



近年来,大语言模型(LLM)代理在完成复杂任务方面表现出色,它们能调用外部工具、执行多步推理,甚至自主决策。然而,就像人类需要记忆来积累经验一样,LLM代理也需要一个长期内存系统来存储和利用历史交互信息。现有的内存系统虽然能实现基本的存储和检索功能,但大多依赖预设的结构和流程,缺乏灵活性。当代理面对新任务或知识演进时,这种僵化的设计会严重限制其适应能力。

论文:A-Mem: Agentic Memory for LLM Agents
链接:https://arxiv.org/pdf/2502.12110
录取:NIPS2025
正是在这样的背景下,该论文提出了一种全新的“能动内存系统”。A-Mem受启发于经典的笔记方法Zettelkasten,赋予内存动态组织、自动链接和持续进化的能力。它不仅能让代理“记住”过去,还能让记忆“自我整理”和“自我更新”,从而显著提升长期对话、复杂推理等任务的性能。实验表明,A-Mem在多个基准测试中大幅领先现有方法,同时保持极高的成本效率。接下来,我们将深入解读这一系统是如何设计的、为什么有效,以及它为我们带来了哪些启示。
研究动机与背景
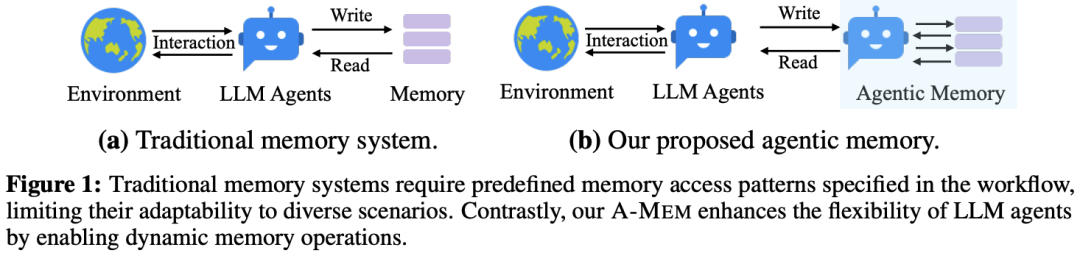 LLM代理若想真正实现长期、自主的交互,就必须具备类似人类的记忆能力:不仅能存储信息,还能在需要时灵活调用、关联不同经验,甚至从新事件中更新旧有认知。现有内存系统(如MemGPT、MemoryBank等)虽然提供了基础功能,但存在两大瓶颈:
LLM代理若想真正实现长期、自主的交互,就必须具备类似人类的记忆能力:不仅能存储信息,还能在需要时灵活调用、关联不同经验,甚至从新事件中更新旧有认知。现有内存系统(如MemGPT、MemoryBank等)虽然提供了基础功能,但存在两大瓶颈:
结构僵化:内存的存储格式、检索时机往往由开发者预先设定,无法根据任务动态调整。
缺乏演进:记忆之间是孤立的,新知识无法触发旧记忆的更新或重组。
论文指出,这就像一本只有目录没有索引的笔记本——你可以往里写内容,但很难快速找到关联信息。为此,作者借鉴了Zettelkasten(卡片盒笔记法)的核心思想:每张笔记是独立的(原子性),但通过灵活的链接形成知识网络。A-Mem将这一理念转化为计算模型,让LLM代理具备“自我组织记忆”的能力。
A-Mem方法详解
整体架构概览
A-Mem的核心是一个动态、自演进的内存网络。每当代理有一次新交互,系统会执行三步操作:
笔记构建:将原始交互转化为结构化的记忆笔记;
链接生成:自动寻找与已有记忆的关联并建立链接;
记忆进化:根据新记忆更新相关旧记忆的上下文或标签。
整个流程如下图所示,清晰展示了从输入到存储再到检索的闭环:
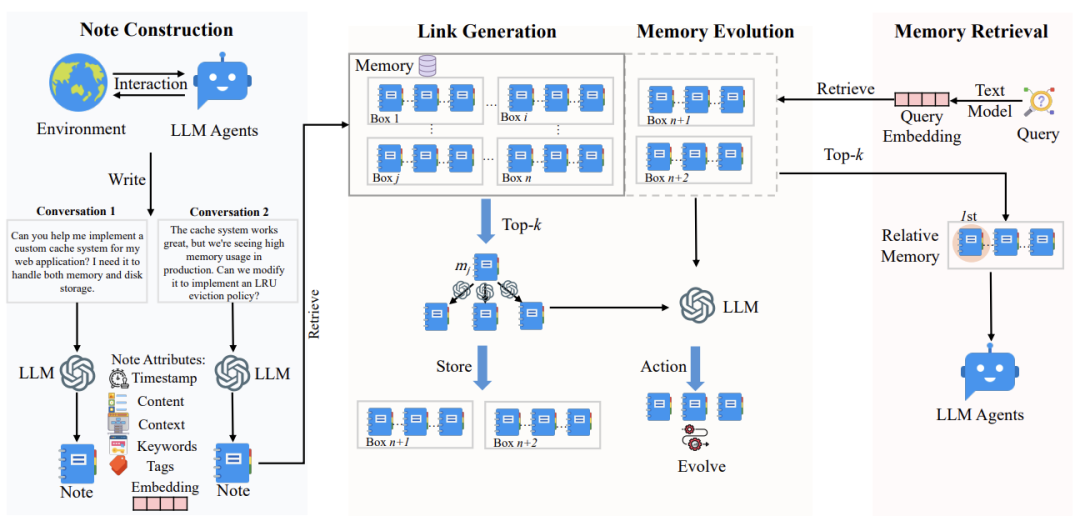
笔记构建:从交互到结构化记忆
每个记忆笔记不是一个简单的文本片段,而是一个包含多种属性的“智能单元”。具体来说,一个笔记 被定义为:
其中:
:原始交互内容(如用户说的话)
:时间戳
:LLM生成的关键词(捕捉核心概念)
:LLM生成的标签(用于分类)
:LLM生成的上下文描述(一段总结性文字)
:嵌入向量(用于相似度计算)
:链接的其他记忆ID列表
这些属性中, 是由LLM根据模板 生成的:
这样做的好处是,LLM能从原始内容中提炼出隐含的语义信息,使记忆更具表达力。最后,系统将所有文本部分拼接后通过编码器(如Sentence-BERT)生成嵌入向量 ,用于后续相似度匹配。
链接生成:建立记忆间的“思维桥梁”
当新记忆 加入后,系统会计算它与所有已有记忆的余弦相似度:
选出最相似的top-个记忆作为候选邻居:
然后,再次调用LLM,基于这些候选记忆的内容分析是否应该建立链接:
这一步的关键在于,LLM能识别出纯向量相似度无法捕捉的深层关系(如因果关系、主题演变),使链接更具语义意义。
记忆进化:让记忆“活起来”
链接建立后,系统会进一步检查是否需要对旧记忆进行更新。对于每个邻居记忆 ,LLM会判断是否需要调整其上下文、关键词或标签:
更新后的记忆 将替换原记忆。这个过程模拟了人类的学习:新知识不只是叠加,而是整合到已有知识体系中,引发认知升级。
记忆检索:智能召回历史信息
当代理需要回答当前查询 时,系统计算查询的嵌入向量 ,并与所有记忆笔记进行相似度匹配,返回最相关的top-个记忆作为上下文。这一步与传统RAG类似,但得益于前面的动态链接,检索到的记忆更具连贯性和相关性。
实验验证与结果分析
实验设置
论文使用两个长对话数据集:
LoCoMo:平均9K token、35轮对话,包含单跳、多跳、时序、开放域、对抗性五类问题。
DialSim:基于电视剧对话的问答数据集,涵盖复杂时序关系。
对比基线包括LoCoMo(无内存)、ReadAgent、MemoryBank、MemGPT。评估指标除了F1和BLEU,还包括ROUGE、METEOR、SBERT相似度等。
性能对比:A-Mem全面领先
下表展示了在LoCoMo数据集上,A-Mem在不同模型和任务类别中的表现:
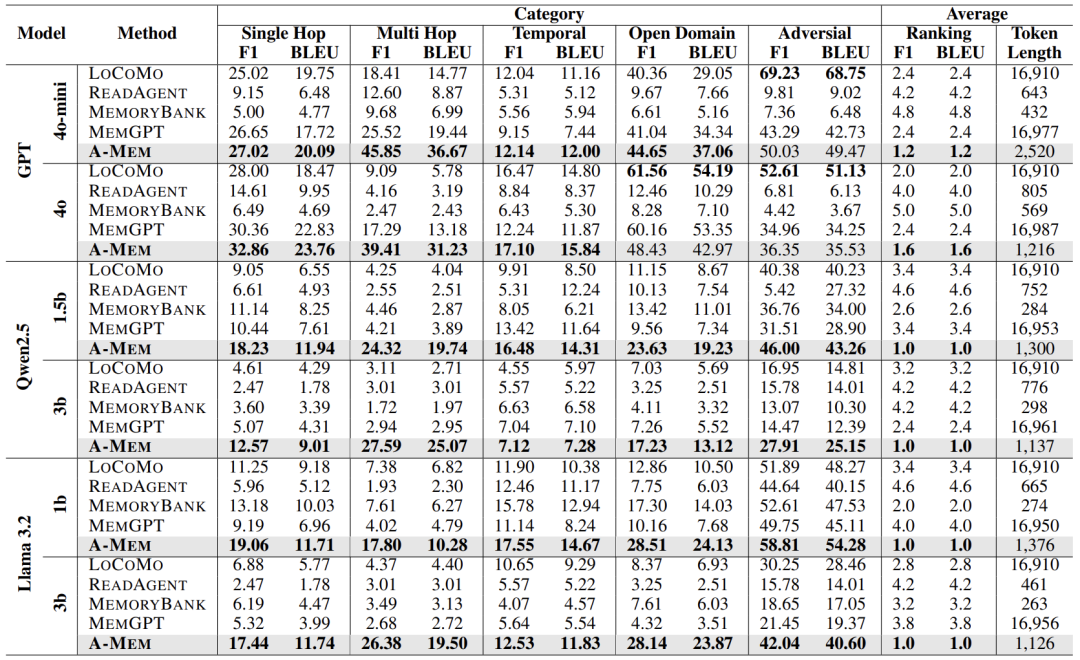
可以看出,A-Mem在多数任务上显著优于基线,尤其是在多跳推理任务中,成绩可达基线两倍以上。例如在使用GPT-4o-mini时,A-Mem在多跳任务上的F1得分达45.85%,远高于MemGPT的25.52%。这证明其动态链接机制能有效支持复杂推理。
在DialSim数据集上,A-Mem同样表现突出:

消融研究:每个模块都关键
作者进一步验证了链接生成(LG)和记忆进化(ME)模块的重要性。如下表所示,去掉任一模块性能都会下降,尤其是多跳和开放域任务:

超参数分析:k值并非越大越好
检索数量k的影响如下图所示:
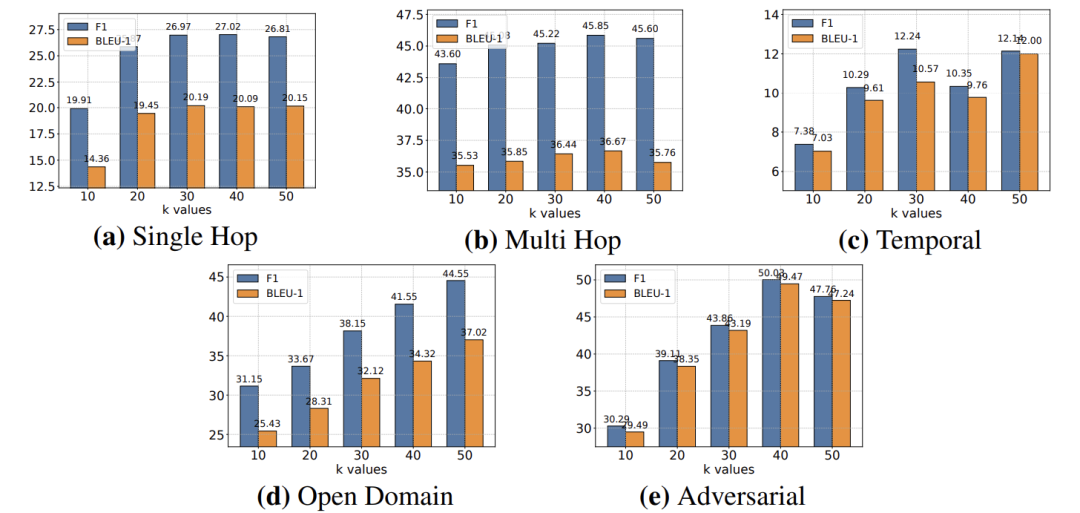
当k从10增加到50时,性能先升后平缓甚至略降。说明过多的记忆会引入噪声,适中k值(如10-40)能在丰富上下文和处理效率间取得平衡。
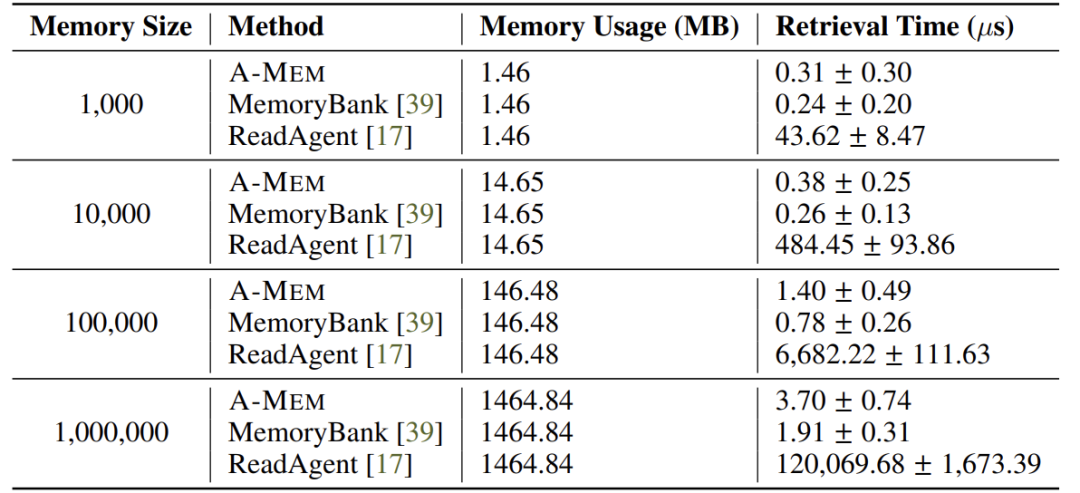
扩展性分析:内存增长不影响效率
即使内存条目从1,000增至1,000,000,A-Mem的检索时间仅从0.31μs升至3.70μs,显示其具备良好的可扩展性:
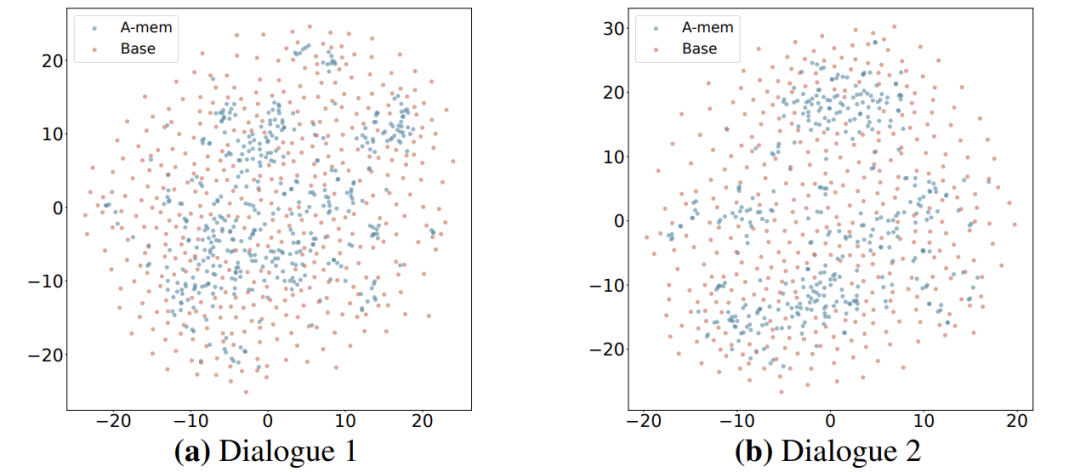
内存结构可视化:更有序的知识网络
t-SNE图显示,A-Mem的记忆嵌入(蓝色)比基线(红色)更聚集、更有结构,证明其能自主形成有意义的记忆组织:
讨论
A-Mem的核心创新在于将“能动性”赋予内存本身:
动态组织:记忆不是静态存储,而是能自动链接、进化;
语义理解:利用LLM生成上下文和链接,超越单纯向量匹配;
成本效益:token使用量减少85-93%,推理速度更快。
与Agentic RAG系统(如Self-RAG)相比,A-Mem的“能动性”体现在内存结构的自我演进,而后者主要优化检索策略。这意味着A-Mem更适合长期、演进式的交互场景。
局限性
论文也指出几点局限性:
内存质量依赖底层LLM的能力;
目前仅支持文本,未来可扩展至多模态;
不同LLM可能生成不一致的链接或描述。
未来工作包括探索多模态记忆、减少模型依赖性、以及应用于更广泛的代理任务(如自动驾驶、机器人)。
结论
A-Mem通过引入Zettelkasten式的动态内存组织机制,为LLM代理提供了真正意义上的“长期记忆”。它不仅能存储信息,还能自我链接、自我进化,从而在复杂推理任务中取得显著优势。实验证明,其在性能、效率和可扩展性方面均优于现有方法,为构建更智能、更自主的LLM代理奠定了重要基础。



















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









