






 本文提出了一种新的分层会议摘要网络(HMNet),针对会议摘要的独特挑战,如长篇转录、多说话人风格差异和数据稀缺。HMNet通过层次结构编码器处理长文本,引入角色向量捕捉说话人差异,并利用预训练技术提升模型性能。在AMI和ICSI数据集上,HMNet显著优于传统方法,如ROUGE-1得分提升41.62%。
本文提出了一种新的分层会议摘要网络(HMNet),针对会议摘要的独特挑战,如长篇转录、多说话人风格差异和数据稀缺。HMNet通过层次结构编码器处理长文本,引入角色向量捕捉说话人差异,并利用预训练技术提升模型性能。在AMI和ICSI数据集上,HMNet显著优于传统方法,如ROUGE-1得分提升41.62%。
摘要
有了自动会议转写,会议摘要对于参与者和其他各方都非常感兴趣。会议摘要的传统方法依赖于复杂的多步骤pipline,这使得联合优化难以实现。同时,对于文本摘要和对话系统来说,已经出现了一些非常有用的深层神经模型。但是,会议记录的语义结构和样式与文章和对话完全不同。在本文中,我们提出了一种适用于会议场景的新的生成式摘要网络。我们设计了一个层次结构来容纳长时间的会议记录,并设计了一个角色向量来描述演讲者之间的差异。此外,由于会议摘要数据不足,我们在大规模新闻摘要数据上对模型进行了预训练。实证结果表明,我们的模型在自动度量和人工评估方面都优于以前的方法。例如,在ICSI数据集上,ROUGE-1得分从34.66%增加到46.28%。
1.介绍

会议是一个非常常见的场景,人们可以通过会议交流想法,制定计划和共享信息。随着自动语音识别系统的普及,大量的会议转写也随之而来。因此,自然需要简洁地总结会议的内容。
目前,已经提出了几种生成会议摘要的方法。 正如Murray et al. (2010) 指出的那样,用户更喜欢生成式会议摘要而不是抽取式摘要。尽管目前方法大多是生成式的,但它们需要复杂的多阶段机器学习pipline,例如模板生成,句子聚类,多句压缩,候选句子生成和排名。由于这些方法不是端到端可优化的,因此很难共同改进pipline中的各个部分以增强整体性能。此外,某些组件(例如模板生成)需要大量的人员参与,从而使解决方案不可扩展或不可移植。
同时,许多端到端系统已成功地用于解决文档摘要问题,例如指针生成器网络,增强摘要网络和记忆网络。这些深度学习方法可以通过直接优化预定义目标来有效地生成文档摘要。
但是,会议摘要任务面临许多挑战,这使得端到端训练会议摘要比文档摘要更加困难。我们在表1中显示了AMI数据集的会议记录示例和模型生成的摘要。
首先,单个会议的转写和摘要通常比文档要长得多。例如,在CNN/Daily Mail数据集中,每篇文章平均有781个字符,每个摘要平均有56个字符,而AMI会议语料库包含的会议平均每个转写有4757个字符,每个摘要平均有322个字符。会议转写的结构与新闻报道截然不同。这些挑战都阻碍了现有新闻摘要模型成功地应用于会议场景。
其次,在多个参与者之间进行的会议,每个参与者的不同语义风格,立场和角色都促成了会议转写的异质性。
第三,与新闻相比,用于会议摘要的有标注的训练数据非常有限(AMI中的137场会议 v.s. n CNN/DM中的31.2w篇文章中)。这是由于会议的私密性以及为为较长的会议转写构建摘要的成本较高。
为了解决这些挑战,我们提出了一个端到端的深度学习框架,即分层会议摘要网络(Hierarchical Meeting summarization Network, MNet)。HMNet利用编码器-解码器transformer架构生成基于会议转写的摘要。为了使模型结构适应摘要,我们提出了两个主要的设计改进。
首先,由于会议转写通常很长,因此直接应用常规的transformer结构可能不可行。例如,在具有数千个字符的转写上执行多头自注意力机制非常耗时,并且可能导致内存溢出问题。因此,我们利用分层结构来减轻计算负担。 由于会议由来自不同参与者的话语组成,因此形成了自然的多轮会议层次结构。因此,分层结构既可以在每轮内执行字符级别的理解,又可以在整个会议中执行多轮级别的理解。在摘要生成过程中,HMNet会将注意力集中在两个层次的理解上,以确保摘要的每个部分都源自转写的不同部分,且粒度各不相同。
其次,为了适应多说话人的情况,HMNet合并了每个说话人的角色,以对参与者之间不同的语义样式和立场进行编码。例如,程序经理通常强调项目的进度,而用户界面设计人员则倾向于关注用户体验。在HMNet中,我们为每个会议参与者训练角色向量,以在编码过程中表示说话人的信息。该角色向量被附加到多轮级别表示上,以用于以后的解码。
为了解决训练数据不足以进行摘要的问题,我们利用了预训练的思想。我们从新闻领域收集摘要数据,并将其转换为会议格式:一组几篇新闻文章组成一个多人会议,每个句子变成一轮。 重新排列转弯以模拟说话人的混合顺序。我们在新闻任务上对HMNet模型进行了预训练,然后在会议摘要数据对其进行了微调。实验结果表明,这种跨域预训练可以有效地提高模型质量。
为了评估我们的模型,我们使用了广泛使用的AMI和ICSI会议语料库。结果表明,HMNet大大优于以前的会议摘要方法。例如,在ICSI数据集上,与先前的最佳结果相比,HMNet的ROUGE1点提高了11.62,ROUGE-2点提高了2.60,ROUGE-SU4提高了6.66。人工评估进一步表明,HMNet生成的摘要要比基线方法好得多。然后,我们进行消融研究,以验证模型中不同组件的有效性。
2.问题定义
我们将会议摘要的问题定义如下:输入是由会议转写 X \mathcal X X和会议参与者 P \mathcal P P组成,假设总共有 s s s个会议,则转写为 X = { X 1 , . . . , X s } \mathcal X=\{X_1,...,X_s\} X={X1,...,Xs}。 每个会议转写由多轮对话组成,其中每个轮次都是参与者的讲话。因此, X i = { ( p 1 , u 1 ) , ( p 2 , u 2 ) , . . . , ( p L i , u L i ) } X_i=\{(p_1,u_1),(p_2,u_2),...,(p_{L_i},u_{L_i})\} Xi={(p1,u1),(p2,u2),...,(pLi,uLi)},其中 p j ∈ P , 1 ≤ j ≤ L i p_j∈\mathcal P,1≤j≤L_i pj∈P,1≤j≤Li表示参与者, u j = ( w 1 , . . . , w l j ) u_j=(w_1,...,w_{l_j}) uj=(w1,...,wlj)是来自 p j p_j pj的标记化文本。会议Xi的人工标注的摘要(由 Y i Y_i Yi表示)也是一个字符序列。为简单起见,我们将删除会议索引下标。因此,系统的目标是给定成转写 X = { ( p 1 , u 1 ) , ( p 2 , u 2 ) , . . . , ( p m , u m ) } X=\{(p_1,u_1),(p_2,u_2),...,(p_m,u_m)\} X={(p1,u1),(p2,u2),...,(pm,um)},生成会议摘要 Y = ( y 1 , . . . , y n ) Y=(y_1,...,y_n) Y=(y1,...,yn)。
3.模型
我们的分层会议摘要网络(HMNet)基于编解码器transformer结构,其目标是在给定转写 X X X和网络参数 θ θ θ的情况下最大化会议摘要 Y Y Y的条件概率: P ( Y ∣ X ; θ ) P(Y|X;θ) P(Y∣X;θ)。
3.1 编码器
3.1.1 角色向量
来自不同参与者的会议转写被记录下来,他们可能具有不同的语义风格和观点。因此,该模型在生成摘要时必须考虑发言人的信息。
为了包含参与者的信息,我们整合了说话人角色(speaker role)组件。在实验中,每个会议参与者都有不同的角色,例如程序经理,工业设计师。对于每个角色,我们训练一个以将其表示为固定长度的向量
r
p
,
1
≤
p
≤
P
r_p,1≤p≤P
rp,1≤p≤P,其中
P
P
P是角色的数量。事实证明,这样的角色/人的分布表示对于情感分析很有用。此向量被附加到说话人对应讲话的嵌入中(第3.1.2节)。根据第4.5节中的结果,说话人角色的矢量表示在提高摘要性能方面起着重要作用。
如果在实际中可以使用更丰富的数据,则可以扩展此想法为:
- 如果有参与者的组织结构图,我们可以将参与者(例如经理和开发人员)之间的关系的表示形式添加到网络中。
- 如果有一组参与者池,则每个参与者都可以拥有一个个人矢量,用作用户画像,并随着收集有关该用户的更多数据而演变。
3.1.2 分层Transformer
(1)Transformer
一个transformer block由一个多头注意力层和一个前馈层组成,两者均包含残差的层归一化:
L
a
y
e
r
N
o
r
m
(
x
+
L
a
y
e
r
(
x
)
)
LayerNorm(x+Layer(x))
LayerNorm(x+Layer(x)),其中
L
a
y
e
r
Layer
Layer可以是注意力层或前馈层。
由于注意力机制与位置无关,因此我们将位置编码附加到输入向量上:
P
E
(
i
,
2
j
)
=
s
i
n
(
i
/
1000
0
2
j
d
)
(1)
PE_{(i,2j)}=sin(i/10000^{\frac{2j}{d}})\tag{1}
PE(i,2j)=sin(i/10000d2j)(1)
P
E
(
i
,
2
j
+
1
)
=
c
o
s
(
i
/
1000
0
2
j
d
)
,
(2)
PE_{(i,2j+1)}=cos(i/10000^{\frac{2j}{d}}),\tag{2}
PE(i,2j+1)=cos(i/10000d2j),(2)
其中
P
E
(
i
,
j
)
PE_{(i,j)}
PE(i,j)代表输入序列中第
i
i
i个单词的第
j
j
j个维度的位置编码。我们选择正弦函数,因为它们可以在推理过程中扩展到任意输入长度。
总之,在
n
n
n个输入嵌入的序列上的transformer block可以生成与输入尺寸相同的
n
n
n个输出嵌入。因此,多个transformer block可以顺序堆叠以形成transformer网络:
T
r
a
n
s
f
o
r
m
e
r
(
{
x
1
,
.
.
.
,
x
n
}
)
=
{
y
1
,
.
.
.
,
y
n
}
(3)
Transformer(\{x_1,...,x_n\})=\{y_1,...,y_n\}\tag{3}
Transformer({x1,...,xn})={y1,...,yn}(3)
(2)Long transcript problem
由于传统transformer具有注意力机制,因此其计算复杂度在输入长度上是二次方的。因此,它很难处理很长的序列,例如5000个字符。但是,会议记录通常很长,由数千个字符组成。
我们注意到,会议具有自然的多轮结构,并具有合理的轮数,例如AMI数据集中每个会议平均289轮。而且每轮的字符数量比整个会议的字符数量少得多。因此,我们采用two-level transformer结构来编码会议记录。
(3)Word-level Transformer
Word-level Transformer在会议中处理一轮的字符序列。我们使用可训练的嵌入矩阵
D
\mathcal D
D在一轮中对每个字符进行编码。因此,第
i
i
i轮中的第
j
j
j个字符
w
i
,
j
w_{i,j}
wi,j与固定长度向量
D
(
w
i
,
j
)
=
g
i
,
j
\mathcal D(w_{i,j})=g_{i,j}
D(wi,j)=gi,j关联。为了合并语法和语义信息,我们还训练了两个嵌入矩阵来表示词性(POS)和实体(ENT)标签。因此,字符
w
i
,
j
w_{i,j}
wi,j由矢量
x
i
,
j
=
[
g
i
,
j
;
P
O
S
i
,
j
;
E
N
T
i
,
j
]
x_{i,j}=[g_{i,j};POS_{i,j};ENT_{i,j}]
xi,j=[gi,j;POSi,j;ENTi,j]表示。请注意,我们在序列之前添加了特殊记号
w
i
,
0
=
[
B
O
S
]
w_{i,0} = [BOS]
wi,0=[BOS]来表示该轮的开始。然后,我们将word-level Transformer的输出表示如下:
W
o
r
d
−
T
r
a
n
s
f
o
r
m
e
r
(
{
x
i
,
0
,
.
.
.
,
x
i
,
L
i
}
)
=
{
x
i
,
0
W
,
.
.
.
,
x
i
,
L
i
W
}
Word-Transformer(\{x_{i,0},...,x_{i,L_i}\})=\{x^{\mathcal W}_{i,0},...,x^{\mathcal W}_{i,L_i}\}
Word−Transformer({xi,0,...,xi,Li})={xi,0W,...,xi,LiW}
(4)Turn-level Transformer
Turn-level transformer在一次会议中处理所有m轮的信息。为了表示第
i
i
i轮,我们采用了word-level Transformer的特殊令牌[BOS]的输出嵌入
x
i
,
0
W
x^W_{i,0}
xi,0W。此外,我们将其与说话人的角色向量
p
i
p_i
pi拼接起来。因此, turn-level transformer的输出为:
T
u
r
n
−
T
r
a
n
s
f
o
r
m
e
r
(
{
[
x
1
,
0
W
;
p
1
]
,
.
.
.
,
[
x
m
,
0
W
;
p
m
]
}
)
=
{
x
1
T
,
.
.
.
,
x
m
T
}
Turn-Transformer(\{[x^{\mathcal W}_{1,0};p_1],...,[x^{\mathcal W}_{m,0};p_m]\})=\{x^{\mathcal T}_1,...,x^{\mathcal T}_m\}
Turn−Transformer({[x1,0W;p1],...,[xm,0W;pm]})={x1T,...,xmT}
3.2 解码器
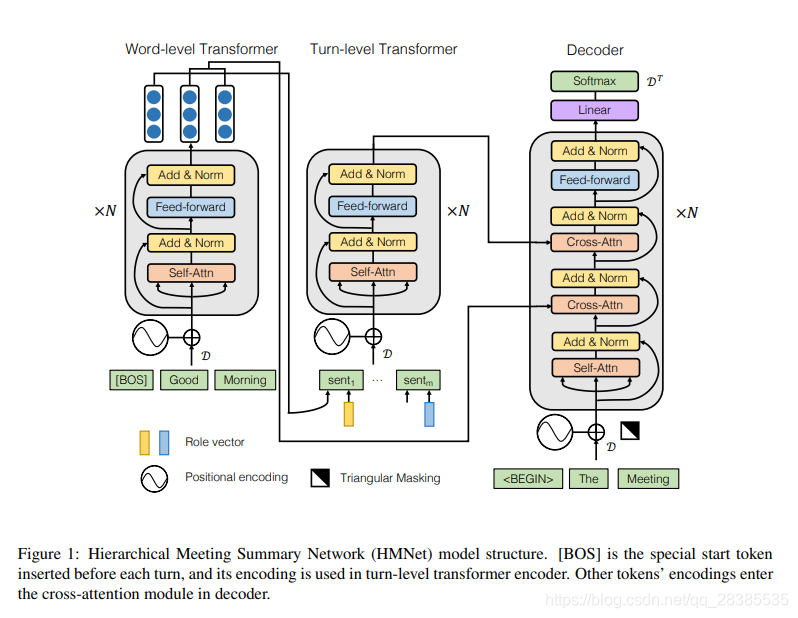
解码器是生成摘要字符的transformer。解码器transformer的输入包含
k
−
1
k-1
k−1个先前生成的摘要字符
y
^
1
,
.
.
.
,
y
^
k
−
1
\hat y_1,...,\hat y_{k-1}
y^1,...,y^k−1。每个字符由一个向量表示,该向量使用与编码器相同的嵌入矩阵
D
(
y
^
i
)
=
g
i
\mathcal D(\hat y_i)=g_i
D(y^i)=gi。
解码器transformer使用下三角形MASK,以防止模型查看将来的字符。而且,transformer block包括两个交叉注意力层。经过自注意力之后,嵌入首先使用token-level的输出
{
x
i
,
j
W
}
i
=
1
,
j
=
1
m
,
L
i
\{x^{\mathcal W}_{i,j}\}^{m,L_i}_{i=1,j=1}
{xi,jW}i=1,j=1m,Li,然后使用turn-level的输出
{
x
i
T
}
i
=
1
m
\{x^{\mathcal T}_i\}^m_{i=1}
{xiT}i=1m,每个注意力后接层归一化。这使得模型在每个推理步骤以不同的比例关注输入的不同部分。
解码器transformer的输出表示为:
D
e
c
o
d
e
r
−
T
r
a
n
s
f
o
r
m
e
r
(
{
g
1
,
.
.
.
,
g
k
−
1
}
)
=
{
v
1
,
.
.
.
,
v
k
−
1
}
Decoder-Transformer(\{g_1,...,g_{k-1}\})=\{v_1,...,v_{k-1}\}
Decoder−Transformer({g1,...,gk−1})={v1,...,vk−1}
为了预测下一个令牌
y
^
k
\hat y_k
y^k,我们重用嵌入矩阵
D
\mathcal D
D的权重,将
v
k
−
1
v_{k-1}
vk−1解码为词汇表上的概率分布:
P
(
y
^
k
∣
y
^
<
k
,
X
)
=
s
o
f
t
m
a
x
(
v
k
−
1
D
T
)
(4)
P(\hat y_k|\hat y_{\lt k},X)=softmax(v_{k-1}\mathcal D^T)\tag{4}
P(y^k∣y^<k,X)=softmax(vk−1DT)(4)
我们在图1中说明了分层会议摘要网络(HMNet)。
(1)Training
在训练过程中,我们的目标是最小化交叉熵:
L
(
θ
)
=
−
1
n
∑
k
=
1
n
l
o
g
P
(
y
k
∣
y
<
k
,
X
)
(5)
L(\theta)=-\frac{1}{n}\sum^n_{k=1}log~P(y_k|y_{\lt k},X)\tag{5}
L(θ)=−n1k=1∑nlog P(yk∣y<k,X)(5)
我们在解码器训练中使用teacher-forcing,即解码器将真实的摘要字符作为输入。
(2)Inference
在推理过程中,我们使用集束搜索来选择最佳候选者。搜索从特殊令牌
<
B
E
G
I
N
>
<BEGIN>
<BEGIN>开始。我们采用了常用的三元blocking功能:在波束搜索期间,如果候选单词会创建一个在先前生成的波束序列中已经存在的三元组,则将单词的概率强制设置为0。最后 ,我们选择每个字符的平均对数概率最高的摘要。
3.3 预训练
由于会议摘要数据的可用性有限,我们提出利用新闻领域的摘要数据对HMNet进行预训练。这可以热启动摘要任务中的模型参数。但是,新闻文章的结构与会议记录非常不同。因此,我们将新闻文章转换为会议格式。
我们将
M
M
M篇新闻文章合并为一次
M
M
M人会议,并将每个句子作为一轮。文章
i
i
i中的句子被认为是第
i
i
i个说话人的讲话,被称为
[
D
a
t
a
s
e
t
−
i
]
[Dataset-i]
[Dataset−i]。 例如,对于每个XSum会议,说话人的名字是
[
X
S
u
m
−
1
]
[XSum-1]
[XSum−1]至
[
X
S
u
m
−
M
]
[XSum-M]
[XSum−M]。为了模拟实际的会议场景,我们在这些伪会议中随机打乱了所有轮次。目标摘要是
M
M
M个摘要的串联。
我们使用大量新闻摘要数据(请参见第4.1节中的详细信息)对HMNet模型进行预训练,然后根据实际的会议摘要任务对其进行微调。

















 5032
5032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









