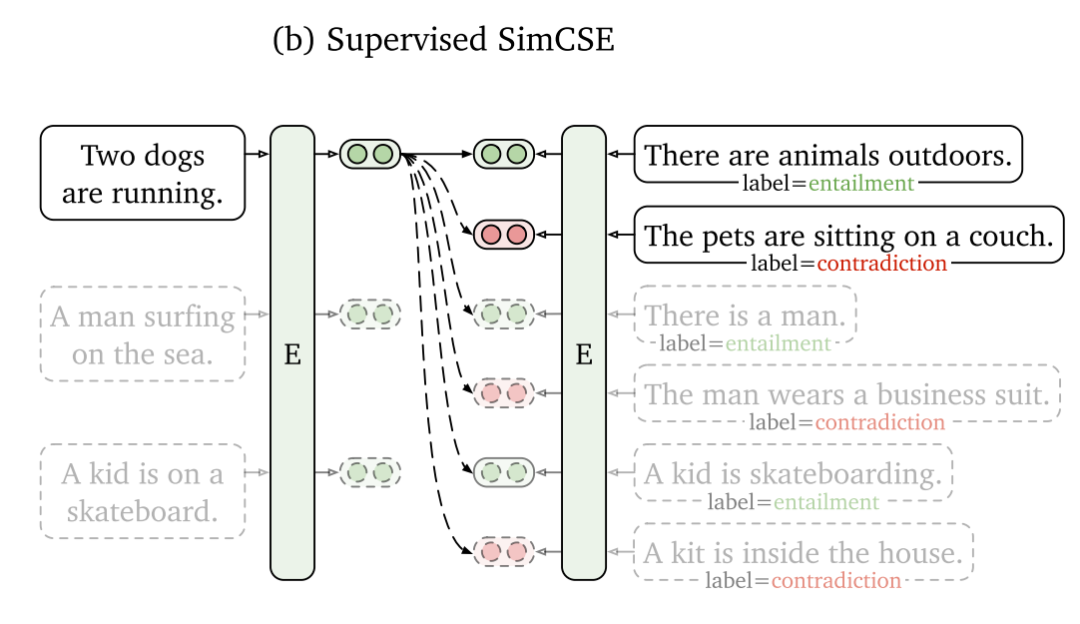
上面论述了SimCSE在无监督语义相似度任务上的优秀表现,在有监督的条件下,SimCSE是否能够超越SBERT呢?
在SBERT原文中,作者将NLI数据集作为一个三分类任务来训练,这种方式忽略了正样本与负样本之间的交互(实际上SBERT文档中早已引入了对比损失,只是没有在原文中发表),而对比损失则可以让模型学习到更丰富的细粒度语义信息。
首先我们来考虑怎么构造训练目标,其实很简单,直接将数据集中的正负样本拿过来用就可以了,将NLI(SNLI+MNLI)数据集中的entailment作为正样本,conradiction作为负样本,加上原样本premise一起组合为 ,并将损失函数改进为
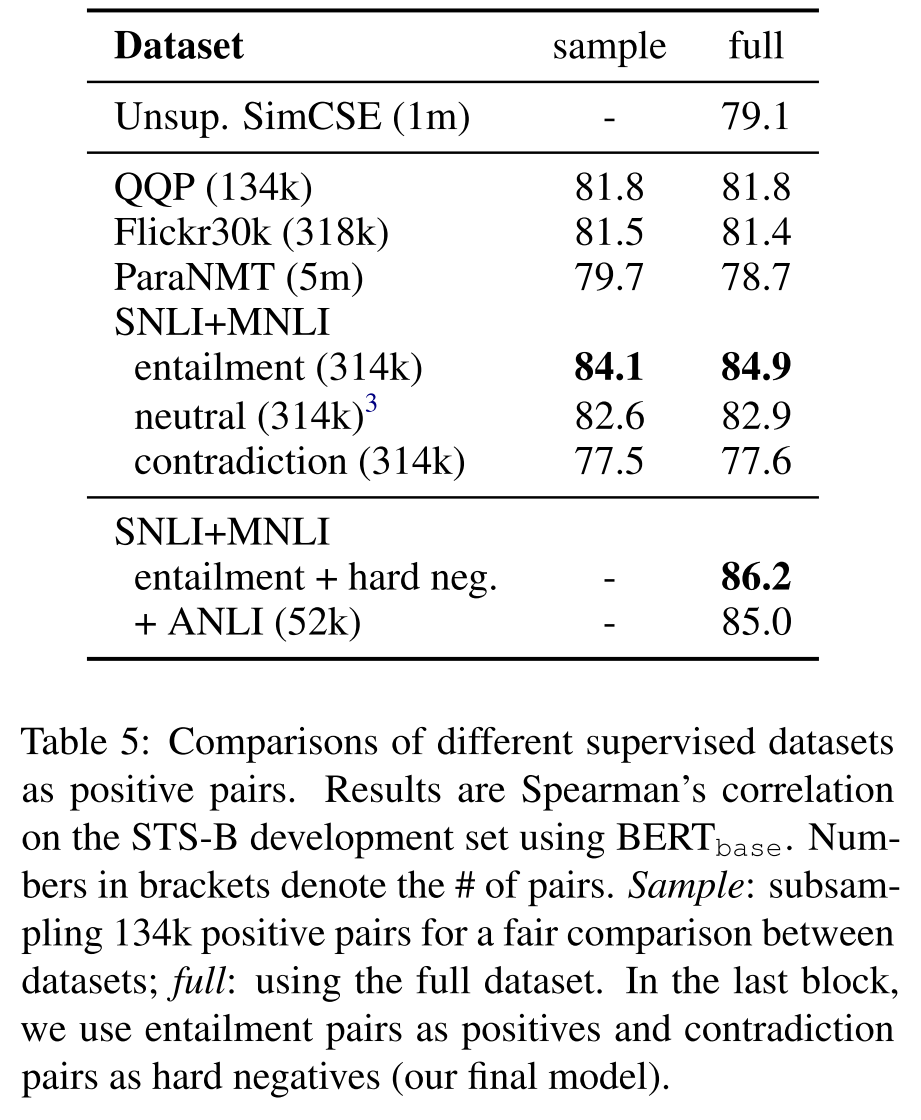
这里的 可以被看作是hard negatives。另外,作者分别尝试在不同的语义匹配数据集上(QQP、Flickr、ParaNMT)训练模型,并在STS-B上测试模型,结果如下表所示,其中sample列表示采样相等样本量训练的结果,作者发现NLI训练出来的模型性能是最好的,这是因为NLI数据集的质量本身很高,正样本词汇重合度非常小(39%)且负样本足够困难,而QQP和ParaNMT数据集的正样本词汇重合度分别达到了60%和55%。
Connection to Anisotropy
近几年不少研究都提到了语言模型生成的语义向量分布存在「各向异性」的问题,这极大地限制了语义向量的表达能力。缓解这个问题的一种简单方法是加入后处理步骤,比如BERT-flow和BERT-whitening将向量映射到各向同性的分布上,而本文作者证明了对比学习的训练目标可以隐式地压低分布的奇异值,提高uniformity。
Wang and Isola (2020)[4]证明了当负样本数量趋于无穷大时,对比学习的训练目标可以渐近表示为
其中第一项表示拉近正样本,第二项表示推开负样本,当 是均匀分布时,设 ,我们可以借助Jensen不等式进一步推导第二项的下界:
设 为 对应的句子嵌入矩阵,即 的第 行是 ,忽略常数项时,优化第二项等价于最小化 的上界,即 ,我们假设 已经被标准化,此时 的对角元素全为1, 为特征值之和,根据Merikoski (1984)[5]的结论,如果 的所有元素均为正值,则 是 最大特征值的上界,因此,当我们最小化损失的第二项时,我们其实是在间接最小化 的最大特征值,也就是隐式地压平了嵌入空间的奇异谱。
综上所述,对比学习可以潜在地解决表示退化的问题,提升表示向量分布的uniformity,之前的BERT-flow和BERT-whitening仅仅致力于寻找各向同性的表示分布,而在优化对比损失时,对比损失的第二项能够达到同样的规整分布的效果,同时,对比损失的第一项还能确保正样本的对齐,这两项起到了相互制约和促进的作用,最终使得SimCSE在BERT和BERT-flow之间找到了平衡点,这也是SimCSE如此有效的关键之处。
实验
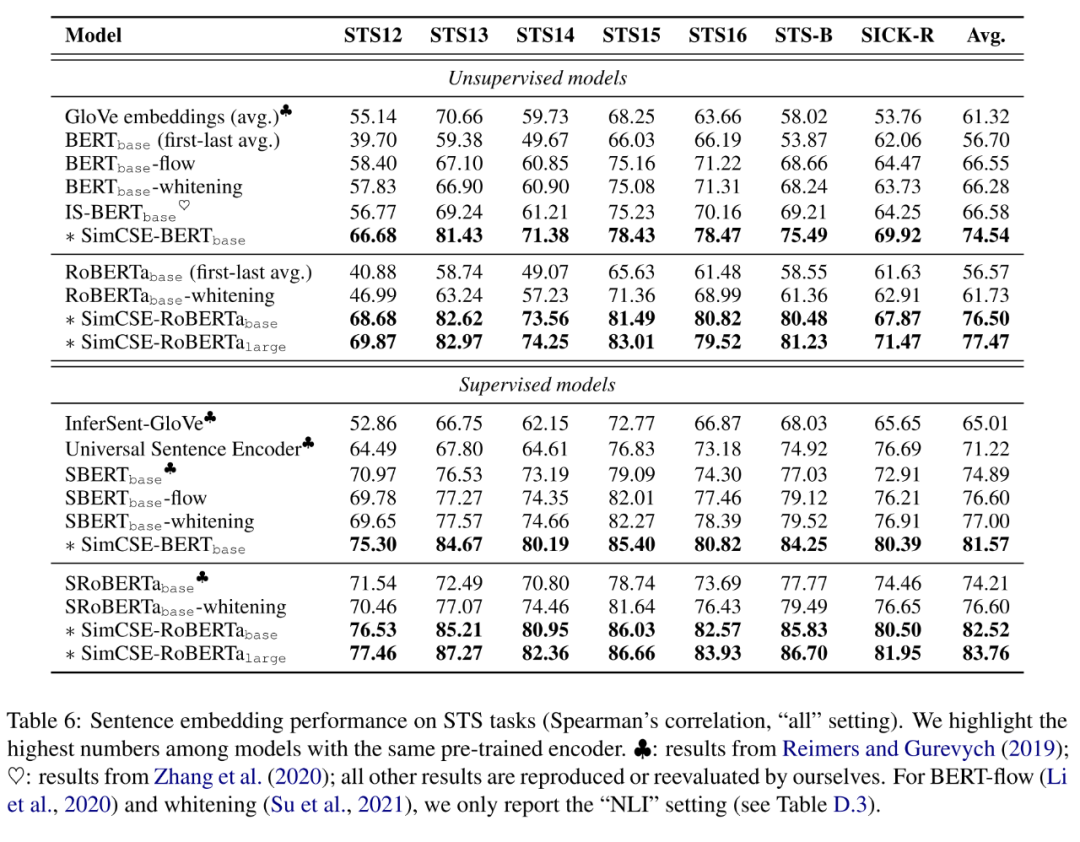
作者借助SentEval在多个数据集上评估了SimCSE的性能,如下表所示,可以发现,在STS系列任务上,SimCSE在无监督和有监督的条件下均大幅超越了之前的SOTA模型,而在迁移任务上,SimCSE也有着可观的性能提升,具体的实验细节可参考原文。
值得说明的是,在迁移任务上,作者尝试了加入MLM损失的trick: ,直观上这缓解了模型对token级别信息的灾难性遗忘,实验结果表明这一额外损失能够提升模型迁移任务上的表现,但对STS任务没有明显帮助。
另外,作者没有比较BERT-flow和BERT-whitening,因为作者发现这些基于后处理的模型在迁移任务上表现还不如BERT,主要原因是这些任务的主要目标并不是学习可用于聚类的语义向量。
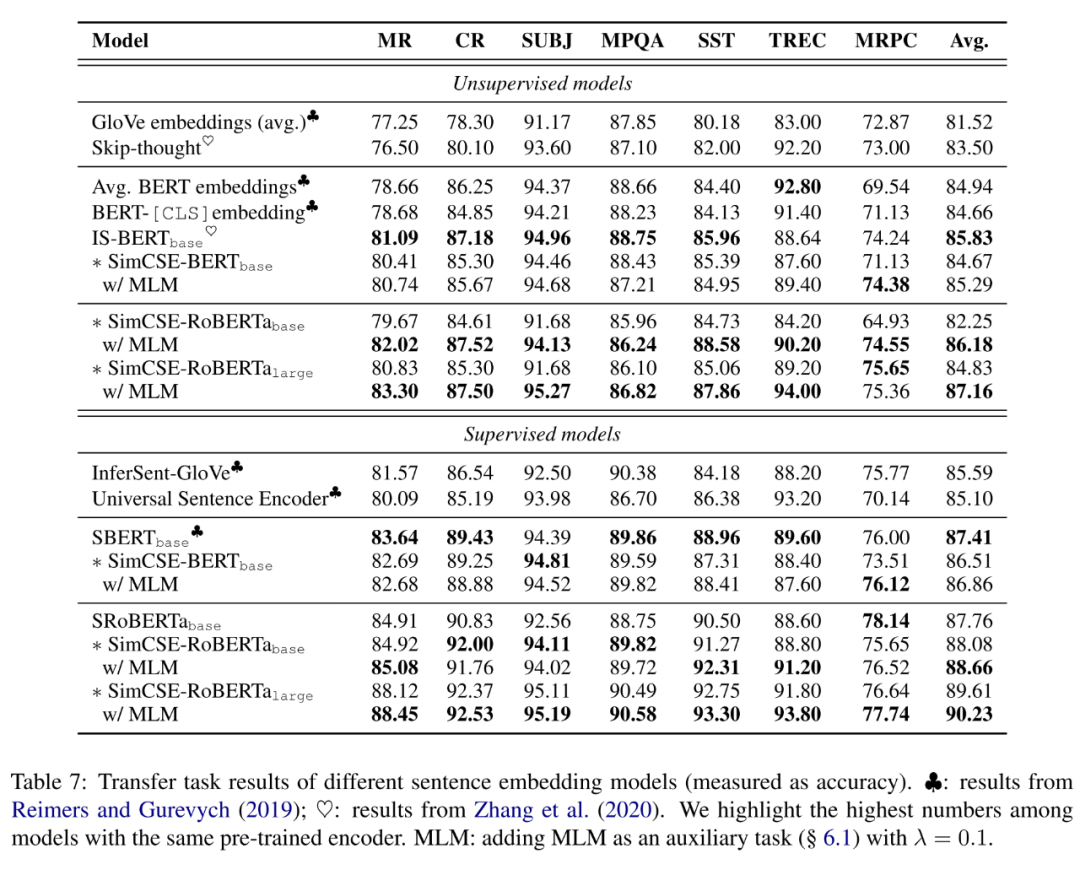
下面是一个关于池化层和MLM的ablation study,可以发现MLM损失对STS任务有负面作用,而对迁移任务有正面作用,但是作者并没有详细解释这其中的原因。

分析
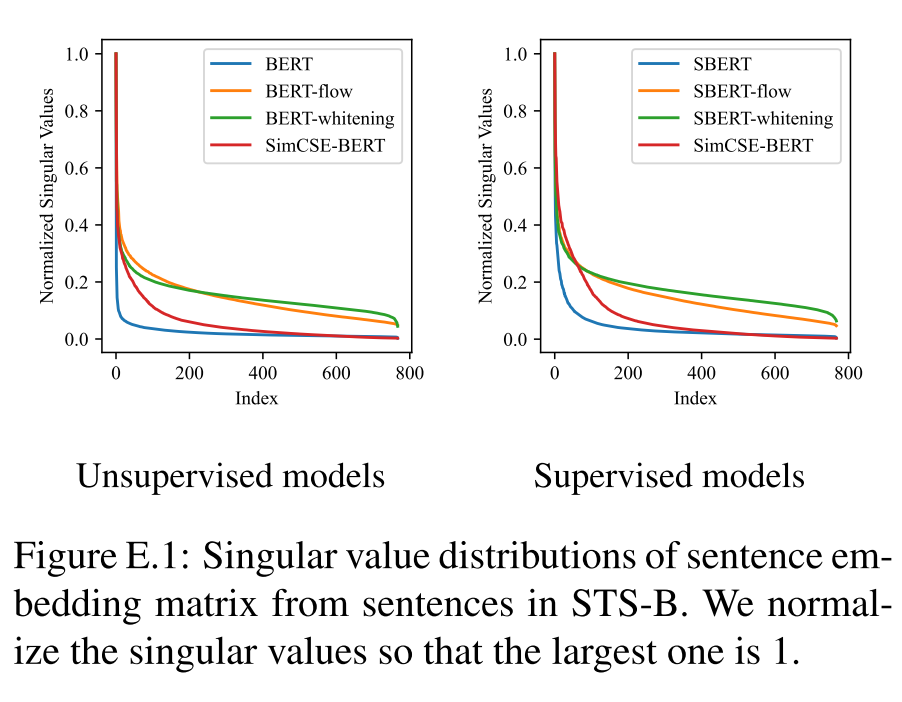
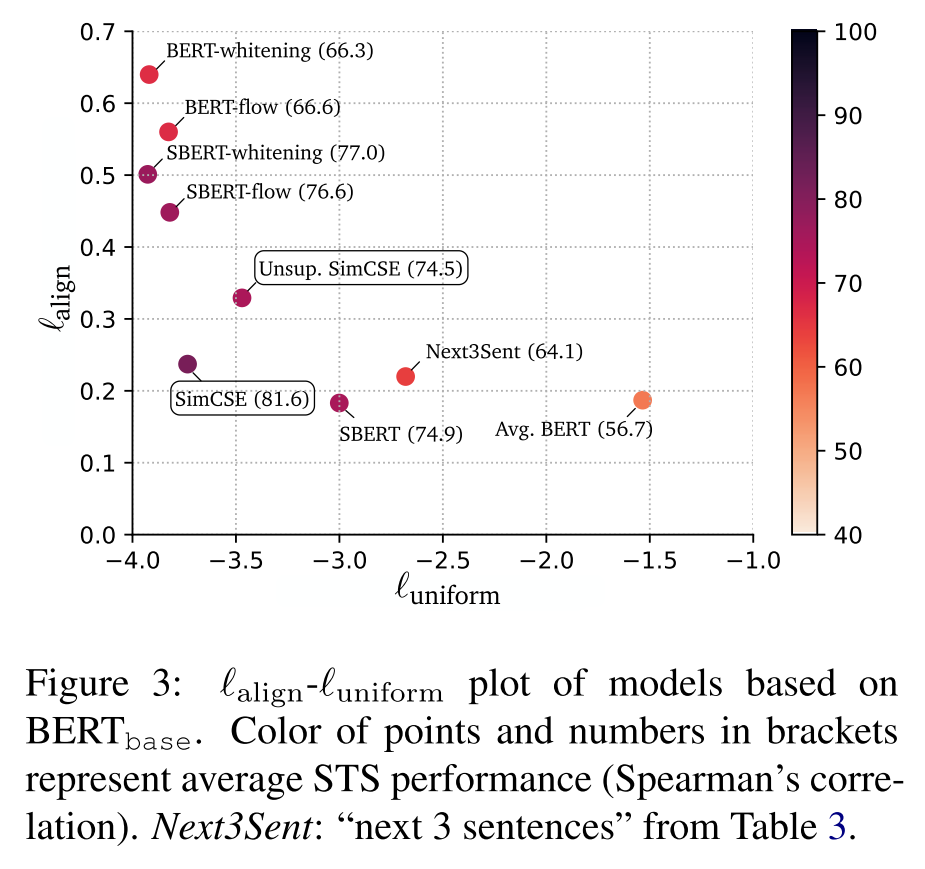
最后作者测试了现有模型的alignment和uniformity,如下图所示。可以发现性能更优的模型通常有着更好的alignment和uniformity,BERT虽然有很好的alignment,但uniformity太差,而基于后处理的BERT-flow和BERT-whitening又恰恰走向了另一个极端,本文提出的SimCSE则是对这两个指标的一个很好的平衡,加入监督训练后,SimCSE的两个指标会同时提升,这个结果和上面的理论证明完全吻合。
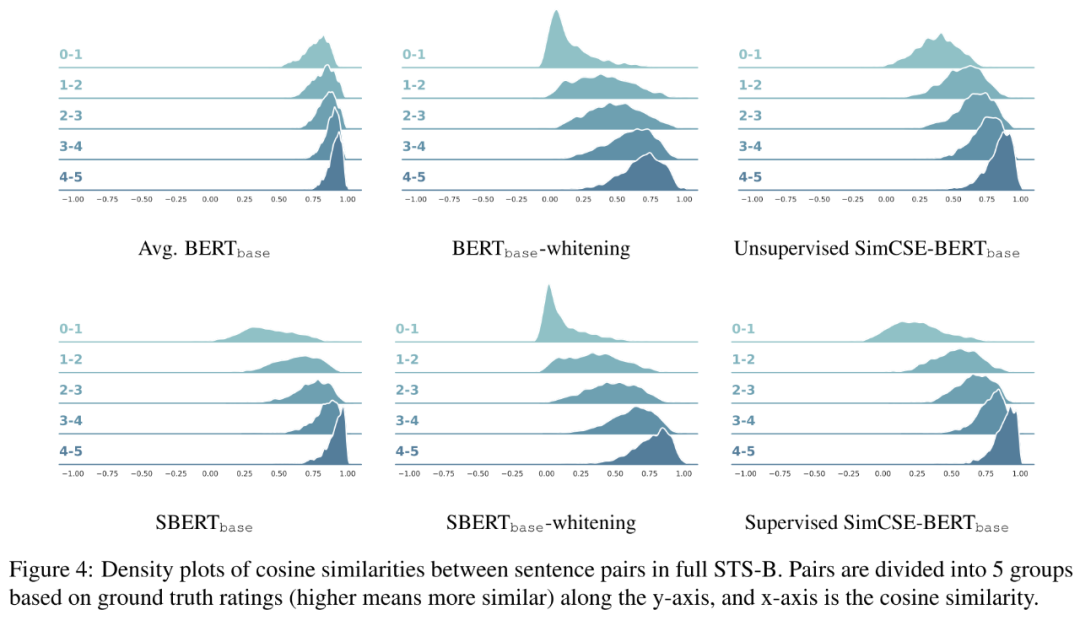
我们可以将上面提到的这三类模型的预测分布做一个可视化,如下图所示,我们可以发现BERT的区分度很差,几乎所有句子对的相似度都在0.7以上,而加上whitening虽然更有区分性,但又增大了整体分布的方差,而SimCSE正是这两者的平衡点,在保持区分度的同时又保持整体分布的集中度。
尾巴
语义相似度计算和语义匹配其实是对比学习在NLP中的一个很好的应用场景,本文提出的random dropout mask为NLP中的对比学习提供了一个全新的视角。由于对比学习是无监督的,所以如何将对比的思想用到无监督的预训练的阶段,学习到更优质的上下文表示,其实是一个值得期待的新方向。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
点击上面卡片,关注我呀,每天推送AI技术干货~
整理不易,还望给个在看!














 2401
2401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









