






来自:机器之心
罗盟,本工作的第一作者。新加坡国立大学(NUS)人工智能专业准博士生,本科毕业于武汉大学。主要研究方向为多模态大语言模型和 Social AI、Human-eccentric AI。
情感计算一直是自然语言处理等相关领域的一个火热的研究课题,最近的进展包括细粒度情感分析(ABSA)、多模态情感分析等等。
新加坡国立大学联合武汉大学、奥克兰大学、新加坡科技设计大学、南洋理工大学团队近期在这个方向上迈出了重要的一步,探索了情感分析的终极形态,提出了 PanoSent —— 一个全景式细粒度多模态对话情感分析基准。PanoSent 覆盖了全面的细粒度、多模态、丰富场景和认知导向的情感分析任务,将为情感计算方向开辟新的篇章,并引领未来的研究方向。该工作被 ACM MM 2024 录用为 Oral paper。

论文地址:https://www.arxiv.org/abs/2408.09481
项目地址:https://panosent.github.io/
研究背景
在人工智能领域,让机器理解人类情感是迈向真正智能化的重要一步。情感分析是自然语言处理领域的一个关键研究课题。通过多年的研究,情感分析在各个维度和方面取得了显著的发展。该领域已从传统的粗粒度分析(如文档和句子级别分析)发展到细粒度分析(例如 ABSA),融合了广泛的情感元素,并发展出提取目标、方面、观点和情感等不同的情感元组。此外,情感分析的范围已从纯文本内容扩展到包括图像和视频的多模态内容。
因为在现实世界场景中,用户通常通过多种多样的多媒体更准确地传达他们的观点和情绪,提供超越文本的附加信息,如微表情、语音语调和其他线索。此外,研究已超越单一文本场景,考虑更复杂的对话情境,在这些情境中,个体在社交媒体平台(例如 Twitter、Facebook、微博、知乎、小红书、抖音等)上频繁进行关于服务、产品、体育等的多轮、多方讨论。
尽管情感分析领域已取得显著进展,目前的研究定义仍然不够全面,无法提供一个完整且详细的情感画面,这主要是由于以下几个问题。
首先,缺乏一个综合定义,将细粒度分析、多模态和对话场景结合起来。在现实生活应用中,如社交媒体和论坛上,这些方面往往需要同时考虑。然而,现有研究要么在多模态情感分析定义中缺乏详细分析,要么在对话 ABSA 中缺失多模态建模。最完整的基于文本的 ABSA 定义仍然无法完全涵盖或细致划分情感元素的粒度。
其次,当前的情感分析定义只考虑识别固定的静态情感极性,忽略了情感随时间变化或因各种因素变化的动态性。例如,社交媒体对话中的用户最初的观点,可能会在接触到其他发言者的新信息或不同观点后发生变化。
第三,也是最关键的,现有工作没有彻底分析或识别情感背后的因果原因和意图。人类情感的激发和变化有特定的触发因素,未能从认知角度理解情感背后的因果逻辑意味着尚未根本实现人类级别的情感智能。总的来说,提供一个更全面的情感分析定义可能会显著增强这项任务的实用价值,例如,开发更智能的语音助手、更好的临床诊断和治疗辅助以及更具人性化的客户服务系统。
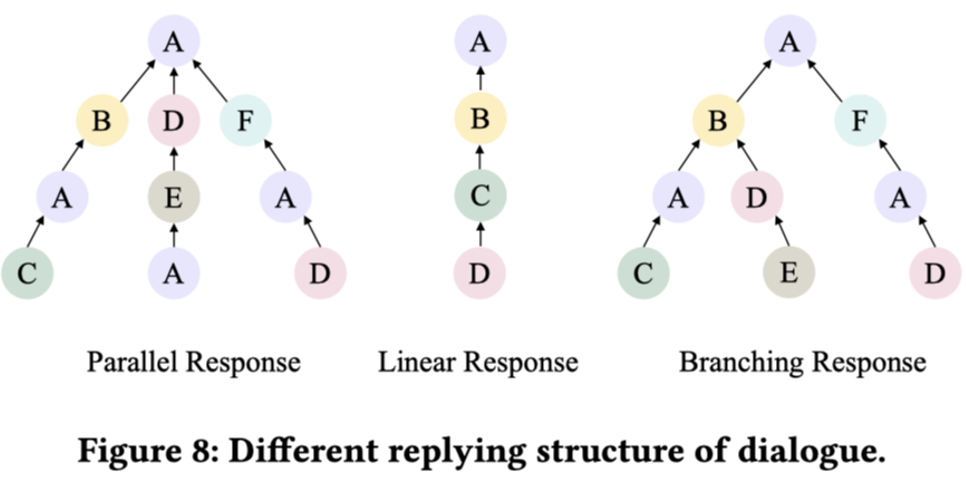
为填补这些空白,本文提出了一种全新的全景式细粒度多模态对话情感分析方法,旨在提供一个更全面的 ABSA 定义,包括全景情感六元组提取(子任务一)和情感翻转分析(子任务二)。如图 1 所示,本文关注的是涵盖日常生活中最常见的四种情感表达模态的对话场景。
一方面,作者将当前的 ABSA 四元组提取定义扩展到六元组提取,包括持有者、目标、方面、观点、情感和理由,全面覆盖更细粒度的情感元素,提供情感的全景视图。
另一方面,作者进一步定义了一个子任务,监控同一持有者在对话中针对同一目标和方面的情感动态变化,并识别导致情感翻转的触发因素。在六元组提取和情感变化识别中,作者强调辨别潜在的因果逻辑与触发因素,力求不仅掌握方法,还要理解背后的原因,并从认知角度进行分析。
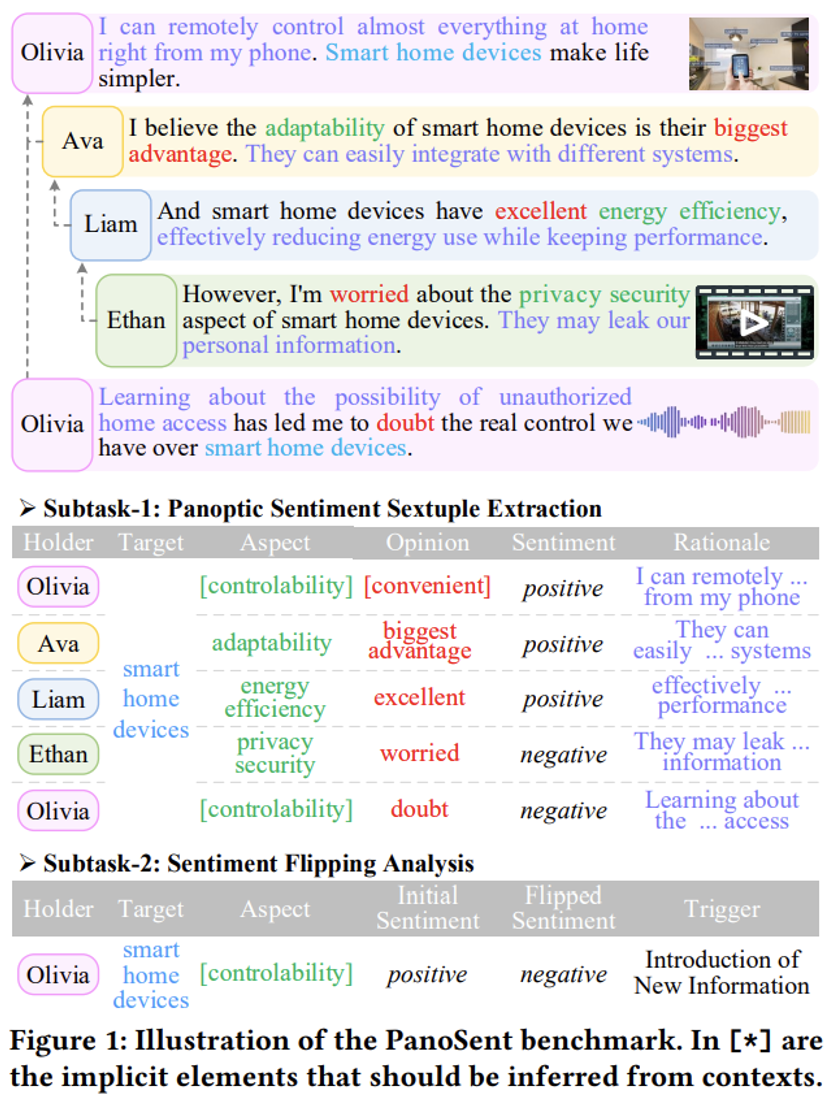
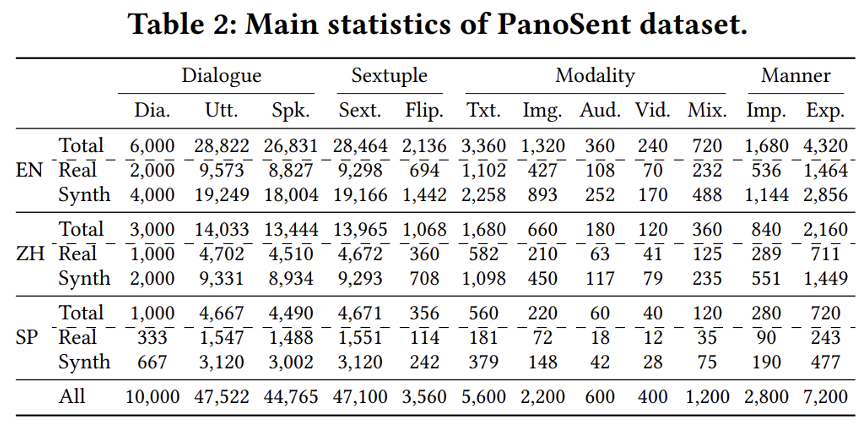
为了对这一新任务进行基准测试,作者构建了一个大规模高质量的数据集,PanoSent。PanoSent 涵盖了 100 多个常见的领域和场景,基于多轮、多方的对话情境,情感元素在六元组中可能跨越多个句子。
为了更真实地模拟人类的情感表达习惯,数据集中的元素可以来自文本和非文本(音频或视觉)模态。情感可能以隐式的方式表达,数据集涵盖了隐式和显式的情感元素。
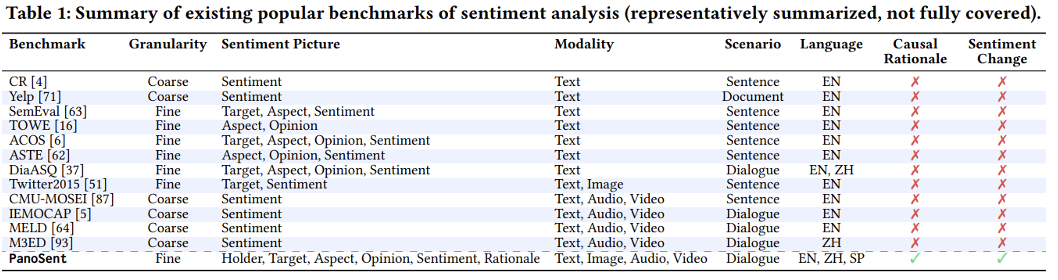
为确保基准的通用性,数据集包括三种主流语言:英语、中文和西班牙语。作者从现实世界来源收集数据,进行了精心的手动标注。为了扩大数据集的规模,作者进一步利用 OpenAI GPT-4 自动生成数据,并结合多模态检索技术进行扩展。严格的人工检查和交叉验证确保了高质量标准。PanoSent 总共覆盖了 10,000 个对话。表 1 对 PanoSent 与现有的一些多模态细粒度情感分析数据集进行了对比分析。
与现有的 ABSA 任务相比,本文提出的新任务提出了更大的挑战,例如需要理解复杂的对话情境并灵活地从各种模态中提取特征,尤其是在认知层面识别因果原因。考虑到多模态大型语言模型(MLLMs)在跨多模态的强大语义理解方面最近取得的巨大成功,作者构建了一个主干 MLLM 系统,Sentica,用于编码和理解多模态对话内容。受人类情感分析过程的启发,作者进一步开发了一个情感链推理框架(CoS),用于高效地解决任务,该框架基于思维链的思想,将任务分解为从简单到复杂的四个渐进推理步骤。该系统能够更有效地提取情感六元组的元素,并逐步识别情感翻转,同时引导出相应的理由和触发因素。基于释义的验证(PpV)机制增强了 CoS 推理过程的稳固性。
全景式细粒度多模态对话情感分析基准:PanoSent
任务建模
PanoSent 包括两个关键任务,具体可参见图 1 的可视化展示。
全景式情感六元组抽取:从多轮、多方、多模态对话中识别情感持有者、目标、方面、观点、情感及其原因。
情感翻转分析:检测对话中情感的动态变化及其背后的因果关系。
PanoSent 基准数据集
研究团队构建了一个包含 10,000 个对话的大规模高质量数据集 PanoSent,数据来自现实世界的多样化来源,情感六元组元素经过手动注释,并借助 GPT-4 和多模态检索进行扩展。通过严格的人工检查和交叉验证,确保数据集的高质量。PanoSent 数据集首次引入了隐式情感元素和情感背后的认知原因,覆盖最全面的细粒度情感元素,适用于多模态、多语言和多场景的应用。
多模态情感分析大模型:Sentica
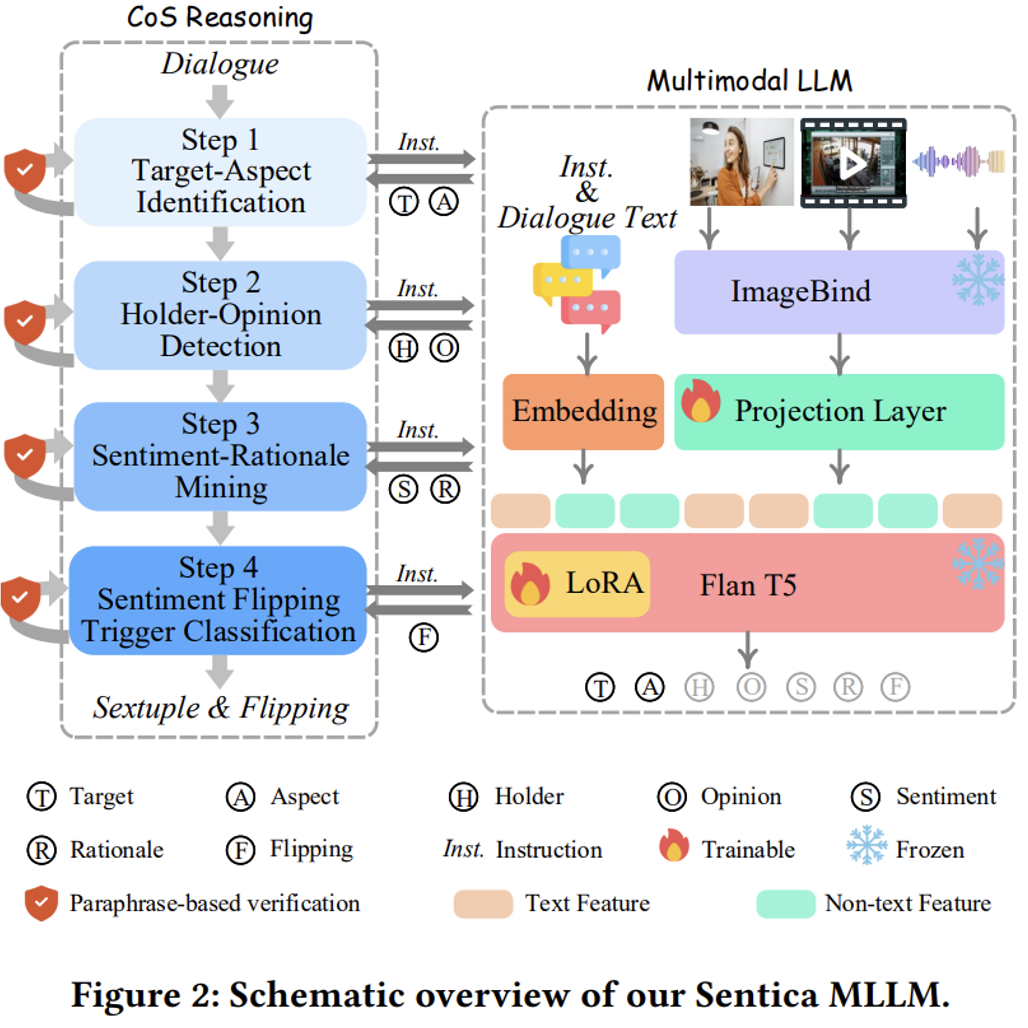
多模态大语言模型骨干
当前,大型语言模型(LLM)在理解语言语义方面表现卓越,多模态大语言模型(MLLM)则展示了对多模态数据的强大理解能力。基于此,研究团队为 PanoSent 设计了一款新的 MLLM——Sentica。该模型使用 Flan-T5 (XXL) 作为语义理解和决策的核心 LLM。对于非文本输入,采用 ImageBind 统一编码多模态信息,并将编码结果投影到 LLM 的嵌入空间。
链式情感推理框架
针对全景式情感六元组抽取和情感翻转分析任务,团队提出了受思想链(CoT)推理启发的链式情感推理框架(CoS)。该框架通过四个渐进的推理步骤,从简单到复杂,逐步解决每个任务,并为后续步骤积累关键线索和见解。步骤包括 “目标 – 方面” 识别、“持有者 - 观点” 检测、“情感 - 理由” 挖掘及 “情感翻转触发器” 分类。
步骤 1:“目标 - 方面” 识别
在给定对话文本及其多模态信号下,通过特定指令,要求模型识别对话中提到的所有可能的目标及其对应的方面,形成目标 - 方面对。

步骤 2:“持有者 - 观点” 检测
在识别出 “目标 - 方面” 对之后,下一步是检测相关的持有者及其具体观点。输出应为包含持有者、目标、方面和观点的四元组,为后续的情感分析奠定基础。

步骤 3:“情感 - 理由” 挖掘
基于已识别的四元组,分析与每个观点相关的情感并识别其背后的理由。最终输出为六元组,全面展现情感表达及其背后的因果逻辑。

步骤 4:“情感翻转触发器” 分类
在识别出所有六元组后,最后一步是检测情感的翻转,即从初始情感到翻转情感的变化,对导致情感翻转的触发因素进行分类。输出应为包含上述情感元素的六元组或 “None” (如果没有情感翻转)

基于复述的验证
为避免链式推理中可能产生的错误累积,研究团队设计了基于复述的验证机制(PpV)。在每个推理步骤中,通过将结构化的 k 元组转化为自然语言表达,并结合上下文检查其是否具有蕴涵或矛盾关系,从而确保每个步骤的准确性。这一机制不仅增强了情感分析的稳健性,还有效减轻了 LLM 固有幻觉的影响。




实验和分析
主实验结果
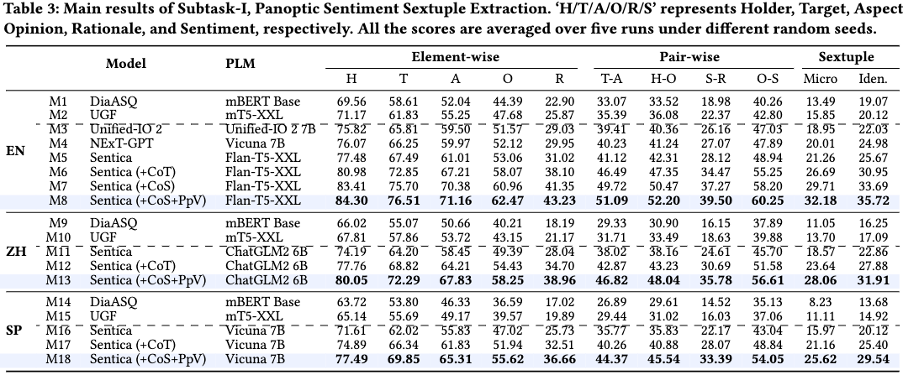
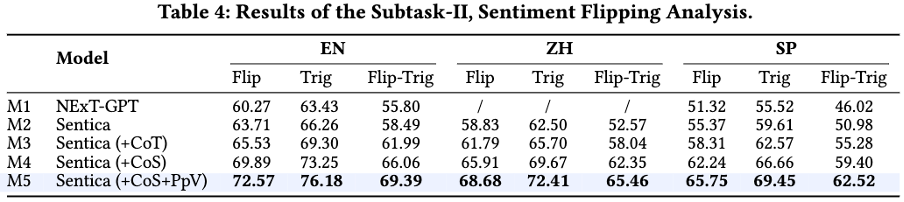
团队通过实验验证了 Sentica 在两个子任务中的表现。在六元组抽取任务中,Sentica 显著优于其他方法,尤其是在结合 CoS 和 PpV 机制后,表现达到最佳。在情感翻转分析中,Sentica 同样表现出色,特别是在多语言环境下,准确性显著提高。
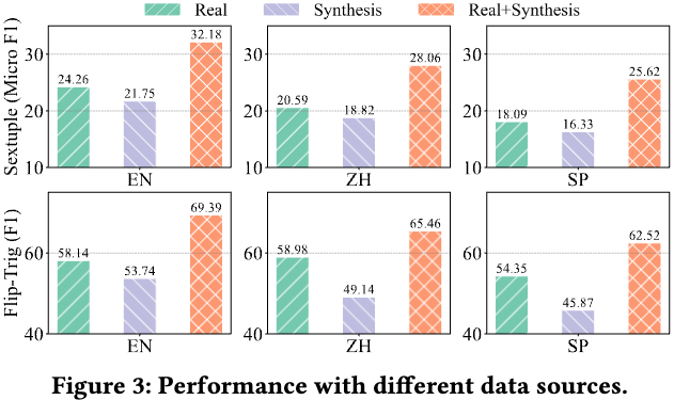
验证构建合成数据的必要性
实验结果表明,尽管合成数据量较大,模型在真实数据上的训练效果更佳。这是因为真实数据的信息分布更为自然,帮助模型学习到更具代表性的特征。然而,合成数据作为补充则显著提升了模型的最终性能,进一步证明了合成数据在优化模型表现中的关键作用。因此,构建合成数据不仅是必要的,而且有助于提升情感分析的整体效果。
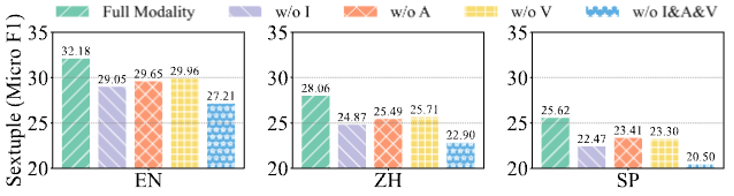
验证多模态信息的重要性
研究团队深入分析了多模态信息在情感分析中的作用,发现其不仅是对文本信息的补充,还在六元组元素的判断中起到关键作用。实验结果显示,移除任何模态信号都会导致性能下降,尤其是图像信息的缺失对性能的影响最大。这表明,多模态信息在任务中不可或缺,对提高模型的识别精度至关重要。
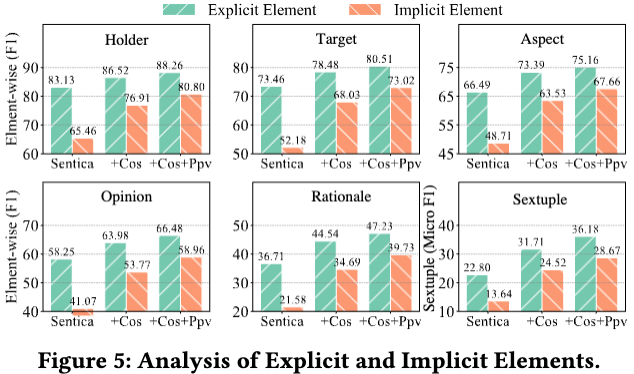
验证显性与隐性元素的识别性能
通过对显性与隐性情感元素的识别性能进行对比分析,结果显示,隐性元素的识别难度明显高于显性元素。这反映了识别隐性元素对上下文语义理解的更高要求,进一步说明在情感分析中,应特别关注对隐性元素的识别和处理。
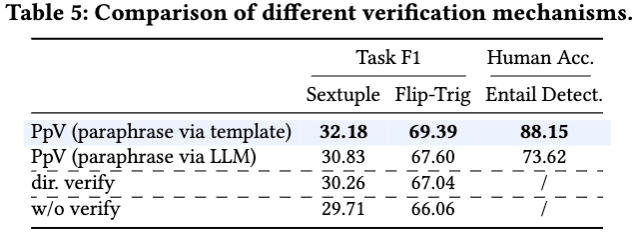
验证 PpV 机制的合理性
作者验证了基于复述的验证机制(PpV)的有效性。实验表明,通过 LLM 复述和直接验证,PpV 机制能够确保结构化数据与对话上下文之间的语义一致性,其性能优于仅依赖直接验证或不进行验证的方式。此外,使用固定模板复述结构化元组比依赖 LLM 复述更为可靠,这进一步增强了情感分析的稳健性。
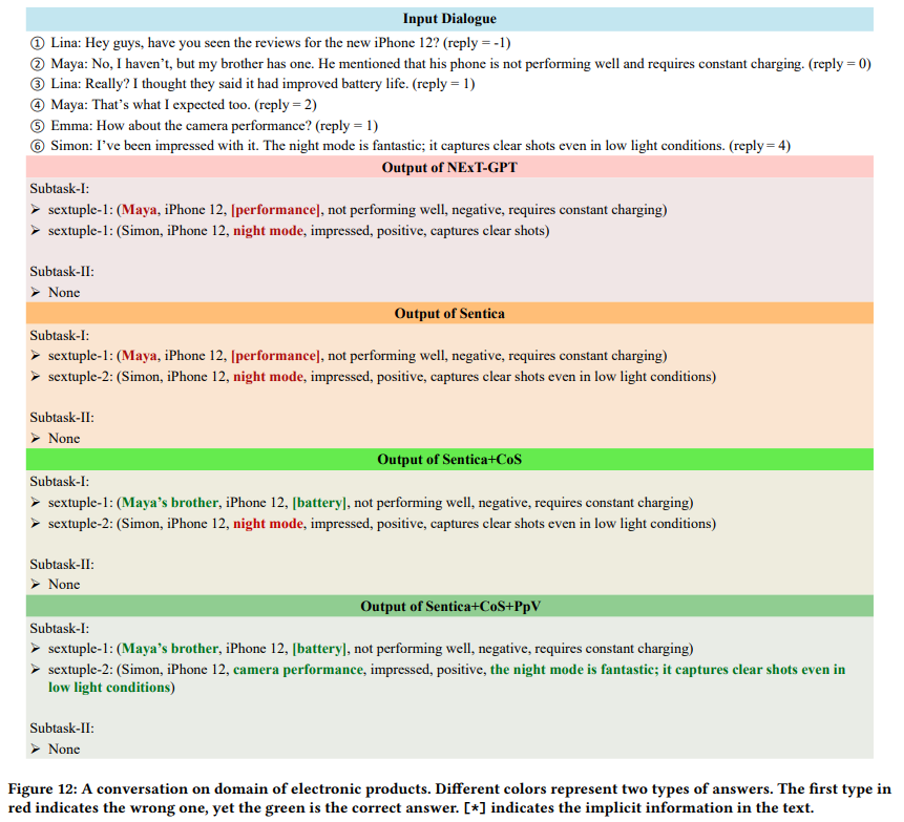
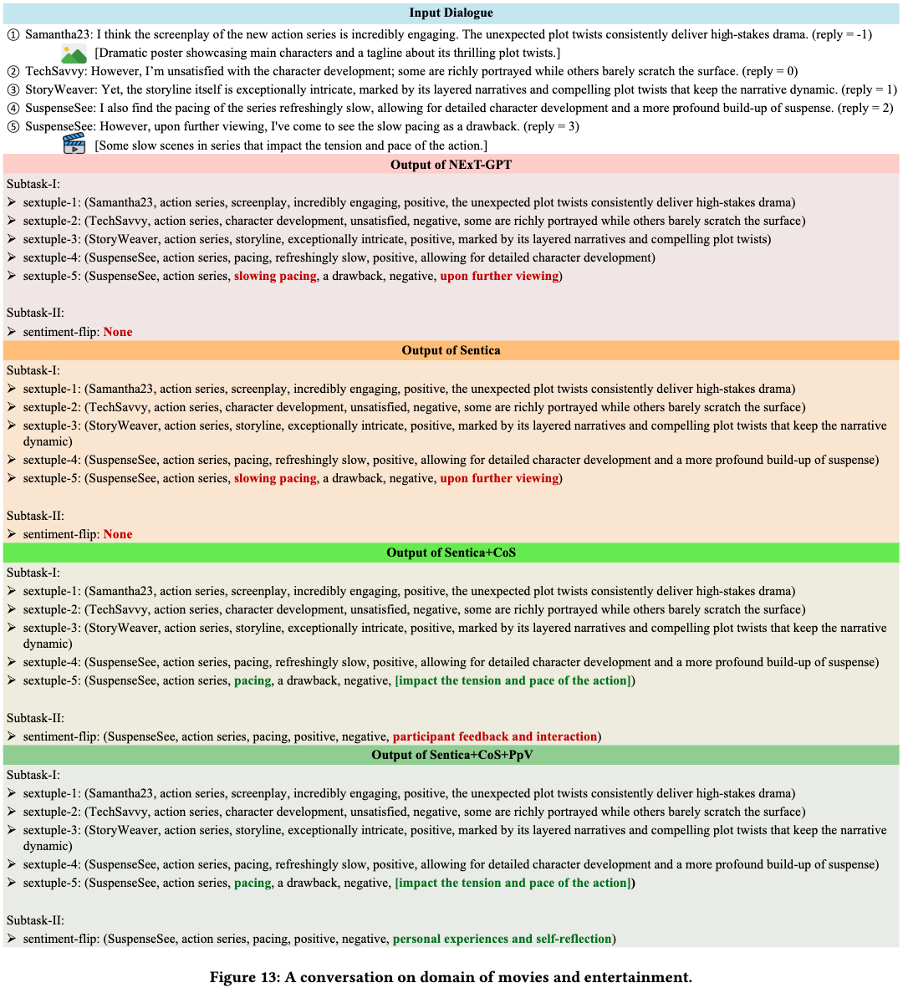
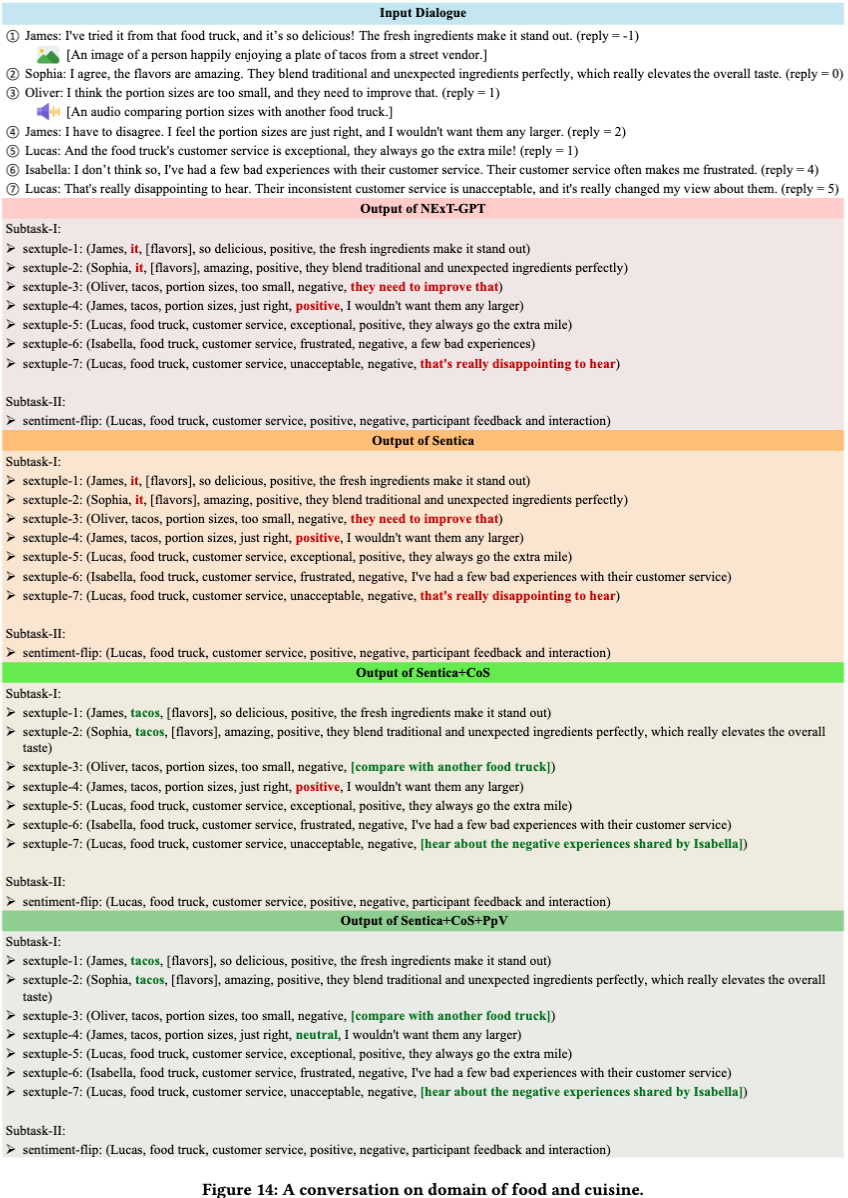
案例研究
作者通过多个实例展示了所提出模型在与其他模型对比中的优越性能。如图 12-14 所示,该模型展现了对复杂对话上下文的更深入理解,能够精准捕捉对话中的微妙细节,并推断出隐含意图。得益于卓越的多模态信息处理能力,该模型能够更准确地解释各种模态信号。此外,该模型在识别对话中隐含元素方面表现突出。这些优势使模型能够更全面地提取六元组信息,并更准确地分析对话中的情感翻转。
结论与展望
在这项研究中,团队引入了全新的全景式细粒度多模态对话情感分析基准 PanoSent,提出了两项新任务:全景情感六元组抽取和情感翻转分析。基于 MLLM 的链式情感推理方法在 PanoSent 数据集上展示了卓越的基准性能,为情感分析领域开辟了新的篇章。
未来的研究可以朝以下几个方向展开:
多模态信息的进一步探索:开发更强大的多模态特征提取和融合方法,深入研究不同模态在情感识别中的具体影响。
隐性情感元素的识别:探索更精准的技术来识别隐性情感元素,这是当前情感分析中较为棘手的挑战。
情感认知与推理机制:研究情感元素之间的交互及其背后的因果机制,以开发更为稳健的情感推理解决方案。
对话上下文的建模:增强模型对对话上下文的理解能力,特别是在处理对话结构和说话者共指解析方面。
跨语言与跨领域迁移学习:研究多模态场景下的迁移学习方法,开发能适应不同语言和领域的通用情感分析模型。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦
















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









