






摘要
虽然teacher forcing已成为神经机翻译的主要训练框架,但它通常只能基于过去的信息上进行预测,因此缺乏对未来信息的全局规划。为了解决这个问题,我们在训练期间将另一个被称为seer的解码器引入到编码器 - 解码器框架中,该解码器包含目标预测中的未来信息。同时,我们强制传统的解码器通过知识蒸馏来建模seer解码器的行为。通过这种方式,在测试时,传统的解码器可以在没有seer参与的情况下像其一样执行。在Chinese-English,English-German和English-Romanian翻译任务上的实验结果显示出我们的方法显著优于基线,并在更大的数据集上具有更大的改进。此外,实验还证明了与对抗学习和L2正规化相比,知识蒸馏能更好地将知识从Seer解码器转移到传统解码器。
1.介绍
神经机翻译(NMT)取得了巨大的成功,并且最近引起越来越多人的关注。大多数NMT模型都是基于注意力的编码器-解码器框架,该框架假设源和目标语言之间存在通用的语义空间。编码器将源句子编码到公共空间以获得其语义,并且解码器将源带入到目标空间以生成相应的目标单词。当需要生成目标字符时,解码器都需要检索源信息,然后解码到目标字符中。确保该框架有效的基本原则是源句所具有的信息和目标句是等价的。因此,可以认为翻译过程将源信息分解为不同的部分,然后根据双语上下文将每个部分转换为适当的目标字符。通过编码源句中的所有信息,则会生成整个翻译。
神经机器翻译模型通常通过最大似然估计(MLE)训练,并且数据操作形式被称为teacher forcing。teacher forcing策略使用历史真实目标词作为上下文来进行逐步预测,并强制预测的分布接近真实目标词的0-1分布。以这种方式,来训练预测序列接近真实序列。从信息分配的角度来看,teacher forcing的功能是教导翻译模型如何在最大概率下从源中分解信息并从源信息计算出真实目标词。
然而,teacher forcing只能为单步预测提供历史真实目标词,因此缺乏对未来的全局规划。这将导致陷入局部最优,特别是当下一个预测与未来高度相关时。此外,随着翻译长度的增加,之前的预测错误将被累积并影响后来的预测。这是NMT模型不能在训练期间一直生成真实序列的重要原因。因此,通过获取关于目标词的未来知识是可能达到全局最优的。但不幸的是,真实序列只能在训练期间获得,我们不能在测试中推断未来的序列。
为了解决这个问题,我们将一个额外的seer解码器带入到编码器-解码器框架中以集成未来的信息。在训练期间,seer解码器用于指导传统解码器的行为,同时在翻译模型测试时仅用传统解码器推断,而不引入任何额外的参数和计算成本。具体地,传统解码器仅获取用于预测下一个字符的过去信息,而seer解码器同时具有过去和未来的真实字符,来进行下一个字符预测。两个解码器都都通过MLE训练来生成真实目标词,同时传统的解码器通过知识蒸馏强迫建模seer解码器的行为。通过这种方式,在测试时,传统的解码器可以像seer解码器一样执行。
我们两个小型数据集((Chinese-English和English-Romanian)和两个大数据集(Chinese-English和EnglishGerman)进行了实验,实验结果表明,我们的方法可以在所有数据集上优于强基线。此外,我们还比较了知识迁移的不同机制,发现知识蒸馏比对抗学习和L2正则化更有效。据我们所知,本文是第一个在机器翻译中同时探索三种机制影响的工作。
2.方法
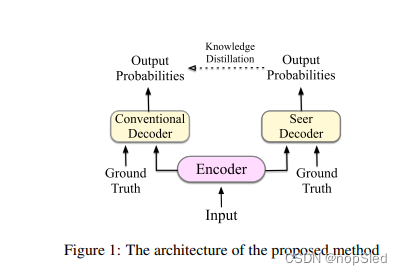
我们在Transformer的基础上介绍了我们的方法。我们的模型包括三个组件:编码器,传统解码器和seer解码器。该结构如图1所示。编码器和传统的解码器使用与Transformer相同的组件进行构建。Seer解码器将未来的真实目标序列信息集成到自注意力表示中,并以自注意力表示作为query来计算源隐藏状态的cross-attention。在训练期间,编码器由两个解码器共享,两个解码器都执行预测以生成真实目标字符。传统解码器的行为由seer解码器通过知识蒸馏引导。如果传统解码器可以预测与seer解码器类似的分布,则认为传统的解码器能像seer解码器一样执行。然后我们只能使用传统解码器进行测试。
编码器和传统解码器的细节可以从Vaswani et al. (2017) 获得。假设输入序列是
x
=
(
x
1
,
.
.
.
,
x
j
)
\textbf x=(x_1,...,x_j)
x=(x1,...,xj),真实目标序列是
y
∗
=
(
y
1
∗
,
.
.
.
,
y
I
∗
)
y^*=(y^*_1,...,y^*_I)
y∗=(y1∗,...,yI∗),生成的翻译是
y
=
(
y
1
,
.
.
.
,
y
I
)
y=(y_1,...,y_I)
y=(y1,...,yI)。在下面章节中,我们将详细描述seer解码器的及其训练。
2.1 The Seer Decoder
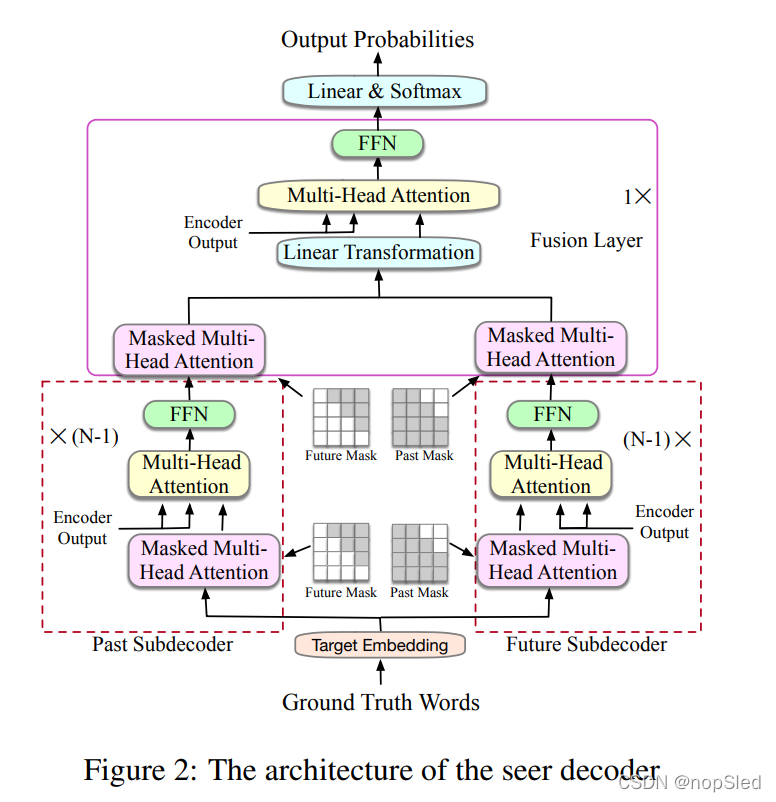
虽然我们向seer解码器中带入了未来真实单词,但我们不会告诉它下一个要生成的真实词,以防它只会学习复制操作,而不会学习如何预测一个单词。考虑到效率,seer解码器并未使用一个解码器整合过去和未来的真实信息,而是使用两个单独的子解码器。因此,seer解码器由三个组件组成:历史子码器,未来子解码器和融合层。seer解码器的架构如图2中所示。历史和未来子解码器分别用于将过去和未来的真实信息分解为隐藏状态,并且在融合层融合过去和未来的输出,然后分析并计算要预测字符的最终隐藏状态。
历史子解码器由
N
−
1
N-1
N−1个层组成,每层具有三个子层,一次是multihead-attention层,cross-attention层和feed-forward network (FNN)层,这与Transformer相同。多头注意力层接受整个真实序列作为输入,并应用屏蔽矩阵
M
p
\textbf M_p
Mp,以确保只有过去的真实单词参与注意力计算。具体地,为了生成第
i
i
i个目标词,屏蔽矩阵
M
p
\textbf M_p
Mp中的相应位置处的屏蔽向量
y
i
∗
,
y
i
+
1
∗
,
.
.
.
,
y
I
∗
y^*_i,y^*_{i+1},...,y^*_I
yi∗,yi+1∗,...,yI∗被屏蔽。然后在cross-attention层和FFN层之后,历史子解码器输出一系列隐藏状态,其隐藏矩阵表示为
H
p
\textbf H_p
Hp。
除屏蔽矩阵之外,未来子解码器与历史子解码器具有相同的结构。未来子解码器同样以整个真实序列作为输入,且使用不同的屏蔽矩阵
M
f
\textbf M_f
Mf来保留未来真实信息。为了生成第
i
i
i个目标字,
M
f
\textbf M_f
Mf中的相应伟指出的屏蔽向量
y
1
∗
,
.
.
.
,
y
i
−
1
∗
,
y
i
∗
y^*_1,...,y^*_{i-1},y^*_i
y1∗,...,yi−1∗,yi∗被屏蔽。未来子解码器生成的隐藏矩阵表示为
H
f
\textbf H_f
Hf。
融合层由四个子层组成:多头注意力层,线性层,cross-attention层和FFN子层。除了线性层外,其余三个层与Transformer具有相同的工作方式。多头注意力层使用屏蔽矩阵
M
p
\textbf M_p
Mp和
M
f
\textbf M_f
Mf分别对过去和未来子解码器的输出进行编码,并且其输出的隐藏矩阵分别表示为
H
p
′
\textbf H'_p
Hp′和
H
f
′
\textbf H'_f
Hf′。然后,我们倒转
H
f
′
\textbf H'_f
Hf′中向量的顺序以获得
H
f
′
′
\textbf H''_f
Hf′′,因此
H
p
′
\textbf H'_p
Hp′和
H
f
′
′
\textbf H''_f
Hf′′中的相同索引可以对应到同一个预测。假设
H
f
′
=
[
h
f
1
′
;
h
f
2
′
;
.
.
.
;
h
f
I
′
]
\textbf H'_f=[\textbf h'_{f1};\textbf h'_{f2};...;\textbf h'_{fI}]
Hf′=[hf1′;hf2′;...;hfI′],然后它的逆转矩阵是
H
f
′
′
=
[
h
f
I
′
;
.
.
.
;
h
f
2
′
;
h
f
1
′
]
\textbf H''_f=[\textbf h'_{fI};...;\textbf h'_{f2};\textbf h'_{f1}]
Hf′′=[hfI′;...;hf2′;hf1′]。线性层通过如下线性变换来融合
H
p
′
\textbf H'_p
Hp′和
H
f
′
′
\textbf H''_f
Hf′′:
A
=
W
p
H
p
′
+
W
f
H
f
′
′
(1)
\textbf A=\textbf W_p\textbf H'_p+\textbf W_f\textbf H''_f\tag{1}
A=WpHp′+WfHf′′(1)
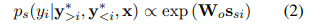
3.训练




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









