






 本文提出了VRBot,一种端到端的医疗对话生成模型,用于在有限的标注数据下生成准确且解释性强的响应。VRBot利用变分推理方法处理患者状态和医生动作的潜在变量,结合先验和推理网络进行状态和动作的追踪。模型通过上下文编码器、状态追踪器和策略网络进行响应生成,同时考虑对话历史和外部医学知识。实验表明,VRBot在多个数据集上优于现有基线,证明了其在医疗对话生成任务中的有效性。
本文提出了VRBot,一种端到端的医疗对话生成模型,用于在有限的标注数据下生成准确且解释性强的响应。VRBot利用变分推理方法处理患者状态和医生动作的潜在变量,结合先验和推理网络进行状态和动作的追踪。模型通过上下文编码器、状态追踪器和策略网络进行响应生成,同时考虑对话历史和外部医学知识。实验表明,VRBot在多个数据集上优于现有基线,证明了其在医疗对话生成任务中的有效性。
摘要
医疗对话生成旨在提供自动和准确的响应,以帮助医生以高效的方式给出诊断和治疗建议。在医疗对话中,有两个关键特征与响应生成有关:患者状态(例如症状,药物)和医师的行为(例如诊断,治疗)。在医疗方案中,由于高成本和隐私要求,通常不可能获得大规模的人工标注数据。因此,当前的医疗对话生成方法通常不会显式考虑患者状态和医生动作,而是专注于隐式表示。
我们为医疗对话生成提出了一种端到端的变分推理方法。为了能够处理有限的标注数据,我们将患者状态和医生动作作为具有类别先验的潜在变量,以分别进行患者状态追踪以及医生策略学习。我们提出了一种变分贝叶斯生成方法,以在患者状态和医师动作上近似后验分布。我们使用有效的随机梯度变分贝叶斯估计器来优化推导的变分下界,其中使用了2阶段collapsed推理方法来减少模型训练期间的偏差。另外,我们提出了一个由动作分类器和两个推理检测器组成的医生策略网络,以增强推理能力。我们在从医疗平台收集的三个数据集上进行实验。实验结果表明,就客观和主观评估指标而言,该提出的方法优于最先进的基线。我们的实验还表明,我们提出的半监督推理方法与医生策略学习的全监督学习基准相当。
1.介绍

越来越多的对话框架被用来将人们与信息联系起来,在满足开放领域的信息需求的同时,还要支持高度专业化的垂直领域。我们的重点是在医疗领域中寻求对话信息。在临床治疗期间,对话医学系统可以作为医生的助手,以帮助对患者的需求产生响应,例如,查询症状,诊断并开药或治疗。智能医疗对话系统(MDS)能够减轻医生的工作压力。给定一个对话上下文,先前关于MDS的工作主要集中于生成准确的诊断。几乎没有工作考虑多轮医疗对话生成的任务,通过利用大规模的医学知识来提供适当的医疗响应。
有两个在对话系统中与临床决策支持(CDS)相关的关键特征:患者状态(例如,症状,药物等)和医生动作(例如,治疗,诊断等)。这两个特征使MDS比其他知识密集型对话方案更加复杂。与面向任务的对话系统(TDS)类似,可以将医疗对话生成(MDG)过程分解为3个阶段:(1)患者状态追踪(PST):在编码患者的描述后,MDS将追踪患者的生理状况,即对话上下文中的患者状态;(2)医生策略学习(PPL):给定患者的状态和话语,MDS会生成医生的动作以嵌入到响应中;(3)医疗响应生成(MRG):MDS根据检测到的状态和动作以连贯的句子做出反应。
图1显示了感染科的一个医疗对话的样例。左侧部分列出了对话过程,而右侧则表示对话期间的患者状态和医生动作。首先,第一轮患者分享了他们的症状,即发烧,食欲不振和咳嗽,以作为患者状态;医生询问患者是否有其他症状,即疲劳,夜汗和干咳,以反映第二轮的医师动作。随着对话的发展,各状态和动作都不同。在最后一轮,医生的动作是开出药物:异烟肼,利福平,吡嗪酰胺,乙胺丁醇。
端到端的MDG解决方案的开发面临许多挑战:(1)大多数TDS需要大量的人工标注数据来预测显式的对话状态。在医疗对话中,标注者需要医学专业知识来标注数据。出于隐私原因,大规模人工标注中间状态是有问题的。因此,很少有TDS方法可以直接应用于MRG。(2)现有的MDG方法对领域的语义理解有限,这使得在医学环境中很难产生知识丰富的响应。(3)为了帮助患者或医生了解为什么MDG系统会生成这样的响应,具有指示性和可解释的信息是必不可少的,这是大多数TDS研究所忽略的。
为了应对这些挑战,我们提出了VRBot,能够对MRG执行变分推理。受TDS方法的启发,VRBot包含患者状态追踪器和医生策略网络,分别检测患者状态和医生动作。与以前的从大量人工标注的观测变量中进行学习的工作不同,VRBot将患者状态和医生动着视为由变分贝叶斯方法推出的双重潜在变量。我们采用随机梯度变分贝叶斯(SGVB)估计器有效地近似后验推断。为了减轻SGVB估计期间的偏差问题,我们提出了一种2阶段的collapsed推理方法,以迭代地近似状态和动作的后验分布。
为了解决响应生成期间语义理解有限的问题,我们采用了如下方法。医生策略网络包括一个动作分类器,将医生的行为分为若干动作类别,以及两个推理组件,分别为上下文推理检测器和图推理检测器,分别通过对话上下文和医学知识图谱来推断显式动作关键字。通过显式的患者状态,医生行动和多跳推理的序列,VRBot能够为其医学对话生成结果提供高度解释性。
为了评估VRBot的有效性,我们收集了一个基于医疗知识的对话数据集,KaMed。KaMed包含了60000多个医疗对话,其中具有5628个实体(例如,哮喘和阿托品)。使用KAMED和其他两个MDG基准数据集,我们发现VRBot使用有限的标记数据,就优于MDG的最先进基准。因此,给定大规模未标注的医疗语料,VRBot可以准确地追踪到患者的生理状况,并通过预测适当的治疗和诊断来提供信息丰富和连贯的响应。我们还发现,VRBot与其他MDG基准相比能够提供更可解释的响应生成过程。
我们的贡献如下:(1)我们提出了一个名为VRBot的端到端医疗响应生成模型。据我们所知, VRBot是第一个同时将状态和动作作为TDS中的潜在变量建模的框架。(2)我们设计了一个混合策略网络,该网络包含上下文检测器和图检测器,该检测器使VRBot能够同时根据对话信息和外部知识预测医生动作。(3)我们表明,即使有很少或没有人工标注的数据,VRBot也可以显式地跟踪患者状态和医生动作。(4)我们发布了KaMed,这是一个具有外部知识的大规模医学对话数据集。(5)基准数据集的实验表明,VRBot能够比最新的基线产生信息更丰富,更准确和更可解释的响应。
2.相关工作
Medical dialogue systems。MDS的先前方法是基于TDS建模的,同时遵循患者表达其症状的框架。Wei et al. 提出使用强化学习来学习用于自动诊断的对话策略。Lin et al.建立了一个症状图,以建模症状之间的关联,以提高症状诊断的性能。Xu et al.考虑使用强化学习显式地考虑症状和疾病的共现概率。Xia et al.使用互信息奖赏和生成对抗网络改进这项工作。同时,已经探索了各种方法,以提高对医疗对话历史的理解能力,包括症状提取,医疗槽填充和医疗信息提取。 Chen et al.研究用于预测响应实体的预训练模型的性能。Chen et al. 收集一个由数百万对话组成的数据集,但没有显式考虑学习对话管理,因为没有人工标注的标签。
目前,还没有工作能从大规模的未标注语料库中显式学习对话策略,从而极大地限制了医疗对话系统的应用。
Dialogue state tracking。对话状态追踪对TDS起着重要作用。目前已经提出了基于条件随机场和深度神经网络的方法来跟踪模块化TDS中的状态。最近,端到端的TDS引起了很多关注。对于非面向任务的对话,, Serban et al. 和Chen
et al. 提出具有隐式状态表示的生成方法,这很难区分医学概念。对话状态也被表示为对话上下文中的一系列关键字。Jin et al. 和 Zhang et al. 提出半监督的生成模型以利用未标注的数据来提高状态追踪性能。Liang et al. 提出一个编码器-解码器训练框架MOSS,以整合来自各种中间对话系统模块的有监督信息。MOSS在模型训练期间利用不完整的监督信息。但是,现有的方法无法产生信息丰富的响应,并且无法解决对话agent的语义推理能力。据我们所知,还没有方法同时建模小样本环境下的状态和动作。
在MDG场景中,学习医生的动作与状态追踪一样重要。 与[17、29、65]相比,我们的模型能够同时推断缺失状态和动作。
Knowledge-grounded conversations。基于知识的对话任务(KGC)是根据准确的背景知识来生成响应。该任务可以根据背景知识的格式(即结构化KGC和非结构化的KGC)将其归为两类。前者侧重利用知识三元组或知识图,后者则以段落文本为条件。对于结构化的KGC,Liu et al.利用神经知识扩散模块编码知识三元组以预测相关实体。Liu et al. 增强知识图,以集成到对话上下文中进行开放领域的对话。Tuan et al.评估模型在构造的转移矩阵上使用马尔可夫链来推理多个跳路径的能力,以便模型可以进行零样本更新。Xu et al.将先验的对话转移信息表示为知识图,并学习一个基于图的对话策略,以生成连贯和可控的响应。Lei et al. 构建一个user-item-attribute知识图,并巧妙地将对话策略学习作为图上的路径推理。
与大多数从开放领域知识库中选择知识的结构化KGC方法不同,MDG旨在探索使用专业的医学领域知识图,研究从患者状态转移到医生动作的多跳知识路径转移。
3.方法
3.1 问题定义
Medical dialogue systems。给定一个
T
T
T轮对话,医学会话
d
d
d由一系列语句组成,即,
d
=
{
U
1
,
R
1
,
U
2
,
R
2
,
.
.
.
,
U
T
,
R
T
}
d=\{U_1,R_1,U_2,R_2,...,U_T,R_T\}
d={U1,R1,U2,R2,...,UT,RT},其中
U
t
U_t
Ut和
R
t
R_t
Rt分别是患者描述和虚拟医生的响应。在第
t
t
t轮中,给定患者的语句
U
t
U_t
Ut和上一轮医生的响应
R
t
−
1
R_{t-1}
Rt−1,对话系统会生成一个响应
R
t
R_t
Rt。令
∣
U
t
∣
|U_t|
∣Ut∣作为
U
t
U_t
Ut中的单词数,我们定义
U
t
=
(
U
t
,
1
,
U
t
,
2
,
.
.
.
,
U
t
,
∣
U
t
∣
)
U_t=(U_{t,1},U_{t,2},...,U_{t,|U_t|})
Ut=(Ut,1,Ut,2,...,Ut,∣Ut∣)作为一个单词序列。完整的词表被定义为
V
\mathcal V
V。
K
K
K表示医学对话系统中的外部知识库,其中
K
K
K中的每个三元组分别表示头实体,关系和尾实体。与[53]相同,我们通过将
K
K
K中具有重叠实体的三元组进行链接来构造一个知识图
G
g
l
o
b
a
l
G^{global}
Gglobal。我们假设每个实体都被归类为一个实体类型,其中实体类型有
E
t
y
p
e
=
{
d
i
s
e
a
s
e
,
s
y
m
p
t
o
m
s
,
m
e
d
i
c
i
n
e
s
,
t
r
e
a
t
m
e
n
t
s
}
E_{type}=\{disease, symptoms, medicines, treatments\}
Etype={disease,symptoms,medicines,treatments}。
我们将VRBot视为具有参数
θ
\theta
θ的模型。给定对话上下文,响应和知识图
G
g
l
o
b
a
l
G^{global}
Gglobal,我们旨在最大化VRBot在
d
d
d上的概率分布:
∏
t
=
1
T
p
θ
(
R
t
∣
R
t
−
1
,
U
t
,
G
g
l
o
b
a
l
)
.
(1)
\prod^T_{t=1}p_{\theta}(R_t|R_{t-1},U_t,G^{global}).\tag{1}
t=1∏Tpθ(Rt∣Rt−1,Ut,Gglobal).(1)
Patient states and physician actions。基于文本跨度的对话状态跟踪器具有结构简单且解释性高的双重优势。因此,在第
t
t
t轮中,我们将文本跨度
S
t
S_t
St(即单词序列)定义为对历史语句及响应进行总结的患者状态(即,
U
1
,
R
1
,
,
.
.
.
,
R
t
−
1
,
U
t
U_1,R_1,,...,R_{t-1},U_t
U1,R1,,...,Rt−1,Ut)。然后,我们将
S
t
S_t
St作为在知识库中搜索的约束。与
S
t
S_t
St类似,我们还使用文本跨度
A
t
A_t
At代表医生在第
t
t
t轮的动作,其对医生的策略进行了总结,例如诊断,药品或治疗。给定
S
t
S_t
St,
A
t
A_t
At通过策略学习过程进行预测。因此,MDG中的任务变成了每个轮次对两个连续文本跨度(
S
t
S_t
St和
A
t
A_t
At)进行生成的问题。
由于文本跨度也有助于提高响应生成的性能,因此每个轮次生成
S
t
S_t
St和
A
t
A_t
At是MDG中的关键组件。在本文中,MDG的问题分解为三个连续的步骤:(1)生成状态跨度
S
t
S_t
St;(2)生成动作跨度
A
t
A_t
At;(3)生成响应
R
t
R_t
Rt。
Variational Bayesian generative model。在MDG中,对大量患者的中间状态和医师的动作进行标注是不切实际的。因此,在VRBot中,我们将
S
t
S_t
St和
A
t
A_t
At视为贝叶斯生成模型的潜在变量,因此我们将等式1重新定义为:
∏
t
=
1
T
∑
S
t
,
A
t
p
θ
g
(
R
t
∣
R
t
−
1
,
U
t
,
S
t
,
A
t
)
⋅
p
θ
s
(
S
t
)
⋅
p
θ
a
(
A
t
)
,
(2)
\prod^T_{t=1}\sum_{S_t,A_t}p_{\theta_g}(R_t|R_{t-1},U_t,S_t,A_t)\cdot p_{\theta_s}(S_t)\cdot p_{\theta_a}(A_t),\tag{2}
t=1∏TSt,At∑pθg(Rt∣Rt−1,Ut,St,At)⋅pθs(St)⋅pθa(At),(2)
其中,
p
θ
g
(
R
t
∣
R
t
−
1
,
U
t
,
S
t
,
A
t
)
p_{\theta_g}(R_t|R_{t-1},U_t,S_t,A_t)
pθg(Rt∣Rt−1,Ut,St,At)通过使用一个相应生成器来计算,并且
p
θ
s
(
S
t
)
p_{\theta_s}(S_t)
pθs(St)和
p
θ
a
(
A
t
)
p_{\theta_a}(A_t)
pθa(At)分别通过一个患者状态追踪器和医生策略网络来估计。
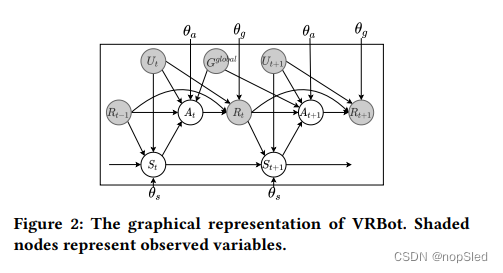
VRBot的图形表示如图2所示,其中阴影部分的结点表示观测变量,白色结点表示潜在变量。我们看到两个相邻状态之间存在依赖关系。在时刻
𝑡
𝑡
t,
S
t
S_t
St根据先前的状态
S
t
−
1
S_{t-1}
St−1,响应
R
t
−
1
R_{t-1}
Rt−1和语句
U
t
U_t
Ut来得出。随后,使用
S
t
S_t
St,
R
t
−
1
R_{t−1}
Rt−1,
U
t
U_t
Ut和
G
g
l
o
b
a
l
G^{global}
Gglobal来推断
A
t
A_t
At。因此,我们将
p
θ
s
(
S
t
)
p_{\theta_s}(S_t)
pθs(St)和
p
θ
s
(
A
t
)
p_{\theta_s}(A_t)
pθs(At)计算为:
p
θ
s
(
S
t
)
≜
p
θ
s
(
S
t
∣
S
t
−
1
,
R
t
−
1
,
U
t
)
(
p
r
i
o
r
s
t
a
t
e
t
r
a
c
k
e
r
)
,
p
θ
a
(
A
t
)
≜
p
θ
a
(
A
t
∣
S
t
,
R
t
−
1
,
U
t
,
G
g
l
o
b
a
l
)
(
p
r
i
o
r
p
o
l
i
c
y
n
e
t
w
o
r
k
)
,
(3)
\begin{array}{cc} p_{\theta_s}(S_t)\triangleq p_{\theta_s}(S_t|S_{t-1},R_{t-1},U_t)(prior~state~tracker),\\ p_{\theta_a}(A_t)\triangleq p_{\theta_a}(A_t|S_t,R_{t-1},U_t,G^{global})(prior~policy~network), \end{array}\tag{3}
pθs(St)≜pθs(St∣St−1,Rt−1,Ut)(prior state tracker),pθa(At)≜pθa(At∣St,Rt−1,Ut,Gglobal)(prior policy network),(3)
其中
θ
s
\theta_s
θs和
θ
a
\theta_a
θa是参数,并且在对话开始时,一个固定的初始值被赋予
S
0
S_0
S0。在VRBot中,我们提出了两个prior networks,以估计等式3中的概率分布。最终,我们用参数
θ
g
\theta_g
θg从
p
θ
g
(
R
t
∣
R
t
−
1
,
U
t
,
S
t
,
A
t
)
p_{\theta_g}(R_t|R_{t-1},U_t,S_t,A_t)
pθg(Rt∣Rt−1,Ut,St,At)得到一个响应
R
t
R_t
Rt。
为了最大化等式2,我们需要估计后验分布
p
θ
(
S
t
,
A
t
∣
R
t
,
R
t
−
1
,
U
t
,
G
g
l
o
b
a
l
)
p_{\theta}(S_t,A_t|R_t,R_{t-1},U_t,G^{global})
pθ(St,At∣Rt,Rt−1,Ut,Gglobal)。然而,由于其复杂的后验期望估计,准确的后验分布非常难以计算。为了解决这个问题,我们引入了两个推理网络(即
q
ϕ
s
(
S
t
)
q_{\phi_s}(S_t)
qϕs(St)和
q
ϕ
s
(
A
t
)
q_{\phi_s}(A_t)
qϕs(At)),以分别近似
S
t
S_t
St和
A
t
A_t
At的后验分布:
q
ϕ
s
(
S
t
)
≜
q
ϕ
s
(
S
t
∣
S
t
−
1
,
R
t
−
1
,
U
t
,
R
t
)
(
i
n
f
e
r
e
n
c
e
s
t
a
t
e
t
r
a
c
k
e
r
)
,
q
ϕ
a
(
A
t
)
≜
q
ϕ
a
(
A
t
∣
S
t
,
R
t
−
1
,
U
t
,
R
t
)
(
i
n
f
e
r
e
n
c
e
p
o
l
i
c
y
n
e
t
w
o
r
k
)
,
(4)
\begin{array}{cc} q_{\phi_s}(S_t)\triangleq q_{\phi_s}(S_t|S_{t-1},R_{t-1},U_t,R_t)(inference~state~tracker),\\ q_{\phi_a}(A_t)\triangleq q_{\phi_a}(A_t|S_t,R_{t-1},U_t,R_t)(inference~policy~network), \end{array}\tag{4}
qϕs(St)≜qϕs(St∣St−1,Rt−1,Ut,Rt)(inference state tracker),qϕa(At)≜qϕa(At∣St,Rt−1,Ut,Rt)(inference policy network),(4)
其中
ϕ
s
\phi_{s}
ϕs和
ϕ
a
\phi{a}
ϕa是推理网络的参数。
Evidence lower bound (ELBO)。在第
t
t
t轮中,我们计算ELBO以同时优化先验和推理网络,如下所示:
l
o
g
p
θ
(
R
t
∣
R
t
−
1
,
U
t
,
G
g
l
o
b
a
l
)
≥
E
q
ϕ
s
(
S
t
−
1
)
[
E
q
ϕ
s
(
S
t
)
⋅
q
ϕ
a
(
A
t
)
[
R
t
∣
R
t
−
1
,
U
t
,
S
t
,
A
t
]
−
K
L
(
q
ϕ
s
(
S
t
)
∣
∣
p
θ
s
(
S
t
)
)
−
K
L
(
q
ϕ
a
(
A
t
)
∣
∣
p
θ
a
(
A
t
)
)
]
=
−
L
j
o
i
n
t
,
(5)
\begin{aligned} &log~p_{\theta}(R_t|R_{t-1},U_t,G^{global})\\ &\ge \mathbb E_{q_{\phi_s}(S_{t-1})}\bigg [\mathbb E_{q_{\phi_s}(S_t)\cdot q_{\phi_a}(A_t)}[R_t|R_{t-1},U_t,S_t,A_t]\\ &-KL(q_{\phi_s(S_t)||p_{\theta_s}(S_t)})-KL(q_{\phi_a}(A_t)||p_{\theta_a(A_t)})\bigg ]\\ &=-\mathcal L_{joint}, \end{aligned}\tag{5}
log pθ(Rt∣Rt−1,Ut,Gglobal)≥Eqϕs(St−1)[Eqϕs(St)⋅qϕa(At)[Rt∣Rt−1,Ut,St,At]−KL(qϕs(St)∣∣pθs(St))−KL(qϕa(At)∣∣pθa(At))]=−Ljoint,(5)
其中
E
(
⋅
)
\mathbb E(·)
E(⋅)是期望,而
K
L
(
⋅
∥
⋅
)
KL(·∥·)
KL(⋅∥⋅)表示KL散度。为了从
q
ϕ
s
(
S
t
−
1
)
q_{\phi_s}(S_{t-1})
qϕs(St−1)估计等式5,我们首先构建状态
S
t
−
1
q
S^q_{t-1}
St−1q,该状态是用于估计
p
θ
s
(
S
t
)
p_{\theta_s}(S_t)
pθs(St)和
q
ϕ
s
(
S
t
)
q_{\phi_s}(S_t)
qϕs(St)。然后,
S
t
p
S^p_t
Stp从
p
θ
s
(
S
t
)
p_{\theta_s}(S_t)
pθs(St)中获得,
S
t
q
S^q_t
Stq从
q
ϕ
s
(
S
t
)
q_{\phi_s}(S_t)
qϕs(St)中获得。我们使用
S
t
p
S^p_t
Stp和
S
t
q
S^q_t
Stq分别估算
p
θ
a
(
A
t
)
p_{\theta_a}(A_t)
pθa(At)和
p
ϕ
a
(
A
t
)
p_{\phi_a}(A_t)
pϕa(At),并从
q
ϕ
a
(
A
t
)
q_{\phi_a}(A_t)
qϕa(At)得到
A
t
q
A^q_t
Atq。最后,
p
θ
g
(
R
t
∣
⋅
)
p_{\theta_g}(R_t|·)
pθg(Rt∣⋅)会基于
S
t
q
S^q_t
Stq和
A
t
q
A^q_t
Atq生成
R
t
R_t
Rt。上述抽样过程如图3所示。
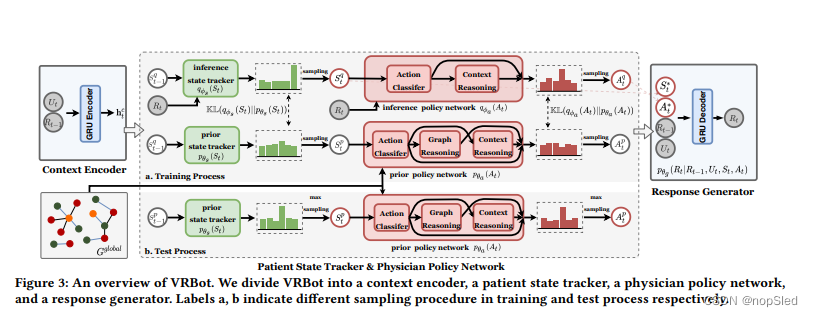
3.2 Context encoder
在第
𝑡
𝑡
t轮中,我们使用双向门控循环单元(GRU)来讲对话历史
(
R
t
−
1
,
U
t
)
(R_{t−1},U_t)
(Rt−1,Ut)编码为词一级的隐藏矢量列表
H
t
=
(
h
t
,
1
,
.
.
.
,
h
t
,
∣
R
t
−
1
∣
+
∣
U
t
∣
)
\textbf H_t=(\textbf h_{t,1},...,\textbf h_{t,|R_{t-1}|+|U_t|})
Ht=(ht,1,...,ht,∣Rt−1∣+∣Ut∣):
H
t
=
B
i
G
R
U
(
h
t
−
1
c
,
e
1
R
t
−
1
,
e
2
R
t
−
1
,
.
.
.
,
e
∣
R
t
−
1
∣
R
t
−
1
,
.
.
.
,
e
∣
U
t
∣
U
t
)
.
(6)
\textbf H_t=BiGRU(\textbf h^c_{t-1},\textbf e^{R_{t-1}}_1,\textbf e^{R_{t-1}}_2,...,\textbf e^{R_{t-1}}_{|R_{t-1}|},...,\textbf e^{U_t}_{|U_t|}).\tag{6}
Ht=BiGRU(ht−1c,e1Rt−1,e2Rt−1,...,e∣Rt−1∣Rt−1,...,e∣Ut∣Ut).(6)
其中
∣
R
t
−
1
∣
|R_{t−1}|
∣Rt−1∣和
∣
U
t
∣
|U_t|
∣Ut∣分别表示
R
t
−
1
R_{t-1}
Rt−1和
U
t
U_t
Ut中的单词数,
e
i
R
t
−
1
\textbf e^{R_{t−1}}_i
eiRt−1表示
R
t
−
1
R_{t-1}
Rt−1中的第
i
i
i个词的嵌入。从第
(
t
−
1
)
(t-1)
(t−1)轮的隐藏表示
h
t
−
1
c
\textbf h^c_{t-1}
ht−1c初始化,我们使用从
H
t
\textbf H_t
Ht中读取的最后一个隐藏状态
h
t
,
∣
R
t
−
1
∣
+
∣
U
t
∣
\textbf h_{t,|R_{t-1}|+|U_t|}
ht,∣Rt−1∣+∣Ut∣作为第
t
t
t轮的隐藏表示,即
h
t
c
\textbf h^c_t
htc。
3.3 Patient state tracker
由于我们将患者状态作为文本跨度,先验和推理状态追踪器均基于编码器-解码器框架。在编码过程中,我们使用GRU编码器编码
S
t
−
1
q
S^q_{t-1}
St−1q以获得
h
t
−
1
S
q
\textbf h^{S^q}_{t-1}
ht−1Sq。然后,我们将
h
t
−
1
S
q
\textbf h^{S^q}_{t-1}
ht−1Sq与
h
t
c
\textbf h^c_t
htc拼接在一起,以在第
t
t
t轮中推断先验状态分布
p
θ
s
(
S
t
)
p_{\theta_s}(S_t)
pθs(St)。在解码过程中,我们首先推断出患者状态的先验分布。我将
b
t
,
0
S
p
=
W
s
p
[
h
t
c
;
h
t
−
1
S
q
]
\textbf b^{S^p}_{t,0}=\textbf W^p_s[\textbf h^c_t; \textbf h^{S^q}_{t-1}]
bt,0Sp=Wsp[htc;ht−1Sq]作为解码器的初始隐藏表示,其中
W
s
p
\textbf W^p_s
Wsp是可学习的参数矩阵,
[
⋅
;
⋅
]
[·;·]
[⋅;⋅]表示矢量拼接。当解码的第
i
i
i个字符时,给定上一个字符嵌入
e
t
,
i
−
1
S
p
\textbf e^{S^p}_{t,i-1}
et,i−1Sp,解码器顺序解码
S
t
S_t
St以输出
b
t
,
i
S
p
\textbf b^{S^p}_{t,i}
bt,iSp,然后再将
b
t
,
i
S
p
\textbf b^{S^p}_{t,i}
bt,iSp映射到患者状态空间,我们将
S
t
S_t
St的长度设置为
∣
S
∣
|S|
∣S∣,则
S
t
S_t
St上的先验分布被计算为:
p
θ
s
(
S
t
)
=
∏
i
=
1
∣
S
∣
s
o
f
t
m
a
x
(
M
L
P
(
b
t
,
i
S
p
)
)
,
(7)
p_{\theta_s}(S_t)=\prod^{|S|}_{i=1}softmax(MLP(\textbf b^{S^p}_{t,i})),\tag{7}
pθs(St)=i=1∏∣S∣softmax(MLP(bt,iSp)),(7)
其中MLP是多层感知器。为了近似后验状态分布,推理状态追踪器遵循类似的过程,但还包含了对
R
t
R_t
Rt的编码,即
h
t
R
\textbf h^R_t
htR。GRU解码器被初始化为
b
t
,
0
S
q
=
W
s
q
[
h
t
c
;
h
t
−
1
S
q
;
h
t
R
]
\textbf b^{S^q}_{t,0}=\textbf W^q_s[\textbf h^c_t; \textbf h^{S^q}_{t-1};\textbf h^R_t]
bt,0Sq=Wsq[htc;ht−1Sq;htR],其中
W
s
q
\textbf W^q_s
Wsq是一个可学习的参数,它在第
i
i
i个解码步骤中输出
b
t
,
i
S
q
\textbf b^{S^q}_{t,i}
bt,iSq。因此,我们将近似后验分布写为:
q
ϕ
s
(
S
t
)
=
∏
i
=
1
∣
S
∣
s
o
f
t
m
a
x
(
M
L
P
(
b
t
,
i
S
q
)
)
.
(8)
q_{\phi_s}(S_t)=\prod^{|S|}_{i=1}softmax(MLP(\textbf b^{S^q}_{t,i})).\tag{8}
qϕs(St)=i=1∏∣S∣softmax(MLP(bt,iSq)).(8)
3.4 Physician policy network
先验和推理策略网络也基于编码器-解码器结构。具体来说,我们将
A
t
A_t
At表示为一个动作类别
A
t
c
A^c_t
Atc和显式关键词
A
t
k
A^k_t
Atk对,即
A
t
=
{
A
t
c
,
A
t
k
}
A_t=\{A^c_t,A^k_t\}
At={Atc,Atk}。其中,我们将
A
t
k
A^k_t
Atk的长度设置为
∣
A
∣
|A|
∣A∣。
对于先验策略网络,在编码过程开始,我们使用GRU编码器将
S
t
p
S^p_t
Stp编码为一个向量
h
t
S
p
\textbf h^{S^p}_t
htSp。此外,外部知识在医生策略网络对患者状态做出响应中是很重要的。由于外部医学知识图
G
g
l
o
b
a
l
G^{global}
Gglobal很大(按实体数目统计),因此我们通过知识库检索操作
qsub
\textbf {qsub}
qsub从
G
g
l
o
b
a
l
G^{global}
Gglobal提取子图
G
n
l
o
c
a
l
G^{local}_n
Gnlocal。在
qsub
\textbf {qsub}
qsub期间,我们将
S
t
p
S^p_t
Stp中的每个实体视为种子节点。从
S
t
p
S^p_t
Stp开始,我们在
n
n
n跳范围内从
G
g
l
o
b
a
l
G^{global}
Gglobal中提取所有可访问的节点和边,以获取子图
G
n
l
o
c
a
l
G^{local}_n
Gnlocal。此外,我们将
S
t
p
S^p_t
Stp中的所有实体都进行链接,以确保连接
G
n
l
o
c
a
l
G^{local}_n
Gnlocal。
为了结合信息传播中的关系类型,我们采用关系图注意网络(RGAT)来表示外部知识图中的每个实体。给定一个图
G
=
{
X
,
Y
}
G=\{X,Y\}
G={X,Y},其包含了关系
Y
Y
Y和节点
X
X
X,在多轮传播后,RGAT输出特征矩阵
G
=
[
g
1
,
g
2
,
.
.
.
,
g
X
]
\textbf G=[\textbf g_1,\textbf g_2,...,\textbf g_X]
G=[g1,g2,...,gX],其中
g
x
\textbf g_x
gx(
1
≤
x
≤
X
1≤x≤X
1≤x≤X)是节点
x
x
x的嵌入。我们使用RGAT表示此操作,因此我们有:
G
n
l
o
c
a
l
=
R
G
A
T
(
G
n
l
o
c
a
l
)
\textbf G^{local}_n=RGAT(G^{local}_n)
Gnlocal=RGAT(Gnlocal)。
为了解码输出,我们需要依次推断
A
t
c
A^c_t
Atc和
A
t
k
A^k_t
Atk。我们设计一个动作分类器来推断
A
t
c
A^c_t
Atc。类似于[1],我们以
h
t
c
\textbf h^c_t
htc作为query来对
G
n
l
o
c
a
l
\textbf G^{local}_n
Gnlocal计算注意力向量
q
t
\textbf q_t
qt。顺序地,动作分类器引入
q
t
\textbf q_t
qt,并将医师的动作分为四类,即
a
s
k
s
y
m
p
t
o
m
s
ask~symptoms
ask symptoms,
d
i
a
g
n
o
s
i
s
diagnosis
diagnosis,
p
r
e
s
c
r
i
b
e
m
e
d
i
c
i
n
e
prescribe~medicine
prescribe medicine和
c
h
i
t
c
h
a
t
chitchat
chitchat,如下所示:
P
θ
a
,
c
(
A
t
c
)
=
s
o
f
t
m
a
x
(
W
c
p
[
h
t
S
p
;
h
t
c
;
q
t
]
)
,
(9)
P_{\theta_{a,c}}(A^c_t)=softmax(\textbf W^p_c[\textbf h^{S^p}_t;\textbf h^c_t;\textbf q_t]),\tag{9}
Pθa,c(Atc)=softmax(Wcp[htSp;htc;qt]),(9)
其中
W
c
p
\textbf W^p_c
Wcp是一个可学习的参数。然后我们通过从
p
θ
a
,
c
(
A
t
c
)
p_{\theta_{a,c}}(A^c_t)
pθa,c(Atc)中采样来计算动作类别
A
t
c
,
p
A^{c,p}_t
Atc,p。
A
t
k
A^k_t
Atk是基于GRU解码器顺序解码的。为了推断先验概率分布,提出了两个推理检测器(即,上下文检测器和一个图检测器)以在每个解码步骤中将解码器的隐藏表示映射射到动作空间。解码器被初始化为
b
t
,
0
A
k
,
p
=
W
𝑘
𝑝
[
h
t
S
p
;
h
t
c
;
e
t
A
c
,
p
]
\textbf b^{A^{k,p}}_{t,0}=\textbf W^𝑝_𝑘[\textbf h^{S^p}_t;\textbf h^c_t;\textbf e^{A^{c,p}}_t]
bt,0Ak,p=Wkp[htSp;htc;etAc,p],其中KaTeX parse error: Expected '}', got 'EOF' at end of input: …bf e^{A^{c,p}_t是
A
t
c
,
p
A^{c,p}_t
Atc,p的嵌入。在第
i
i
i个解码步骤,解码器输出
b
t
,
i
A
k
,
p
\textbf b^{A^{k,p}}_{t,i}
bt,iAk,p。上下文检测器和图检测器一起基于
b
t
,
i
A
k
,
p
\textbf b^{A^{k,p}}_{t,i}
bt,iAk,p推断
A
t
,
i
k
A^k_{t,i}
At,ik。
从原始上下文和状态中学习,上下文检测器使用MLP推理
A
t
,
i
k
A^k_{t,i}
At,ik上的先验分布,如下所示:
p
θ
a
,
d
(
A
t
,
i
k
)
=
1
z
A
e
x
p
(
M
L
P
(
[
h
t
S
p
]
;
h
t
c
;
b
t
,
i
A
k
,
p
)
)
,
(10)
p_{\theta_{a,d}}(A^k_{t,i})=\frac{1}{z_A}exp(MLP([\textbf h^{S^p}_t];\textbf h^c_t;\textbf b^{A^{k,p}}_{t,i})),\tag{10}
pθa,d(At,ik)=zA1exp(MLP([htSp];htc;bt,iAk,p)),(10)
其中
z
A
z_A
zA是与图检测器共享的归一化项。图检测器考虑从
G
𝑛
l
o
c
a
l
G^{local}_𝑛
Gnlocal中复制实体:
p
θ
a
,
g
(
A
t
,
i
k
)
=
1
z
A
I
(
e
j
,
A
t
,
i
k
)
⋅
e
x
p
(
W
g
[
h
t
c
;
b
t
,
i
A
k
,
p
;
g
j
]
)
,
(11)
p_{\theta_{a,g}}(A^k_{t,i})=\frac{1}{z_A}\mathbb I(e_j,A^k_{t,i})\cdot exp(\textbf W_g[\textbf h^c_t;\textbf b^{A^{k,p}}_{t,i};\textbf g_j]),\tag{11}
pθa,g(At,ik)=zA1I(ej,At,ik)⋅exp(Wg[htc;bt,iAk,p;gj]),(11)
其中
W
g
\textbf W_g
Wg是一个可学习的参数矩阵,
e
j
e_j
ej是
G
n
l
o
c
a
l
G^{local}_n
Gnlocal中的第
j
j
j个实体,
g
j
\textbf g_j
gj是
G
n
l
o
c
a
l
\textbf G^{local}_n
Gnlocal中的第
j
j
j个嵌入,
I
(
e
j
,
A
t
,
i
k
)
\mathbb I(e_j,A^k_{t,i})
I(ej,At,ik)表示如果
e
j
=
A
t
,
i
k
e_j=A^k_{t,i}
ej=At,ik则等于1,否则为0。我们将先验分布
A
t
A_t
At按如下所示进行计算:
p
θ
a
(
A
t
)
=
p
θ
a
,
c
(
A
t
c
)
⋅
∏
i
=
1
∣
A
∣
[
p
θ
a
,
d
(
A
t
,
i
k
)
+
p
θ
a
,
g
(
A
t
,
i
k
)
]
.
(12)
p_{\theta_a}(A_t)=p_{\theta_{a,c}}(A^c_t)\cdot\prod^{|A|}_{i=1}[p_{\theta_{a,d}}(A^k_{t,i})+p_{\theta_{a,g}}(A^k_{t,i})].\tag{12}
pθa(At)=pθa,c(Atc)⋅i=1∏∣A∣[pθa,d(At,ik)+pθa,g(At,ik)].(12)
推理策略网络通过从响应
R
t
R_t
Rt抽取指示性信息来近似动作类别后验分布和关键字后验分布。GRU编码器分别将
R
t
R_t
Rt编码到
h
t
R
\textbf h^R_t
htR,将
S
t
q
S^q_t
Stq编码到
h
t
S
q
\textbf h^{S^q}_t
htSq。然后,我们获得动作类别的近似后验分布,如下所示:
q
ϕ
a
,
c
(
A
t
c
)
=
s
o
f
t
m
a
x
(
W
c
q
[
h
t
c
;
h
t
S
q
;
h
t
R
]
)
.
(13)
q_{\phi_{a,c}}(A^c_t)=softmax(\textbf W^q_c[\textbf h^c_t;\textbf h^{S^q}_t;\textbf h^R_t]).\tag{13}
qϕa,c(Atc)=softmax(Wcq[htc;htSq;htR]).(13)
此后,我们通过从
q
ϕ
a
,
c
(
𝐴
𝑐
𝑡
)
q_{\phi_{a,c}}(𝐴𝑐𝑡)
qϕa,c(Act)的采样
A
t
c
,
q
A^{c,q}_t
Atc,q。为了加强来自
R
t
R_t
Rt信息的影响,我们仅使用上下文检测器来近似
A
t
k
A^k_t
Atk的后验分布。解码器初始化为
b
t
,
0
A
k
,
q
=
W
k
q
[
h
t
c
;
h
𝑡
S
𝑞
;
e
t
A
c
,
q
;
h
t
R
]
\textbf b^{A^{k,q}}_{t,0}=\textbf W^q_k[\textbf h^c_t;\textbf h^{S^𝑞}_𝑡;\textbf e^{A^{c,q}}_t;\textbf h^R_t]
bt,0Ak,q=Wkq[htc;htSq;etAc,q;htR],其中
e
t
A
c
,
q
\textbf e^{A^{c,q}}_t
etAc,q是
A
t
c
,
q
A^{c,q}_t
Atc,q的嵌入,
W
k
q
\textbf W^q_k
Wkq表示可学习的参数矩阵。
在第
i
i
i个解码步骤中,解码器输出
b
t
,
i
A
k
,
q
\textbf b^{A^{k,q}}_{t,i}
bt,iAk,q,因此我们在第
i
i
i个动作关键字上具有如下近似后验分布:
q
ϕ
a
,
d
(
A
t
,
i
k
)
=
s
o
f
t
m
a
x
(
M
L
P
(
[
h
t
c
;
h
t
S
q
;
b
t
,
i
A
k
,
q
]
)
)
.
(14)
q_{\phi_{a,d}}(A^k_{t,i})=softmax(MLP([\textbf h^c_t;\textbf h^{S^q}_t;\textbf b^{A^{k,q}}_{t,i}])).\tag{14}
qϕa,d(At,ik)=softmax(MLP([htc;htSq;bt,iAk,q])).(14)
最终我们得到一个
A
t
A_t
At的近似后验分布:
q
ϕ
a
(
A
t
)
=
q
ϕ
a
,
c
(
A
t
c
)
⋅
∏
i
=
1
∣
A
∣
q
ϕ
a
,
d
(
A
t
,
i
k
)
.
(15)
q_{\phi_a}(A_t)=q_{\phi_{a,c}}(A^c_t)\cdot \prod^{|A|}_{i=1}q_{\phi_{a,d}}(A^k_{t,i}).\tag{15}
qϕa(At)=qϕa,c(Atc)⋅i=1∏∣A∣qϕa,d(At,ik).(15)
受Jin et al.的启发,我们在
p
θ
s
(
S
t
)
p_{\theta_s}(S_t)
pθs(St)和
q
ϕ
s
(
S
t
)
q_{\phi_s}(S_t)
qϕs(St)中还采用了复制机制,以从
R
t
−
1
,
U
t
,
S
t
−
1
q
R_{t-1},U_t,S^q_{t-1}
Rt−1,Ut,St−1q中复制字符。以同样的方式,我们从
R
t
R_t
Rt复制字符来生成
q
ϕ
a
(
A
t
)
q_{\phi_a}(A_t)
qϕa(At)。
3.5 Response generator
在响应生成期间的第一阶段,我们使用一个GRU编码器将
S
t
q
S^q_t
Stq编码为
S
t
q
\textbf S^q_t
Stq,这是一个单词级的嵌入矩阵。
S
t
q
\textbf S^q_t
Stq中的每个列向量反映了
S
t
q
S^q_t
Stq中相应单词的嵌入向量。以相同的方式,将
A
t
k
,
q
A^{k,q}_t
Atk,q编码为
A
t
k
,
q
\textbf A^{k,q}_t
Atk,q。如3.3节和3.4节所述,我们还分别计算出
S
t
q
S^q_t
Stq和
A
t
k
,
q
A^{k,q}_t
Atk,q的整体嵌入
h
𝑡
S
q
\textbf h^{S^q}_𝑡
htSq和
h
k
A
\textbf h^A_k
hkA。具有GRU单元的响应解码器采用
b
t
,
0
R
=
W
d
[
h
t
c
;
h
t
S
q
;
e
𝑡
A
c
,
q
;
h
t
A
k
,
q
]
\textbf b^R_{t,0}=\textbf W_d[\textbf h^c_t;\textbf h^{S^q}_t;\textbf e^{A^{c,q}}_𝑡;\textbf h^{A^{k,q}}_t]
bt,0R=Wd[htc;htSq;etAc,q;htAk,q]作为初始隐藏状态。
在第
i
i
i个解码步骤中,第
𝑖
−
1
𝑖-1
i−1步的输出
b
t
,
i
−
1
R
\textbf b^R_{t,i−1}
bt,i−1R地读取上下文表示
H
t
\textbf H_t
Ht来获得
b
t
,
i
h
\textbf b^h_{t,i}
bt,ih,同时,
b
t
,
i
−
1
R
\textbf b^R_{t,i−1}
bt,i−1R还分别读取
S
t
q
\textbf S^q_t
Stq和
A
t
k
,
q
\textbf A^{k,q}_t
Atk,q以获得
b
t
,
i
s
\textbf b^s_{t,i}
bt,is和
b
t
,
i
a
\textbf b^a_{t,i}
bt,ia。随后,
[
b
t
,
i
h
;
b
t
,
i
s
;
b
t
,
i
a
;
e
t
,
i
−
1
R
]
[\textbf b^h_{t,i}; \textbf b^s_{t,i}; \textbf b^a_{t,i}; \textbf e^R_{t,i−1}]
[bt,ih;bt,is;bt,ia;et,i−1R]被带入到解码器GRU单元以输出
b
t
,
i
R
\textbf b^R_{t,i}
bt,iR,其中
e
t
,
i
−
1
R
\textbf e^R_{t,i−1}
et,i−1R是第
(
𝑖
−
1
)
(𝑖-1)
(i−1)个词的嵌入。
R
t
,
i
R_{t,i}
Rt,i的生成概率被形式化为生成概率和复制概率的和:
p
θ
g
(
R
t
,
i
)
=
p
θ
g
g
(
R
t
,
i
)
+
p
θ
g
c
(
R
t
,
i
)
,
p
θ
g
g
(
R
t
,
i
)
=
1
z
R
e
x
p
(
M
L
P
(
b
t
,
i
R
)
)
,
p
θ
g
c
(
R
t
,
i
)
=
1
z
R
∑
j
:
W
j
=
R
t
,
i
e
x
p
(
h
j
W
T
⋅
b
t
,
i
R
)
,
(16)
\begin{aligned} & p_{\theta_g}(R_{t,i})=p^g_{\theta_g}(R_{t,i})+p^c_{\theta_g}(R_{t,i}),\\ & p^g_{\theta_g}(R_{t,i})=\frac{1}{z_R}exp(MLP(\textbf b^R_{t,i})),\\ & p^c_{\theta_g}(R_{t,i})=\frac{1}{z_R}\sum_{j:W_j=R_{t,i}}exp({\textbf h^W_j}^T\cdot \textbf b^R_{t,i}), \end{aligned}\tag{16}
pθg(Rt,i)=pθgg(Rt,i)+pθgc(Rt,i),pθgg(Rt,i)=zR1exp(MLP(bt,iR)),pθgc(Rt,i)=zR1j:Wj=Rt,i∑exp(hjWT⋅bt,iR),(16)
其中
p
θ
g
g
(
R
t
,
i
)
p^g_{\theta_g}(R_{t,i})
pθgg(Rt,i)是生成概率,
p
θ
g
c
(
R
t
,
i
)
p^c_{\theta_g}(R_{t,i})
pθgc(Rt,i)是复制项,
z
R
z_R
zR是与
p
θ
g
c
(
R
t
,
i
)
p^c_{\theta_g}(R_{t,i})
pθgc(Rt,i)共享的归一化项。我们将
R
t
−
1
R_{t-1}
Rt−1,
U
t
U_t
Ut,
S
t
q
S^q_t
Stq和
A
t
k
,
q
A^{k,q}_t
Atk,q序列进行拼接以得到
W
W
W,其中
W
j
W_j
Wj是
W
W
W中的第
j
j
j个单词,而
h
j
W
\textbf h^W_j
hjW是
[
H
t
;
S
t
q
;
A
t
k
,
q
]
[\textbf H_t; \textbf S^q_t;\textbf A^{k,q}_t]
[Ht;Stq;Atk,q]中的第
j
j
j个向量。
3.6 Collapsed inference and training
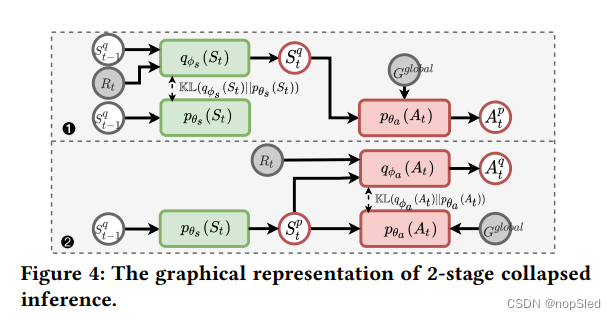
等式5提供了优化所有组件的统一目标。但是,联合分布
p
θ
s
(
S
t
)
⋅
p
θ
a
(
A
t
)
p_{\theta_s}(S_t)·p_{\theta_a}(A_t)
pθs(St)⋅pθa(At)很难进行优化,因为
p
θ
(
A
t
)
p_{\theta}(A_t)
pθ(At)很容易被
𝑆
p
θ
s
(
S
t
)
𝑆p_{\theta_s}(S_t)
Spθs(St)不正确的采样结果
S
t
p
S^p_t
Stp所误导。为了解决这个问题,我们通过将目标函数分解为2个优化目标,提出了一个2阶段的collapsed inference方法。在第一阶段,我们将
p
θ
s
(
S
t
)
p_{\theta_s}(S_t)
pθs(St)拟合到
q
ϕ
s
(
S
t
)
q_{\phi_s}(S_t)
qϕs(St)以得出ELBO(图4中的➊标记):
l
o
g
p
θ
(
R
t
∣
R
t
−
1
,
U
t
,
G
g
l
o
b
a
l
)
≥
E
q
ϕ
s
(
S
t
−
1
)
[
E
q
ϕ
s
(
S
t
)
[
E
p
θ
a
(
A
t
)
[
l
o
g
p
θ
g
(
R
t
∣
R
t
−
1
,
U
t
,
S
t
,
A
t
)
]
]
−
K
L
(
q
ϕ
s
(
S
t
)
∣
∣
p
θ
s
(
S
t
)
)
]
=
−
L
s
.
(17)
\begin{aligned} & log~p_{\theta}(R_t|R_{t-1},U_t,G^{global}) \\ & \ge \mathbb E_{q_{\phi_s}(S_{t-1})}\bigg[ \mathbb E_{q_{\phi_s}(S_t)}[\mathbb E_{p_{\theta_a}(A_t)}[log~p_{\theta_g}(R_t|R_{t-1},U_t,S_t,A_t)]] \\ & -\mathbb {KL}(q_{\phi_s}(S_t)||p_{\theta_s}(S_t))\bigg]\\ & = -\mathcal L_s. \end{aligned}\tag{17}
log pθ(Rt∣Rt−1,Ut,Gglobal)≥Eqϕs(St−1)[Eqϕs(St)[Epθa(At)[log pθg(Rt∣Rt−1,Ut,St,At)]]−KL(qϕs(St)∣∣pθs(St))]=−Ls.(17)
随后,类似于
ϕ
S
\phi_S
ϕS和
θ
S
\theta_S
θS的优化,我们将
p
θ
a
(
A
t
)
p_{\theta_a}(A_t)
pθa(At)拟合到
q
ϕ
a
(
A
t
)
q_{\phi_a}(A_t)
qϕa(At)以得出ELBO(图4中的➋标记):
l
o
g
p
θ
(
R
t
∣
R
t
−
1
,
U
t
,
G
g
l
o
b
a
l
)
≥
E
q
ϕ
s
(
S
t
−
1
)
[
E
q
ϕ
s
(
S
t
)
[
E
p
θ
a
(
A
t
)
[
l
o
g
p
θ
g
(
R
t
∣
R
t
−
1
,
U
t
,
S
t
,
A
t
)
]
]
−
K
L
(
q
ϕ
a
(
A
t
)
∣
∣
p
θ
a
(
A
t
)
)
]
=
−
L
a
.
(18)
\begin{aligned} & log~p_{\theta}(R_t|R_{t-1},U_t,G^{global}) \\ & \ge \mathbb E_{q_{\phi_s}(S_{t-1})}\bigg[ \mathbb E_{q_{\phi_s}(S_t)}[\mathbb E_{p_{\theta_a}(A_t)}[log~p_{\theta_g}(R_t|R_{t-1},U_t,S_t,A_t)]] \\ & -\mathbb {KL}(q_{\phi_a}(A_t)||p_{\theta_a}(A_t))\bigg]\\ & = -\mathcal L_a. \end{aligned}\tag{18}
log pθ(Rt∣Rt−1,Ut,Gglobal)≥Eqϕs(St−1)[Eqϕs(St)[Epθa(At)[log pθg(Rt∣Rt−1,Ut,St,At)]]−KL(qϕa(At)∣∣pθa(At))]=−La.(18)
因此,当不存在人类标注数据时,训练过程包括两个阶段。所以我们有:
L
u
n
=
{
L
s
(
1
s
t
t
r
a
i
n
i
n
g
s
t
a
g
e
)
L
s
+
L
a
(
2
n
d
t
r
a
i
n
i
n
g
s
t
a
g
e
)
.
(19)
\mathcal L^{un}= \begin{cases} \mathcal L_s & (1st~training~stage)\\ \mathcal L_{s}+\mathcal L_a & (2nd~training~stage). \end{cases}\tag{19}
Lun={LsLs+La(1st training stage)(2nd training stage).(19)
我们首先最小化
L
s
\mathcal L_s
Ls来获得合适的状态追踪结果。然后,我们在第二阶段联合优化所有参数。我们通过SGVB学习VRBOT,并使用Gumbel-Softmax技巧采样样本,以通过离散变量计算梯度。
如果有部分可用的标注状态
S
ˉ
t
\bar S_t
Sˉt和动作
A
ˉ
t
\bar A_t
Aˉt,我们添加一个辅助损失
L
s
u
p
\mathcal L^{sup}
Lsup以进行半监督训练:
L
s
u
p
=
−
(
l
o
g
p
θ
g
(
R
t
∣
S
ˉ
t
,
A
ˉ
t
,
R
T
−
1
,
U
t
)
)
+
l
o
g
(
p
θ
s
(
S
ˉ
t
)
⋅
q
ϕ
s
(
S
ˉ
t
)
)
+
l
o
g
(
p
θ
a
(
A
ˉ
t
)
⋅
q
ϕ
a
(
A
ˉ
t
)
)
.
(20)
\mathcal L^{sup}=-(log~p_{\theta_g}(R_t|\bar S_t,\bar A_t,R_{T-1},U_t))\\ +log(p_{\theta_s}(\bar S_t)\cdot q_{\phi_s}(\bar S_t))+log(p_{\theta_a}(\bar A_t)\cdot q_{\phi_a}(\bar A_t)).\tag{20}
Lsup=−(log pθg(Rt∣Sˉt,Aˉt,RT−1,Ut))+log(pθs(Sˉt)⋅qϕs(Sˉt))+log(pθa(Aˉt)⋅qϕa(Aˉt)).(20)
在测试过程中,我们仅执行
p
θ
s
(
S
t
)
p_{\theta_s}(S_t)
pθs(St)和
p
θ
a
(
A
t
)
p_{\theta_a}(A_t)
pθa(At)来推断患者状态和医生的动作(图3中的b部分)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









