






 通过人类反馈微调的InstructGPT模型,在多种任务上展现出更好的用户意图理解能力,减少了有害输出,同时在公共NLP数据集上的表现接近原版GPT-3。
通过人类反馈微调的InstructGPT模型,在多种任务上展现出更好的用户意图理解能力,减少了有害输出,同时在公共NLP数据集上的表现接近原版GPT-3。
摘要
使语言模型更大并不总是能使它们对用户意图理解的更好。例如,大型语言模型可以生成一个不真实,有毒或根本对用户没帮助的输出。换句话说,这些模型与用户不匹配。在本文中,我们展示了通过使用人类反馈进行微调来使语言模型在各种任务上与用户意图保持一致的方法。通过使用一组标注人员编写的提示以及由OpenAI API提交的提示开始,我们收集了一组希望模型具有所需行为的演示数据集,我们使用有监督学习来微调GPT-3。然后,我们收集了一组由模型输出排名得到的数据集,然后进一步使用强化学习从人类反馈中来微调有监督模型。我们将最终得到的模型称为InstructGPT。在人类评估中,我们1.3B的InstructGPT优于175B的GPT-3。此外,InstructGPT模型显示出缺乏真实性和有毒输出的减少,同时对公共NLP数据集的性能回归很小。尽管InstructGPT仍然会犯一些简单的错误,我们的结果表明,基于人类反馈的微调是使语言模型与人类意图相结合的有前途的方向。
1.介绍
可以通过“提示”并给定一些任务样例作为输入,大型语言模型(LMS)可以被用来执行一系列自然语言处理(NLP)任务。但是,这些模型经常表现出一些不期望行为,例如伪造事实,生成偏见或有毒文本,或者根本不遵守用户指令。这是因为用于训练大型LM的目标(token预测)与“遵守对用户有帮助,且安全的指令”这一目标不同。因此,我们认为语言建模的目标是未被对齐的。避免这些意外行为对于在数百个应用中部署和使用的语言模型尤其重要。
我们通过让语言模型满足用户的意图来训练。这包含了显式的意图,例如遵守指令,以及隐式的意图,例如满足真实性,没有偏见,有毒或其他有害输出。正如Askell et al. (2021) 所说,我们希望语言模型是:(1)helpful,即他们应该帮助用户解决任务;(2)honest,即他们不应该捏造信息或误导用户;(3)harmless,即他们不应该对人或环境造成物理,心里或社会伤害。我们在第3.6节中详细阐述了对这些标准的评估。
我们主要专注用于使语言模型更匹配的微调方法。具体来说,我们使用基于人类反馈的强化学习来微调GPT-3(RLHF),以遵循大量编写的指令(如图2)。该技术使用人类的偏好作为奖赏信号来微调我们的模型。我们首先雇佣40个合同工来标注我们的数据,该数据主要基于他们在特定场景的爱好来标注(更多细节参考3.4节及附录B.1)。然后,我们收集人工编写的数据集,其中包括提交给OpenAI API和一些标注人员编写的提示及提示所需输出行为的数据集(主要是英语),并使用它来有监督训练我们的基线模型。接下来,我们收集了来自API的较多的提示,并得到模型输出,并对这些输出进行人工标注。然后,我们在此数据集上训练奖赏模型(RM),以预测我们的标注者更喜欢哪种模型输出。最后,我们将此RM用作奖赏函数,使用PPO算法来微调我们的有监督基线模型。我们在图2中说明了这一过程。此过程使GPT-3的行为与特定人群(主要是我们的标注员和研究人员)的偏好相吻合,而不是任何更泛化的“人类价值观”概念;我们在第5.2节中进一步讨论。我们将该模型称为InstructGPT。
我们主要通过让标注者对模型在测试集的输出质量进行评估,测试集的提示包括来自保密客户的提示(训练数据中未出现)。我们还对一系列公共NLP数据集进行了自动评估。我们训练了三个尺寸的模型(1.3b,6b和175b参数),且我们的所有模型都使用GPT-3体系结构。我们的主要有如下发现:
与GPT-3相比,标注者更喜欢InstructGPT的输出。在我们的测试集中,尽管1.3B InstructGPT与175B GPT-3相比参数少了100倍,但从InstructGPT模型中的输出比GPT-3的输出更优。这些模型具有相同的网络结构,略有不同的是InstructGPT在人类标注数据上进行了微调。即使我们在GPT-3中添加了few-shot提示,从而使其更好地遵循指令,测试结果仍然保持不变。从我们175B InstructGPT的输出要优于175B GPT-3输出
85
%
±
3
%
85\%±3\%
85%±3%,并且要优于few-shot 175B GPT-3输出
71
%
±
4
%
71\%±4\%
71%±4%。InstructGPT模型同样会生成与标注者更匹配的输出,并且在给出显式约束指令时更加可信赖。
InstructGPT模型在真实性上的提升优于GPT-3。在TruthfulQA基准上,InstructGPT生成了更加真实且信息更加丰富的答案,这要由于GPT-3两倍。在来自我们API提示中的“closed-domain”任务上,其中输出不应包含输入中不存在的信息(例如摘要和closed-domain QA),InstructGPT模型伪造的不存在于输入中的信息是GPT-3的一半。
InstructGPT模型生成没有危害性文本要略优于GPT-3,但不会带来偏见。为了测量危害性,我们使用RealToxicityPrompts数据集来进行自动和人工评估。InstructGPT模型的危害性输出比GPT-3少约25%。在Winogender和CrowSPairs数据集上,InstructGPT没有显着改善。
我们可以通过修改我们的RLHF微调过程来最小化公共NLP数据集的性能回归。在RLHF微调期间,我们观察到与GPT-3相比,InstructGPT在某些公共NLP数据集上存在性能回归,尤其是SQuAD,DROP,HellaSwag和WMT 2015 French到English翻译。 这是“alignment tax”的一个示例,因为我们的对齐过程是以我们更关心的某任务而降低其它任务性能为代价。我们可以通过将PPO更新与预训练目标相混合(PPO-ptx),从而大大降低这些数据集上的性能回归,同时不降低标注者的喜好分数。
我们的模型对未生成任何训练数据的标注者的偏好也具有泛化性。为了测试我们的模型的泛化性,我们对集外标注者进行了初步实验,并发现他们更喜欢InstructGPT的输出,而不是GPT-3的输出,其比率与我们的集内标注者大致相同。但是,需要更多的工作来研究这些模型是如何在更广泛的用户群体上执行的,以及他们在面对人类对所需行为不满意时的表现。
公共NLP数据集并不能反映我们的语言模型的使用方式。我们对在人类偏好数据上进行微调的GPT-3(即InstructGPT)和在两个不同公开NLP任务集(FLAN和T0)上进行微调的GPT-3进行了比较。这些数据集由各种NLP任务组成,每一个任务都包含自然语言指令。在我们的API提示分布中,我们的Flan和T0模型的性能比我们的SFT基线稍差,标注者显然更喜欢InstructGPT。
InstructGPT对RLHF微调分布外的指令也展示出有希望的泛化能力。我们定性地探究了InstructGPT的能力,并发现它能够按照指令摘要代码,回答有关代码的问题,并且有时会遵循不同语言的指令,尽管这些指令在微调分布中非常罕见。相反,虽然GPT-3可以执行这些任务,但需要更详细的提示,并且通常不会遵循这些领域中的指令。该结果令人兴奋,因为它表明我们的模型能够泛化“遵循指令”的概念。即使在几乎没有监督信号的任务上,他们也能够具有一些匹配。
InstructGPT仍然会犯一些简单的错误。例如,InstructGPT仍然无法遵守指令,会伪造事实,同时给出简单问题的长期冗余答案,或者无法检测出使用错误前提的指令。
总体而言,我们的结果表明,使用人类偏好微调的大型语言模型可显着改善其在各种任务上的行为,尽管还有许多工作要提高其安全性和可靠性。
本文的其余部分结构如下:我们首先在第2节中详细介绍了第3节中的相关工作,包括我们的high-level methodology(3.1),任务和数据集信息(3.3和3.2) ,人类数据收集(3.4),以及我们如何训练模型(3.5)及我们的评估过程(3.6)。然后,我们在第4节中介绍了我们的结果,分为三个部分:API提示分布(4.1),公开NLP数据集上的结果(4.2)以及定性结果(4.3)。最后,我们在第5节中对我们的工作进行了广泛的讨论。
2.相关工作
Research on alignment and learning from human feedback。我们基于先前的技术,使用来自人类反馈的强化学习(RLHF),使模型和人类意图对齐。RL原本用于在仿真环境和Atari游戏中训练简单的机器人,最近已被应用于微调语言模型以总结文本。这项工作反过来受在对话,翻译,语义解析,故事生成,评论生成以及证明抽取领域中以人类反馈作为reward的工作的影响。Madaan et al. (2022) 使用编写的人工反馈来增强提示并提高GPT-3的性能。也有使用规范性先验的RL在基于文本环境中对齐agent的工作。我们的工作可以看作是RLHF的直接应用,以使语言模型和广泛分布的语言任务相对齐。
最近,对语言模型对齐可解释性问题(what it means)也最近受到了关注。Kenton et al. (2021)分类了由未对齐导致的LMS中的行为问题,包括产生有害内容和游戏未指定目标。在同期工作中,Askell et al. (2021) 提出了将语言助手作为对齐研究的测试平台,研究一些简单的基准及其缩放特性。
Training language models to follow instructions。我们的工作还与语言模型中的跨任务通用有关,其中,LM在广泛的公开NLP数据集上进行了微调(通常具有适当的提示前缀),并对不同的NLP任务进行了评估。该领域有着一系列广泛的工作,包括训练和评估数据,指令的格式,预训练模型的尺寸和其他实验细节方面。在整个研究中一个一致的发现是,通过指令进行一系列NLP任务的微调改善了LM在zero-shot和few-shot中任务上的下游性能。
还有一项有关指令导航的相关工作,其中训练模型以遵循自然语言指令以在模拟环境中导航。
Evaluating the harms of language models。修改语言模型行为的一个目标是减轻这些模型在现实世界中应用时的危害。这些风险在大量记录中出现。语言模型可以产生有偏见的输出,从而导致泄漏私人数据,产生错误信息并且能被恶意使用。如果需要进行详尽的了解,我们推荐读者阅读Weidinger et al. (2021)。在特定领域中部署语言模型会带来新的风险和挑战,例如在对话系统中。有一个新但不断增长的领域旨在建立一个基准,以具体评估这些危害,特别是毒害性,呆板和社会偏见。在这些问题上取得重大进展非常困难,因为对LM行为的良好干预措施可能会产生副作用。例如,由于训练数据中的相关性,降低LM的毒性可能会降低其从统一类领域建模文本的能力。
Modifying the behavior of language models to mitigate harms。有很多方法可以改变语言模型的生成行为。Solaiman and Dennison (2021) 在一个具有针对性目标的数据集中微调LM,这提高了模型在QA任务上遵守这些目标的能力。Ngo et al. (2021) 通过删除语言模型对研究人员编写的特点触发短语具有很高条件似然的文档来过滤预训练数据集。当对该过滤的数据集进行训练时,其LM会产生较小的危害文本,而语言建模性能只有略微下降。Xu et al. (2020) 使用各种方法来提高聊天机器人的安全性,包括数据过滤,在生成期间阻止某些单词或n-gram,安全相关的控制token。其它减轻LM生成偏见的方法有,词嵌入正则化,数据增强,使过度敏感单词更加均匀的非空间映射。另外一种工作,是使用额外一个语言模型(通常更小)指导语言模型生成。
3.Methods and experimental details
3.1 High-level methodology
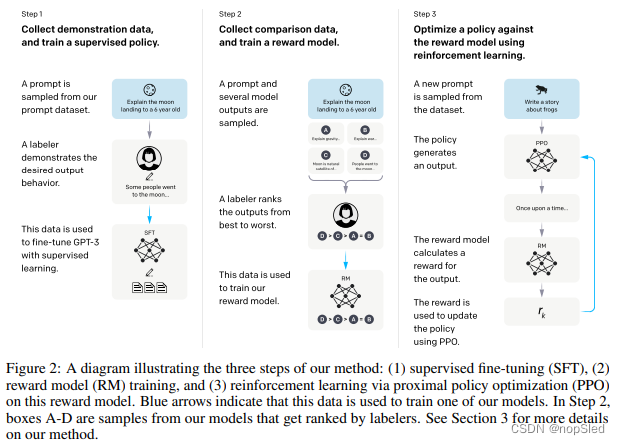
我们的方法遵循 Ziegler et al. (2019) 和Stiennon et al. (2020),这两个工作分别研究了文体延续和摘要领域。我们从预训练语言模型,我们想让模型生成对齐输出的提示分布,以及一组受过训练的人类标注者开始(有关详细信息,请参见3.4节)。 然后,我们应用以下三个步骤(图2)。
Step 1: Collect demonstration data, and train a supervised policy。我们的标注者提供了期望提示分布所需行为的演示(有关此分布的详细信息,请参见第3.2节)。然后,我们使用有监督的学习对这些数据微调GPT-3模型。
Step 2: Collect comparison data, and train a reward model。我们收集了一个模型输出的数据集,其中标注人员需要指出他们更喜欢的输出。然后,我们训练奖赏模型以预测人类偏爱的输出。
Step 3: Optimize a policy against the reward model using PPO。我们将RM的输出用作标量奖赏。我们将使用PPO算法微调有监督模型,以优化此奖赏。
步骤2和3可以连续迭代。
3.2 Dataset
3.3 Tasks
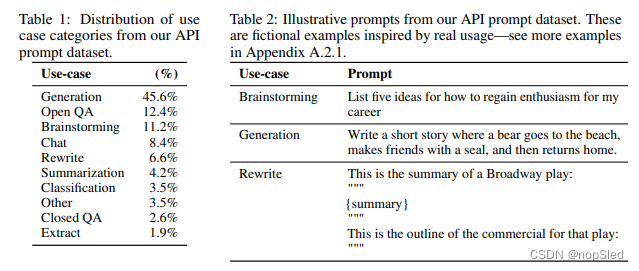
我们的训练任务来自两个数据源:(1)一批由标注者编写的提示数据集,以及(2)通过API提交的早期InstructGPT的提示数据集(请参见表6)。这些提示非常多样化,包括生成,问答,对话,摘要,抽取和其他自然语言任务(请参见表1)。我们的数据集包含了超过96%的英语,但是在第4.3节中,我们还探究了模型对其他语言完成编码任务的响应能力。
对于每个自然语言提示,其任务通常是通过自然语言指令直接指定的(例如,“Write a story about a wise frog”),但也可以通过一些few-shot演示来间接指定(例如,给出两个青蛙故事的例子 ,并提示该模型生成一个新的),或者给出一些隐式前缀(例如提供有关青蛙故事的开头)。在每种情况下,我们都会要求我们的标注人员竭尽所能推断出编写提示的用户的意图,并要求他们跳过意图非常不明确的输入。此外,我们的标注者还考虑了诸如响应真实性的隐含意图,以及在我们提供的指令的指导下,潜在有害的输出,并给出最优判断(参见附录B)。
3.4 Human data collection
3.5 Models
我们从Brown et al. (2020)提出的GPT-3预训练语言模型开始。该模型在广泛分布的互联网数据上进行训练,并且可以适应广泛的下游任务,但特征行为却很差。我们将使用三种不同的技术训练该模型:
Supervised fine-tuning (SFT)。基于标注者提供的演示,我们使用有监督学习微调GPT-3。我们使用余弦学习率衰减和0.2的残差dropout训练了16个epoch。我们根据验证集的RM分数进行最终的SFT模型选择。与Wu et al. (2021) 类似,我们发现我们的SFT模型在1个epoch过拟合验证集损失;但是,我们发现,尽管出现过拟合,但进行更多epoch的训练有助于提高RM分数和人类偏好评分。
Reward modeling (RM)。从SFT模型开始,其最后一个unembedding层被删除,我们训练了一个模型,其以提示和响应作为输入,并输出奖赏。在本文中,我们只使用6B参数的RM,因为这节省了大量计算,我们发现175B的RM可能是不稳定的,因此不太适合作为RL期间的价值函数(有关更多详细信息,请参见附录C)。
在Stiennon et al. (2020)中,RM模型在给定同一个输入,比较两个不同模型输出的数据集上进行训练。他们使用交叉熵损失,并将比较结果作为标签。
为了加快比较收集的速度,我们为标注者提供了
k
=
4
k=4
k=4和
k
=
9
k=9
k=9个响应以进行排序。这会对显示给标注者的每个提示生成
(
K
2
)
\left(\begin{matrix} K\\2\end{matrix}\right)
(K2)个比较。由于比较数据在每个标注任务中都非常相关,因此我们发现,如果我们仅仅简单地将比较结果打乱到一个数据集中,数据过完一遍会导致奖赏模型过拟合。相反,我们将每个提示的所有
(
K
2
)
\left(\begin{matrix} K\\2\end{matrix}\right)
(K2)个比较结果作为一个batch处理。这在计算上是更有效的,因为它对每个提示仅需要一个forward过程,而不是
(
K
2
)
\left(\begin{matrix} K\\2\end{matrix}\right)
(K2)次,并且由于它不再过拟合,因此它具有更高的验证机准确率。
具体而言,奖赏模型的损失函数是:
l
o
s
s
(
θ
)
=
−
1
(
K
2
)
E
(
x
,
y
w
,
y
l
)
∼
D
[
l
o
g
(
σ
(
r
θ
(
x
,
y
w
)
−
r
θ
(
x
,
y
l
)
)
)
]
(1)
loss(\theta)=-\frac{1}{\left(\begin{matrix} K\\2\end{matrix}\right)}E_{(x,y_w,y_l)\sim D}[log(\sigma(r_{\theta}(x,y_w)-r_{\theta}(x,y_l)))]\tag{1}
loss(θ)=−(K2)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))](1)
其中
r
θ
(
x
,
y
)
r_{\theta}(x,y)
rθ(x,y)是奖赏模型的一个标量输出,
x
x
x是提示,
y
y
y是语言模型输出。
y
w
y_w
yw是比较对
(
y
w
,
y
l
)
(y_w,y_l)
(yw,yl)中更倾向的结果,并且
D
D
D是训练数据集。
Reinforcement learning (RL)。再次采用Stiennon et al. (2020)中的方法,我们使用PPO微调我们环境中的SFT模型。环境是一个bandit环境,它给出随机的提示,并期望对提示产生响应。基于生成的响应,它会产生由奖赏模型确定的奖赏并结束episode。此外,我们在SFT模型中的每个token处添加了KL惩罚,以减轻奖赏模型的过度优化。价值函数是从RM初始化的。我们称这些模型为“ PPO”。
我们还试验了将预训练梯度与PPO梯度混合,以便修复公开NLP数据集上的性能回归。我们称这些模型为“ PPO-ptx”。我们在RL训练中最大化以下组合目标函数:
o
b
j
e
c
t
i
v
e
(
ϕ
)
=
E
(
x
,
y
)
∼
D
π
ϕ
R
L
[
r
θ
(
x
,
y
)
−
β
l
o
g
(
π
ϕ
R
L
(
y
∣
x
)
/
π
S
F
T
(
y
∣
x
)
)
]
+
γ
E
x
∼
D
p
r
e
t
a
i
n
[
l
o
g
(
π
ϕ
R
L
(
x
)
)
]
(2)
objective(\phi)=E_{(x,y)\sim D_{\pi^{RL}_{\phi}}}[r_{\theta}(x,y)-\beta log(\pi^{RL}_{\phi}(y|x)/\pi^{SFT}(y|x))]+\gamma E_{x\sim D_{pretain}}[log(\pi^{RL}_{\phi}(x))]\tag{2}
objective(ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretain[log(πϕRL(x))](2)
如果
π
ϕ
R
L
\pi^{RL}_{\phi}
πϕRL是学习的RL策略,则
π
S
F
T
\pi^{SFT}
πSFT是有监督的训练模型,而
D
p
r
e
t
a
i
n
D_{pretain}
Dpretain是预训练的分布。
β
\beta
β是KL奖赏系数,预处理损失系数
γ
γ
γ分别控制KL惩罚的强度和预训练梯度的强度。
Baseline。我们将PPO模型的性能与SFT模型和GPT-3进行比较。 我们还将其与GPT-3相比,当它提供了一些弹出前缀以将其“提示”到“指令跟随模式”(GPT-3启用)中。 该前缀添加到用户指定的指令。
我们还将指令与FLAN和T0数据集的微调175B GPT-3进行比较,这些数据集由各种NLP任务组成,并结合了每个任务的自然语言指令(包括NLP数据集的数据集不同,样式以及样式不同 使用的说明)。 我们分别在大约100万个示例上对其进行微调,并选择在验证集中获得最高奖励模型得分的检查点。 有关更多培训详细信息,请参见附录C


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









