







梯度下降属于线性回归的一个重要的部分。但是这种方法具有局限性,在一般的情况下,并不能保证找到的局部最小就是全局最小。所以这种方法适用于目标函数是凸函数的情况(local minimum == global minimum)。即使是在凸函数中也不能保证最后找到的点就是最小值,这取决于算法的中止条件(即变化率小于一个定值)和所取的参数λ。所以算法很可能在找到一个相对平滑而并非最小值的地方以后就终止。
在梯度下降中,λ的选择尤为重要。λ偏大的话,算法会一直徘徊在最小值左右的两个点而陷入死循环;λ偏小的话,会导致梯度下降的速率偏慢。基于这种情况,我们不再将λ设置成为一个定值,而是随着算法不断变化。一般来说,我们选择先快后慢,即初始的λ较大,而第k次更迭的λ与k-1次的λ成正比,与1+k的开方成反比。现在考虑另一个问题:对于同一个特征X来说,若w1处的导数值大于w2处的导数值,那么在w1处移动的距离将会大于在w2处移动的距离,这样正好满足了我们对于梯度下降的要求,即越靠近可能是最小值的点时,移动的距离越小。但是对于所有的特征来说都通用吗?试想Y=1000X^2 这个函数,相当陡峭,即使是在靠近X=0这个点,附近的导数也很大,这样依然是很容易越过最小值点而陷入死循环。那么如何解决这个问题呢?我们注意到,这里涉及到了变化率的大小这个问题,也就是说λ的设置不仅与更迭的次数有关,还与该特征变化的快慢(即导数的大小)有关系。很明显,对于导数偏大的特征,我们需要降低下降的速率,对于导数偏小的特征,我们需要加快下降的速率。故第k次的λ还与前k-1次的导数平方的累加成反比,为了避免该值过大,我们取其均值的开方放在分母上。
好的,当自由变量λ设置好以后,又出现了新的问题:如果一个特征的变化范围在10000到100000中,而另一个特征的变化范围在10^(-9)到10^(-8)中。这样的情况下,参数w的变化对于小范围的特征来说微乎其微,而对于大范围的参数来说,会更加放大w的变化。而且过大或者过小的特征的值,不仅会很大程度地影响梯度下降的速率,而且对于设定算法终止条件也很困难。所以需要进行feature scaling ,来消除特征本身范围对于梯度下降的影响。这样既保证了最后找到的点是全局相对平滑的点,又保证了梯度下降的速率和准确度。
那么, 如何来进行feature scaling 呢?其实方法有很多种,关键是控制放缩比例。常见的方法是:
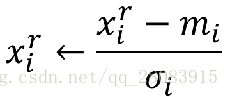
mi 是特征X的均值,σi 是特征X的标准差。这样一来,得到的所有例子的特征X的新值,均值为0,方差为1。














 1541
1541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









