






 MEGABYTE是一种新的多尺度解码器结构,设计用于有效建模超过一百万个字节的长序列,如高分辨率图像和音频。它通过将序列划分为patches并使用局部和全局模型来减少注意力复杂度,提高并行性,降低训练和生成成本。实验显示MEGABYTE在长上下文语言建模、ImageNet密度估算和音频建模上表现出色,证明了tokenizer无关的自回归序列建模能力。
MEGABYTE是一种新的多尺度解码器结构,设计用于有效建模超过一百万个字节的长序列,如高分辨率图像和音频。它通过将序列划分为patches并使用局部和全局模型来减少注意力复杂度,提高并行性,降低训练和生成成本。实验显示MEGABYTE在长上下文语言建模、ImageNet密度估算和音频建模上表现出色,证明了tokenizer无关的自回归序列建模能力。
摘要
自回归transformer对短序列来说是性能强大的模型,但对较长序列性能交差,例如高分辨率图像,播客,代码或书籍。我们提出了MEGABYTE,这是一种多尺度解码器结构,可实现超过一百万个字节序列的端到端可微分建模。MEGABYTE将序列分段为若干patches,并在每个patch中使用一个局部子模型,在patches之间使用一个全局模型。这使得注意力复杂度变为pathes的二次方,从而在相同计算的情况下支持更大的前馈层,并在解码过程中提高了并行性 ,使得在降低训练和生成的成本的同时解锁了更好的性能。广泛的实验表明,MEGABYTE允许字节级模型在长上下文语言建模上达到和子词模型相当的性能,在ImageNet以及来自RAW文件的音频建模上达到SOTA的密度估算。总之,这些结果证明了tokenizer无关的自回归序列建模的能力。
1.介绍
具有数百万个字节的序列无处不在;例如,音乐,图像或视频文件通常由多个兆字节组成。但是,大型transformer解码器(LLM)通常仅使用数千个上下文token,这是因为自注意力的二次运算成本,而且更重要的是,还有每一个位置大型前馈网络的成本。这严重限制了可以应用LLM的任务集合。
我们介绍了MEGABYTE,这是一种建模长字节序列的新方法。首先,字节序列可以被分割为固定大小的patches,这与tokens相似。然后,我们的模型由三个部分组成:(1)patch embedder,它只是通过拼接每个字节的嵌入来编码一个patch,(2)global module,一个大型自回归transformer,以patch表示作为输入和输出,(3)local module,一种小型自回归模型,可预测patch中的字节。至关重要的是,我们观察到,对于许多任务,大多数字节预测相对容易(例如,在给定前几个字符来补全一个单词),这意味着对每个字节使用大型网络是不必要的,并且可以将较小的模型用于path内部建模。
MEGABYTE架构对用于长序列建模的Transformers进行了三个重大改进:
- Sub-quadratic self-attention。长序列模型的大多数工作都集中在如何减轻自注意力的二次复杂度上。MEGABYTE将长序列分解为两个较短的序列,最优的patch大小能将自注意力的成本降低到 O ( N 4 3 ) O(N^{\frac{4}{3}}) O(N34),这对于长序列是可行的。
- Per-patch feedforward layers。在GPT3大小的模型中,超过98%的FLOPS用于前馈层的计算。MEGABYTE在每个patch而不是位置处使用较大的前馈层。对于大小为 P P P的patch,基线transformer将使用带有 m m m参数的的前馈层 P P P次,MEGABYTE可以在相同成本的情况下使用带有 m P mP mP参数的前馈层。
- Parallelism in Decoding。Transformers必须在生成过程中串行执行所有计算,因为每个时刻的输入是前一个时刻的输出。通过并行生成patch表示,MEGABYTE可以在生成过程中具有更大的并行性。例如,具有1.5B参数的MEGABYTE模型可以比标准350M的Transformer快40%,同时使用相同的计算成本训练时也可以改善困惑度。
这些改进共同使我们能够在使用相同计算开销情况下,将输入序列扩展到很长并提高部署期间的生成速度来培训更大,性能更好的模型。
MEGABYTE还与现在的自回归模型具有较大差别,这些模型通用使用某种形式的tokenizer方法,其中字节序列被映射到更大的离散token。tokenizer使预处理,多模态建模并迁移到新领域中变得复杂,同时隐藏了来自模型可利用的结构。这也意味着大多数SOTA模型并不是真正的端到端。最广泛使用的tokenizer方法需要特定于语言的启发式方法或丢失信息。因此,用高效和高性能的字节模型代替tokenizer将具有许多优势。
我们对MEGABYTE和强基线进行了广泛的实验。我们在所有模型中使用固定的计算和数据预算,以关注模型的结构,而不是训练资源,这些资源已知会使模型模型受益。我们发现,MEGABYTE允许字节级模型在长上下文语言建模上达到和子词模型可比的性能,在ImageNet密度估计上达到SOTA困惑度,并允许从原始音频文件中进行音频建模。总之,这些结果确定了tokenization无关的自回归序列建模的能力。
2.MEGABYTE Transformer
2.1 Overview
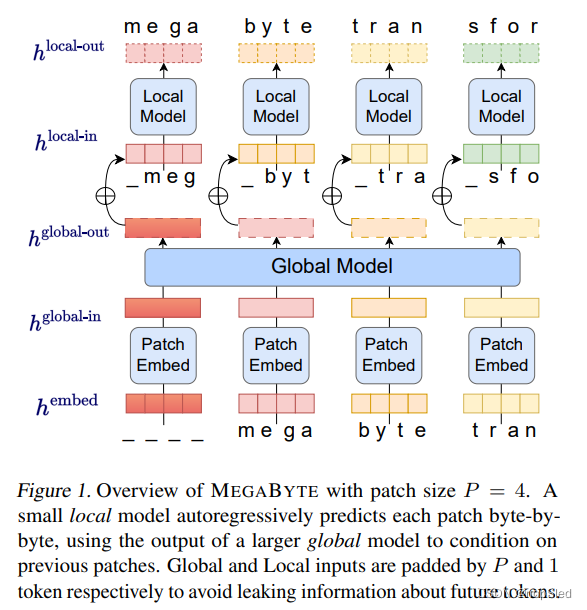
MEGABYTE是一种自回归模型,用于有效地对长输入序列进行建模。MEGABYTE由3个组件组成:(1)一个patch embedder,其以离散序列作为输入,并对每个元素进行嵌入,然后将其分解为长度为
P
P
P的多个patches;(2)large global Transformer,通过对pathches执行自注意力来建模patches间的上下文表示,以及(3)smaller local Transformer,以来自global model的patches上下文表示作为输入,并自回归预测下一个patch。
2.2 Components

Patch Embedder。Patch Embedder将patch大小为
P
P
P的字节序列
x
0..
T
x_{0..T}
x0..T映射到长度为
K
=
T
P
K=\frac{T}{P}
K=PT和维度为
P
⋅
D
G
P\cdot D_G
P⋅DG的patch嵌入序列。
首先,每个字节都用一个查找表
E
g
l
o
b
a
l
−
e
m
b
e
d
∈
R
V
×
D
G
E^{global-embed}∈\mathbb R^{V×D_G}
Eglobal−embed∈RV×DG嵌入到维度为
D
G
D_G
DG的嵌入,并添加位置嵌入。
h
t
e
m
b
e
d
=
E
x
t
g
l
o
b
a
l
−
e
m
b
e
d
+
E
t
p
o
s
t
∈
[
0..
T
]
(1)
h^{embed}_t=E^{global-embed}_{x_t}+E^{pos}_t\qquad t\in [0..T]\tag{1}
htembed=Extglobal−embed+Etpost∈[0..T](1)
然后,将字节嵌入reshaped为具有维度
P
⋅
D
G
P·D_G
P⋅DG的
K
K
K个patch嵌入。为了允许自回归建模,在patch序列开头使用一个可训练的padding嵌入
E
g
l
o
b
a
l
−
p
a
d
∈
R
P
×
D
G
E^{global-pad}\in \mathbb R^{P\times D_G}
Eglobal−pad∈RP×DG进行补全,然后从输入中移除最后一个patch。该序列是Global Model的输入,并表示为
h
g
l
o
b
a
l
−
i
n
∈
R
k
×
(
P
⋅
D
G
)
h^{global-in}∈\mathbb R^{k×(P·D_G)}
hglobal−in∈Rk×(P⋅DG)。
h
k
g
l
o
b
a
l
−
i
n
=
{
E
g
l
o
b
a
l
−
p
a
d
,
i
f
k
=
0
,
h
(
(
k
−
1
)
⋅
P
)
:
(
k
⋅
P
)
e
m
b
e
d
,
k
∈
[
1
,
.
.
.
,
K
)
,
(2)
h^{global-in}_k= \begin{cases} E^{global-pad},& if~k=0,\\ h^{embed}_{((k-1)\cdot P):(k\cdot P)},& k\in [1,...,K), \end{cases}\tag{2}
hkglobal−in={Eglobal−pad,h((k−1)⋅P):(k⋅P)embed,if k=0,k∈[1,...,K),(2)
Global Model。全局模型是一种纯解码器的Transformer,维度为
P
⋅
D
G
P·D_G
P⋅DG,在长度为
K
K
K的patch序列上运行。它结合了一种自注意力机制和因果mask,以捕获patch之间的依赖性。它输入是由
K
K
K个patch表示组成的序列
h
0
:
K
g
l
o
b
a
l
−
i
n
h^{global-in}_{0:K}
h0:Kglobal−in,并通过对先前的patch进行自注意力来输出更新的表示
h
0
:
K
g
l
o
b
a
l
−
o
u
t
h^{global-out}_{0:K}
h0:Kglobal−out。
h
0
:
K
g
l
o
b
a
l
−
o
u
t
=
t
r
a
n
s
f
o
r
m
e
r
g
l
o
b
a
l
(
h
0
:
K
g
l
o
b
a
l
−
i
n
)
(3)
h^{global-out}_{0:K}=transformer^{global}(h^{global-in}_{0:K})\tag{3}
h0:Kglobal−out=transformerglobal(h0:Kglobal−in)(3)
global model最后一层的输出
h
0
:
K
g
l
o
b
a
l
h^{global}_{0:K}
h0:Kglobal包含
K
K
K个维度为
P
⋅
D
G
P·D_G
P⋅DG的patch表示。对于每个patch表示,我们将它们reshape为长度为
P
P
P和维度为
D
G
D_G
DG的序列。然后将每个位置处的表示通过矩阵
w
G
L
∈
R
D
G
×
D
L
w^{GL}∈\mathbb R^{D_G×D_L}
wGL∈RDG×DL投影到的local model的维度,其中
D
L
D_L
DL是local model维度。然后,我们将它们与下一个patch中每一token的大小为
D
L
D_L
DL的字节嵌入
E
x
(
k
⋅
P
+
p
−
1
)
l
o
c
a
l
−
e
m
b
e
d
E^{local-embed}_{x(k·P+p-1)}
Ex(k⋅P+p−1)local−embed组合。局部字节嵌入被一个可训练的局部padding嵌入(
E
l
o
c
a
l
−
p
a
d
∈
R
D
L
E^{local-pad}∈\mathbb R^{D_L}
Elocal−pad∈RDL)进行偏移,以允许patch内进行自回归建模。这得到了张量
h
l
o
c
a
l
−
i
n
∈
R
K
×
P
×
D
L
h^{local-in}∈\mathbb R^{K×P×D_L}
hlocal−in∈RK×P×DL。
h
k
,
p
l
o
c
a
l
−
i
n
=
w
G
L
h
k
,
(
p
⋅
D
G
)
:
(
(
p
+
1
)
⋅
D
G
)
g
l
o
b
a
l
−
o
u
t
+
E
x
(
k
⋅
P
+
p
−
1
)
l
o
c
a
l
−
m
b
e
d
(4)
h^{local-in}_{k,p}=w^{GL}h^{global-out}_{k,(p\cdot D_G):((p+1)\cdot D_G)}+E^{local-mbed}_{x(k\cdot P+p-1)}\tag{4}
hk,plocal−in=wGLhk,(p⋅DG):((p+1)⋅DG)global−out+Ex(k⋅P+p−1)local−mbed(4)
Local Model。Local Model是维数为
D
L
D_L
DL的纯解码器Transformer,该模型在包含
P
P
P个元素的单个patch
k
k
k上操作,每个元素都是来自全局模型输出以及序列中上一个字节嵌入的总和。local models的
K
K
K个副本单独地在每个patch上(在训练期间并行)运行,得到表示
h
l
o
c
a
l
−
o
u
t
∈
R
K
×
P
⋅
D
L
h^{local-out}\in \mathbb R^{K\times P\cdot D_L}
hlocal−out∈RK×P⋅DL。
h
k
,
0
:
P
l
o
c
a
l
−
o
u
t
=
t
r
a
n
s
f
o
r
m
e
r
l
o
c
a
l
(
h
k
,
0
:
P
l
o
c
a
l
−
i
n
)
(5)
h^{local-out}_{k,0:P}=transformer^{local}(h^{local-in}_{k,0:P})\tag{5}
hk,0:Plocal−out=transformerlocal(hk,0:Plocal−in)(5)
最后,我们可以在每个位置计算词表上的概率分布。第
k
k
k个patch上的第
p
p
p个元素对应于完整序列的元素
t
t
t,其中
t
=
k
⋅
P
+
p
t=k·P+p
t=k⋅P+p:
p
(
x
t
∣
x
0
:
t
)
=
s
o
f
t
m
a
x
(
E
l
o
c
a
l
−
e
m
b
e
d
h
k
,
p
l
o
c
a
l
−
o
u
t
)
x
t
(6)
p(x_t|x_{0:t})=softmax(E^{local-embed}h^{local-out}_{k,p})_{x_t}\tag{6}
p(xt∣x0:t)=softmax(Elocal−embedhk,plocal−out)xt(6)
2.3 Variations and Extensions
我们尝试了MEGABYTE一些扩展版本。

















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









