






 本文全面探讨了图神经网络(GNN)的发展,包括四种主要类别:循环图神经网络、卷积图神经网络、图自编码器和时空图神经网络。介绍了GNN在各领域的应用,如电子商务、化学和社交网络,以及其在处理图数据时的开源资源和挑战。对未来研究方向提出了思考。
本文全面探讨了图神经网络(GNN)的发展,包括四种主要类别:循环图神经网络、卷积图神经网络、图自编码器和时空图神经网络。介绍了GNN在各领域的应用,如电子商务、化学和社交网络,以及其在处理图数据时的开源资源和挑战。对未来研究方向提出了思考。
摘要
近年来,深度学习彻底改变了许多机器学习任务,从图像分类和视频处理到语音识别和自然语言理解。这些任务中的数据通常在欧式空间中进行表示。但是,有越来越多的应用从非欧式域中生成数据,并将其表示为具有复杂关系和对象间相互依存的图。图数据的复杂性对现有的机器学习算法构成了重大挑战。最近,已经出现了许多有关将深度学习方法扩展到图数据的研究。在这项调查中,我们提供了数据挖掘和机器学习领域中图神经网络(GNN)的全面概述。我们提出了一种新的分类法,将最新的图形神经网络划分为四类,即循环图神经网络,卷积图神经网络,图自编码器和时空图神经网络。我们进一步讨论了图神经网络再在各个领域中的应用,并总结了图神经网络的开源代码,基准数据集和模型评估。最后,我们提出了这个快速增长的领域的一些潜在研究方向。
1.介绍
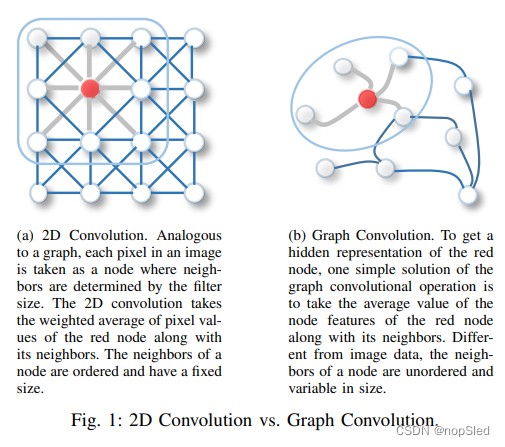
神经网络最近的成功提高了对模式识别和数据挖掘的研究。许多曾经严重依赖人工制作的特征工程来提取信息丰富特征集的机器学习任务,例如目标检测,机器翻译和语音识别,最近已被各种端到端的深度学习框架彻底改变,例如卷积神经网络(CNN),循环神经网络(RNN)和自编码器。深度学习在许多领域的成功部分归因于快速发展的计算资源(例如GPU),大型训练数据的可用性以及深度学习从欧式数据中提取潜在表示的有效性(例如图像,文本和视频)。以图像数据为例,我们可以将图像表示为欧式空间中的规则化的网格。卷积神经网络(CNN)能够利用图像数据的位移不变,局部连接和组合性。结果是,CNN可以提取与整个数据集共享的局部有意义的特征,以进行各种图像分析。
虽然深度学习以有效地捕获欧式数据的隐藏模式,但越来越多的应用是以图的形式表示数据。例如,在电子商务中,基于图的学习系统可以利用用户和产品之间的交互,以提出高度准确的推荐。在化学中,分子被建模为图,从而去确定其生物活性以进行药物发现。在引用网络中,论文通过引文相互关联,且需要将它们分为不同的组。图数据的复杂性对现有的机器学习算法构成了重大挑战。由于图是不规则的,因此图可能具有可变大小的无序结点,并且图的节点可能具有不同数量的邻居,从而导致一些重要的操作(例如,卷积)难以应用于图领域。此外,现有机器学习算法的核心假设是样例是彼此独立的。该假设不再适用于图数据,因为每个样例(节点)与被用各种类型边链接起来的样例相关。
最近,对图数据应用深度学习方法的兴趣越来越大。受CNN,RNN和自编码器深度学习的驱动,新操作的泛化和定义在过去几年快速发展,以能够处理复杂图数据。例如,可以从2D卷积中泛化出图卷积。如图1所示,一张图片可以视为图的特殊情况,其中像素通过相邻像素连接。与2D卷积类似,可以通过对节点的相邻信息进行加权平均来执行图卷积。
目前有关图神经网络(GNN)主题的报告数量是有限的。使用“几何深度学习”一词,Bronstein et al.给出了深度学习方法在非欧式空间中的概述,包括图和流形。尽管这是关于GNN的首次报告,但这项调查主要回顾卷积GNN。Hamilton et al.重点是解决网络嵌入问题,因此仅包含有限数量的GNN。Battaglia et al.将图网络作为一个从关系数据中学习的固有模块,是统一GNN架构下的一部分。Lee et al. 对应用了不同注意力机制的GNNS进行调查。总而言之,现有的调查仅包括一些GNN并检查有限数量的工作,从而缺少对GNN最新发展的概述。我们的调查为GNN提供了全面的概述,为希望进入这个迅速发展的领域和比较GNN模型的专家或研究人员提供帮助。为了涵盖更广泛的方法,本调查将GNN作为处理图数据的所有深度学习方法。
Our contributions。我们的论文做出了以下几点显著的贡献:
- New taxonomy。我们提出了图神经网络的新分类。图神经网络分为四组:循环图神经网络,卷积图神经网络,图自编码器和时空图神经网络。
- Comprehensive review。我们为图数据提供了现代深度学习技术的最全面概述。对于每种类型的图神经网络,我们将提供有关代表性模型的详细描述,进行了必要的比较,并总结相应的算法。
- Abundant resources。我们收集了与图神经网络上相关的丰富的资源,包括最好的模型,基准数据集,开源代码和实际应用。这项调查可以用作实践,理解,使用和开发解决各种现实生活相关的不同深度学习方法的指南。
- Future directions。我们讨论了图神经网络的理论方面,分析现有方法的局限性,并提出了四个可能的未来研究方向,即模型深度,可伸缩性权衡,异质性和动态性方面。
Organization of our survey。本调查的其余部分组织如下:第二节概述了图神经网络的背景,列出了常用的符号,并定义了与图相关的概念。第三节阐明了图神经网络的分类。第IV-VII节提供了图神经网络模型的概述。第七节介绍了各个领域的应用场景。第IX节讨论了当前的挑战,并提出了未来的方向。第X节对论文进行了总结。
2.BACKGROUND & DEFINITION
在本节中,我们概述了图神经网络的背景,列出通常使用的符号,并定义了相关的概念。
2.1 Background
A brief history of graph neural networks (GNNs)。Sperduti et al. (1997) 首先将神经网络应用于有向无环图,这激发了对GNN的早期研究。Gori et al. (2005) 最初概述了图神经网络的概念,并在Scarselli et al. (2009) 和 Gallicchio et al. (2010) 中进一步进行了阐述。这些早期研究属于循环图神经网络(RecGNNs)的类别。他们通过以迭代方式传播邻接节点信息来学习目标节点的表示,直到达到稳定的固定点为止。这个过程在计算上很昂贵,最近有越来越多地工作试图克服这些挑战。
受CNN在计算机视觉领域中成功的鼓励,大量方法对图数据进行卷积的操作进行了重新定义。这些方法在卷积图神经网络(ConvGNNs)的保护下。ConvGNNs被分为两个主要流,即spectral-based的方法和spatial-based的方法。Bruna et al. (2013) 首次提出了对spectral-based ConvGNNs的研究,该研究基于光谱图理论开发了图卷积。自从这段时间以来,针对spectral-based ConvGNNs的改进,扩展和近似的工作越来越多。对spatial-based ConvGNNs的研究要比spectral-based ConvGNNs开始得早。在2009年,Micheli et al. 通过架构组合非循环层首先解决了图的相互依赖性,同时继承了RecGNNs的信息传递的思想。但是,这项工作的重要性被忽略了。直到最近,许多spatial-based ConvGNNs研究出现。表II的第一列显示了代表性的RecGNNs和ConvGNNs的时间表。除了RecGNN和ConvGNN,在过去的几年中,已经开发了许多GNN变种,包括图自编码器(GAE)和时空图神经网络(STGNN)。某些通用学习框架可以建立在RecGNN,ConvGNN或其他用于图建模的神经体系结构上。关于这些方法的分类的详细信息在第三节中给出。
Graph neural networks vs. network embedding。关于GNN的研究与图嵌入或网络嵌入密切相关,这是另一个在数据挖掘和机器学习界越来越受关注的主题。网络嵌入旨在将网络节点表示为低维矢量表示,从而保留网络拓扑结构和节点内容信息,以便可以轻松地使用简单的现成机器学习算法来执行任何后续的图形分析任务,例如分类,聚类和推荐(例如,支持向量机)。同时,GNN是一种旨在以端到端方式解决与图相关任务的深度学习模型。许多GNN显式抽取高级表示。GNN和网络嵌入之间的主要区别在于,GNN是一组神经网络模型,专为各种任务而设计,而网络嵌入涵盖了针对相同任务的各种方法。因此,GNN可以通过图自编码器框架解决网络嵌入问题。另一方面,网络嵌入包含其他非深度学习方法,例如矩阵分解和随机游走。
Graph neural networks vs. graph kernel methods。图核方法是历史上主要用来解决图分类问题的技术。这些方法采用核函数来测量图之间的相似性,从而使基于核的算法(如支持向量机)可用于在图上进行有监督学习。与GNN相似,图核方法可以通过映射函数将图或节点嵌入到向量空间中。区别在于,此映射函数是确定性的,而不是可学习的。由于逐对地进行相似性计算,图核方法受到计算瓶颈的严重影响。一方面,GNN直接基于提取的图表示来执行图分类,因此比图核方法更有效。想要进一步了解图核方法,我们推荐读者参考[39]。
2.2 Definition

在整个本文中,我们使用粗体大写字符来表示矩阵和粗体小写字符来表示矢量。除非特别指定,否则本文中使用的符号在表I中进行了说明。现在,我们定义了理解本文所需的最小定义集合。
Definition 1 (Graph)。一个图被表示为
G
=
(
V
,
E
)
G=(V,E)
G=(V,E),其中
V
V
V是一组节点的集合,而
E
E
E是一组边。 令
v
i
∈
V
v_i∈V
vi∈V表示一个节点,而
e
i
j
=
(
v
i
,
v
j
)
∈
E
e_{ij}=(v_i,v_j)∈E
eij=(vi,vj)∈E表示从
v
j
v_j
vj指向
v
i
v_i
vi的边。节点
v
v
v的相邻节点被定义为
N
(
v
)
=
{
u
∈
V
∣
(
v
,
u
)
∈
E
}
N(v)=\{u∈V|(v,u)∈E\}
N(v)={u∈V∣(v,u)∈E}。邻接矩阵
A
\textbf A
A是一个
n
×
n
n×n
n×n的矩阵,如果
e
i
j
∈
E
e_{ij}\in E
eij∈E则
A
i
j
=
1
A_{ij}=1
Aij=1否则
A
i
j
=
0
A_{ij}=0
Aij=0。一个图可能具有节点属性
X
\textbf X
X,其中
X
∈
R
n
×
d
\textbf X\in \textbf R^{n\times d}
X∈Rn×d是一个节点特征矩阵,
x
v
∈
R
d
x_v\in \textbf R^d
xv∈Rd表示节点
v
v
v的特征向量。同事,一个图也可能具有边属性
X
e
\textbf X^e
Xe,其中
X
e
∈
R
m
×
c
\textbf X^e\in\textbf R^{m\times c}
Xe∈Rm×c是一个边特征矩阵,
x
v
,
u
e
∈
R
c
x^e_{v,u}\in \textbf R^c
xv,ue∈Rc表示边
(
v
,
u
)
(v,u)
(v,u)的特征向量。
Definition 2 (Directed Graph)。有向图是图的一个类别,其所有的边从一个节点指向另一个节点。 无向图被认为是有向图的特殊情况,如果连接了两个节点,则具有一对带有相反方向的边。当且仅当邻接矩阵是对称时,图是无方向性的。
Definition 3 (Spatial-Temporal Graph)。时空图是一个属性图,其中节点的属性随时间而动态变化。时空图被定义为
G
(
t
)
=
(
V
,
E
,
X
(
t
)
)
,
X
(
t
)
∈
t
R
n
×
d
G^{(t)}=(\textbf V,\textbf E,\textbf X^{(t)}),\textbf X^{(t)}∈t\textbf R^{n×d}
G(t)=(V,E,X(t)),X(t)∈tRn×d。
3.CATEGORIZATION AND FRAMEWORKS
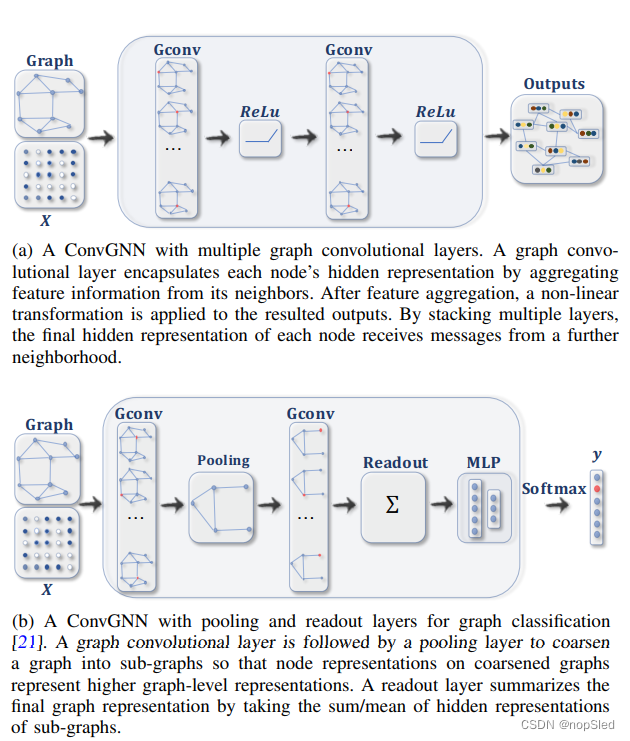
在本节中,我们介绍了图神经网络(GNN)的分类方法,如表II所示。我们将图形神经网络(GNN)分类为循环图神经网络(RecGNNs),卷积图神经网络(ConvGNNs),图自编码器(GAE)和时空图形神经网络(STGNN)。图2给出了各种模型网络结构的示例。在下文中,我们简要介绍了每个类别。
3.1 Taxonomy of Graph Neural Networks (GNNs)
Recurrent graph neural networks (RecGNNs)。循环图神经网络大部分都是图神经网络的先驱工作。RecGNN旨在学习具有循环神经结构的节点表示。他们假设图中的一个节点不断与邻居交换信息or消息,直到达到稳定的平衡态为止。RecGNN在概念上是重要的,后来为卷积图神经网络的提出提供了启发。特别是,消息传递的观点是由基于空间的卷积图神经网络继承的。
Convolutional graph neural networks (ConvGNNs) 。卷积图神经网络泛化了从网格数据到图数据的卷积操作。主要思想是通过整合其自己的特征
x
v
\textbf x_v
xv和邻接节点的特征
x
u
\textbf x_u
xu来生成节点
v
v
v的表示形式,其中
u
∈
N
(
v
)
u∈N(v)
u∈N(v)。与RecGNN不同,ConvGNN堆叠多个图卷积层以提取节点的高级表示。ConvGNN在建立许多其他复杂的GNN模型方面发挥了核心作用。 图2a展示了一个用于节点分类的ConvGNN。图2b展示了用于图分类的ConvGNN。
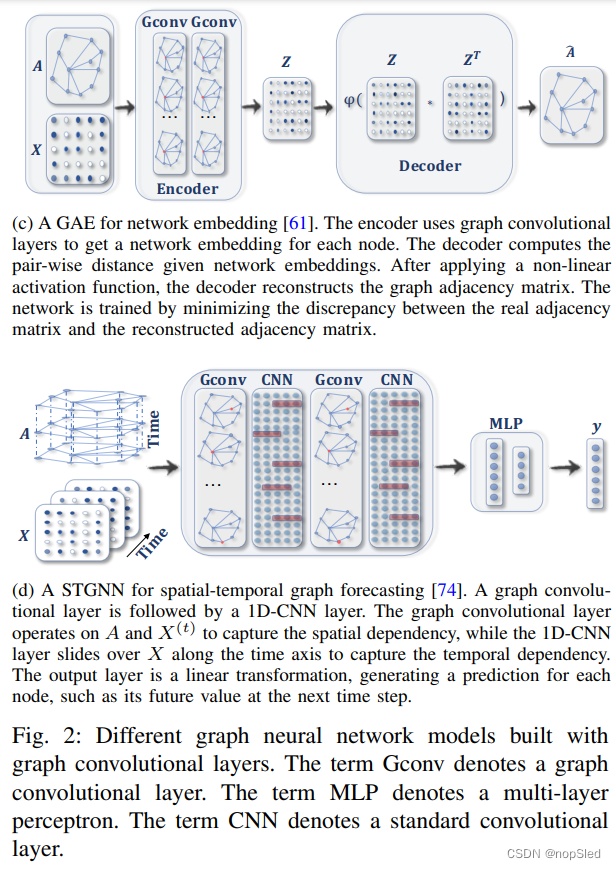
Graph autoencoders (GAEs)。图自编码器(GAE)是无监督学习的框架,它们将节点/图编码为潜在的向量空间,并从编码信息中重建图数据。GAE被用于学习网络嵌入和图的生成分布。对于网络嵌入,GAE通过重建图结构信息(例如图邻接矩阵)来学习潜在节点表示。 对于图生成,某些方法逐步生成图的节点和边,而其他方法一次直接输出整张图。图2c显示了用于网络嵌入的GAE。
Spatial-temporal graph neural networks (STGNNs)。时空图神经网络(STGNN)旨在从时间和空间角度学习隐藏的模式,这些模式在各种应用中变得越来越重要,例如交通速度预测,驾驶员操作预期和人类行动识别。STGNN的关键思想是同时考虑空间依赖性和时间依赖性。许多当前的方法通过集成图卷积来捕获空间依赖性,通过集成RNN或CNN以建模时间依赖性。图2d说明了用于空间图预测的STGNN。
3.2 Frameworks
任务框架。将图结构和节点内容信息作为输入,GNN的输出可以专注于不同的图分析任务,主要有以下几种:
- Node-level。节点一级的输出能应用到与节点回归和节点分类相关的任务。RecGNNs和ConvGNNs可以通过信息传输or图卷积提取节点的高级表示。GNN可以使用MLP或softmax层作为输出层,能够以端到端的方式执行节点级任务。
- Edge-level。边一级的输出能应用到与边分类或链接预测相关的任务。通过GNN中两个节点的隐藏表示,可以利用相似性函数或神经网络来预测边的标签或连接强度。
- Graph-level。图一级的输出能应用到与图分类相关的任务。为了在图一级上获得紧凑的表示,GNN通常与池化和readout操作结合使用。有关池化和readout操作的详细信息将在第5.3节中进行描述。
训练框架。许多GNN(例如,ConvGNNs)可以在端到端的学习框架中以半监督,有监督或无监督的方式进行训练,具体取决于已有的学习任务和标签信息。
- Semi-supervised learning for node-level classification。给定一个部分节点带有标注而其它节点未被标注的网络,ConvGNNs可以学习一个鲁棒的模型,该模型能有效地标识了未被标注的节点的类别。为此,可以通过堆叠几个图卷积层,然后堆叠用于多分类的softmax层来构建端到端框架。
- Supervised learning for graph-level classification。图一级分类旨在预测整个图的类别。该任务的端到端学习可以通过使用图卷积层,图池化层和readout层的组合来实现。其中图卷积层负责建模节点的高级表示,图池化层起到下采样的作用,每次都会将每个图缩小到一个子结构中。readout层将每个图的节点表示折叠成图表示。通过将多层感知器和softmax层应用于图表示,我们可以构建用于图分类的端到端框架。图2b中给出了一个示例。
- Unsupervised learning for graph embedding。当没有图的类别标签时,我们可以在端到端框架中以无监督的方式学习图嵌入。这些算法通过两种方式利用边一级的信息。 一种简单的方法是采用一个自编码器框架,其中编码器采用图卷积层将图嵌入到潜在表示中,并在其上使用解码器重建图结构。另一种流行的方法是利用负采样方法,该方法将一部分节点对作为负例对,而图中彼此链接的节点对是正例对。然后应用logistic回归层以区分正例和负例对。
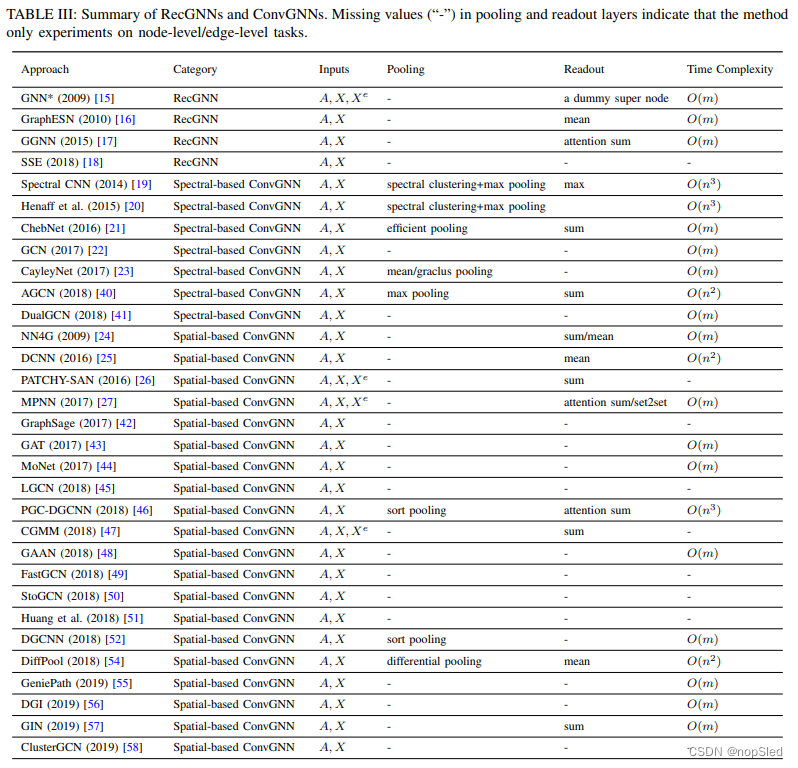
在表III中,我们总结了若干具有代表性的RecGNNs和ConvGNN的主要特点。我们在各种模型之间对输入源,池化层,readout层和时间复杂度进行了比较。更详细地,我们仅比较每个模型中消息传递/图卷积操作的时间复杂度。由于[19]和[20]中的方法需要特征值分解,因此时间复杂性为
O
(
n
3
)
O(n^3)
O(n3)。由于需要对节点对进行最短路径计算,[46]的时间复杂度也是
O
(
n
3
)
O(n^3)
O(n3)。其他方法会产生同等的时间复杂度,如果图邻接矩阵是稀疏,则是
O
(
m
)
O(m)
O(m),否则为
O
(
n
2
)
O(n^2)
O(n2)。这是因为在这些方法中,每个节点
v
i
v_i
vi表示的计算涉及
d
i
d_i
di个邻接节点,并且所有节点上的
d
i
d_i
di之和完全等于边的数量。表III中缺少几种方法的时间复杂度。这些方法要么在论文中缺乏对时间复杂度的分析,要么只报告其整体模型或算法的时间复杂度。
4.RECURRENT GRAPH NEURAL NETWORKS
循环图神经网络(RecGNNs)主要是GNN的先驱工作。他们将相同的一组参数循环应用于图中的节点,以提取高级节点表示。受到计算能力的限制,早期的研究主要集中在有向无环图上。
Scarselli et al. 提出的图神经网络(
G
N
N
∗
GNN^*
GNN∗)扩展了循环模型以处理通用类型的图,例如无环,有环,有向和无向的图。基于信息扩散机制,GNN*通过循环交换邻接节点的信息来更新节点的状态,直到达到稳定的平衡。节点的隐藏状态按如下方式被循环更新:
h
v
(
t
)
=
∑
u
∈
N
(
v
)
f
(
x
v
,
x
(
v
,
u
)
e
,
x
u
,
h
u
(
t
−
1
)
)
,
(1)
\textbf h^{(t)}_v=\sum_{u\in N(v)}f(\textbf x_v,\textbf x^{\textbf e}_{(v,u)},\textbf x_u,\textbf h^{(t-1)}_u),\tag{1}
hv(t)=u∈N(v)∑f(xv,x(v,u)e,xu,hu(t−1)),(1)
其中
f
(
⋅
)
f(·)
f(⋅)是一个参数化函数,且
h
v
(
0
)
\textbf h^{(0)}_v
hv(0)是随机初始化的。求和操作使
G
N
N
∗
GNN^*
GNN∗适用于所有节点,即使邻接节点的数量有所不同,并且没有邻接节点的顺序。为了确保收敛,循环函数
f
(
⋅
)
f(·)
f(⋅)必须是收缩映射,即将它们投射到潜在空间后两个点之间的距离会进一步缩小。如果
f
(
⋅
)
f(·)
f(⋅)是神经网络,则必须对参数的雅可比矩阵施加惩罚。当满足收敛标准时,最后一步的节点隐藏状态将馈送到readout层。
G
N
N
∗
GNN^*
GNN∗交替使用节点状态传播阶段和参数梯度计算阶段,以最小化训练目标。此策略使
G
N
N
∗
GNN^*
GNN∗能够处理循环图。在后续工作中, Graph Echo State Network(GraphESN) 将echo state networks进行扩展以提高
G
N
N
∗
GNN^*
GNN∗的训练效率。GraphESN由编码器和输出层组成。编码器是随机初始化的,不需要训练。它实现了收缩状态转移函数,以循环更新节点状态,直到全局图状态达到收敛为止。然后,通过将固定节点状态作为输入来训练输出层。
门控图神经网络(GGNN)利用门控循环单元(GRU)作为循环函数,将循环次数减少到固定数量的步骤。优势是它不再需要约束参数以确保收敛。节点隐藏状态由其上一步的隐藏状态及其相邻节点的隐藏状态更新,定义为:
h
v
(
t
)
=
G
R
U
(
h
v
(
t
−
1
)
,
∑
u
∈
N
(
v
)
W
h
u
(
t
−
1
)
)
,
(2)
\textbf h^{(t)}_v=GRU(\textbf h^{(t-1)}_v,\sum_{u\in N(v)}\textbf W\textbf h^{(t-1)}_u),\tag{2}
hv(t)=GRU(hv(t−1),u∈N(v)∑Whu(t−1)),(2)
其中
h
v
(
0
)
=
x
v
\textbf h^{(0)}_v=\textbf x_v
hv(0)=xv。与
G
N
N
∗
GNN*
GNN∗和
G
r
a
p
h
E
S
N
GraphESN
GraphESN不同,GGNN使用时间后向传播算法(BPTT)来学习模型参数。对于较大的图而言,这可能是有问题的,因为GGNN需要在所有节点上多次运行循环函数,这需要所有节点的中间状态存储在内存中。
Stochastic Steady-state Embedding(SSE)提出了一种学习算法,对大图具有可扩展性。SSE以一种随机和异步的方式循环更新节点隐藏状态。或者,它可以为状态更新采样一批节点,以及一批用于梯度计算的节点。为了保持稳定性,SSE的循环函数被定义为历史状态和新状态的加权平均,该状态采用一下形式:
h
v
(
t
)
=
(
1
−
α
)
h
v
(
t
−
1
)
+
α
W
1
σ
(
W
2
[
x
v
,
∑
u
∈
N
(
v
)
[
h
u
(
t
−
1
)
,
x
u
]
]
)
,
(3)
\textbf h^{(t)}_v=(1-\alpha)\textbf h^{(t-1)}_v+\alpha\textbf W_1\sigma(\textbf W_2[\textbf x_v,\sum_{u\in N(v)}[\textbf h^{(t-1)}_u,\textbf x_u]]),\tag{3}
hv(t)=(1−α)hv(t−1)+αW1σ(W2[xv,u∈N(v)∑[hu(t−1),xu]]),(3)
其中α是超参数,
h
v
(
0
)
\textbf h^{(0)}_v
hv(0)被随机初始化。虽然在概念上很重要,但SSE从理论上并未证明节点状态将通过重复应用方程3逐渐收敛到固定点。
5.CONVOLUTIONAL GRAPH NEURAL NETWORKS
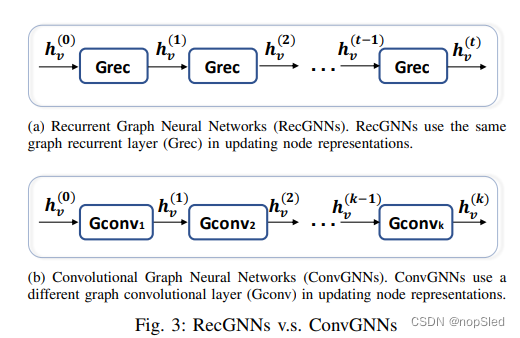
卷积图神经网络(ConvGNNs)与循环图神经网络密切相关。与使用收缩约束来迭代节点状态不同,ConvGNN是使用固定数量的层在架构上解决了循环相互依赖关系,其中每层具有不同的权重。关键区别在图3中进行了说明。由于图卷积能够更有效,更方便地与其他神经网络相结合,因此近年来,ConvGNN的受欢迎程度一直在迅速增长。ConvGNN分为两类,spectral-based和spatial-based。Spectral-based 的方法通过从图信号处理的角度引入滤波器来定义图卷积,其将图卷积操作解释为从图信号中删除噪声。Spatial-based 的方法继承了RecGNN的思想,将图卷积定义为信息传输操作。由于GCN缩短了spectral-based和spatial-based方法的差距,因此spatial-based的方法由于其高效性,灵活性和通用性而迅速发展。
5.1 Spectral-based ConvGNNs
Background。Spectral-based的方法在图信号处理中具有坚实的数学基础。他们假设图是无向的。归一化图的拉普拉斯矩阵是无向图的数学表示,定义为
L
=
I
n
−
D
−
1
2
A
D
−
1
2
\textbf L=\textbf I_n-\textbf D^{-\frac{1}{2}} \textbf A\textbf D^{-\frac{1}{2}}
L=In−D−21AD−21,其中
D
\textbf D
D是节点度的对角线矩阵,
D
i
i
=
∑
j
(
A
i
,
j
)
\textbf D_{ii}=\sum_j(\textbf A_{i,j})
Dii=∑j(Ai,j)。归一化图的拉普拉斯矩阵是半正定矩阵。基于此属性,可以将归一化的拉普拉斯矩阵分解为
L
=
U
Λ
U
T
\textbf L=\textbf U\Lambda\textbf U^T
L=UΛUT,其中
U
=
[
u
0
,
u
1
,
u
1
,
u
n
−
1
]
∈
R
n
×
n
\textbf U=[\textbf u_0,\textbf u_1,\textbf u_1,\textbf u_{n-1}]∈\textbf R^{n×n}
U=[u0,u1,u1,un−1]∈Rn×n是由特征值组成的特征向量矩阵,
Λ
\Lambda
Λ是特征值(频谱)的对角矩阵,
Λ
i
i
=
λ
i
\Lambda_{ii}=λ_i
Λii=λi。归一化拉普拉斯矩阵的特征向量形成一个正交空间,在数学中有
U
T
U
=
I
\textbf U^T\textbf U=\textbf I
UTU=I。在图信号处理中,图信号
x
∈
R
n
\textbf x∈\textbf R^n
x∈Rn是图中所有节点的特征向量,其中
x
i
x_i
xi是第
i
i
i个节点的值。对信号
x
\textbf x
x的图傅立叶变换被定义为
F
(
x
)
=
U
T
x
\mathcal F(\textbf x)=\textbf U^T\textbf x
F(x)=UTx,并且图傅立叶变换的逆被定义为
F
−
1
(
x
^
)
=
U
x
^
\mathcal F^{-1}(\hat {\textbf x})=\textbf U\hat {\textbf x}
F−1(x^)=Ux^,其中
x
^
\hat {\textbf x}
x^表示来自图傅立叶变换的结果信号。图傅立叶变换将输入图信号投射到正交空间,并且其基由归一化图拉普拉斯的特征向量组成。变换信号
x
^
\hat {\textbf x}
x^中的元素是图信号在新空间中的坐标,因此可以将输入信号表示为
x
=
∑
i
x
^
i
u
i
\textbf x=\sum_i\hat x_i\textbf u_i
x=∑ix^iui,这正是逆向图傅立叶变换。因此,给定一个滤波器
g
∈
R
n
\textbf g∈\textbf R^n
g∈Rn,输入信号
x
\textbf x
x的图卷积定义为:
x
∗
G
g
=
F
−
1
(
F
(
x
)
⊙
F
(
g
)
)
=
U
(
U
T
x
⊙
U
T
g
)
,
(4)
\textbf x*_G\textbf g=\mathcal F^{-1}(\mathcal F(\textbf x)\odot \mathcal F(\textbf g))\\ =\textbf U(\textbf U^T\textbf x\odot \textbf U^T\textbf g),\tag{4}
x∗Gg=F−1(F(x)⊙F(g))=U(UTx⊙UTg),(4)
其中,
⊙
\odot
⊙表示逐元素乘积。如果我们将滤波器表示为
g
θ
=
d
i
a
g
(
U
T
g
)
\textbf g_{\theta}=diag(\textbf U^T\textbf g)
gθ=diag(UTg),那么谱图卷积被简化为:
x
∗
G
g
θ
=
U
g
θ
U
T
x
.
(5)
\textbf x*_G\textbf g_{\theta}=\textbf U {\textbf g_{\theta}}\textbf U^T\textbf x.\tag{5}
x∗Ggθ=UgθUTx.(5)
所有spectral-based ConvGNN都遵循这个定义。主要区别在于滤波器
g
θ
\textbf g_{\theta}
gθ的选择。
Spectral Convolutional Neural Network(Spectral CNN)假设滤波器
g
θ
=
Θ
i
,
j
(
k
)
\textbf g_θ=\Theta^{(k)}_{i,j}
gθ=Θi,j(k)是一组可学习的参数,并考虑了具有多个通道的图信号。Spectral CNN的图卷积层被定义为:
H
:
,
j
(
k
)
=
σ
(
∑
i
=
1
f
k
−
1
U
Θ
i
,
j
(
k
)
U
T
H
:
,
i
(
k
−
1
)
)
(
j
=
1
,
2
,
.
.
.
,
f
k
)
,
(6)
\textbf H^{(k)}_{:,j}=\sigma(\sum^{f_{k-1}}_{i=1}\textbf U\Theta^{(k)}_{i,j}\textbf U^T\textbf H^{(k-1)}_{:,i})\quad (j=1,2,...,f_k),\tag{6}
H:,j(k)=σ(i=1∑fk−1UΘi,j(k)UTH:,i(k−1))(j=1,2,...,fk),(6)
其中
k
k
k是层索引,
H
(
k
−
1
)
∈
R
n
×
f
k
−
1
\textbf H^{(k-1)}∈\textbf R^{n×f_{k-1}}
H(k−1)∈Rn×fk−1是输入图信号,
H
(
0
)
=
X
\textbf H^{(0)}=\textbf X
H(0)=X,
f
k
−
1
f_{k -1}
fk−1是输入通道的数量,
f
k
f_k
fk是输出通道的数量,
Θ
i
,
j
(
k
)
\Theta^{(k)}_{i,j}
Θi,j(k)是一个对角矩阵,是可学习的参数。由于拉普拉斯矩阵的特征值分解,Spectral CNN面临三个局限性。首先,对图的任何扰动都会导致特征基的变化。其次,学到的滤波器是领域依赖的,这意味着它们不能应用于具有不同结构的图。第三,特征分解需要
O
(
n
3
)
O(n^3)
O(n3)的计算复杂性。在后续工作中,ChebNet和GCN通过进行若干近似和简化来使计算复杂度降低到
O
(
m
)
O(m)
O(m)。
Chebyshev Spectral CNN (ChebNet) 通过特征值的对角矩阵的切比雪夫多项式近似滤波器
g
θ
\textbf g_{\theta}
gθ,即,
g
θ
=
∑
i
=
0
K
θ
i
T
i
(
Λ
~
)
\textbf g_θ=\sum^K_{i=0}θ_iT_i(\tilde{\Lambda})
gθ=∑i=0KθiTi(Λ~),其中
Λ
~
=
2
Λ
/
λ
m
a
x
−
I
n
\tilde \Lambda=2\Lambda/\lambda_{max}-\textbf I_n
Λ~=2Λ/λmax−In。切比雪夫多项式由
T
i
(
x
)
=
2
x
T
i
−
1
(
x
)
−
T
i
−
2
(
x
)
T_i(\textbf x)=2\textbf xT_{i-1}(\textbf x)-T_{i-2}(\textbf x)
Ti(x)=2xTi−1(x)−Ti−2(x)递归定义,其中
T
0
(
x
)
=
1
T_0(\textbf x)=1
T0(x)=1和
T
1
(
x
)
=
x
T_1(\textbf x)=\textbf x
T1(x)=x。因此,具有近似滤波器
g
θ
\textbf g_{\theta}
gθ的图信号
x
\textbf x
x的卷积为:
x
∗
G
g
θ
=
U
(
∑
i
=
0
K
θ
i
T
i
(
Λ
~
)
)
U
T
x
,
(7)
\textbf x*_G\textbf g_{\theta}=\textbf U(\sum^K_{i=0}\theta_iT_i(\tilde \Lambda))\textbf U^T\textbf x,\tag{7}
x∗Ggθ=U(i=0∑KθiTi(Λ~))UTx,(7)
令
L
~
=
2
L
/
λ
m
a
x
−
I
n
\tilde {\textbf L}=2\textbf L/\lambda_{max}-\textbf I_n
L~=2L/λmax−In,因为
T
i
(
L
~
)
=
U
T
i
(
Λ
~
)
U
T
T_i(\tilde {\textbf L})=\textbf UT_i(\tilde \Lambda)\textbf U^T
Ti(L~)=UTi(Λ~)UT(可以通过在
i
i
i上使用归纳法证明),ChebNet则具有一下形式:
x
∗
G
g
θ
=
∑
i
=
0
K
θ
i
T
i
(
L
~
)
x
,
(8)
\textbf x*_G\textbf g_{\theta}=\sum^K_{i=0}\theta_iT_i(\tilde {\textbf L})\textbf x,\tag{8}
x∗Ggθ=i=0∑KθiTi(L~)x,(8)
作为对 Spectral CNN 的改进,由ChebNet定义的滤波器在空间中被局部化,这意味着滤波器可以抽取出与图大小无关的局部特征。 ChebNet的频谱被线性映射到
[
−
1
,
1
]
[-1,1]
[−1,1]。CayleyNet进一步应用Cayley多项式,这是参数合理的复杂函数,以捕获狭窄的频带。CayleyNet的谱图卷积被定义为:
x
∗
G
g
θ
=
c
0
x
+
2
R
e
{
∑
j
=
1
r
c
j
(
h
L
−
i
I
)
j
(
h
L
+
i
I
)
−
j
x
}
,
(9)
\textbf x*_G\textbf g_{\theta}=c_0\textbf x+2Re\{\sum^r_{j=1}c_j(h\textbf L-i\textbf I)^j(h\textbf L+i\textbf I)^{-j}\textbf x\},\tag{9}
x∗Ggθ=c0x+2Re{j=1∑rcj(hL−iI)j(hL+iI)−jx},(9)
其中
R
e
(
⋅
)
Re(·)
Re(⋅)返回复数的实数部分,
c
0
c_0
c0是一个实系数,
c
j
c_j
cj是一个复系数,
i
i
i是虚数,
h
h
h是控制Cayley滤波器频谱的参数。在保留空间局部性的同时,CayleyNet表明ChebNet可以被视为CayleyNet的一个特殊情况。
Graph Convolutional Network (GCN) 引入了ChebNet的一阶近似。其假设
K
=
1
K=1
K=1和
λ
m
a
x
=
2
λ_{max}=2
λmax=2,公式8被简化为:
x
∗
G
g
θ
=
θ
0
x
−
θ
1
D
−
1
2
A
D
−
1
2
x
.
(10)
\textbf x*_G\textbf g_{\theta}=\theta_0\textbf x-\theta_1\textbf D^{-\frac{1}{2}}\textbf A\textbf D^{-\frac{1}{2}}\textbf x.\tag{10}
x∗Ggθ=θ0x−θ1D−21AD−21x.(10)
为了限制参数的数量并避免过拟合,GCN进一步假设
θ
=
θ
0
=
−
θ
1
θ=θ_0=−θ_1
θ=θ0=−θ1,则得到图卷积的以下定义:
x
∗
G
g
θ
=
θ
(
I
n
+
D
−
1
2
A
D
−
1
2
)
x
.
(11)
\textbf x*_G\textbf g_{\theta}=\theta(\textbf I_n+\textbf D^{-\frac{1}{2}}\textbf A\textbf D^{-\frac{1}{2}})\textbf x.\tag{11}
x∗Ggθ=θ(In+D−21AD−21)x.(11)
为了允许多通道输入和输出,GCN将等式11修改为一个可组合层,定义如下:
H
=
X
∗
G
g
Θ
=
f
(
A
ˉ
X
Θ
)
,
(12)
\textbf H=\textbf X*_G\textbf g_{\Theta}=f(\bar {\textbf A}\textbf X\Theta),\tag{12}
H=X∗GgΘ=f(AˉXΘ),(12)
其中
A
ˉ
=
I
n
+
D
−
1
2
A
D
−
1
2
\bar{\textbf A}=\textbf I_n+\textbf D^{-\frac{1}{2}}\textbf A\textbf D^{-\frac{1}{2}}
Aˉ=In+D−21AD−21,并且
f
(
⋅
)
f(·)
f(⋅)是一个激活函数。使用
I
n
+
D
−
1
2
A
D
−
1
2
\textbf I_n+\textbf D^{-\frac{1}{2}}\textbf A\textbf D^{-\frac{1}{2}}
In+D−21AD−21经验上会导致GCN数值不稳定性。为了解决此问题,GCN应用了一个归一化的技巧,将
A
ˉ
=
I
n
+
D
−
1
2
A
D
−
1
2
\bar {\textbf A} =\textbf I_n+\textbf D^{-\frac{1}{2}}\textbf A\textbf D^{-\frac{1}{2}}
Aˉ=In+D−21AD−21替换为
A
ˉ
=
D
~
−
1
2
A
~
D
~
−
1
2
\bar {\textbf A}= \tilde D^{-\frac{1}{2}}\tilde {\textbf A}\tilde {\textbf D}^{-\frac{1}{2}}
Aˉ=D~−21A~D~−21,其中
A
~
=
A
+
I
n
\tilde {\textbf A}=\textbf A+\textbf I_n
A~=A+In且
D
~
i
i
=
∑
j
A
~
i
j
\tilde D_{ii}=\sum_j\tilde {\textbf A}_{ij}
D~ii=∑jA~ij。作为一种基于频谱的方法,GCN也可以被解释为基于空间的方法。从基于空间的角度来看,GCN可以被视为整合相邻节点的信息。方程12可以表示为:
h
v
=
f
(
Θ
T
(
∑
u
∈
{
N
(
v
)
∪
v
}
A
ˉ
v
,
u
x
u
)
)
∀
v
∈
V
.
(13)
\textbf h_v=f(\Theta^T(\sum_{u\in \{N(v)\cup v\}}\bar A_{v,u}\textbf x_u))\quad \forall v\in V.\tag{13}
hv=f(ΘT(u∈{N(v)∪v}∑Aˉv,uxu))∀v∈V.(13)
最近的几项工作通过探索一个可替代的对称矩阵对GCN进行了改进。自适应图卷积网络(AGCN)学习了图邻接矩阵中没有指定的隐藏结构关系。它通过可学习的距离函数构建了所谓的残差邻接矩阵,该距离函数将两个节点的特征作为输入。双图卷积网络(DGCN)引入了一个并行的双图卷积结构,其能同时处理两个图卷积层。尽管这两个层共享参数,但它们分别使用归一化的邻接矩阵
A
ˉ
\bar A
Aˉ和正点互信息(PPMI)矩阵,该矩阵通过从图中随机游走采样来捕获节点共现信息。 PPMI矩阵被定义为:
P
P
M
I
v
1
,
v
2
=
m
a
x
(
l
o
g
(
c
o
u
n
t
(
v
1
,
v
2
)
⋅
∣
D
∣
c
o
u
n
t
(
v
1
)
c
o
u
n
t
(
v
2
)
)
,
0
)
,
(14)
PPMI_{v_1,v_2}=max(log(\frac{count(v_1,v_2)\cdot |D|}{count(v_1)count(v_2)}),0),\tag{14}
PPMIv1,v2=max(log(count(v1)count(v2)count(v1,v2)⋅∣D∣),0),(14)
其中
v
1
,
v
2
∈
V
v_1,v_2∈V
v1,v2∈V,
∣
D
∣
=
∑
v
1
,
v
2
c
o
u
n
t
(
v
1
,
v
2
)
|D|=\sum_{v_1,v_2}count(v_1,v_2)
∣D∣=∑v1,v2count(v1,v2)和
c
o
u
n
t
(
⋅
)
count(·)
count(⋅)函数返回节点
v
v
v或节点
v
,
u
v,u
v,u在随机游走中共同出现的频率。通过结合双图卷积层的输出,DGCN编码局部和全局结构信息,而无需堆叠多个图卷积层。
5.2 Spatial-based ConvGNN
与传统CNN在图像上的卷积操作类似,基于空间的方法是基于节点的空间关系来定义图卷积操作。图像可以被视为图的特殊形式,每个像素代表一个节点。 每个像素直接连接到其附近的像素,如图1a所示。 一个
3
×
3
3\times 3
3×3的滤波器在每一个通道上通过对中心节点极其相邻节点进行加权平均来进行卷积操作。同样,基于空间的图卷积对中央节点的表示及其邻居的表示进行卷积,以得出中央节点更新后的表示,如图1b所示。 从另一个角度来看,基于空间的ConvGNNs与RecGNNs具有相同的信息传播/消息传递观点。空间图卷积操作基本上通过边来传播节点信息。
Neural Network for Graphs(NN4G)与
G
N
N
∗
GNN*
GNN∗同时提出,是基于空间的ConvGNNs的第一项工作。NN4G与RecGNNs截然不同,通过使用具有独立参数的神经层来组合以学习图的相互依赖性。一个节点的邻居可以通过增加结构来扩展。NN4G通过直接对节点的邻居信息相加来执行图卷积。 它还应用残差连接以及skip连接来记住每一层的信息。因此,NN4G按如下方式计算下一层的节点状态:
h
v
(
k
)
=
f
(
W
(
k
)
T
x
v
+
∑
i
=
1
k
−
1
∑
u
∈
N
(
v
)
Θ
(
k
)
T
h
u
(
k
−
1
)
)
,
(15)
\textbf h^{(k)}_v=f(\textbf W^{(k)^T}\textbf x_v+\sum^{k-1}_{i=1}\sum_{u\in N(v)}\Theta^{(k)^T}\textbf h^{(k-1)}_u),\tag{15}
hv(k)=f(W(k)Txv+i=1∑k−1u∈N(v)∑Θ(k)Thu(k−1)),(15)
其中,
f
(
⋅
)
f(\cdot)
f(⋅)是一个激活函数并且
h
v
(
0
)
=
0
\textbf h^{(0)}_v=0
hv(0)=0。等式15能够被写成如下矩阵形式:
H
(
k
)
=
f
(
X
W
(
k
)
+
∑
i
=
1
k
−
1
A
H
(
k
−
1
)
Θ
(
k
)
)
,
(16)
\textbf H^{(k)}=f(\textbf X\textbf W^{(k)}+\sum^{k-1}_{i=1}\textbf A\textbf H^{(k-1)}\Theta^{(k)}),\tag{16}
H(k)=f(XW(k)+i=1∑k−1AH(k−1)Θ(k)),(16)
这与GCN的形式类似。一个区别是NN4G使用非归一化的邻接矩阵,该矩阵可能会导致隐藏的节点状态具有较大的值域。Contextual Graph Markov Model(CGMM)受NN4G启发提出了一个概率模型。在保持空间位置的同时,CGMM具有概率可解释性的好处。
Diffusion Convolutional Neural Network(DCNN)将图卷积作为一个扩散过程。它假设信息从一个节点传递到与其相邻的另外一个节点,并具有一定的转移概率,因此信息分布在几轮后可以达到平衡。DCNN将扩散图卷积定义为:
H
(
k
)
=
f
(
W
(
k
)
⊙
P
k
X
)
,
(17)
\textbf H^{(k)}=f(\textbf W^{(k)}\odot\textbf P^k\textbf X),\tag{17}
H(k)=f(W(k)⊙PkX),(17)
其中
f
(
⋅
)
f(·)
f(⋅)是激活函数,概率转移矩阵
P
∈
R
n
×
n
\textbf P∈\textbf R^{n×n}
P∈Rn×n由
P
=
D
−
1
A
\textbf P=\textbf D^{-1}\textbf A
P=D−1A计算。请注意,在DCNN中,隐藏表示矩阵
H
(
k
)
\textbf H^{(k)}
H(k)保持与输入特征矩阵
X
\textbf X
X相同的维度,并且不是上一个隐藏表示矩阵
H
(
k
−
1
)
\textbf H^{(k-1)}
H(k−1)的函数。DCNN将
H
(
1
)
,
H
(
2
)
,
⋅
⋅
⋅
,
H
(
k
)
\textbf H^{(1)},\textbf H^{(2)},···,\textbf H^{(k)}
H(1),H(2),⋅⋅⋅,H(k)拼接在一起作为最终模型的输出。由于扩散过程的固定分布是概率转移矩阵幂级数的和,因此 Diffusion Graph Convolution(DGC)在每个扩散步骤对输出进行相加而不是拼接。扩散图卷积定义如下所示:
H
=
∑
k
=
0
K
f
(
P
k
X
W
(
k
)
)
,
(18)
\textbf H=\sum^K_{k=0}f(\textbf P^k\textbf X\textbf W^{(k)}),\tag{18}
H=k=0∑Kf(PkXW(k)),(18)
其中
W
(
k
)
∈
R
D
×
F
\textbf W^{(k)}∈\textbf R^{D×F}
W(k)∈RD×F,
f
(
⋅
)
f(·)
f(⋅)是激活函数。使用概率转移矩阵的幂意味着较远邻接节点对中心节点的信息贡献很少。PGC-DGCNN根据最短路径增加了较远邻接节点的贡献。它定义了最短路径邻接矩阵
S
(
j
)
\textbf S^{(j)}
S(j)。如果从节点
v
v
v到节点
u
u
u的最短路径是长度
j
j
j,则
S
v
,
u
(
j
)
=
1
\textbf S^{(j)}_{v,u}=1
Sv,u(j)=1否则为0。使用超参数
r
r
r来控制感受野的大小,PGC-DGCNN引入的图卷积操作如下所示:
H
(
k
)
=
∣
∣
j
=
0
r
f
(
(
D
~
(
j
)
)
−
1
S
(
j
)
H
(
k
−
1
)
W
(
j
,
k
)
)
,
(19)
\textbf H^{(k)}=||^r_{j=0}f((\tilde{\textbf D}^{(j)})^{-1}\textbf S^{(j)}\textbf H^{(k-1)}\textbf W^{(j,k)}),\tag{19}
H(k)=∣∣j=0rf((D~(j))−1S(j)H(k−1)W(j,k)),(19)
其中
D
ˉ
i
i
(
j
)
=
∑
l
S
i
,
l
(
j
)
\bar D^{(j)}_{ii}=\sum_lS^{(j)}_{i,l}
Dˉii(j)=∑lSi,l(j) ,
H
(
0
)
=
X
\textbf H^{(0)}=\textbf X
H(0)=X,并且
∣
∣
||
∣∣表示向量的拼接。最短路径邻接矩阵的计算可能很昂贵,复杂度最大为
O
(
n
3
)
O(n^3)
O(n3)。Partition Graph Convolution (PGC) 根据不受限于最短路径的一定标准将节点的邻居划分为
Q
Q
Q个组。PGC根据每组定义的邻居构造
Q
Q
Q个邻接矩阵。然后,PGC 将具有不同参数矩阵的 GCN 应用于每个组,并对结果求和:
H
(
k
)
=
∑
j
=
1
Q
A
ˉ
(
j
)
H
(
k
−
1
)
W
(
j
,
k
)
,
(20)
\textbf H^{(k)}=\sum^Q_{j=1}\bar{\textbf A}^{(j)}\textbf H^{(k-1)}\textbf W^{(j,k)},\tag{20}
H(k)=j=1∑QAˉ(j)H(k−1)W(j,k),(20)
其中
H
(
0
)
=
X
\textbf H^{(0)}=\textbf X
H(0)=X,
A
ˉ
(
j
)
=
(
D
~
(
j
)
)
−
1
2
A
~
(
j
)
(
D
~
−
1
2
)
\bar{\textbf A}^{(j)}=(\tilde{\textbf D}^{(j)})^{-\frac{1}{2}}\tilde{\textbf A}^{(j)}(\tilde{\textbf D}^{-\frac{1}{2}})
Aˉ(j)=(D~(j))−21A~(j)(D~−21)并且
A
~
(
j
)
=
A
(
j
)
+
I
\tilde{\textbf A}^{(j)}=\textbf A^{(j)}+\textbf I
A~(j)=A(j)+I。
Message Passing Neural Network (MPNN) 对spatial-based ConvGNN的通用框架进行了概述。它将图卷积视为消息传递过程,其中信息可以直接沿边从一个节点传递到另一个节点。MPNN 运行 K 步消息传递迭代以让信息进一步传播。消息传递函数(即空间图卷积)定义为:
h
v
(
k
)
=
U
k
(
h
v
(
k
−
1
)
,
∑
u
∈
N
(
v
)
M
k
(
h
v
(
k
−
1
)
,
h
u
(
k
−
1
)
,
x
v
u
e
)
)
,
(21)
\textbf h^{(k)}_v=U_k(\textbf h^{(k-1)}_v,\sum_{u\in N(v)}M_k(\textbf h^{(k-1)}_v,\textbf h^{(k-1)}_u,\textbf x^e_{vu})),\tag{21}
hv(k)=Uk(hv(k−1),u∈N(v)∑Mk(hv(k−1),hu(k−1),xvue)),(21)
其中
h
v
(
0
)
=
x
v
\textbf h^{(0)}_v=\textbf x_v
hv(0)=xv,
U
k
(
⋅
)
U_k(·)
Uk(⋅)和
M
k
(
⋅
)
M_k(·)
Mk(⋅)是具有可学习参数的函数。在得到每个节点的隐藏表示之后,
h
v
(
k
)
\textbf h^{(k)}_v
hv(k) 可以传递到输出层以执行节点级预测任务或传递到readout函数以执行图一级的预测任务。readout函数基于节点的隐藏表示生成整个图的表示。一般定义为
h
G
=
R
(
h
v
(
K
)
∣
v
∈
G
)
,
(22)
\textbf h_G=R(\textbf h^{(K)}_v|v\in G),\tag{22}
hG=R(hv(K)∣v∈G),(22)
其中
R
(
⋅
)
R(·)
R(⋅) 表示具有可学习参数的readout函数。MPNN 可以通过假设不同的
U
k
(
⋅
)
U_k(·)
Uk(⋅)、
M
k
(
⋅
)
M_k(·)
Mk(⋅) 和
R
(
⋅
)
R(·)
R(⋅) 形式来覆盖许多现有的GNN,例如 [22]、[85]、[86]、[87]。 然而, Graph Isomorphism Network (GIN) 发现,先前的基于 MPNN 的方法无法根据它们产生的图嵌入来区分不同的图结构。为了弥补这个缺点,GIN 通过一个可学习的参数
ϵ
(
k
)
\epsilon^{(k)}
ϵ(k) 来调整中心节点的权重。它通过以下方式执行图卷积:
h
v
(
k
)
=
M
L
P
(
(
1
+
ϵ
(
k
)
)
h
v
(
k
−
1
)
+
∑
u
∈
N
(
v
)
h
u
(
k
−
1
)
)
,
(23)
\textbf h^{(k)}_v=MLP((1+\epsilon^{(k)})\textbf h^{(k-1)}_v+\sum_{u\in N(v)}\textbf h^{(k-1)}_u),\tag{23}
hv(k)=MLP((1+ϵ(k))hv(k−1)+u∈N(v)∑hu(k−1)),(23)
其中,
M
L
P
(
⋅
)
MLP(\cdot)
MLP(⋅)表示一个多层感知器。
由于节点的邻居数量可以从一到一千甚至更多,因此获取全部的邻居节点是低效的。GraphSage通过采样为每个节点获取固定数量的邻居。它通过以下方式执行图卷积:
h
v
(
k
)
=
σ
(
W
(
k
)
⋅
f
k
(
h
v
(
k
−
1
)
,
∀
u
∈
S
N
(
v
)
)
)
,
(24)
\textbf h^{(k)}_v=\sigma(\textbf W^{(k)}\cdot f_k(\textbf h^{(k-1)}_v,\forall u\in S_{\mathcal N(v)})),\tag{24}
hv(k)=σ(W(k)⋅fk(hv(k−1),∀u∈SN(v))),(24)
其中
h
v
(
0
)
=
x
v
\textbf h^{(0)}_v=\textbf x_v
hv(0)=xv,
f
k
(
⋅
)
f_k(·)
fk(⋅)是一个聚合函数,
S
N
(
v
)
S_{\mathcal N(v)}
SN(v)是节点
v
v
v邻居的随机采样集合。聚合函数应与节点顺序无关,例如可以使用均值,求和或取最大的函数。
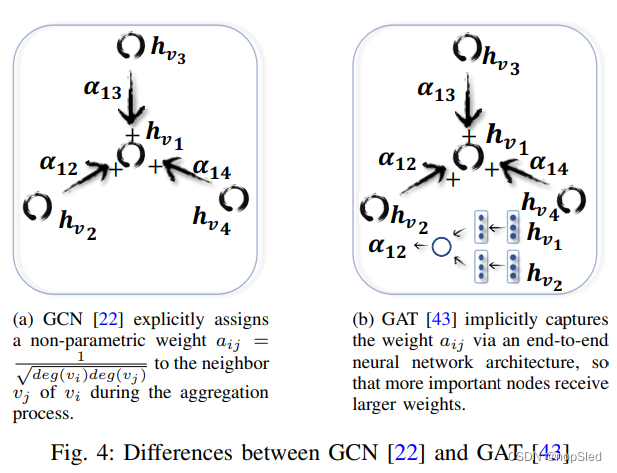
Graph Attention Network (GAT) 假设邻接节点对中心节点的贡献既不像GraphSage一样是相同的,也不像GCN那样是预先确定的(图4中说明了此差异)。GAT采用注意力机制来学习两个连接节点之间的相对权重。GAT的图卷积操作定义为:
h
v
(
k
)
=
σ
(
∑
u
∈
N
(
v
)
∪
v
α
v
u
(
k
)
W
(
k
)
h
u
(
k
−
1
)
)
,
(25)
\textbf h^{(k)}_v=\sigma(\sum_{u\in N(v)\cup v}\alpha^{(k)}_{vu}\textbf W^{(k)}\textbf h^{(k-1)}_u),\tag{25}
hv(k)=σ(u∈N(v)∪v∑αvu(k)W(k)hu(k−1)),(25)
其中
h
v
(
0
)
=
x
v
\textbf h^{(0)}_v=\textbf x_v
hv(0)=xv。注意力权重
α
v
u
(
k
)
\alpha^{(k)}_{vu}
αvu(k)测量了节点
v
v
v和其邻居
u
u
u的链接强度:
α
u
v
(
k
)
=
s
o
f
t
m
a
x
(
g
(
a
T
[
W
(
k
)
h
v
(
k
−
1
)
∣
∣
W
(
k
)
h
u
(
k
−
1
)
]
)
)
,
(26)
\alpha^{(k)}_{uv}=softmax(g(\textbf a^T[\textbf W^{(k)}\textbf h^{(k-1)}_v||\textbf W^{(k)}\textbf h^{(k-1)}_u])),\tag{26}
αuv(k)=softmax(g(aT[W(k)hv(k−1)∣∣W(k)hu(k−1)])),(26)
其中
g
(
⋅
)
g(·)
g(⋅)是LeakyReLU激活函数,
a
\textbf a
a是可学习的参数向量。softmax函数确保了所有相邻节点
v
v
v的注意力权重之和为1。GAT进一步执行了多头注意力,以提高模型的表达能力。这在节点分类任务上展示了比GraphSage更好的效果。由于GAT假设每个注意力头的贡献是相等的,因此在Gated Attention Network (GAAN) 中引入了一种自注意力机制,该机制为每个注意力头计算一个额外的注意力分数。除了在空间上应用图注意力外,GeniePath还进一步提出了类似LSTM的门控机制来控制图卷积层间的信息流。还有其他图注意力模型可能会引起人们的关注。但是,它们不属于ConvGNN框架。
Mixture Model Network (MoNet) 采用了一种不同的方法,将不同的权重分配给邻接节点。它引入了节点伪坐标,以确定节点与其邻接节点之间的相对位置。一旦已知两个节点之间的相对位置,权重函数将相对位置映射到这两个节点之间的相对权重。这样,可以在不同位置共享图滤波器的参数。基于MONET框架,存在各种变种方法,例如Geodesic CNN (GCNN),Anisotropic CNN (ACNN),Spline CNN。GCN,DCNN可以通过构建非参数权重函数来作为MONET的特殊实例。MoNet 额外提出了具有可学习参数的高斯核函数,以自适应学习权重。
另一个不同的工作方向是基于某些标准对节点的邻接节点进行排名,并将每个排名与可学习的权重相关联,从而实现了各个位置的权重共享。PATCHY-SAN根据每个节点的图标签对邻接节点进行排序,并选择top-q个邻接节点。图标签本质上是节点分数,可以通过节点度,中心性和Weisfeiler-Lehman color 得出。由于每个节点现在都具有固定数量的有序邻居,因此可以将图结构化数据转换为网格结构化数据。PATCHY-SAN应用标准的1D卷积滤波来汇总邻接节点的特征信息,其中滤波器的权重顺序与邻居节点的顺序相对应。PATCHY-SAN的排名标准仅考虑图结构,这需要大量的数据处理计算。Large-scale Graph Convolutional Network (LGCN) 根据节点特征信息对节点的邻居进行排名。对于每个节点,LGCN构建一个由其邻接节点组成的特征矩阵,并沿列对其行进行排序。排序后的特征矩阵的前
q
q
q行被视为中心节点的输入数据。
(1)Improvement in terms of training efficiency
训练ConvGNN(例如GCN)通常需要存储整个图数据以及每个节点的中间状态。ConvGNNs的full-batch训练算法由于内存溢出问题而遭受重大影响,尤其是当图包含数百万个节点时。为了节省内存,GraphSage为ConvGNNs提出了batch-training算法。它通过递归具有固定大小的K步扩展了根节点的邻接节点,从而采样了一个可以以每个节点为根的树。对于每个被采样的树,GraphSage通过自下而上分层汇总计算根节点的隐藏表示。
Fast Learning with Graph Convolutional Network (FastGCN) 为每个图卷积层采样了固定数量的节点,而不是为每个节点采样固定数量的邻居(如GraphSage)。它将图卷积解释为在概率度量下的节点嵌入函数的整体变换。蒙特卡洛近似和方差缩减技术用于促进训练过程。随着FastGCN对每一层独立采样节点,层之间的连接可能稀疏。Huang et al. 提出了一种自适应层采样方法,其中下层采样的节点以上层的节点为条件。与FastGCN相比,该方法以采用更为复杂的采样方案而获得了更高的准确性。
在另一项工作中,Stochastic Training of Graph Convolutional Networks (StoGCN) 通过将历史节点表示作为一个控制变量,将图卷积感受野大小减少到任意小的尺度。即使每个节点使用两个邻居,StoGCN也达到了可比的性能。但是,StoGCN仍然必须保存所有节点的中间状态,对大图来说非常消耗内存。
Cluster-GCN 使用图聚类算法对子图进行采样,并对采样子图中的节点执行图卷积。由于在采样子图中还限制了邻接节点的搜索,因此GCN能够处理较大的图并同时使用更深层次的架构,更少的时间和更少的内存。Cluster-GCN还在时间和空间复杂度上提供了对现有ConvGNN训练算法比较。表IV分析了其结果。
(2)Comparison between spectral and spatial models
spectral models 在图信号处理中具有一个理论基础。通过设计新的图信号滤波器(例如Cayleynets),可以构建新的ConvGNNs。但是,由于效率,通用性和灵活性问题,spatial models要优于spectral models。首先,spectral models的效率不如spatial models。spectral models需要同时执行特征向量计算或处理整个图。spatial models对大图更具可扩展性,因为它们通过信息传播直接在图中执行卷积。该计算可以在一批节点上而不是整个图中执行。其次,依赖图傅立叶的spectral models对新图的泛化能力差。他们假设图是固定的。对图的任何扰动都会导致特征基的变化。另一方面,spatial models 在每个节点上执行局部图卷积,在该节点可以轻松地在不同的位置和结构上共享权重。第三,spectral models仅限于在无向图上运行,而spatial models可以更灵活地处理多中输入源,例如边输入,有向图,有符号图和异质图,因为这些图输入可以轻松地将通过聚合函数进行合并。

5.3 Graph Pooling Modules
GNN生成节点特征后,我们可以将它们用于最终任务。但是,直接使用所有这些特征在计算上可能具有挑战性,因此需要采用下采样策略。根据这些特征在网络中的目标及其所扮演角色,给出了不同的策略:(1)池化操作旨在通过下采样节点来减少参数的大小以生成较小的表示,从而避免过拟合,排列不变性和计算复杂度的问题;(2)readout操作主要用于基于节点表示生成图一级的表示。它们的机制非常相似。在本章中,我们使用池化来指代在GNNS中应用的各种下采样策略。
在一些较早的工作中,图粗化算法基于其拓扑结构使用特征分解对图进行下采样。但是,这些方法遇到了时间复杂度的问题。Graclus算法是特征分解的替代方法,可以计算原始图的聚类版本。最近的一些工作将Graclus用作池化操作来对图下采样。
目前,
m
e
a
n
/
m
a
x
/
s
u
m
mean/max/sum
mean/max/sum池化是实现下采样的最基本和有效的方法,因为计算
m
e
a
n
/
m
a
x
/
s
u
m
mean/max/sum
mean/max/sum的操作很快:
h
G
=
m
e
a
n
/
m
a
x
/
s
u
m
(
h
1
(
K
)
,
h
2
(
K
)
,
.
.
.
,
h
n
(
K
)
)
,
(27)
\textbf h_G=mean/max/sum(\textbf h^{(K)}_1,\textbf h^{(K)}_2,...,\textbf h^{(K)}_n),\tag{27}
hG=mean/max/sum(h1(K),h2(K),...,hn(K)),(27)
其中,
K
K
K是最后一个图卷积层的索引。
Henaff et al. 证明在输入网络前执行简单的max/mean池化,对于降低图域中的维度并减少图傅立叶变换操作复杂度尤其重要。此外,某些工作还使用注意力机制来强化mean/sum池化。
即使是使用注意力机制的池化操作也不太令人满意,因为它使嵌入效率低下:无论图的大小如何,都会生成固定尺寸的嵌入。Vinyals et al. 提出Set2Set方法,以生成随着输入大小而增加的存储。然后,通过实现一个LSTM,在应用池化操作之前,将顺序相关的信息整合到一个内存嵌入,否则会破坏这些顺序信息。
Defferrard et al. 通过用有意义的方式重新排列图中的节点,从而解决了此问题。他们在方法ChebNet中设计了有效的池化策略。首先,通过Graclus算法将输入图分为多个级别。在粗化后,输入图的节点及其粗化的版本的被重新排列为平衡二叉树。自上而下整合平衡二叉树会将相似节点聚合在一起。对这种重排列后的节点进行池化要比对原始节点进行池化更有效。
Zhang et al. 在DGCNN中提出类似的池化策略,名为SortPooling,该策略通过将节点重新排列为有意义的顺序来执行池化。与ChebNet不同,DGCNN根据其在图中的结构角色进行排序。图从空间图卷积中的无序节点特征被视为连续的WL colors,然后将其用于对节点进行排序。除了对节点特征进行排序之外,它还通过截断/扩展节点的特征矩阵将图大小统一到
q
q
q。如果
n
>
q
n>q
n>q,则删除后面的
n
−
q
n-q
n−q行,否则添加
q
−
n
q-n
q−n个值为零的行。
前面提到的池化方法主要考虑图的特征,而忽略了图的结构信息。最近,提出了一个可微分池化(DiffPool),可以生成图的层次表示。与所有先前的粗化方法相比,DiffPool不仅会将图中的节点进行聚类,而且还在第
k
k
k层学习了聚类分配矩阵
S
\textbf S
S,表示为
S
(
k
)
∈
R
n
k
×
n
k
+
1
\textbf S^{(k)}∈\textbf R^{n_k×n_{k+1}}
S(k)∈Rnk×nk+1,其中
n
k
n_k
nk是第
k
k
k层节点的数目。矩阵
S
(
k
)
S^{(k)}
S(k)中的概率值是根据节点特征和拓扑结构生成的:
S
(
k
)
=
s
o
f
t
m
a
x
(
C
o
n
v
G
N
N
k
(
A
(
k
)
,
H
(
k
)
)
)
.
(28)
\textbf S^{(k)}=softmax(ConvGNN_k(\textbf A^{(k)},\textbf H^{(k)})).\tag{28}
S(k)=softmax(ConvGNNk(A(k),H(k))).(28)
这样做的核心思想是学习能同时考虑图的拓扑和特征信息的综合节点分配矩阵,因此可以使用任何ConvGNNs实现等式28。但是,DiffPool的缺点是它在合并后会生成一个密集图,然后计算复杂度变为
O
(
n
2
)
O(n^2)
O(n2)。
最近,SAGPool方法被提出,该方法既考虑节点特征又有图拓扑结构,并以自注意力的方式学习池化。
总体而言,池化是减少图尺寸的重要操作。如何提高池化的有效性并降低其计算复杂度是一个仍未解决的问题。
5.4 Discussion of Theoretical Aspects
我们从不同的角度讨论了图神经网络的理论基础。
(1)Shape of receptive field
节点的感受野是对当前节点的最终表示有贡献的节点集合。当组合多个空间图卷积层时,节点的感受野每次都会沿其较远邻居前进一步。Micheli证明,存在有限数量的空间图卷积层,使得每一个节点
v
∈
V
v\in V
v∈V的感受野能够覆盖图中所有的节点。因此,ConvGNN能够通过堆叠局部图卷积层来提取全局信息。
(2)VC dimension
VC维是模型复杂度的度量指标,其被定义为可被模型打散的最大样本数。很少有工作对GNN的VC维进行分析。给定模型参数
p
p
p的数量和节点
n
n
n的数量,Scarselli et al. 得出,如果GNN使用sigmoid或者tangent hyperbolic激活,则其VC维为
O
(
p
4
n
2
)
O(p^4n^2)
O(p4n2),如果使用分段多项式激活,则其VC维为
O
(
p
2
n
)
O(p^2n)
O(p2n)。结果表明,如果使用sigmoid或者tangent hyperbolic激活,则GNN的模型复杂度会随
p
p
p和
n
n
n迅速增加。
(3)Graph isomorphism
如果两个图在拓扑上是相同的,则它们是同构的。给定两个非同构图
G
1
G_1
G1和
G
2
G_2
G2,Xu et al. 证明,如果GNN将
G
1
G_1
G1和
G
2
G_2
G2映射到不同的嵌入,则可以通过同构的Weisfeiler-Lehman (WL)测试将这两个图识别为非同构图。他们表明,诸如GCN和GraphSage之类的常见GNN无法区分不同的图形结构。Xu et al. 进一步证明,如果GNN的池化函数和readout函数是注入性的,则GNN则能够与WL测试在区分不同的图上一样强大。
(4)Equivariance and invariance
当执行节点级任务时,GNN必须是等变函数,如果是执行图一级任务时则必须是不变函数。对于节点级任务,令
f
(
A
,
X
)
∈
R
n
×
d
f(\textbf A,\textbf X)∈R^{n×d}
f(A,X)∈Rn×d为GNN,
Q
Q
Q为任何更改节点顺序的排列矩阵。如果GNN满足
f
(
QAQ
T
,
QX
)
=
Q
f
(
A
,
X
)
f(\textbf {QAQ}^T,\textbf {QX})=\textbf Qf(\textbf A,\textbf X)
f(QAQT,QX)=Qf(A,X),则GNN是等变的。对于图一级任务,令
f
(
A
,
X
)
∈
R
d
f(\textbf A,\textbf X)∈R^d
f(A,X)∈Rd。如果GNN满足
f
(
QAQ
T
QX
)
=
f
(
A
,
X
)
f(\textbf {QAQ}^T\textbf {QX})=f(\textbf A,\textbf X)
f(QAQTQX)=f(A,X),则是不变的。为了实现等变或不变性,GNN的组件必须对节点顺序是不变的。 Maron et al. 理论上研究图数据的变换不变和等变线性层的特征。
(5)Universal approximation
众所周知,双层前馈神经网络可以近似任何波莱尔函数。目前很少有研究GNNS通用近似能力的工作。Hammer et al. 证明cascade correlation可以近似具有结构化输出的函数。Scarselli et al.证明RecGNN可以近似将unfolding equivalence保持在任何精确度的函数。如果两个节点的展开树是相同的,则两个节点是相同的,其中节点的展开树是通过迭代扩展其领居到某个深度来构建的。Xu et al. 证明消息传递框架下的ConvGNNs不是在多元集合中定义的连续函数的通用近似器。Maron et al.证明不变图网络可以近似在图上定义的任意不变函数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









