







XML
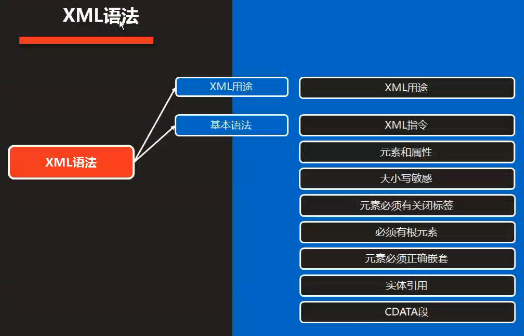
XML用途

XML处理指令

这个永远是第一行
<??>
<?xml version=”1.0” encoding=”utf-8”?>
元素和属性

标签成对出现


XML是又若干组标签组成的,一组标签包含前标签和后标签
缺一不可。标签可以包含其他标签或文本。前标签中可以定义属性
格式是: 属性名=”属性值”(值需要被”” 括上)
必须有根元素,并且根元素只能有一个

所谓根元素就是不在被任何元素包含了。
XML可以描述一个很复杂的树状结构
所有保存和传输信息很方便。
html是xml的分支
实体引用(就是进行转义的)
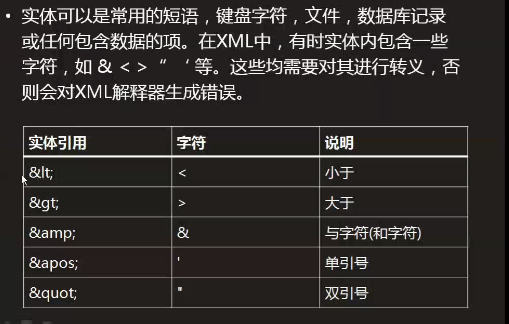
那些个标签的名字标签都是自己写的
CDATA段

<![CDATA][
这里无论写什么都是文本
]>
SAX解析方式

SAX占用的内存,比如安卓就是用的SAX
DOM解析方式
在内部是描述树的,想获取哪个节点就能获取。
把整个xml文件变成树。
文件大,解析慢,内存有压力
但是可以编辑XML文件

读取XML

demo4j-1.6 下载
http://download.csdn.net/download/zsy_fengzhiying/4175530
导入 demo4j 1.6
创建文件夹直接把文件拖过去就可以
element方法

Element element(String name) 获取当前元素下的指定名字的子元素
Element e = element.element(“标签名字”) ;
如果写的是emp那么会返回所有emp标签的 这么多当然返回的是list!!!
element.getName()获取当前元素标签的名字
attribute方法
获取当前元素的指定属性,index为索引,从0开始
或者直接指定属性名来获取属性值


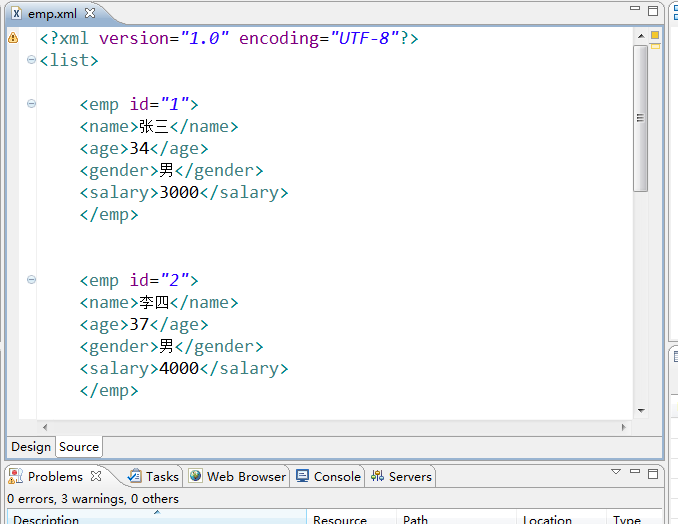
例子:写一个emp.xml 然后解析
emp.xml
<?xml version="1.0" encoding="UTF-8"?>
<list>
<emp id="1">
<name>张三</name>
<age>34</age>
<gender>男</gender>
<salary>3000</salary>
</emp>
<emp id="2">
<name>李四</name>
<age>37</age>
<gender>男</gender>
<salary>4000</salary>
</emp>
<emp id="3">
<name>王五</name>
<age>42</age>
<gender>男</gender>
<salary>7000</salary>
</emp>
<emp id="5">
<name>赵六</name>
<age>31</age>
<gender>女</gender>
<salary>5000</salary>
</emp>
<emp id="6">
<name>钱七</name>
<age>24</age>
<gender>男</gender>
<salary>3500</salary>
</emp>
</list>创建一个Emp类来存储每个emp标签的信息
package day08;
/**
* 该类用于描述emp.xml文件中表示的员工
* @author Administrator
*
*/
public class Emp {
private int id;
private String name;
private int age;
private String gender;
private int salary;
public Emp(int id, String name, int age, String gender, int salary) {
super();
this.id = id;
this.name = name;
this.age = age;
this.gender = gender;
this.salary = salary;
}
/*无参的构造方法:
* 当我们没有定义构造方法时,编译器会自动帮我们添加一个默认的构造方法
*
* 默认构造方法:
* 无参数,且没有任何实现代码,如下:
* 若我们定义任何过构造方法,编译器不会为我们添加默认构造方法,若需要,则手动书写
*
* Person
* int age;
* run()
* Son()
* int age
* run()
*
* Person p = new Son();
* p.run();//调用的是子类的run
* p.age =1;//改的是子类
* 属性是不具备多态性的
*
*/
public Emp(){}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public int getSalary() {
return salary;
}
public void setSalary(int salary) {
this.salary = salary;
}
public String toString(){
return id+","+name+","+age+","+gender+","+salary;
}
}解析xml,并存到一个Emp类中,然后创建个每一个Emp放入list中
package day08;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
/**
* 使用DOM解析XML文件
* @author Administrator
*
*/
public class XMLDemo1 {
public static void main(String[] args) {
try{
/*
* 解析XML文件的基本流程
* 1、创建SAXReader,用来读取XML文件
* 2、指定XML文件使得SAXRreader读取并解析文档对象Document
* 3、获取根元素
* 4、获取每一个元素,从而达到解析目的
*/
//1
SAXReader reader
= new SAXReader();
//2
/*
* 常用的读取方法
* Document read (InputStream in)
* Document read(Reader read )
* Document read(File file )
* read方法的作用:
* 读取给定的xml,并将其揭西县转换为一个Document对象
* 实际上这里已经完成了对整个xml解析的工作。并将所有内容封装到了
* Document对象中
* Document对象可以描述当前xml文档
*/
//创建个文件描述符,操作emp.xml
File xmlFile = new File("emp.xml");
Document doc = reader.read(xmlFile);
//3 注意导包!!!!要org.demo4j的
Element root = doc.getRootElement();
//4遍历子元素
/*
* Element element(String name)
* 获取当前标签下第一个名为给定名字的标签
*
* List elements(String name)
* 获取当前标签下所有给定名字的标签
*
* List elements()
* 获取所有子标签,不管什么名字
*/
//获取所有标签存在list elements中
List<Element> elements =root.elements();
/*创建一个集合,用于保存xml中的每一个用户信息。我们先将
* 用户信息取出,然后创建一个Emp实例,将信息设置到该实例的相应属性上。
* 最终将所有emp对象存入该集合
*
*/
List<Emp> list
= new ArrayList<Emp>();
//遍历每一个emp标签
for(Element emp : elements){
//创建一个Emp对象,用于保存信息
Emp e = new Emp();
//解析emp标签
//获取name的值
/*
* 首先获取名为name的子标签
* 其次获取前后标签中的文本
*/
Element ename = emp.element("name");
String name = ename.getTextTrim();
/*
* String elementText(String name)
* 获取当前标签中名为给定名字的子标签中间的文本
* 该方法与上面获取“name”的两句话等效
*/
String agestr = emp.elementTextTrim("age");
int age = Integer.parseInt(agestr);
String gender =emp.elementText("gender");
String salarystr = emp.elementText("salary");
int salary = Integer.parseInt(salarystr);
e.setAge(age);
e.setGender(gender);
e.setName(name);
e.setSalary(salary);
/*
* 通过Element获取元素属性
*/
Attribute attr = emp.attribute("id");
//获取属性值,获取属性值:getName
//直接转换为int id
int id = Integer.parseInt( attr.getValue());
e.setId(id);
//将Emp对象存入集合
list.add(e);
}
System.out.println("解析了"+list.size()+"个员工信息");
//输出每一个员工的信息
for(Emp e : list){
System.out.println(e);
}
}catch(Exception e){
}
}
}
然后是写XML文件
package day08;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.dom.DOMElement;
import org.dom4j.io.XMLWriter;
import org.xml.sax.DocumentHandler;
/**
* 使用DOM写出一个XML
* @author Administrator
*
*/
public class XMLDemo2 {
public static void main(String[] args) {
//创建一个list用来存储创建的Emp对象
List<Emp> list
= new ArrayList<Emp>();
//创建Emp,然后增加到list中
list.add(new Emp(1,"jack",33,"男",68000));
list.add(new Emp(2,"Recar",33,"男",28000));
list.add(new Emp(3,"marry",24,"女",68000));
list.add(new Emp(4,"kate",32,"女",8000));
list.add(new Emp(5,"boss",26,"男",8700));
list.add(new Emp(6,"peter",38,"男",12000));
/*
* 生成一个xml的基本步骤
* 1、创建文档对象Document
* 2、为Document添加根节点
* 3、为根节点组建树状结构
* 4、创建XMLWriter
* 5、为XMLWriter指定写出目标
* 6、写出xml
*/
// 1
//注意!!!创建这个文档用的是DocumentHelper的静态方法createDocument来创建
//xml文件
Document doc = DocumentHelper.createDocument();
/*
* Document 的方法
* Element addElement(String name)
* 该方法用于向文档中添加给定名字的根元素,返回的Element实例就表示该
* 根元素
* 需要注意的是,该方法只能调用一次
* 既然都是根了。。。
* 调用第二次会抛出异常
*/
Element root
= doc.addElement("list");
/*
* 循环添加每一个员工信息
*/
for(Emp e:list){
/*
* Element同样支持方法:
* Element addElement(String name)
* 向当前标签中添加给定名字的子标签
*/
//向根标签中添加emp标签
//list里有多少个就添加几次
Element emp = root.addElement("emp");
//向emp标签中添加子标签name
Element name = emp.addElement("name");
//直接设置。把原来的改变
name.setText(e.getName());
//或者增加
name.addText(e.getName());
//是int放入String的话,就加个空字符串
emp.addElement("age").addText(e.getAge()+"");
emp.addElement("gender").addText(e.getGender());
emp.addElement("salary").addText(e.getSalary()+"");
/*
* 为标签添加属性
* Element addAttribute(String name,String value)
* 为当前标签添加给定名字以及对应值的属性
* 返回值仍然为当前标签
* 这样走的目的是可以连续添加若干属性
* 就好像StringBuilder的append的返回值效果和作用
*/
//增加属性
emp.addAttribute("id", e.getId()+"'");
}
/*
* 当退出循环后,那么Document中的结构就已经构建完了
* 需要将其写出xml
*/
XMLWriter writer
= new XMLWriter();
FileOutputStream out = null;
try {
out = new FileOutputStream("emp2.xml");
} catch (FileNotFoundException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
//指定往哪写
try {
writer.setOutputStream(out);
try {
/*
* 将Document对象写出到文件中,
* 这时会将Document转换为xml格式写入文件
*/
writer.write(doc);
writer.close();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
} catch (UnsupportedEncodingException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
System.out.println("创建成功!!!");
}
}写完后格式不好
ctrl+shift+f 或者 source->format
小结:
读取XML
1、先创建 SAXReader 来读取XML
2、创建XML的文件描述符
3、创建文档对象 Document doc来操作XML
doc =saxreader.read(XML的文件描述符);
4、获取根标签用的Element
Element root = doc.getRootElement();
既然用xm存储信息。那么就给他创建个类,然后把标签下的值赋进去。
5、用list来装。即
List<Element> element = root.element();获取根下所有的标签
6、循环遍历List并创建和赋值,不同的是属性用Attribute attr = emp.attribute(“属性名”);
获取属性值: attr.getValue();
写XML
1、先将信息写入emp并放入list中
创建文档对象Document
要注意!!!
Document doc = DocumentHelper.CreateDocument();2、创建根
3、循环增加标签并加内容
创建完要写出XML
是XMLWriter
4、创建字符流
写
writer.seetoutpastream(out);
writer.write(doc);记得最后要关闭















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









