






摘要
已被证明,在指令数据集上微调语言模型可以改善模型性能和对未知任务的泛化能力。在本文中,我们探索了指令微调,并主要关注下面几点:(1)缩放任务的数量,(2)缩放模型的大小,(3)在思维链数据集上进行微调。我们发现具有上述关注点的指令微调能显著提升各种类别模型(例如PaLM,T5,U-PaLM),各种提示设置(例如zero-shot,few-shot,CoT)以及评估基准(例如MMLU,BBH,TyDiQA,MGSM,open-ended generation,RealToxicityPrompts)的性能。例如,Flan-PaLM 540B在1.8K个任务的指令微调显著超越了PaLM 540B(平均提示9.4%)。Flan-PaLM 540B在若干基准上达到了SOTA性能。我们还开源了Flan-T5的checkpoint,其表现出很强的few-shot性能,甚至超越大型模型。总的来说,指令微调是一个用于提升预训练模型性能和使用能力的通用方法。
1.介绍
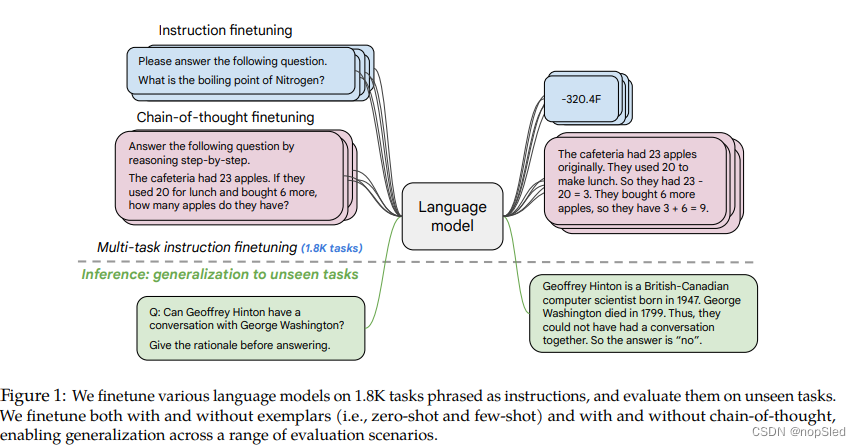
人工智能的一个重要目标是开发一个可以泛化到未知任务的模型。在自然语言处理(NLP)中,预训练语言模型已沿着这一目标取得了重大进展,因为它们可以在给定自然语言描述的情况下执行任务。通过在一系列任务指令集中微调语言模型取得了进一步的进展,这使模型能够更好地响应指令减少对few-shot样例的需求。
在本文中,我们通过多种方式来提高指令微调。首先,我们研究了缩放对指令微调的影响。我们的实验表明,指令微调确实可以随着任务的数量和模型的大小而缩放。他们各自的缩放行为表明,未来的研究应扩大任务数量和模型的规模。其次,我们研究了finetune对模型执行推理任务能力的影响。我们的实验表明,先前没有包含思维链的指令微调方法会严重降低在CoT评估时的性能,当将9个CoT数据集添加到微调训练后,就能提高所有评估的性能。
基于这些发现,我们通过将微调任务的数量增加到1.8K,并引入CoT数据,训练了一个具有540B参数的Flan-PaLM模型。Flan-PaLM 的表现优于PaLM,且在几个基准测试中获得了新的SOTA。例如,Flan-PaLM提高的推理能力使它能够利用CoT和自洽,以在Massive Multi-task Language Understanding(MMLU)上提升到75.2%。与PaLM相比,Flan-PaLM的多语言能力也提高了,例如,在one-shot TyDiQA上绝对提升14.9%,在训练集未出现语言的数学推理上提升了8.1%。在人类评估者的评估中,Flan-PaLM在一组充满挑战的开放式生成问题上大大优于PaLM,这表明提高了可用性。此外,我们发现指令微调还改善了几个负责任AI评估的基准的性能。
此外,我们还指令微调了Flan-T5模型(80M至11B)。这些checkpoint具有强大的zero-shot,few-shot和COT能力,且性能优于先前的开源checkpoint,例如T5。例如,Flan-T5 11B的表现比T5 11B好两位数,甚至在一些具有挑战性的BIG-Bench任务上胜过PaLM 62B。总体而言,我们的结果强调了指令微调如何改善各种模型,提示设置和评估任务的性能。
2. Flan Finetuning
我们在具有多种指令模板类型(图3)的数据源集合(图2)上进行指令微调。我们将该微调过程称为FLAN(Finetuning language models),并将“Flan”附加到最终需要微调的模型名前(例如Flan-PaLM)。我们表明,FLAN在几种模型和结构上都表现良好(表2)。

2.1 Finetuning Data
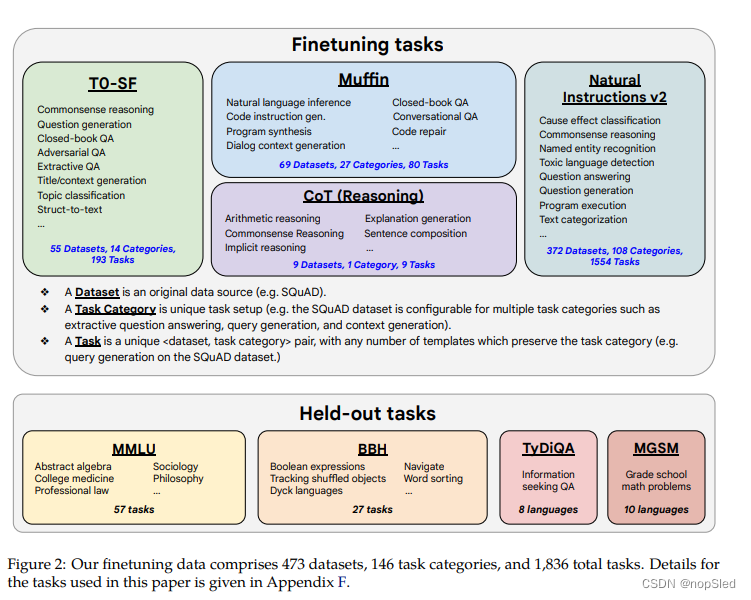
Task mixtures。先前的文献表明,增加指令微调任务的数量可以改善对未知任务的泛化能力。在本文中,我们通过将先前工作的四种任务进行混合( Muffin, T0-SF, NIV2, and CoT),以将其扩展到1,836个微调任务,如图2所示。Muffin(80个任务)包括来自Wei et al. (2021) 的62个任务,以及我们在这项工作中添加的26个新任务,包括对话数据和程序合成数据。T0-SF(193个任务)包括来自和Muffin中任务不重叠T0的任务(SF表示san Flan)。NIV2(1554个任务)来自Wang et al. (2022c)。
Chain-of-thought finetuning mixture。第四个微调数据(推理)涉及CoT标注,我们用该数据来探索在CoT上的微调是否可以改善对未知推理任务的性能。我们基于先前工作创建了九个数据集的新CoT数据,其中人类评估者手动为训练语料库编写了CoT注释。这9个数据集包括算术推理,多跳推理和自然语言推理等任务。我们为每个任务手动构建了十个指令模板,细节请查看附录F。
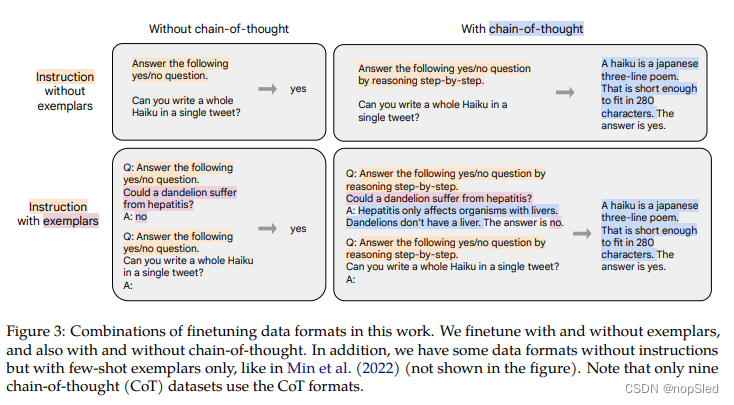
Templates and formatting。对于Muffin,T0-SF和NIV2,我们使用每个创建者为其任务构建的指令模板。对于CoT,我们为九个数据集中的每个数据集手动编写十个指令模板。为了创建few-shot模板,我们编写各种样例分隔符(例如“ Q:” and “A:”),并在样例级随机应用它们。图3中显示了有或没有格式化的样例,以及有无CoT的样例。
2.2 Finetuning procedure
在本文中,我们各种类别的模型上应用了指令微调,包括T5,PaLM,以及U-PaLM。这些模型涉及多种尺寸,包括Flan-T5-small(80M参数),PaLM和U-PaLM(540B参数)。对于每种模型,除了超参数设置(学习率,batch-size,dropout和微调步数)不同外,我们都采用相同的训练过程。我们使用Adafactor优化器以及固定学习率。我们使用packing将多个训练样例组合到单个序列中,同时使用序列结束字符将输入与目标分开。应用MASK以防止字符在packing边界上与其他样例一起参与计算。附录E中给出了每个模型的微调步骤,学习率,batch-size和dropout的数量。对于每个模型,最优步骤是根据固定任务的定期评估(根据模型大小每2k或10k步骤进行一次)选择的。值得注意的是,用于微调的计算数量仅占预预训练计算量的一小部分,如表2所示。我们使用基于JAX的T5X框架。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









