







25. Leetcode 121 买卖股票的最佳时机
难度:⭐️⭐️
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
-
示例 1:
-
输入:[7,1,5,3,6,4]
-
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。 -
示例 2:
-
输入:prices = [7,6,4,3,1]
-
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
方法1 暴力
这道题目最直观的想法,就是暴力,找最优间距了。
class Solution {
public:
int maxProfit(vector<int>& prices) {
int result = 0;
for (int i = 0; i < prices.size(); i++) {
for (int j = i + 1; j < prices.size(); j++){
result = max(result, prices[j] - prices[i]);
}
}
return result;
}
};
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
当然该方法超时了。
方法2 贪心
因为股票就买卖一次,那么贪心的想法很自然就是取最左最小值,取最右最大值,那么得到的差值就是最大利润。
C++代码如下:
class Solution {
public:
int maxProfit(vector<int>& prices) {
int low = INT_MAX;
int result = 0;
for (int i = 0; i < prices.size(); i++) {
low = min(low, prices[i]); // 取最左最小价格
result = max(result, prices[i] - low); // 直接取最大区间利润
}
return result;
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1)
方法3 动态规划
动规五部曲分析如下:
1.确定dp数组(dp table)以及下标的含义
dp[i][0] 表示第i天持有股票所得最多现金 ,这里可能有同学疑惑,本题中只能买卖一次,持有股票之后哪还有现金呢?
其实一开始现金是0,那么加入第i天买入股票现金就是 -prices[i], 这是一个负数。
dp[i][1] 表示第i天不持有股票所得最多现金
注意这里说的是“持有”,“持有”不代表就是当天“买入”!也有可能是昨天就买入了,今天保持持有的状态
很多同学把“持有”和“买入”没区分清楚。
在下面递推公式分析中,我会进一步讲解。
2.确定递推公式
如果第i天持有股票即dp[i][0], 那么可以由两个状态推出来
- 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:dp[i - 1][0]
- 第i天买入股票,所得现金就是买入今天的股票后所得现金即:-prices[i]
那么dp[i][0]应该选所得现金最大的,所以dp[i][0] = max(dp[i - 1][0], -prices[i]);
如果第i天不持有股票即dp[i][1], 也可以由两个状态推出来
- 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:dp[i - 1][1]
- 第i天卖出股票,所得现金就是按照今天股票价格卖出后所得现金即:prices[i] + dp[i - 1][0]
同样dp[i][1]取最大的,dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);
这样递推公式我们就分析完了
3.dp数组如何初始化
由递推公式 dp[i][0] = max(dp[i - 1][0], -prices[i]); 和 dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);可以看出
其基础都是要从dp[0][0]和dp[0][1]推导出来。
那么dp[0][0]表示第0天持有股票,此时的持有股票就一定是买入股票了,因为不可能有前一天推出来,所以dp[0][0] -= prices[0];
dp[0][1]表示第0天不持有股票,不持有股票那么现金就是0,所以dp[0][1] = 0;
4.确定遍历顺序
从递推公式可以看出dp[i]都是由dp[i - 1]推导出来的,那么一定是从前向后遍历。
5.举例推导dp数组
以示例1,输入:[7,1,5,3,6,4]为例,dp数组状态如下:
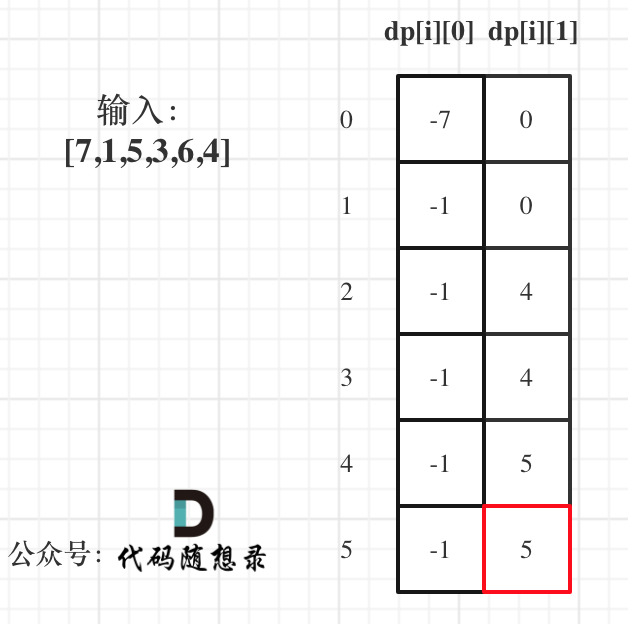
dp[5][1]就是最终结果。
为什么不是dp[5][0]呢?
因为本题中不持有股票状态所得金钱一定比持有股票状态得到的多!
26. Leetcode 122 买卖股票的最佳时机II
难度:⭐️⭐️
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
-
示例 1:
-
输入: [7,1,5,3,6,4]
-
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4。随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。 -
示例 2:
-
输入: [1,2,3,4,5]
-
输出: 4
解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。 -
示例 3:
-
输入: [7,6,4,3,1]
-
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
提示:
- 1 <= prices.length <= 3 * 10 ^ 4
- 0 <= prices[i] <= 10 ^ 4
方法1:贪心
这道题目可能我们只会想,选一个低的买入,再选个高的卖,再选一个低的买入.....循环反复。
如果想到其实最终利润是可以分解的,那么本题就很容易了!
如何分解呢?
假如第 0 天买入,第 3 天卖出,那么利润为:prices[3] - prices[0]。
相当于(prices[3] - prices[2]) + (prices[2] - prices[1]) + (prices[1] - prices[0])。
此时就是把利润分解为每天为单位的维度,而不是从 0 天到第 3 天整体去考虑!
那么根据 prices 可以得到每天的利润序列:(prices[i] - prices[i - 1]).....(prices[1] - prices[0])。
如图:
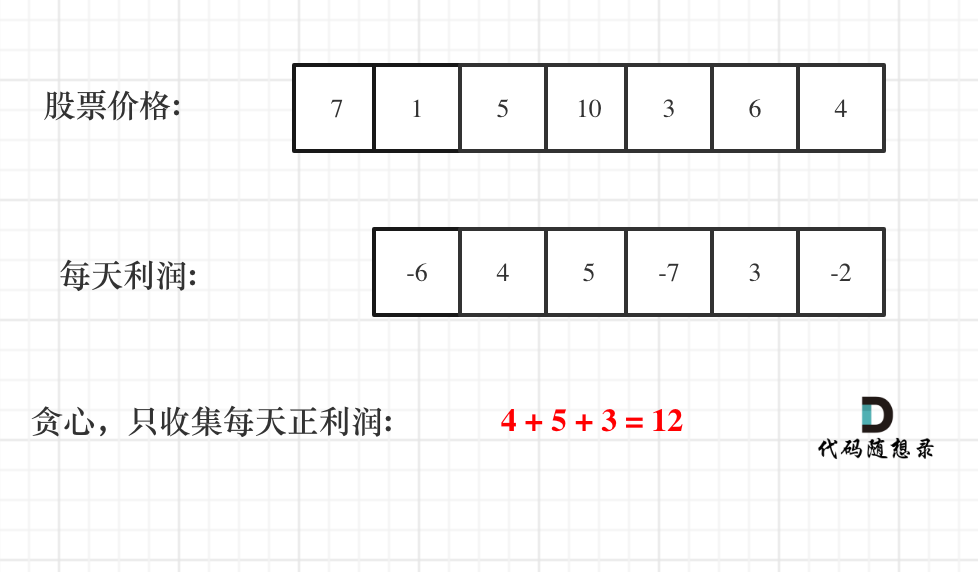
一些同学陷入:第一天怎么就没有利润呢,第一天到底算不算的困惑中。
第一天当然没有利润,至少要第二天才会有利润,所以利润的序列比股票序列少一天!
从图中可以发现,其实我们需要收集每天的正利润就可以,收集正利润的区间,就是股票买卖的区间,而我们只需要关注最终利润,不需要记录区间。
那么只收集正利润就是贪心所贪的地方!
局部最优:收集每天的正利润,全局最优:求得最大利润。
局部最优可以推出全局最优,找不出反例,试一试贪心!
方法2:动态规划
本题和121. 买卖股票的最佳时机 (opens new window)的唯一区别是本题股票可以买卖多次了(注意只有一只股票,所以再次购买前要出售掉之前的股票)
在动规五部曲中,这个区别主要是体现在递推公式上,其他都和121. 买卖股票的最佳时机 (opens new window)一样一样的。
注意这里和121. 买卖股票的最佳时机 (opens new window)唯一不同的地方,就是推导dp[i][0]的时候,第i天买入股票的情况。
在121. 买卖股票的最佳时机 (opens new window)中,因为股票全程只能买卖一次,所以如果买入股票,那么第i天持有股票即dp[i][0]一定就是 -prices[i]。
而本题,因为一只股票可以买卖多次,所以当第i天买入股票的时候,所持有的现金可能有之前买卖过的利润。
那么第i天持有股票即dp[i][0],如果是第i天买入股票,所得现金就是昨天不持有股票的所得现金 减去 今天的股票价格 即:dp[i - 1][1] - prices[i]。
27. Leetcode 123 买卖股票的最佳时机III
难度:⭐️⭐️⭐️(动态规划,动态规划+滚动数组)/⭐️⭐️⭐️⭐️⭐️(动态规划+一维滚动数组,贪心)
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
-
示例 1:
-
输入:prices = [3,3,5,0,0,3,1,4]
-
输出:6 解释:在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3。
-
示例 2:
-
输入:prices = [1,2,3,4,5]
-
输出:4 解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4。注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
-
示例 3:
-
输入:prices = [7,6,4,3,1]
-
输出:0 解释:在这个情况下, 没有交易完成, 所以最大利润为0。
-
示例 4:
-
输入:prices = [1] 输出:0
提示:
- 1 <= prices.length <= 10^5
- 0 <= prices[i] <= 10^5
方法1 动态规划
这道题目相对 121.买卖股票的最佳时机 (opens new window)和 122.买卖股票的最佳时机II (opens new window)难了不少。
关键在于至多买卖两次,这意味着可以买卖一次,可以买卖两次,也可以不买卖。
接来下我用动态规划五部曲详细分析一下:
- 确定dp数组以及下标的含义
一天一共就有五个状态,
- 没有操作 (其实我们也可以不设置这个状态)
- 第一次持有股票
- 第一次不持有股票
- 第二次持有股票
- 第二次不持有股票
dp[i][j]中 i表示第i天,j为 [0 - 4] 五个状态,dp[i][j]表示第i天状态j所剩最大现金。
需要注意:dp[i][1],表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区。
例如 dp[i][1] ,并不是说 第i天一定买入股票,有可能 第 i-1天 就买入了,那么 dp[i][1] 延续买入股票的这个状态。
- 确定递推公式
达到dp[i][1]状态,有两个具体操作:
- 操作一:第i天买入股票了,那么dp[i][1] = dp[i-1][0] - prices[i]
- 操作二:第i天没有操作,而是沿用前一天买入的状态,即:dp[i][1] = dp[i - 1][1]
那么dp[i][1]究竟选 dp[i-1][0] - prices[i],还是dp[i - 1][1]呢?
一定是选最大的,所以 dp[i][1] = max(dp[i-1][0] - prices[i], dp[i - 1][1]);
同理dp[i][2]也有两个操作:
- 操作一:第i天卖出股票了,那么dp[i][2] = dp[i - 1][1] + prices[i]
- 操作二:第i天没有操作,沿用前一天卖出股票的状态,即:dp[i][2] = dp[i - 1][2]
所以dp[i][2] = max(dp[i - 1][1] + prices[i], dp[i - 1][2])
同理可推出剩下状态部分:
dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
- dp数组如何初始化
第0天没有操作,这个最容易想到,就是0,即:dp[0][0] = 0;
第0天做第一次买入的操作,dp[0][1] = -prices[0];
第0天做第一次卖出的操作,这个初始值应该是多少呢?
此时还没有买入,怎么就卖出呢? 其实大家可以理解当天买入,当天卖出,所以dp[0][2] = 0;
第0天第二次买入操作,初始值应该是多少呢?应该不少同学疑惑,第一次还没买入呢,怎么初始化第二次买入呢?
第二次买入依赖于第一次卖出的状态,其实相当于第0天第一次买入了,第一次卖出了,然后再买入一次(第二次买入),那么现在手头上没有现金,只要买入,现金就做相应的减少。
所以第二次买入操作,初始化为:dp[0][3] = -prices[0];
同理第二次卖出初始化dp[0][4] = 0;
- 确定遍历顺序
从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
- 举例推导dp数组
以输入[1,2,3,4,5]为例

大家可以看到红色框为最后两次卖出的状态。
现在最大的时候一定是卖出的状态,而两次卖出的状态现金最大一定是最后一次卖出。如果想不明白的录友也可以这么理解:如果第一次卖出已经是最大值了,那么我们可以在当天立刻买入再立刻卖出。所以dp[4][4]已经包含了dp[4][2]的情况。也就是说第二次卖出手里所剩的钱一定是最多的。
所以最终最大利润是dp[4][4]
方法2 动态规划+滚动数组(改进写法)
首先第一个优化是,第一列的值都为0,因此可以去除
第二个优化是,常规理解的滚动数组,为dp[2][4],但本题还可以进一步优化为一维dp[4]


//上图中划红线部分理解:sell1多考虑的那种情况(buy1相对于buy1'多的部分,也就是第i天第一次买了股票),对应的sell1就是-prices[i]+prices[i](当天买当天卖),总和为0,所以不影响max{}中的结果。后续关于buy2,sell2的推导类同(稍微复杂一些)。具体推导如下:

一维递推公式dp[4]的难点是,理解同一层i中的状态转移,如果较难理解,也可以写成dp[2][4],也就多了4个元素。
方法3 贪心
将股票价格区间,分成第1次和第2次交易两个区域。本题示例1[3,3,5,0,0,3,1,4]如图

贪心策略:最低点买入,最高点卖出,利润最大
第1次交易:初始第0天买入,从第1天顺序遍历,第i天价格比上次买入:
低,重新在当天买入。即 更新最小值
高,假设在当天卖出,利润 存入dp0[i]
遍历结束,第1次交易在第[0, 数组长度 - 1]天结束时的利润dp0
第2次交易:初始最后1天卖出,从倒数第2天倒序遍历,第i天价格比上次卖出:
高,重新在当天卖出。即 更新最大值
低,假设在当天买入,上次(最大值所在那天)卖出,利润 dp1
第2次交易,最早只能在第2天开始,第3天产生利润
2次交易的利润和 = 第i天作为第1次交易结束dp0[i] + 第i天以后进行第2次交易利润dp1
//注意这里dp1[i]代表从0天开始(不一定第0天买入,可以是区间内的任意一天),到第i天卖出的最大收益;dp2[i]代表从第j天开始买入(j>=i),到第prices.size()-1天结束(不一定是最后一天卖出,可以是区间内的任意一天)的最大收益。
//分析一下可能出现的结果
//极端情况1:i=prices.size()-1,第一个区间的局部最优解即全局最优解(且正好最后一天卖出)
//极端情况2:i为中间某个值,且dp2区间的最优解的起始点也为i,相当于在第i天既卖又买,全局最优解恰好是两个局部最优解拼接在一起的结果(合起来是一个完整的区间,只是不一定最终最后一天卖出)
//正常情况3:i为中间某个值,而dp2区间的最优解的起始点不是i,得到两个不相连区间的局部最优解
代码:动态规划/动态规划+一维滚动数组/贪心
28. Leetcode 188 买卖股票的最佳时机IV
难度:⭐️⭐️⭐️⭐️
给定一个整数数组 prices ,它的第 i 个元素 prices[i] 是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
-
示例 1:
-
输入:k = 2, prices = [2,4,1]
-
输出:2 解释:在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2。
-
示例 2:
-
输入:k = 2, prices = [3,2,6,5,0,3]
-
输出:7 解释:在第 2 天 (股票价格 = 2) 的时候买入,在第 3 天 (股票价格 = 6) 的时候卖出, 这笔交易所能获得利润 = 6-2 = 4。随后,在第 5 天 (股票价格 = 0) 的时候买入,在第 6 天 (股票价格 = 3) 的时候卖出, 这笔交易所能获得利润 = 3-0 = 3 。
提示:
- 0 <= k <= 100
- 0 <= prices.length <= 1000
- 0 <= prices[i] <= 1000
这道题目可以说是动态规划:123.买卖股票的最佳时机III (opens new window)的进阶版,这里要求至多有k次交易。
动规五部曲,分析如下:
1.确定dp数组以及下标的含义
在动态规划:123.买卖股票的最佳时机III (opens new window)中,我是定义了一个二维dp数组,本题其实依然可以用一个二维dp数组。
使用二维数组 dp[i][j] :第i天的状态为j,所剩下的最大现金是dp[i][j]
j的状态表示为:
- 0 表示不操作
- 1 第一次买入
- 2 第一次卖出
- 3 第二次买入
- 4 第二次卖出
- .....
大家应该发现规律了吧 ,除了0以外,偶数就是卖出,奇数就是买入。
题目要求是至多有K笔交易,那么j的范围就定义为 2 * k + 1 就可以了。
所以二维dp数组的C++定义为:
vector<vector<int>> dp(prices.size(), vector<int>(2 * k + 1, 0));
2.确定递推公式
还要强调一下:dp[i][1],表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区。
达到dp[i][1]状态,有两个具体操作:
- 操作一:第i天买入股票了,那么dp[i][1] = dp[i - 1][0] - prices[i]
- 操作二:第i天没有操作,而是沿用前一天买入的状态,即:dp[i][1] = dp[i - 1][1]
选最大的,所以 dp[i][1] = max(dp[i - 1][0] - prices[i], dp[i - 1][1]);
同理dp[i][2]也有两个操作:
- 操作一:第i天卖出股票了,那么dp[i][2] = dp[i - 1][1] + prices[i]
- 操作二:第i天没有操作,沿用前一天卖出股票的状态,即:dp[i][2] = dp[i - 1][2]
所以dp[i][2] = max(dp[i - 1][1] + prices[i], dp[i - 1][2])
同理可以类比剩下的状态,代码如下:
for (int j = 0; j < 2 * k - 1; j += 2) {
dp[i][j + 1] = max(dp[i - 1][j + 1], dp[i - 1][j] - prices[i]);
dp[i][j + 2] = max(dp[i - 1][j + 2], dp[i - 1][j + 1] + prices[i]);
}
本题和动态规划:123.买卖股票的最佳时机III (opens new window)最大的区别就是这里要类比j为奇数是买,偶数是卖的状态。
3.dp数组如何初始化
第0天没有操作,这个最容易想到,就是0,即:dp[0][0] = 0;
第0天做第一次买入的操作,dp[0][1] = -prices[0];
第0天做第一次卖出的操作,这个初始值应该是多少呢?
此时还没有买入,怎么就卖出呢? 其实大家可以理解当天买入,当天卖出,所以dp[0][2] = 0;
第0天第二次买入操作,初始值应该是多少呢?应该不少同学疑惑,第一次还没买入呢,怎么初始化第二次买入呢?
第二次买入依赖于第一次卖出的状态,其实相当于第0天第一次买入了,第一次卖出了,然后在买入一次(第二次买入),那么现在手头上没有现金,只要买入,现金就做相应的减少。
所以第二次买入操作,初始化为:dp[0][3] = -prices[0];
第二次卖出初始化dp[0][4] = 0;
所以同理可以推出dp[0][j]当j为奇数的时候都初始化为 -prices[0]
代码如下:
for (int j = 1; j < 2 * k; j += 2) {
dp[0][j] = -prices[0];
}
在初始化的地方同样要类比j为偶数是卖、奇数是买的状态。
4.确定遍历顺序
从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
5.举例推导dp数组
以输入[1,2,3,4,5],k=2为例。
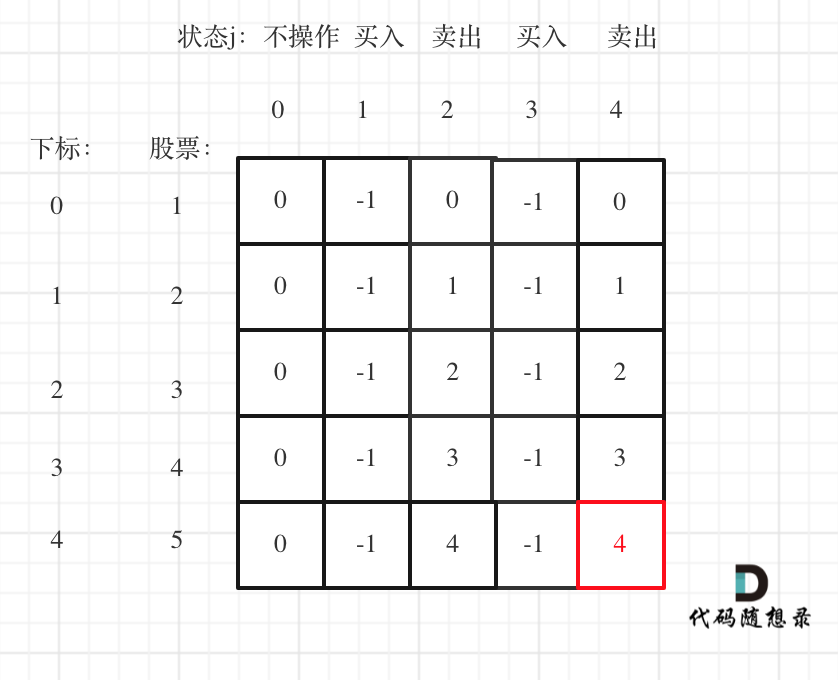
最后一次卖出,一定是利润最大的,dp[prices.size() - 1][2 * k]即红色部分就是最后求解。
以上分析完毕,C++代码如下:
class Solution {
public:
int maxProfit(int k, vector<int>& prices) {
if (prices.size() == 0) return 0;
vector<vector<int>> dp(prices.size(), vector<int>(2 * k + 1, 0));
for (int j = 1; j < 2 * k; j += 2) {
dp[0][j] = -prices[0];
}
for (int i = 1;i < prices.size(); i++) {
for (int j = 0; j < 2 * k - 1; j += 2) {
dp[i][j + 1] = max(dp[i - 1][j + 1], dp[i - 1][j] - prices[i]);
dp[i][j + 2] = max(dp[i - 1][j + 2], dp[i - 1][j + 1] + prices[i]);
}
}
return dp[prices.size() - 1][2 * k];
}
};
- 时间复杂度: O(n * k),其中 n 为 prices 的长度
- 空间复杂度: O(n * k)
当然有的解法是定义一个三维数组dp[i][j][k],第i天,第j次买卖,k表示买还是卖的状态,从定义上来讲是比较直观。
但感觉三维数组操作起来有些麻烦,我是直接用二维数组来模拟三维数组的情况,代码看起来也清爽一些。
另外本题可以用滚动数组,将空间复杂度将为O(k)
代码:动态规划
29. Leetcode 309 最佳买卖股票时机含冷冻期
难度:⭐️⭐️⭐️⭐️
给定一个整数数组,其中第 i 个元素代表了第 i 天的股票价格 。
设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
- 你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
- 卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
示例:
- 输入: [1,2,3,0,2]
- 输出: 3
- 解释: 对应的交易状态为: [买入, 卖出, 冷冻期, 买入, 卖出]
//这道题的关键,就是把前面几题中的“保持卖出”状态拆分为“今天刚卖”“处于冷冻期”“保持卖出”三种状态(由于本题冷冻期=1天,所以后两种状态可以合并,但如果冷冻期有多天,就需要加入多个不同“冷冻期剩余天数”的状态进行过渡)
相对于动态规划:122.买卖股票的最佳时机II (opens new window),本题加上了一个冷冻期
在动态规划:122.买卖股票的最佳时机II (opens new window)中有两个状态,持有股票后的最多现金,和不持有股票的最多现金。
动规五部曲,分析如下:
1.确定dp数组以及下标的含义
dp[i][j],第i天状态为j,所剩的最多现金为dp[i][j]。
其实本题很多同学搞的比较懵,是因为出现冷冻期之后,状态其实是比较复杂度,例如今天买入股票、今天卖出股票、今天是冷冻期,都是不能操作股票的。
具体可以区分出如下四个状态:
- 状态一:持有股票状态(今天买入股票,或者是之前就买入了股票然后没有操作,一直持有)
- 不持有股票状态,这里就有两种卖出股票状态
- 状态二:保持卖出股票的状态(两天前就卖出了股票,度过一天冷冻期。或者是前一天就是卖出股票状态,一直没操作)
- 状态三:今天卖出股票
- 状态四:今天为冷冻期状态,但冷冻期状态不可持续,只有一天!

j的状态为:
- 0:状态一
- 1:状态二
- 2:状态三
- 3:状态四
很多题解为什么讲的比较模糊,是因为把这四个状态合并成三个状态了,其实就是把状态二和状态四合并在一起了。
从代码上来看确实可以合并,但从逻辑上分析合并之后就很难理解了,所以我下面的讲解是按照这四个状态来的,把每一个状态分析清楚。
如果大家按照代码随想录顺序来刷的话,会发现 买卖股票最佳时机 1,2,3,4 的题目讲解中
- 动态规划:121.买卖股票的最佳时机(opens new window)
- 动态规划:122.买卖股票的最佳时机II(opens new window)
- 动态规划:123.买卖股票的最佳时机III(opens new window)
- 动态规划:188.买卖股票的最佳时机IV(opens new window)
「今天卖出股票」我是没有单独列出一个状态的归类为「不持有股票的状态」,而本题为什么要单独列出「今天卖出股票」 一个状态呢?
因为本题我们有冷冻期,而冷冻期的前一天,只能是 「今天卖出股票」状态,如果是 「不持有股票状态」那么就很模糊,因为不一定是 卖出股票的操作。
如果没有按照 代码随想录 顺序去刷的录友,可能看这里的讲解 会有点困惑,建议把代码随想录本篇之前股票内容的讲解都看一下,领会一下每天 状态的设置。
注意这里的每一个状态,例如状态一,是持有股票股票状态并不是说今天一定就买入股票,而是说保持买入股票的状态即:可能是前几天买入的,之后一直没操作,所以保持买入股票的状态。
2.确定递推公式
达到买入股票状态(状态一)即:dp[i][0],有两个具体操作:
- 操作一:前一天就是持有股票状态(状态一),dp[i][0] = dp[i - 1][0]
- 操作二:今天买入了,有两种情况
- 前一天是冷冻期(状态四),dp[i - 1][3] - prices[i]
- 前一天是保持卖出股票的状态(状态二),dp[i - 1][1] - prices[i]
那么dp[i][0] = max(dp[i - 1][0], dp[i - 1][3] - prices[i], dp[i - 1][1] - prices[i]);
达到保持卖出股票状态(状态二)即:dp[i][1],有两个具体操作:
- 操作一:前一天就是状态二
- 操作二:前一天是冷冻期(状态四)
dp[i][1] = max(dp[i - 1][1], dp[i - 1][3]);
达到今天就卖出股票状态(状态三),即:dp[i][2] ,只有一个操作:
昨天一定是持有股票状态(状态一),今天卖出
即:dp[i][2] = dp[i - 1][0] + prices[i];
达到冷冻期状态(状态四),即:dp[i][3],只有一个操作:
昨天卖出了股票(状态三)
dp[i][3] = dp[i - 1][2];
综上分析,递推代码如下:
dp[i][0] = max(dp[i - 1][0], max(dp[i - 1][3], dp[i - 1][1]) - prices[i]);
dp[i][1] = max(dp[i - 1][1], dp[i - 1][3]);
dp[i][2] = dp[i - 1][0] + prices[i];
dp[i][3] = dp[i - 1][2];
3.dp数组如何初始化
这里主要讨论一下第0天如何初始化。
如果是持有股票状态(状态一)那么:dp[0][0] = -prices[0],一定是当天买入股票。
保持卖出股票状态(状态二),这里其实从 「状态二」的定义来说 ,很难明确应该初始多少,这种情况我们就看递推公式需要我们给他初始成什么数值。
如果i为1,第1天买入股票,那么递归公式中需要计算 dp[i - 1][1] - prices[i] ,即 dp[0][1] - prices[1],那么大家感受一下 dp[0][1] (即第0天的状态二)应该初始成多少,只能初始为0。想一想如果初始为其他数值,是我们第1天买入股票后 手里还剩的现金数量是不是就不对了。
今天卖出了股票(状态三),同上分析,dp[0][2]初始化为0,dp[0][3]也初始为0。
4.确定遍历顺序
从递归公式上可以看出,dp[i] 依赖于 dp[i-1],所以是从前向后遍历。
5.举例推导dp数组
以 [1,2,3,0,2] 为例,dp数组如下:

最后结果是取 状态二,状态三,和状态四的最大值,不少同学会把状态四忘了,状态四是冷冻期,最后一天如果是冷冻期也可能是最大值。
代码:动态规划+滚动数组
30. Leetcode 714 买卖股票的最佳时机含手续费
难度:⭐️⭐️⭐️(动态规划)/⭐️⭐️⭐️⭐️⭐️(贪心)
给定一个整数数组 prices,其中第 i 个元素代表了第 i 天的股票价格 ;非负整数 fee 代表了交易股票的手续费用。
你可以无限次地完成交易,但是你每笔交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。
返回获得利润的最大值。
注意:这里的一笔交易指买入持有并卖出股票的整个过程,每笔交易你只需要为支付一次手续费。
示例 1:
- 输入: prices = [1, 3, 2, 8, 4, 9], fee = 2
- 输出: 8
解释: 能够达到的最大利润:
- 在此处买入 prices[0] = 1
- 在此处卖出 prices[3] = 8
- 在此处买入 prices[4] = 4
- 在此处卖出 prices[5] = 9
- 总利润: ((8 - 1) - 2) + ((9 - 4) - 2) = 8.
注意:
- 0 < prices.length <= 50000.
- 0 < prices[i] < 50000.
- 0 <= fee < 50000.
方法1 动态规划
题使用贪心算法并不好理解,也很容易出错,那么我们再来看看是使用动规的方法如何解题。
相对于动态规划:122.买卖股票的最佳时机II (opens new window),本题只需要在计算卖出操作的时候减去手续费就可以了,代码几乎是一样的。
唯一差别在于递推公式部分,所以本篇也就不按照动规五部曲详细讲解了,主要讲解一下递推公式部分。
这里重申一下dp数组的含义:
dp[i][0] 表示第i天持有股票所省最多现金。 dp[i][1] 表示第i天不持有股票所得最多现金
如果第i天持有股票即dp[i][0], 那么可以由两个状态推出来
- 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:dp[i - 1][0]
- 第i天买入股票,所得现金就是昨天不持有股票的所得现金减去 今天的股票价格 即:dp[i - 1][1] - prices[i]
所以:dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
在来看看如果第i天不持有股票即dp[i][1]的情况, 依然可以由两个状态推出来
- 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:dp[i - 1][1]
- 第i天卖出股票,所得现金就是按照今天股票价格卖出后所得现金,注意这里需要有手续费了即:dp[i - 1][0] + prices[i] - fee
所以:dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i] - fee);
本题和动态规划:122.买卖股票的最佳时机II (opens new window)的区别就是这里需要多一个减去手续费的操作。
方法2 贪心
在贪心算法:122.买卖股票的最佳时机II (opens new window)中使用贪心策略不用关心具体什么时候买卖,只要收集每天的正利润,最后稳稳的就是最大利润了。
而本题有了手续费,就要关系什么时候买卖了,因为计算所获得利润,需要考虑买卖利润可能不足以手续费的情况。
如果使用贪心策略,就是最低值买,最高值(如果算上手续费还盈利)就卖。
此时无非就是要找到两个点,买入日期,和卖出日期。
- 买入日期:其实很好想,遇到更低点就记录一下。
- 卖出日期:这个就不好算了,但也没有必要算出准确的卖出日期,只要当前价格大于(最低价格+手续费),就可以收获利润,至于准确的卖出日期,就是连续收获利润区间里的最后一天(并不需要计算是具体哪一天)。
所以我们在做收获利润操作的时候其实有三种情况:
- 情况一:收获利润的这一天并不是收获利润区间里的最后一天(不是真正的卖出,相当于持有股票),所以后面要继续收获利润。
- 情况二:前一天是收获利润区间里的最后一天(相当于真正的卖出了),今天要重新记录最小价格了。
- 情况三:不作操作,保持原有状态(买入,卖出,不买不卖)
贪心算法C++代码如下:
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
int result = 0;
int minPrice = prices[0]; // 记录最低价格
for (int i = 1; i < prices.size(); i++) {
// 情况二:相当于买入
if (prices[i] < minPrice) minPrice = prices[i];
// 情况三:保持原有状态(因为此时买则不便宜,卖则亏本)
if (prices[i] >= minPrice && prices[i] <= minPrice + fee) {
continue;
}
// 计算利润,可能有多次计算利润,最后一次计算利润才是真正意义的卖出
if (prices[i] > minPrice + fee) {
result += prices[i] - minPrice - fee;
minPrice = prices[i] - fee; // 情况一,这一步很关键,避免重复扣手续费
}
}
return result;
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1)
从代码中可以看出对情况一的操作,因为如果还在收获利润的区间里,表示并不是真正的卖出,而计算利润每次都要减去手续费,所以要让minPrice = prices[i] - fee;,这样在明天收获利润的时候,才不会多减一次手续费!
大家也可以发现,情况三,那块代码是可以删掉的,我是为了让代码表达清晰,所以没有精简。

//贪心算法的难点,是理解:为什么累计result后,要把min_price=prices[i]-fee(a.后续prices[i+1]继续涨时继续累计resut,并实时更新min_price;b,后续prices[i+1]跌,但没低于min_price,无需更新min_price,这时仍看做是第一笔买卖,只是出现了一点小波动,但最合适的收益我们已经记录了;c.直到prices[i+1]跌过新的最低点,min_price=prices[i+1],这时相当于开启了第二次买卖,并记录了最低入手点)新一轮买卖之后的分析类同。
//贪心算法每行代码的本质,我写在下面链接中的代码的注释里了

//力扣官解用了另一个角度去理解这个问题(买入时扣手续费),解释其实大同小异,其实看完我的解释能理解就足够了。
股票问题总结
动态规划:121.买卖股票的最佳时机 (opens new window),股票只能买卖一次,问最大利润。
【贪心解法】
取最左最小值,取最右最大值,那么得到的差值就是最大利润
【动态规划】
- dp[i][0] 表示第i天持有股票所得现金。
- dp[i][1] 表示第i天不持有股票所得现金。
如果第i天持有股票即dp[i][0], 那么可以由两个状态推出来
- 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:dp[i - 1][0]
- 第i天买入股票,所得现金就是买入今天的股票后所得现金即:-prices[i] 所以dp[i][0] = max(dp[i - 1][0], -prices[i]);
如果第i天不持有股票即dp[i][1], 也可以由两个状态推出来
- 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:dp[i - 1][1]
- 第i天卖出股票,所得现金就是按照今天股票佳价格卖出后所得现金即:prices[i] + dp[i - 1][0] 所以dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);
动态规划:122.买卖股票的最佳时机II (opens new window)可以多次买卖股票,问最大收益。
【贪心解法】
收集每天的正利润便可
【动态规划】
注意这里和121. 买卖股票的最佳时机 (opens new window)唯一不同的地方,就是推导dp[i][0]的时候,第i天买入股票的情况。
在121. 买卖股票的最佳时机 (opens new window)中,因为股票全程只能买卖一次,所以如果买入股票,那么第i天持有股票即dp[i][0]一定就是 -prices[i]。
而本题,因为一只股票可以买卖多次,所以当第i天买入股票的时候,所持有的现金可能有之前买卖过的利润。
动态规划:123.买卖股票的最佳时机III (opens new window)最多买卖两次,问最大收益。
【贪心】
先从左到右遍历一遍,用dp1[j]记录区间[0,j](第j天必须卖出)的最大收益;
再从右到左遍历一遍,用dp2[i]记录区间[i,prices.size()-1]的最大收益(注意不要求第i天必须买入)
注意第一次遍历范围j:1~prices.size()-1,第二次遍历范围i: prices.size()-2~1,第二轮没遍历到0,是为了给第一个区间留至少一个元素,保证第一个区间的有效性,也是为了符合之后累加的定义。
最后,从1~prices.size()-1遍历一遍,求出max(dp1[i]+dp2[i]))
分析一下可能出现的结果
//极端情况1:i=prices.size()-1,第一个区间的局部最优解即全局最优解(且正好最后一天卖出)
//极端情况2:i为中间某个值,且dp2区间的最优解的起始点也为i,相当于在第i天既卖又买,全局最优解恰好是两个局部最优解拼接在一起的结果(合起来是一个完整的区间,只是不一定最终最后一天卖出)
//正常情况3:i为中间某个值,而dp2区间的最优解的起始点不是i,得到两个不相连区间的局部最优解
【动态规划】
一天一共就有五个状态,
- 没有操作
- 第一次买入
- 第一次卖出
- 第二次买入
- 第二次卖出
dp[i][j]中 i表示第i天,j为 [0 - 4] 五个状态,dp[i][j]表示第i天状态j所剩最大现金。
达到dp[i][1]状态,有两个具体操作:
- 操作一:第i天买入股票了,那么dp[i][1] = dp[i-1][0] - prices[i]
- 操作二:第i天没有操作,而是沿用前一天买入的状态,即:dp[i][1] = dp[i - 1][1]
dp[i][1] = max(dp[i-1][0] - prices[i], dp[i - 1][1]);
同理dp[i][2]也有两个操作:
- 操作一:第i天卖出股票了,那么dp[i][2] = dp[i - 1][1] + prices[i]
- 操作二:第i天没有操作,沿用前一天卖出股票的状态,即:dp[i][2] = dp[i - 1][2]
所以dp[i][2] = max(dp[i - 1][1] + prices[i], dp[i - 1][2])
同理可推出剩下状态部分:
dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
动态规划:188.买卖股票的最佳时机IV (opens new window)最多买卖k笔交易,问最大收益。
使用二维数组 dp[i][j] :第i天的状态为j,所剩下的最大现金是dp[i][j]
j的状态表示为:
- 0 表示不操作
- 1 第一次买入
- 2 第一次卖出
- 3 第二次买入
- 4 第二次卖出
- .....
除了0以外,偶数就是卖出,奇数就是买入。
动态规划:309.最佳买卖股票时机含冷冻期 (opens new window)可以多次买卖但每次卖出有冷冻期1天。
相对于动态规划:122.买卖股票的最佳时机II (opens new window),本题加上了一个冷冻期。
在动态规划:122.买卖股票的最佳时机II (opens new window)中有两个状态,持有股票后的最多现金,和不持有股票的最多现金。本题则可以花费为四个状态
dp[i][j]:第i天状态为j,所剩的最多现金为dp[i][j]。
具体可以区分出如下四个状态:
- 状态一:买入股票状态(今天买入股票,或者是之前就买入了股票然后没有操作)
- 卖出股票状态,这里就有两种卖出股票状态
- 状态二:两天前就卖出了股票,度过了冷冻期,一直没操作,今天保持卖出股票状态
- 状态三:今天卖出了股票
- 状态四:今天为冷冻期状态,但冷冻期状态不可持续,只有一天!
动态规划:714.买卖股票的最佳时机含手续费 (opens new window)可以多次买卖,但每次有手续费。
【贪心】
本题贪心比较难想,主要需要:比较prices[i]与min_price的值,如果prices[i]<min_price,更新min_price(开启新的buy-sell轮次);如果prices[i]>min_price+fee,累计earning并更新min_price的值为prices[i]-fee
【动态规划】
相对于动态规划:122.买卖股票的最佳时机II (opens new window),本题只需要在计算卖出操作的时候减去手续费就可以了,代码几乎是一样的。
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i] - fee);

31. Leetcode 300 最长递增子序列
难度:⭐️⭐️
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
示例 1:
- 输入:nums = [10,9,2,5,3,7,101,18]
- 输出:4
- 解释:最长递增子序列是 [2,3,7,101],因此长度为 4 。
示例 2:
- 输入:nums = [0,1,0,3,2,3]
- 输出:4
示例 3:
- 输入:nums = [7,7,7,7,7,7,7]
- 输出:1
提示:
- 1 <= nums.length <= 2500
- -10^4 <= nums[i] <= 104
方法1 动态规划
首先通过本题大家要明确什么是子序列,“子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序”。
本题也是代码随想录中子序列问题的第一题,如果没接触过这种题目的话,本题还是很难的,甚至想暴力去搜索也不知道怎么搜。 子序列问题是动态规划解决的经典问题,当前下标i的递增子序列长度,其实和i之前的下表j的子序列长度有关系,那又是什么样的关系呢。
接下来,我们依然用动规五部曲来详细分析一波:
1.dp[i]的定义
本题中,正确定义dp数组的含义十分重要。
dp[i]表示i之前包括i的以nums[i]结尾的最长递增子序列的长度
为什么一定表示 “以nums[i]结尾的最长递增子序” ,因为我们在 做 递增比较的时候,如果比较 nums[j] 和 nums[i] 的大小,那么两个递增子序列一定分别以nums[j]为结尾 和 nums[i]为结尾, 要不然这个比较就没有意义了,不是尾部元素的比较那么 如何算递增呢。
2.状态转移方程
位置i的最长升序子序列等于j从0到i-1各个位置的最长升序子序列 + 1 的最大值。
所以:if (nums[i] > nums[j]) dp[i] = max(dp[i], dp[j] + 1);
注意这里不是要dp[i] 与 dp[j] + 1进行比较,而是我们要取dp[j] + 1的最大值。
3.dp[i]的初始化
每一个i,对应的dp[i](即最长递增子序列)起始大小至少都是1.
4.确定遍历顺序
dp[i] 是有0到i-1各个位置的最长递增子序列 推导而来,那么遍历i一定是从前向后遍历。
j其实就是遍历0到i-1,那么是从前到后,还是从后到前遍历都无所谓,只要吧 0 到 i-1 的元素都遍历了就行了。 所以默认习惯 从前向后遍历。
遍历i的循环在外层,遍历j则在内层,代码如下:
for (int i = 1; i < nums.size(); i++) {
for (int j = 0; j < i; j++) {
if (nums[i] > nums[j]) dp[i] = max(dp[i], dp[j] + 1);
}
if (dp[i] > result) result = dp[i]; // 取长的子序列
}
5.举例推导dp数组
输入:[0,1,0,3,2],dp数组的变化如下:
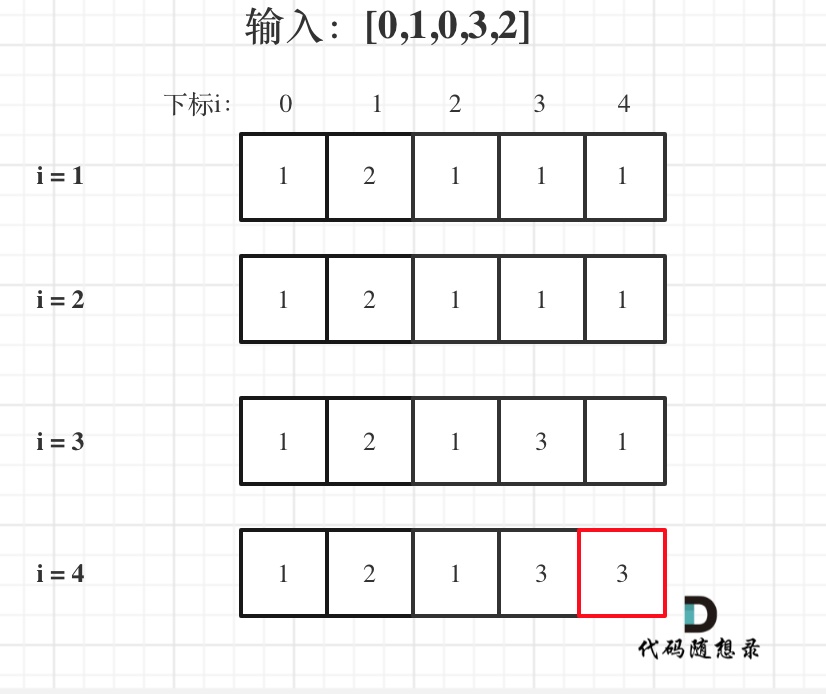
如果代码写出来,但一直AC不了,那么就把dp数组打印出来,看看对不对!
方法2 贪心+二分查找


32. Leetcode 674 最长连续递增子序列
难度:⭐️
给定一个未经排序的整数数组,找到最长且 连续递增的子序列,并返回该序列的长度。
连续递增的子序列 可以由两个下标 l 和 r(l < r)确定,如果对于每个 l <= i < r,都有 nums[i] < nums[i + 1] ,那么子序列 [nums[l], nums[l + 1], ..., nums[r - 1], nums[r]] 就是连续递增子序列。
示例 1:
- 输入:nums = [1,3,5,4,7]
- 输出:3
- 解释:最长连续递增序列是 [1,3,5], 长度为3。尽管 [1,3,5,7] 也是升序的子序列, 但它不是连续的,因为 5 和 7 在原数组里被 4 隔开。
示例 2:
- 输入:nums = [2,2,2,2,2]
- 输出:1
- 解释:最长连续递增序列是 [2], 长度为1。
提示:
- 0 <= nums.length <= 10^4
- -10^9 <= nums[i] <= 10^9
方法1 动态规划
1.确定dp数组(dp table)以及下标的含义
dp[i]:以下标i为结尾的连续递增的子序列长度为dp[i]。
注意这里的定义,一定是以下标i为结尾,并不是说一定以下标0为起始位置。
2.确定递推公式
如果 nums[i] > nums[i - 1],那么以 i 为结尾的连续递增的子序列长度 一定等于 以i - 1为结尾的连续递增的子序列长度 + 1 。
即:dp[i] = dp[i - 1] + 1;
注意这里就体现出和动态规划:300.最长递增子序列 (opens new window)的区别!
因为本题要求连续递增子序列,所以就只要比较nums[i]与nums[i - 1],而不用去比较nums[j]与nums[i] (j是在0到i之间遍历)。
既然不用j了,那么也不用两层for循环,本题一层for循环就行,比较nums[i] 和 nums[i - 1]。
这里大家要好好体会一下!
方法2 贪心
这道题目也可以用贪心来做,也就是遇到nums[i] > nums[i - 1]的情况,count就++,否则count为1,记录count的最大值就可以了。
33. Leetcode 718 最长重复子数组
难度:⭐️⭐️(动态规划)/⭐️⭐️⭐️⭐️(滑动窗口)
给两个整数数组 A 和 B ,返回两个数组中公共的、长度最长的子数组的长度。
示例:
输入:
- A: [1,2,3,2,1]
- B: [3,2,1,4,7]
- 输出:3
- 解释:长度最长的公共子数组是 [3, 2, 1] 。
提示:
- 1 <= len(A), len(B) <= 1000
- 0 <= A[i], B[i] < 100
方法1 动态规划
注意题目中说的子数组,其实就是连续子序列。
要求两个数组中最长重复子数组,如果是暴力的解法 只需要先两层for循环确定两个数组起始位置,然后再来一个循环可以是for或者while,来从两个起始位置开始比较,取得重复子数组的长度。
本题其实是动规解决的经典题目,我们只要想到 用二维数组可以记录两个字符串的所有比较情况,这样就比较好推 递推公式了。 动规五部曲分析如下:
1.确定dp数组(dp table)以及下标的含义
dp[i][j] :以下标i - 1为结尾的A,和以下标j - 1为结尾的B,最长重复子数组长度为dp[i][j]。 (特别注意: “以下标i - 1为结尾的A” 标明一定是 以A[i-1]为结尾的字符串 )
此时细心的同学应该发现,那dp[0][0]是什么含义呢?总不能是以下标-1为结尾的A数组吧。
其实dp[i][j]的定义也就决定着,我们在遍历dp[i][j]的时候i 和 j都要从1开始。
那有同学问了,我就定义dp[i][j]为 以下标i为结尾的A,和以下标j 为结尾的B,最长重复子数组长度。不行么?
行倒是行! 但实现起来就麻烦一点,需要单独处理初始化部分,在本题解下面的拓展内容里,我给出了 第二种 dp数组的定义方式所对应的代码和讲解,大家比较一下就了解了。
2.确定递推公式
根据dp[i][j]的定义,dp[i][j]的状态只能由dp[i - 1][j - 1]推导出来。
即当A[i - 1] 和B[j - 1]相等的时候,dp[i][j] = dp[i - 1][j - 1] + 1;
根据递推公式可以看出,遍历i 和 j 要从1开始!
3.dp数组如何初始化
根据dp[i][j]的定义,dp[i][0] 和dp[0][j]其实都是没有意义的!
但dp[i][0] 和dp[0][j]要初始值,因为 为了方便递归公式dp[i][j] = dp[i - 1][j - 1] + 1;
所以dp[i][0] 和dp[0][j]初始化为0。
举个例子A[0]如果和B[0]相同的话,dp[1][1] = dp[0][0] + 1,只有dp[0][0]初始为0,正好符合递推公式逐步累加起来。
4.确定遍历顺序
外层for循环遍历A,内层for循环遍历B。
那又有同学问了,外层for循环遍历B,内层for循环遍历A。不行么?
也行,一样的,我这里就用外层for循环遍历A,内层for循环遍历B了。
同时题目要求长度最长的子数组的长度。所以在遍历的时候顺便把dp[i][j]的最大值记录下来。
5.举例推导dp数组
拿示例1中,A: [1,2,3,2,1],B: [3,2,1,4,7]为例,画一个dp数组的状态变化,如下:

扩展
前面讲了 dp数组为什么定义:以下标i - 1为结尾的A,和以下标j - 1为结尾的B,最长重复子数组长度为dp[i][j]。
我就定义dp[i][j]为 以下标i为结尾的A,和以下标j 为结尾的B,最长重复子数组长度。不行么?
当然可以,就是实现起来麻烦一些。
如果定义 dp[i][j]为 以下标i为结尾的A,和以下标j 为结尾的B,那么 第一行和第一列毕竟要进行初始化,如果nums1[i] 与 nums2[0] 相同的话,对应的 dp[i][0]就要初始为1, 因为此时最长重复子数组为1。 nums2[j] 与 nums1[0]相同的话,同理。
方法2 滑动窗口
//一句话概括一下,就是先用nums2沿着nums1的每个起点i开始滑,然后nums1沿着nums2的每个起点j滑,最后比较每次窗口的最大值。


代码:动态规划/动态规划+滚动数组/动态规划+手动初始化/滑动窗口/二分查找+哈希
34. Leetcode 1143 最长公共子序列
难度:⭐️⭐️⭐️
给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列的长度。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。两个字符串的「公共子序列」是这两个字符串所共同拥有的子序列。
若这两个字符串没有公共子序列,则返回 0。
示例 1:
- 输入:text1 = "abcde", text2 = "ace"
- 输出:3
- 解释:最长公共子序列是 "ace",它的长度为 3。
示例 2:
- 输入:text1 = "abc", text2 = "abc"
- 输出:3
- 解释:最长公共子序列是 "abc",它的长度为 3。
示例 3:
- 输入:text1 = "abc", text2 = "def"
- 输出:0
- 解释:两个字符串没有公共子序列,返回 0。
提示:
- 1 <= text1.length <= 1000
- 1 <= text2.length <= 1000 输入的字符串只含有小写英文字符。
本题和动态规划:718. 最长重复子数组 (opens new window)区别在于这里不要求是连续的了,但要有相对顺序,即:"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。
继续动规五部曲分析如下:
1.确定dp数组(dp table)以及下标的含义
dp[i][j]:长度为[0, i - 1]的字符串text1与长度为[0, j - 1]的字符串text2的最长公共子序列为dp[i][j]
有同学会问:为什么要定义长度为[0, i - 1]的字符串text1,定义为长度为[0, i]的字符串text1不香么?
这样定义是为了后面代码实现方便,如果非要定义为长度为[0, i]的字符串text1也可以,我在 动态规划:718. 最长重复子数组 (opens new window)中的「拓展」里 详细讲解了区别所在,其实就是简化了dp数组第一行和第一列的初始化逻辑。
2.确定递推公式
主要就是两大情况: text1[i - 1] 与 text2[j - 1]相同,text1[i - 1] 与 text2[j - 1]不相同
如果text1[i - 1] 与 text2[j - 1]相同,那么找到了一个公共元素,所以dp[i][j] = dp[i - 1][j - 1] + 1;
如果text1[i - 1] 与 text2[j - 1]不相同,那就看看text1[0, i - 2]与text2[0, j - 1]的最长公共子序列 和 text1[0, i - 1]与text2[0, j - 2]的最长公共子序列,取最大的。
即:dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
35. Leetcdoe 1035 不相交的线
难度:⭐️⭐️⭐️
我们在两条独立的水平线上按给定的顺序写下 A 和 B 中的整数。
现在,我们可以绘制一些连接两个数字 A[i] 和 B[j] 的直线,只要 A[i] == B[j],且我们绘制的直线不与任何其他连线(非水平线)相交。
以这种方法绘制线条,并返回我们可以绘制的最大连线数。

相信不少录友看到这道题目都没啥思路,我们来逐步分析一下。
绘制一些连接两个数字 A[i] 和 B[j] 的直线,只要 A[i] == B[j],且直线不能相交!
直线不能相交,这就是说明在字符串A中 找到一个与字符串B相同的子序列,且这个子序列不能改变相对顺序,只要相对顺序不改变,链接相同数字的直线就不会相交。
拿示例一A = [1,4,2], B = [1,2,4]为例,相交情况如图:

其实也就是说A和B的最长公共子序列是[1,4],长度为2。 这个公共子序列指的是相对顺序不变(即数字4在字符串A中数字1的后面,那么数字4也应该在字符串B数字1的后面)
这么分析完之后,大家可以发现:本题说是求绘制的最大连线数,其实就是求两个字符串的最长公共子序列的长度!
那么本题就和我们刚刚讲过的这道题目动态规划:1143.最长公共子序列 (opens new window)就是一样一样的了。
代码:动态规划+滚动数组
36. Leetcode 53 最大字序和
难度:⭐️⭐️(动态规划,贪心)/⭐️⭐️⭐️⭐️(分治+线段树)
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
- 输入: [-2,1,-3,4,-1,2,1,-5,4]
- 输出: 6
- 解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
方法1 动态规划
这次我们用动态规划的思路再来分析一次。
动规五部曲如下:
1.确定dp数组(dp table)以及下标的含义
dp[i]:包括下标i(以nums[i]为结尾)的最大连续子序列和为dp[i]。
2.确定递推公式
dp[i]只有两个方向可以推出来:
- dp[i - 1] + nums[i],即:nums[i]加入当前连续子序列和
- nums[i],即:从头开始计算当前连续子序列和
一定是取最大的,所以dp[i] = max(dp[i - 1] + nums[i], nums[i]);
3.dp数组如何初始化
从递推公式可以看出来dp[i]是依赖于dp[i - 1]的状态,dp[0]就是递推公式的基础。
dp[0]应该是多少呢?
根据dp[i]的定义,很明显dp[0]应为nums[0]即dp[0] = nums[0]。
4.确定遍历顺序
递推公式中dp[i]依赖于dp[i - 1]的状态,需要从前向后遍历。
5.举例推导dp数组
以示例一为例,输入:nums = [-2,1,-3,4,-1,2,1,-5,4],对应的dp状态如下:
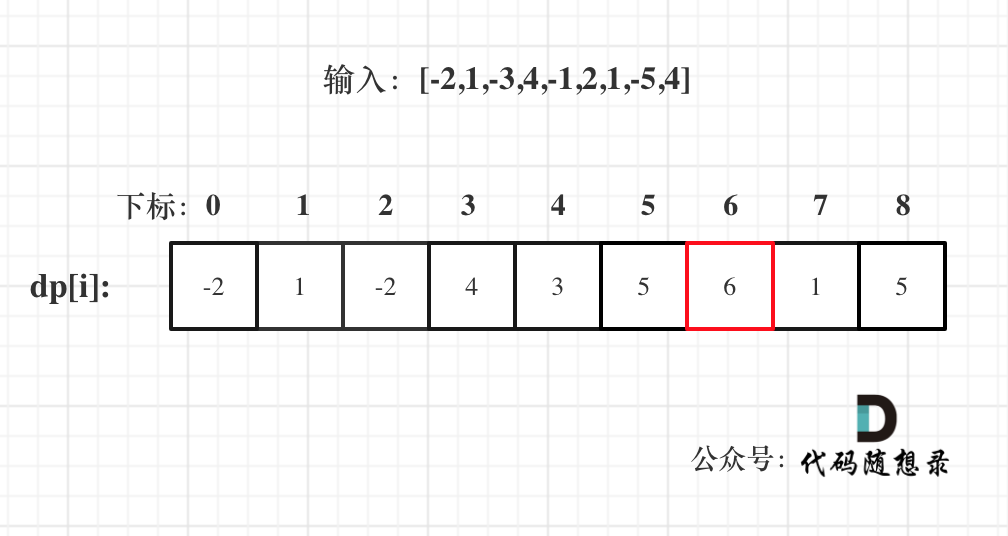
注意最后的结果可不是dp[nums.size() - 1]! ,而是dp[6]。
在回顾一下dp[i]的定义:包括下标i之前的最大连续子序列和为dp[i]。
那么我们要找最大的连续子序列,就应该找每一个i为终点的连续最大子序列。
所以在递推公式的时候,可以直接选出最大的dp[i]。
方法2 贪心
如果 -2 1 在一起,计算起点的时候,一定是从 1 开始计算,因为负数只会拉低总和,这就是贪心贪的地方!
局部最优:当前“连续和”为负数的时候立刻放弃,从下一个元素重新计算“连续和”,因为负数加上下一个元素 “连续和”只会越来越小。
全局最优:选取最大“连续和”
局部最优的情况下,并记录最大的“连续和”,可以推出全局最优。
从代码角度上来讲:遍历 nums,从头开始用 count 累积,如果 count 一旦加上 nums[i]变为负数,那么就应该从 nums[i+1]开始从 0 累积 count 了,因为已经变为负数的 count,只会拖累总和。
这相当于是暴力解法中的不断调整最大子序和区间的起始位置。
那有同学问了,区间终止位置不用调整么? 如何才能得到最大“连续和”呢?
区间的终止位置,其实就是如果 count 取到最大值了,及时记录下来了。例如如下代码:
if (count > result) result = count;
这样相当于是用 result 记录最大子序和区间和(变相的算是调整了终止位置)。
如动画所示:
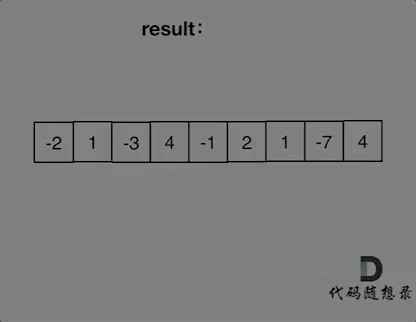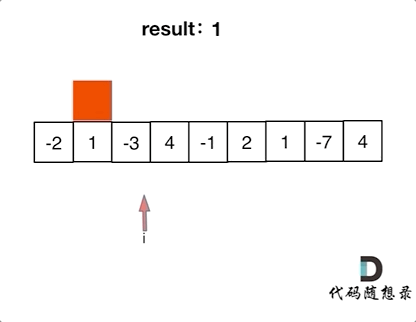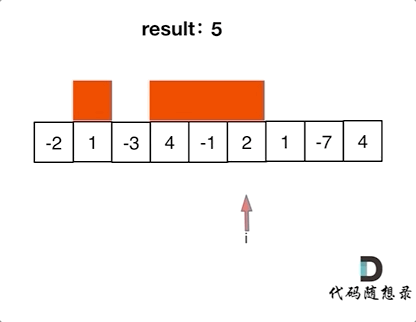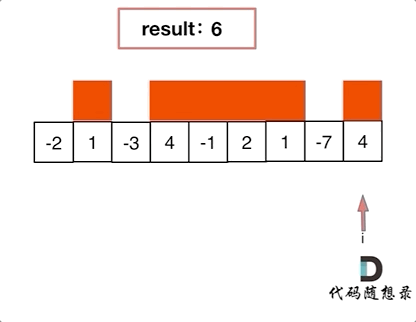
红色的起始位置就是贪心每次取 count 为正数的时候,开始一个区间的统计。
方法3 分治+线段树


37. Leetcode 392 判断子序列
难度:⭐️⭐️(双指针)/⭐️⭐️⭐️(动态规划)/⭐️⭐️⭐️⭐️(编辑距离)
方法1 双指针

方法2 动态规划
这道题应该算是编辑距离的入门题目,因为从题意中我们也可以发现,只需要计算删除的情况,不用考虑增加和替换的情况。
所以掌握本题的动态规划解法是对后面要讲解的编辑距离的题目打下基础。
动态规划五部曲分析如下:
1.确定dp数组(dp table)以及下标的含义
dp[i][j] 表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]。
注意这里是判断s是否为t的子序列。即t的长度是大于等于s的。
有同学问了,为啥要表示下标i-1为结尾的字符串呢,为啥不表示下标i为结尾的字符串呢?
为什么这么定义我在 718. 最长重复子数组 (opens new window)中做了详细的讲解。
其实用i来表示也可以!
但我统一以下标i-1为结尾的字符串来计算,这样在下面的递归公式中会容易理解一些,如果还有疑惑,可以继续往下看。
2.确定递推公式
在确定递推公式的时候,首先要考虑如下两种操作,整理如下:
- if (s[i - 1] == t[j - 1])
- t中找到了一个字符在s中也出现了
- if (s[i - 1] != t[j - 1])
- 相当于t要删除元素,继续匹配
if (s[i - 1] == t[j - 1]),那么dp[i][j] = dp[i - 1][j - 1] + 1;,因为找到了一个相同的字符,相同子序列长度自然要在dp[i-1][j-1]的基础上加1(如果不理解,在回看一下dp[i][j]的定义)
if (s[i - 1] != t[j - 1]),此时相当于t要删除元素,t如果把当前元素t[j - 1]删除,那么dp[i][j] 的数值就是 看s[i - 1]与 t[j - 2]的比较结果了,即:dp[i][j] = dp[i][j - 1];
其实这里 大家可以发现和 1143.最长公共子序列 (opens new window)的递推公式基本那就是一样的,区别就是 本题 如果删元素一定是字符串t,而 1143.最长公共子序列 是两个字符串都可以删元素。
3.dp数组如何初始化
从递推公式可以看出dp[i][j]都是依赖于dp[i - 1][j - 1] 和 dp[i][j - 1],所以dp[0][0]和dp[i][0]是一定要初始化的。
这里大家已经可以发现,在定义dp[i][j]含义的时候为什么要表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]。
因为这样的定义在dp二维矩阵中可以留出初始化的区间,如图:

如果要是定义的dp[i][j]是以下标i为结尾的字符串s和以下标j为结尾的字符串t,初始化就比较麻烦了。
dp[i][0] 表示以下标i-1为结尾的字符串,与空字符串的相同子序列长度,所以为0. dp[0][j]同理。
vector<vector<int>> dp(s.size() + 1, vector<int>(t.size() + 1, 0));
4.确定遍历顺序
同理从递推公式可以看出dp[i][j]都是依赖于dp[i - 1][j - 1] 和 dp[i][j - 1],那么遍历顺序也应该是从上到下,从左到右
如图所示:
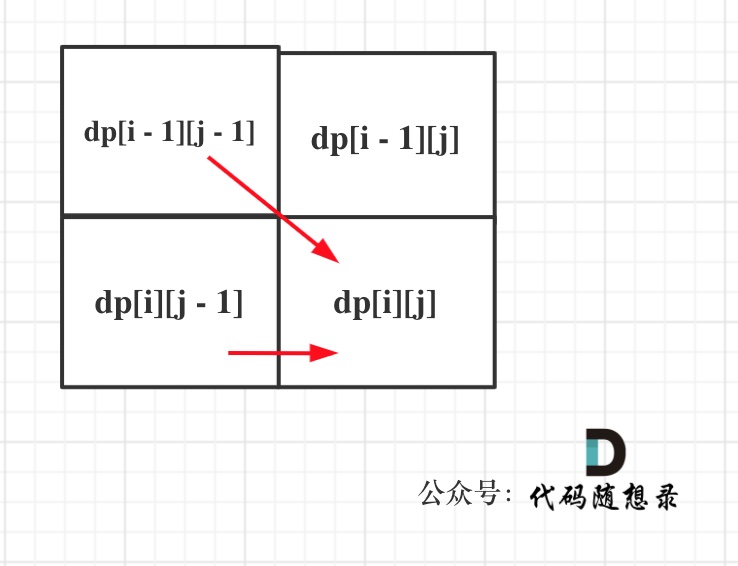
5.举例推导dp数组
以示例一为例,输入:s = "abc", t = "ahbgdc",dp状态转移图如下:

dp[i][j]表示以下标i-1为结尾的字符串s和以下标j-1为结尾的字符串t 相同子序列的长度,所以如果dp[s.size()][t.size()] 与 字符串s的长度相同说明:s与t的最长相同子序列就是s,那么s 就是 t 的子序列。
图中dp[s.size()][t.size()] = 3, 而s.size() 也为3。所以s是t 的子序列,返回true。
方法3 动态规划+记忆化搜索

代码:双指针/动态规划/动态规划+滚动数组/动态规划+记忆化搜索
38. Leetcde 115 不同的子序列
难度:⭐️⭐️⭐️
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
题目数据保证答案符合 32 位带符号整数范围。

提示:
- 0 <= s.length, t.length <= 1000
- s 和 t 由英文字母组成
这道题目如果不是子序列,而是要求连续序列的,那就可以考虑用KMP。
这道题目相对于72. 编辑距离,简单了不少,因为本题相当于只有删除操作,不用考虑替换增加之类的。
但相对于刚讲过的动态规划:392.判断子序列 (opens new window)就有难度了,这道题目双指针法可就做不了了,来看看动规五部曲分析如下:
1.确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的s子序列中出现以j-1为结尾的t的个数为dp[i][j]。
为什么i-1,j-1 这么定义我在 718. 最长重复子数组 (opens new window)中做了详细的讲解。
2.确定递推公式
这一类问题,基本是要分析两种情况
- s[i - 1] 与 t[j - 1]相等
- s[i - 1] 与 t[j - 1] 不相等
当s[i - 1] 与 t[j - 1]相等时,dp[i][j]可以有两部分组成。
一部分是用s[i - 1]来匹配,那么个数为dp[i - 1][j - 1]。即不需要考虑当前s子串和t子串的最后一位字母,所以只需要 dp[i-1][j-1]。
一部分是不用s[i - 1]来匹配,个数为dp[i - 1][j]。
这里可能有录友不明白了,为什么还要考虑 不用s[i - 1]来匹配,都相同了指定要匹配啊。
例如: s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。
当然也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。
所以当s[i - 1] 与 t[j - 1]相等时,dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
当s[i - 1] 与 t[j - 1]不相等时,dp[i][j]只有一部分组成,不用s[i - 1]来匹配(就是模拟在s中删除这个元素),即:dp[i - 1][j]
所以递推公式为:dp[i][j] = dp[i - 1][j];
这里可能有录友还疑惑,为什么只考虑 “不用s[i - 1]来匹配” 这种情况, 不考虑 “不用t[j - 1]来匹配” 的情况呢。
这里大家要明确,我们求的是 s 中有多少个 t,而不是 求t中有多少个s,所以只考虑 s中删除元素的情况,即 不用s[i - 1]来匹配 的情况。
3.dp数组如何初始化
从递推公式dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j] 是从上方和左上方推导而来,如图:,那么 dp[i][0] 和dp[0][j]是一定要初始化的。

每次当初始化的时候,都要回顾一下dp[i][j]的定义,不要凭感觉初始化。
dp[i][0]表示什么呢?
dp[i][0] 表示:以i-1为结尾的s可以随便删除元素,出现空字符串的个数。
那么dp[i][0]一定都是1,因为也就是把以i-1为结尾的s,删除所有元素,出现空字符串的个数就是1。
再来看dp[0][j],dp[0][j]:空字符串s可以随便删除元素,出现以j-1为结尾的字符串t的个数。
那么dp[0][j]一定都是0,s如论如何也变成不了t。
最后就要看一个特殊位置了,即:dp[0][0] 应该是多少。
dp[0][0]应该是1,空字符串s,可以删除0个元素,变成空字符串t。
初始化分析完毕,代码如下:
vector<vector<long long>> dp(s.size() + 1, vector<long long>(t.size() + 1));
for (int i = 0; i <= s.size(); i++) dp[i][0] = 1;
for (int j = 1; j <= t.size(); j++) dp[0][j] = 0; // 其实这行代码可以和dp数组初始化的时候放在一起,但我为了凸显初始化的逻辑,所以还是加上了。
4.确定遍历顺序
从递推公式dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j]都是根据左上方和正上方推出来的。

所以遍历的时候一定是从上到下,从左到右,这样保证dp[i][j]可以根据之前计算出来的数值进行计算。
代码如下:
for (int i = 1; i <= s.size(); i++) {
for (int j = 1; j <= t.size(); j++) {
if (s[i - 1] == t[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
} else {
dp[i][j] = dp[i - 1][j];
}
}
}
5.举例推导dp数组
以s:"baegg",t:"bag"为例,推导dp数组状态如下:

如果写出来的代码怎么改都通过不了,不妨把dp数组打印出来,看一看,是不是这样的。
39. Leetcode 583 两个字符串的删除操作
难度:⭐️⭐️⭐️
给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最小步数,每步可以删除任意一个字符串中的一个字符。
示例:
- 输入: "sea", "eat"
- 输出: 2
- 解释: 第一步将"sea"变为"ea",第二步将"eat"变为"ea"
方法1 动态规划(删元素)
本题和动态规划:115.不同的子序列 (opens new window)相比,其实就是两个字符串都可以删除了,情况虽说复杂一些,但整体思路是不变的。
这次是两个字符串可以相互删了,这种题目也知道用动态规划的思路来解,动规五部曲,分析如下:
1.确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。
这里dp数组的定义有点点绕,大家要撸清思路。
2.确定递推公式
当word1[i - 1] 与 word2[j - 1]相同的时候
- 当word1[i - 1] 与 word2[j - 1]不相同的时候
当word1[i - 1] 与 word2[j - 1]相同的时候,dp[i][j] = dp[i - 1][j - 1];
当word1[i - 1] 与 word2[j - 1]不相同的时候,有三种情况:
情况一:删word1[i - 1],最少操作次数为dp[i - 1][j] + 1
情况二:删word2[j - 1],最少操作次数为dp[i][j - 1] + 1
情况三:同时删word1[i - 1]和word2[j - 1],操作的最少次数为dp[i - 1][j - 1] + 2
那最后当然是取最小值,所以当word1[i - 1] 与 word2[j - 1]不相同的时候,递推公式:dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
因为 dp[i][j - 1] + 1 = dp[i - 1][j - 1] + 2,所以递推公式可简化为:dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
这里可能不少录友有点迷糊,从字面上理解 就是 当 同时删word1[i - 1]和word2[j - 1],dp[i][j-1] 本来就不考虑 word2[j - 1]了,那么我在删 word1[i - 1],是不是就达到两个元素都删除的效果,即 dp[i][j-1] + 1。
3.dp数组如何初始化
从递推公式中,可以看出来,dp[i][0] 和 dp[0][j]是一定要初始化的。
dp[i][0]:word2为空字符串,以i-1为结尾的字符串word1要删除多少个元素,才能和word2相同呢,很明显dp[i][0] = i。
dp[0][j]的话同理,所以代码如下:
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
4.确定遍历顺序
从递推公式 dp[i][j] = min(dp[i - 1][j - 1] + 2, min(dp[i - 1][j], dp[i][j - 1]) + 1); 和dp[i][j] = dp[i - 1][j - 1]可以看出dp[i][j]都是根据左上方、正上方、正左方推出来的。
所以遍历的时候一定是从上到下,从左到右,这样保证dp[i][j]可以根据之前计算出来的数值进行计算。
5.举例推导dp数组
以word1:"sea",word2:"eat"为例,推导dp数组状态图如下:

方法2 动态规划(最长公共子序列)
本题和动态规划:1143.最长公共子序列 (opens new window)基本相同,只要求出两个字符串的最长公共子序列长度即可,那么除了最长公共子序列之外的字符都是必须删除的,最后用两个字符串的总长度减去两个最长公共子序列的长度就是删除的最少步数。
代码:动态规划(删元素)/动态规划(最长公共子序列)+滚动数组
40. Leetcode 72 编辑距离
难度:⭐️⭐️⭐️⭐️
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
-
插入一个字符
-
删除一个字符
-
替换一个字符
-
示例 1:
-
输入:word1 = "horse", word2 = "ros"
-
输出:3
-
解释: horse -> rorse (将 'h' 替换为 'r') rorse -> rose (删除 'r') rose -> ros (删除 'e')
-
示例 2:
-
输入:word1 = "intention", word2 = "execution"
-
输出:5
-
解释: intention -> inention (删除 't') inention -> enention (将 'i' 替换为 'e') enention -> exention (将 'n' 替换为 'x') exention -> exection (将 'n' 替换为 'c') exection -> execution (插入 'u')
提示:
- 0 <= word1.length, word2.length <= 500
- word1 和 word2 由小写英文字母组成
编辑距离终于来了,这道题目如果大家没有了解动态规划的话,会感觉超级复杂。
编辑距离是用动规来解决的经典题目,这道题目看上去好像很复杂,但用动规可以很巧妙的算出最少编辑距离。
接下来我依然使用动规五部曲,对本题做一个详细的分析:
1. 确定dp数组(dp table)以及下标的含义
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
有同学问了,为啥要表示下标i-1为结尾的字符串呢,为啥不表示下标i为结尾的字符串呢?
为什么这么定义我在 718. 最长重复子数组 (opens new window)中做了详细的讲解。
其实用i来表示也可以! 用i-1就是为了方便后面dp数组初始化的。
2. 确定递推公式
在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下:
if (word1[i - 1] == word2[j - 1])
不操作
if (word1[i - 1] != word2[j - 1])
增
删
换
也就是如上4种情况。
if (word1[i - 1] == word2[j - 1]) 那么说明不用任何编辑,dp[i][j] 就应该是 dp[i - 1][j - 1],即dp[i][j] = dp[i - 1][j - 1];
此时可能有同学有点不明白,为啥要即dp[i][j] = dp[i - 1][j - 1]呢?
那么就在回顾上面讲过的dp[i][j]的定义,word1[i - 1] 与 word2[j - 1]相等了,那么就不用编辑了,以下标i-2为结尾的字符串word1和以下标j-2为结尾的字符串word2的最近编辑距离dp[i - 1][j - 1]就是 dp[i][j]了。
在下面的讲解中,如果哪里看不懂,就回想一下dp[i][j]的定义,就明白了。
在整个动规的过程中,最为关键就是正确理解dp[i][j]的定义!
if (word1[i - 1] != word2[j - 1]),此时就需要编辑了,如何编辑呢?
- 操作一:word1删除一个元素,那么就是以下标i - 2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i - 1][j] + 1;
- 操作二:word2删除一个元素,那么就是以下标i - 1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i][j - 1] + 1;
这里有同学发现了,怎么都是删除元素,添加元素去哪了。
word2添加一个元素,相当于word1删除一个元素,例如 word1 = "ad" ,word2 = "a",word1删除元素'd' 和 word2添加一个元素'd',变成word1="a", word2="ad", 最终的操作数是一样! dp数组如下图所示意的:
a a d
+-----+-----+ +-----+-----+-----+
| 0 | 1 | | 0 | 1 | 2 |
+-----+-----+ ===> +-----+-----+-----+
a | 1 | 0 | a | 1 | 0 | 1 |
+-----+-----+ +-----+-----+-----+
d | 2 | 1 |
+-----+-----+
操作三:替换元素,word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增删加元素。
可以回顾一下,if (word1[i - 1] == word2[j - 1])的时候我们的操作 是 dp[i][j] = dp[i - 1][j - 1] 对吧。
那么只需要一次替换的操作,就可以让 word1[i - 1] 和 word2[j - 1] 相同。
所以 dp[i][j] = dp[i - 1][j - 1] + 1;
综上,当 if (word1[i - 1] != word2[j - 1]) 时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
递归公式代码如下:
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
3. dp数组如何初始化
再回顾一下dp[i][j]的定义:
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
那么dp[i][0] 和 dp[0][j] 表示什么呢?
dp[i][0] :以下标i-1为结尾的字符串word1,和空字符串word2,最近编辑距离为dp[i][0]。
那么dp[i][0]就应该是i,对word1里的元素全部做删除操作,即:dp[i][0] = i;
同理dp[0][j] = j;
所以C++代码如下:
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
4. 确定遍历顺序
从如下四个递推公式:
dp[i][j] = dp[i - 1][j - 1]dp[i][j] = dp[i - 1][j - 1] + 1dp[i][j] = dp[i][j - 1] + 1dp[i][j] = dp[i - 1][j] + 1
可以看出dp[i][j]是依赖左方,上方和左上方元素的,如图:

所以在dp矩阵中一定是从左到右从上到下去遍历。
代码如下:
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
}
}
5. 举例推导dp数组
以示例1为例,输入:word1 = "horse", word2 = "ros"为例,dp矩阵状态图如下:
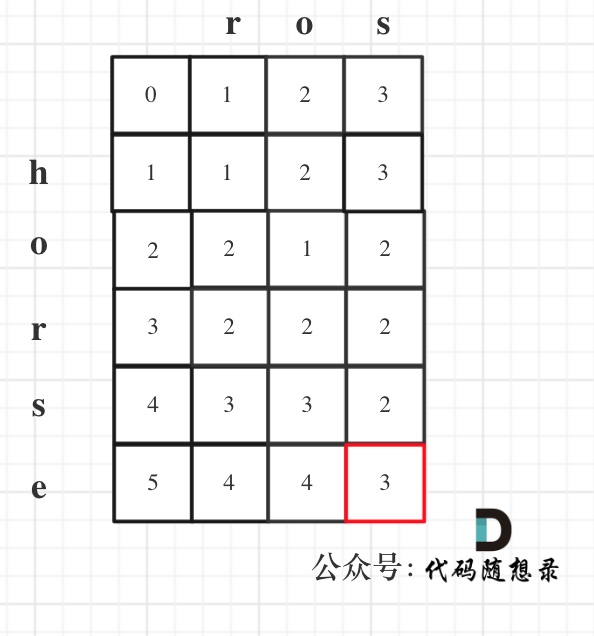
以上动规五部分析完毕,C++代码如下:
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1, 0));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
}
}
return dp[word1.size()][word2.size()];
}
};
- 时间复杂度: O(n * m)
- 空间复杂度: O(n * m)
代码:动态规划
41. Leetcode 647 回文子串
难度:⭐️(暴力)/⭐️⭐️(双指针+两轮迭代)/⭐️⭐️⭐️(动态规划)/⭐️⭐️⭐️⭐️(双指针+一轮迭代)/⭐️⭐️⭐️⭐️⭐️⭐️(Manacher 算法)
给定一个字符串,你的任务是计算这个字符串中有多少个回文子串。
具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
示例 1:
- 输入:"abc"
- 输出:3
- 解释:三个回文子串: "a", "b", "c"
示例 2:
- 输入:"aaa"
- 输出:6
- 解释:6个回文子串: "a", "a", "a", "aa", "aa", "aaa"
提示:输入的字符串长度不会超过 1000 。
方法1 暴力解法
两层for循环,遍历区间起始位置和终止位置,然后还需要一层遍历判断这个区间是不是回文。所以时间复杂度:O(n^3)
方法2 双指针+中心拓展(两轮迭代)
动态规划的空间复杂度是偏高的,我们再看一下双指针法。
首先确定回文串,就是找中心然后向两边扩散看是不是对称的就可以了。
在遍历中心点的时候,要注意中心点有两种情况。
一个元素可以作为中心点,两个元素也可以作为中心点。
那么有人同学问了,三个元素还可以做中心点呢。其实三个元素就可以由一个元素左右添加元素得到,四个元素则可以由两个元素左右添加元素得到。
所以我们在计算的时候,要注意一个元素为中心点和两个元素为中心点的情况。
这两种情况可以放在一起计算,但分别计算思路更清晰,我倾向于分别计算
方法3 双指针+中心拓展(一轮迭代)


//解释一下2n-1: n为单中心的总数(单个字母的总数),n-1为双中心的总数(两个相邻字母构成区间的总数)
//li和ri可以代入每个i值去理解一下,其实就是对应从左到右依次的每个单双中心(也就是上表中的每个区间)
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
方法4 动态规划
动规五部曲:
1.确定dp数组(dp table)以及下标的含义
如果大家做了很多这种子序列相关的题目,在定义dp数组的时候 很自然就会想题目求什么,我们就如何定义dp数组。
绝大多数题目确实是这样,不过本题如果我们定义,dp[i] 为 下标i结尾的字符串有 dp[i]个回文串的话,我们会发现很难找到递归关系。
dp[i] 和 dp[i-1] ,dp[i + 1] 看上去都没啥关系。
所以我们要看回文串的性质。 如图:

我们在判断字符串S是否是回文,那么如果我们知道 s[1],s[2],s[3] 这个子串是回文的,那么只需要比较 s[0]和s[4]这两个元素是否相同,如果相同的话,这个字符串s 就是回文串。
那么此时我们是不是能找到一种递归关系,也就是判断一个子字符串(字符串的下表范围[i,j])是否回文,依赖于,子字符串(下表范围[i + 1, j - 1])) 是否是回文。
所以为了明确这种递归关系,我们的dp数组是要定义成一位二维dp数组。
布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如果是dp[i][j]为true,否则为false。
2.确定递推公式
在确定递推公式时,就要分析如下几种情况。
整体上是两种,就是s[i]与s[j]相等,s[i]与s[j]不相等这两种。
当s[i]与s[j]不相等,那没啥好说的了,dp[i][j]一定是false。
当s[i]与s[j]相等时,这就复杂一些了,有如下三种情况
- 情况一:下标i 与 j相同,同一个字符例如a,当然是回文子串
- 情况二:下标i 与 j相差为1,例如aa,也是回文子串
- 情况三:下标:i 与 j相差大于1的时候,例如cabac,此时s[i]与s[j]已经相同了,我们看i到j区间是不是回文子串就看aba是不是回文就可以了,那么aba的区间就是 i+1 与 j-1区间,这个区间是不是回文就看dp[i + 1][j - 1]是否为true。
以上三种情况分析完了,那么递归公式如下:
if (s[i] == s[j]) {
if (j - i <= 1) { // 情况一 和 情况二
result++;
dp[i][j] = true;
} else if (dp[i + 1][j - 1]) { // 情况三
result++;
dp[i][j] = true;
}
}
result就是统计回文子串的数量。
注意这里我没有列出当s[i]与s[j]不相等的时候,因为在下面dp[i][j]初始化的时候,就初始为false。
3.dp数组如何初始化
dp[i][j]可以初始化为true么? 当然不行,怎能刚开始就全都匹配上了。
所以dp[i][j]初始化为false。
4.确定遍历顺序
遍历顺序可有有点讲究了。
首先从递推公式中可以看出,情况三是根据dp[i + 1][j - 1]是否为true,在对dp[i][j]进行赋值true的。
dp[i + 1][j - 1] 在 dp[i][j]的左下角,如图:
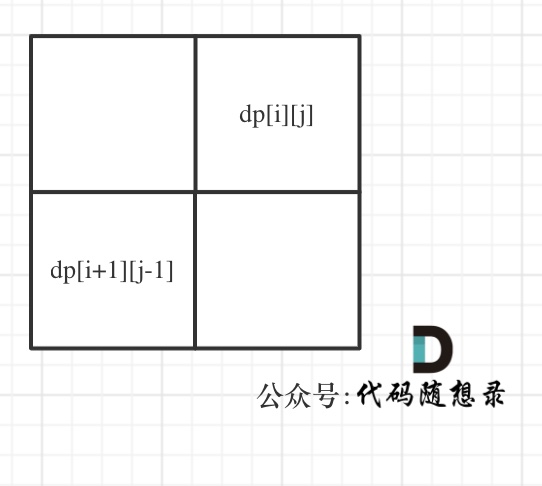
如果这矩阵是从上到下,从左到右遍历,那么会用到没有计算过的dp[i + 1][j - 1],也就是根据不确定是不是回文的区间[i+1,j-1],来判断了[i,j]是不是回文,那结果一定是不对的。
所以一定要从下到上,从左到右遍历,这样保证dp[i + 1][j - 1]都是经过计算的。
有的代码实现是优先遍历列,然后遍历行,其实也是一个道理,都是为了保证dp[i + 1][j - 1]都是经过计算的。
代码如下:
for (int i = s.size() - 1; i >= 0; i--) { // 注意遍历顺序
for (int j = i; j < s.size(); j++) {
if (s[i] == s[j]) {
if (j - i <= 1) { // 情况一 和 情况二
result++;
dp[i][j] = true;
} else if (dp[i + 1][j - 1]) { // 情况三
result++;
dp[i][j] = true;
}
}
}
}
5.举例推导dp数组
举例,输入:"aaa",dp[i][j]状态如下:

图中有6个true,所以就是有6个回文子串。
注意因为dp[i][j]的定义,所以j一定是大于等于i的,那么在填充dp[i][j]的时候一定是只填充右上半部分。
//注意这道题dp[i][j]定义的是“是否为回文串”,而不是“区间内可能的回文串总数”,因为后者较难用递推公式去实现。
方法5 Manacher 算法
//马拉车算法的本质,就是解决了双指针+中心扩展算法中,从每个中心点直接向外拓展的时间开销,通过以O(n)空间复杂度记录每个位置i的最大子串半径f(i),使得可以直接从i+f(i)-1而非i+1的位置进行中心拓展,最终将时间复杂度从O(n2)降低至O(n)




关于马拉车算法的另一篇解释,也可以当做补充阅读材料。
- 时间复杂度:O(n)
- 空间复杂度:O(n)
代码:暴力/动态规划/双指针+两次迭代/双指针+一次迭代/manacher算法
42. Leetcode 516 最长回文子序列
难度:⭐️⭐️⭐️
给定一个字符串 s ,找到其中最长的回文子序列,并返回该序列的长度。可以假设 s 的最大长度为 1000 。
示例 1: 输入: "bbbab" 输出: 4 一个可能的最长回文子序列为 "bbbb"。
示例 2: 输入:"cbbd" 输出: 2 一个可能的最长回文子序列为 "bb"。
提示:
- 1 <= s.length <= 1000
- s 只包含小写英文字母
方法1 动态规划(最长回文串)
我们刚刚做过了 动态规划:回文子串 (opens new window),求的是回文子串,而本题要求的是回文子序列, 要搞清楚这两者之间的区别。
回文子串是要连续的,回文子序列可不是连续的! 回文子串,回文子序列都是动态规划经典题目。
回文子串,可以做这两题:
- 647.回文子串
- 5.最长回文子串
思路其实是差不多的,但本题要比求回文子串简单一点,因为情况少了一点。
动规五部曲分析如下:
1.确定dp数组(dp table)以及下标的含义
dp[i][j]:字符串s在[i, j]范围内最长的回文子序列的长度为dp[i][j]。
2.确定递推公式
在判断回文子串的题目中,关键逻辑就是看s[i]与s[j]是否相同。
如果s[i]与s[j]相同,那么dp[i][j] = dp[i + 1][j - 1] + 2;
如图:
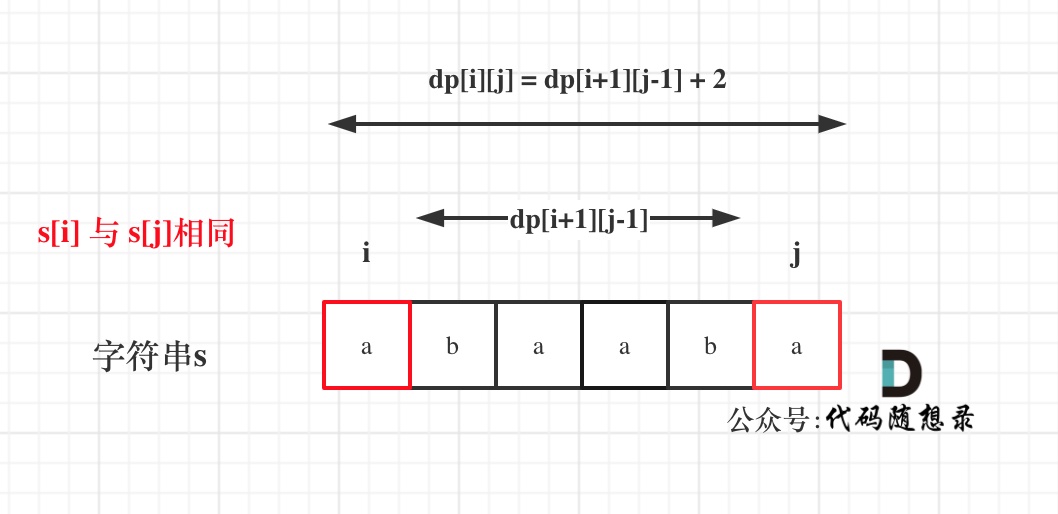
(如果这里看不懂,回忆一下dp[i][j]的定义)
如果s[i]与s[j]不相同,说明s[i]和s[j]的同时加入 并不能增加[i,j]区间回文子序列的长度,那么分别加入s[i]、s[j]看看哪一个可以组成最长的回文子序列。
加入s[j]的回文子序列长度为dp[i + 1][j]。
加入s[i]的回文子序列长度为dp[i][j - 1]。
那么dp[i][j]一定是取最大的,即:dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
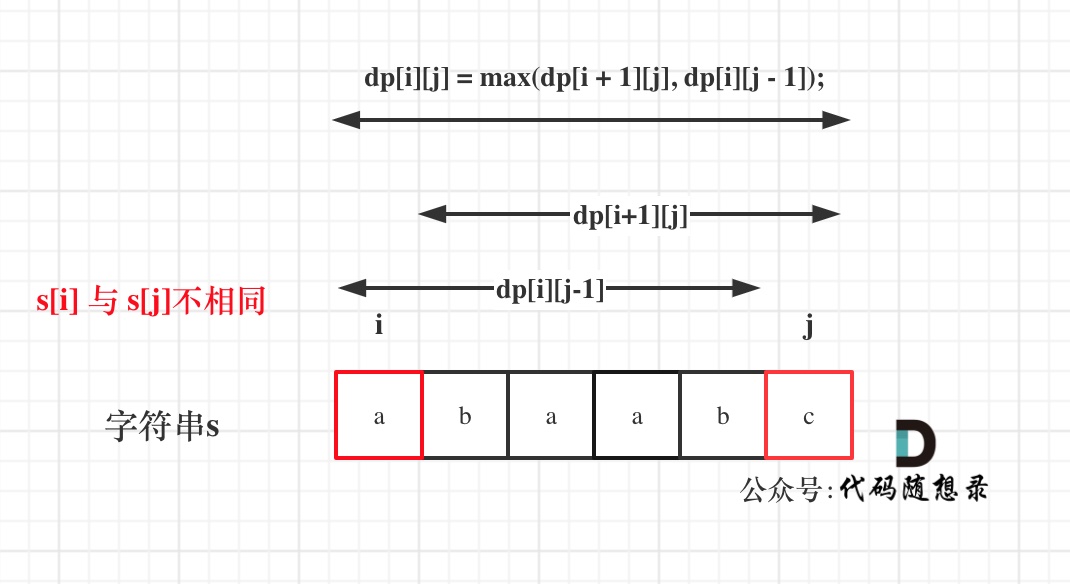
代码如下:
if (s[i] == s[j]) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
3.dp数组如何初始化
首先要考虑当i 和j 相同的情况,从递推公式:dp[i][j] = dp[i + 1][j - 1] + 2; 可以看出 递推公式是计算不到 i 和j相同时候的情况。
所以需要手动初始化一下,当i与j相同,那么dp[i][j]一定是等于1的,即:一个字符的回文子序列长度就是1。
其他情况dp[i][j]初始为0就行,这样递推公式:dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]); 中dp[i][j]才不会被初始值覆盖。
vector<vector<int>> dp(s.size(), vector<int>(s.size(), 0));
for (int i = 0; i < s.size(); i++) dp[i][i] = 1;
4.确定遍历顺序
从递归公式中,可以看出,dp[i][j] 依赖于 dp[i + 1][j - 1] ,dp[i + 1][j] 和 dp[i][j - 1],如图:

所以遍历i的时候一定要从下到上遍历,这样才能保证下一行的数据是经过计算的。
j的话,可以正常从左向右遍历。
代码如下:
for (int i = s.size() - 1; i >= 0; i--) {
for (int j = i + 1; j < s.size(); j++) {
if (s[i] == s[j]) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
}
}
5.举例推导dp数组
输入s:"cbbd" 为例,dp数组状态如图:
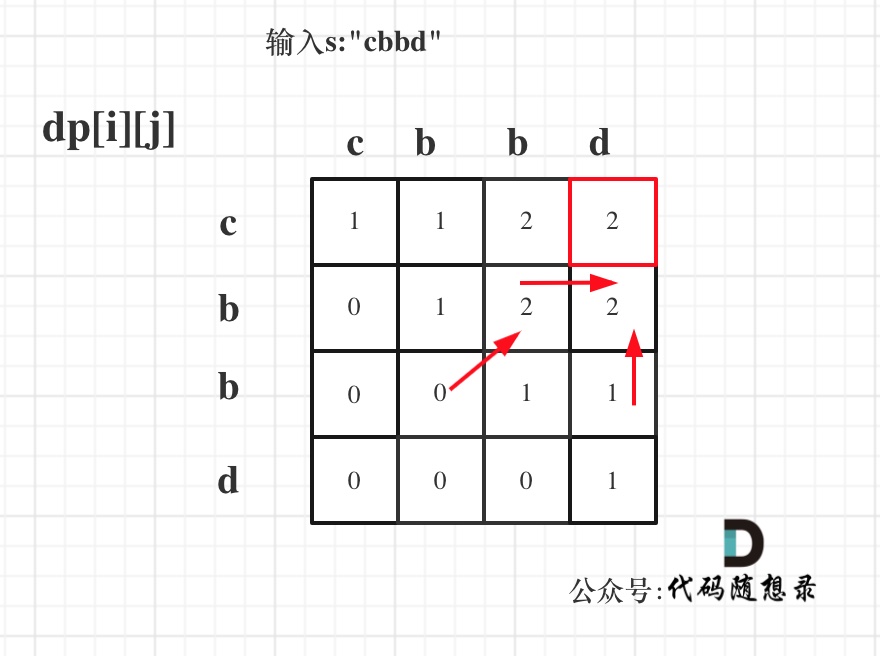
红色框即:dp[0][s.size() - 1]; 为最终结果。
方法2 动态规划(最长公共子序列)
将字符串翻转,然后求两个字符串的最长公共子序列就可以了
子序列问题总结

动态规划总结
















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









