







简介
我们在使用nginx或者rpc框架的时候,经常会用到负载均衡策略。负载均衡策略中有一致性hash、权重算法、轮询、最小活跃输、随机等。
今天采用通俗易懂的白话讲解一下为何nginx、dubbo采用的平滑加权轮询算法?
它和我们平时使用的权重算法到底有何区别呢?
实现
- 一般的权重算法
我们有三个节点A,B,C,假设权重分配为3,1,1;
那么如果在做rpc调用的时候,进来了5个请求;那么如果按照权重分配比,处理请求节点的情况是
AAABCAAABC。具体实现我们可以按照权重比分配一个区间,然后生成随机数进行碰撞。如按照权重
A:[0, 60)
B:[60, 80)
C:[80,100)
然后在100内随机生成一个正数,这个点落在那个区间,那么就选取那个节点请求。
这种方式会导致A节点会连续不断处理多个请求,其余两个节点确一致等待,显然这种方式不能平滑各个节点的请求,让权重大的节点压力较大。
- 平滑权重轮询算法
平滑权重轮询算法的实现就是为了解决权重大的节点负载压力大的问题,其具体做法如下。
同样我们有A,B,C,假设权重分配为3,1,1, 初始权重微0,0,0.
weightSum += weight CurrentWeight = max(weight) max(weight) - totalWeight
3,1,1 3 -2, 1, 1
1,2,2 2 1, -3, 2
4,-2,3 4 -1, -2, 3
2,-1,4 4 2, -1,-1
2,0,0 2 -0, 0, 0
经过四轮之后又回到了初始权重值0,0,0;各个节点的负载均衡情况是ABACA,可以看到我们的A节点没有连续作为工作节点,而是穿插在BC两个节点中进行,这样不会一直处理进来的请求,减小服务器的负载压力。
一个简易的图来形象的展示我们平滑加权算法的实现过程中前三次过程:
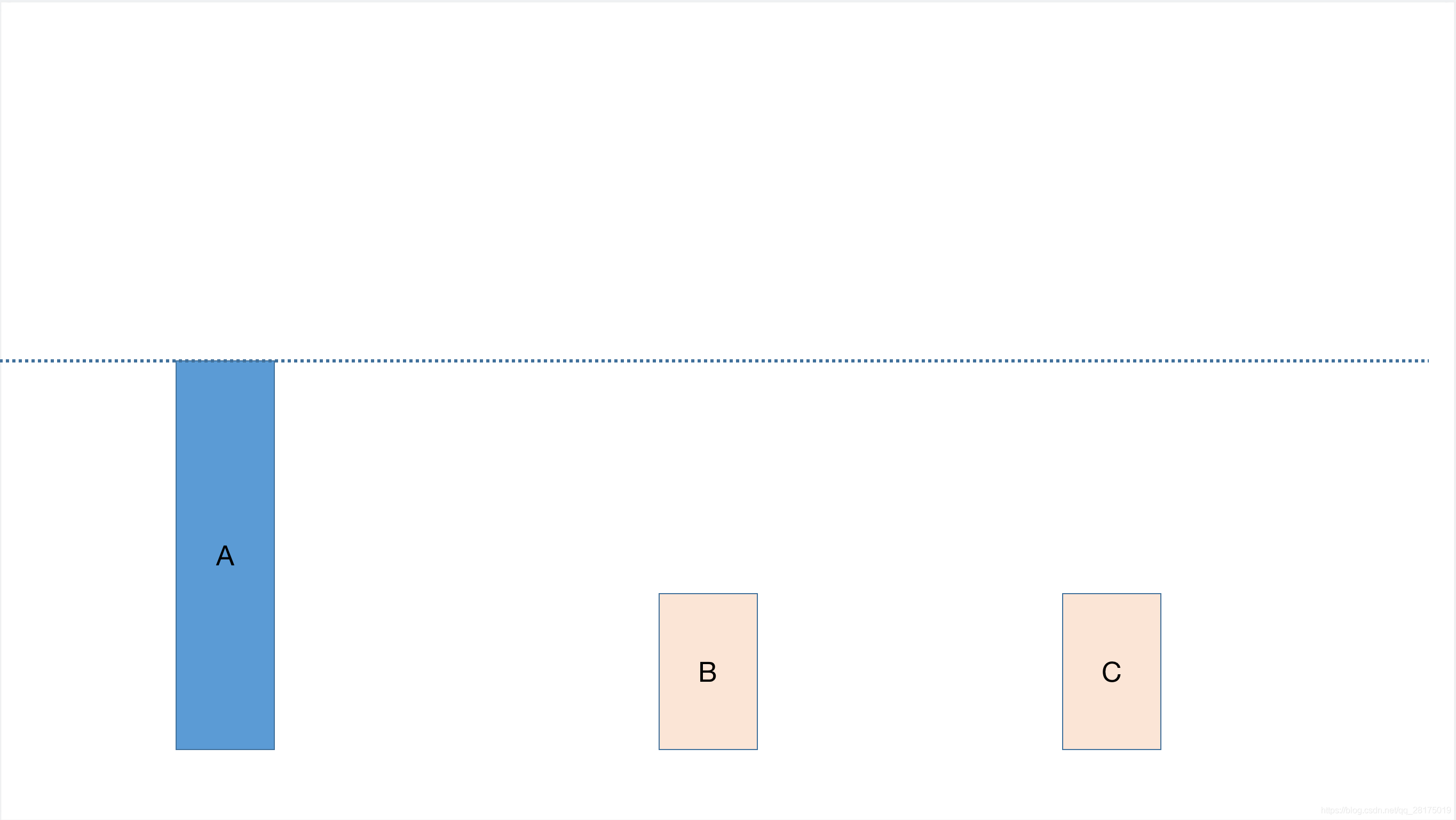

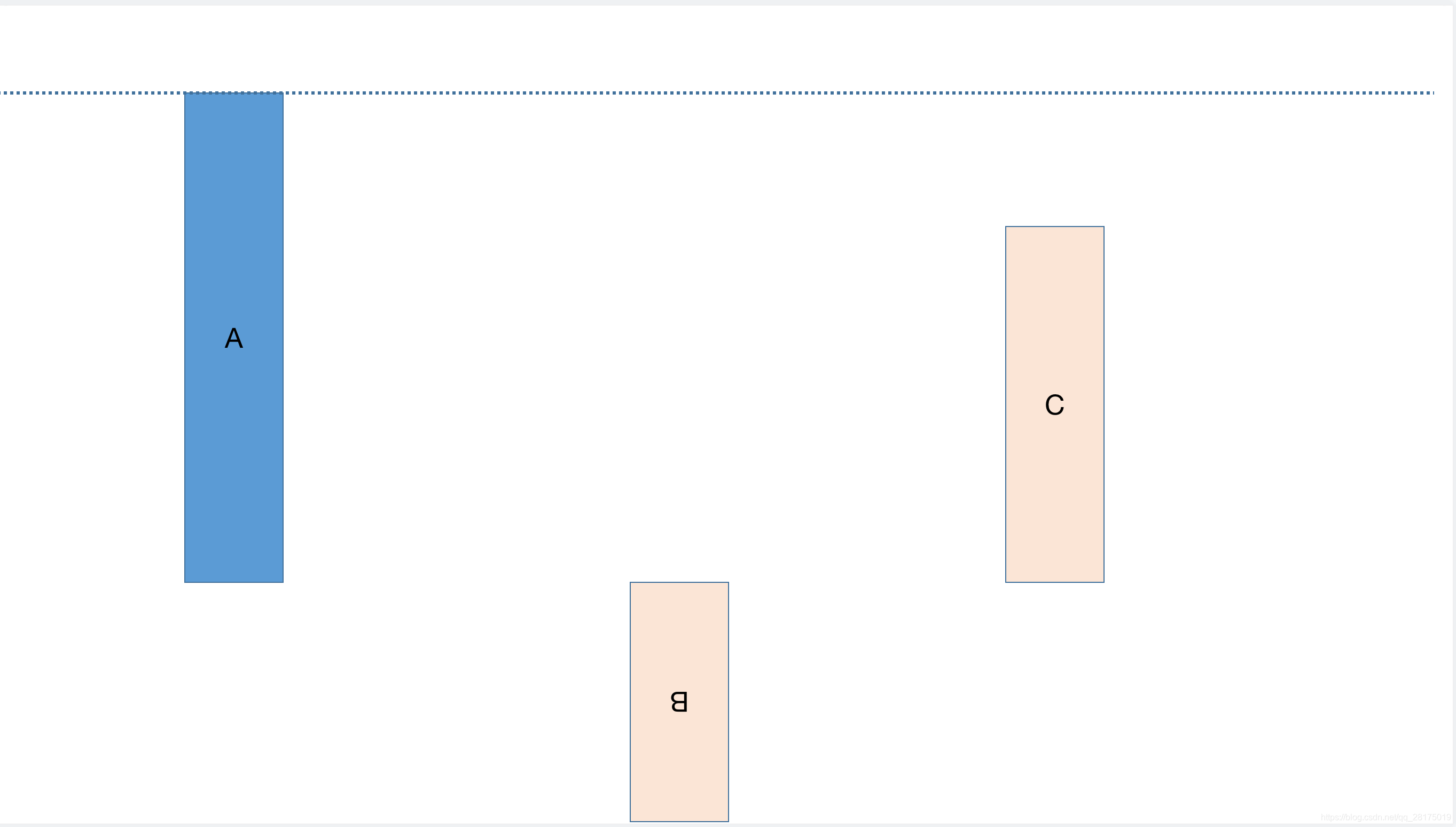
用一句形象的话描述:就像割韭菜,长到一定的高度就割韭菜,权限重的就长得快,割的次数就多,但是长得快的割得狠,所以下次就割别的韭菜了。
















 337
337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











