






 文章探讨了大规模语言模型训练数据中存在的重复问题,指出这可能导致模型过度记忆训练数据。通过开发精确子字符串匹配和近似完整文档匹配技术进行数据去重,减少了训练数据中的重复,从而提高了模型的泛化能力和效率,同时减少了训练-测试重叠导致的准确性偏差。去重过程不影响模型的困惑度,甚至能在某些情况下降低困惑度。
文章探讨了大规模语言模型训练数据中存在的重复问题,指出这可能导致模型过度记忆训练数据。通过开发精确子字符串匹配和近似完整文档匹配技术进行数据去重,减少了训练数据中的重复,从而提高了模型的泛化能力和效率,同时减少了训练-测试重叠导致的准确性偏差。去重过程不影响模型的困惑度,甚至能在某些情况下降低困惑度。
摘要
我们发现现有的语言建模数据集包含许多几乎重复的样例以及重复子字符串。因此,在这些数据上训练的语言模型有超过1%的未被提示的输出是从训练集中逐字复制的。我们开发了两个工具,使我们可以去重训练数据集,例如,从C4中删除单个包含61个单词的英语句子,该句子重复了60,000次。数据去重使我们能够训练出现频次较少文本的模型,并且只需要更少的训练步骤就能达到相同或更高的准确性。我们还可以减少训练-测试的重叠,这会影响标准数据集中验证集的4%以上,从而可以进行更准确的评估。数据去重的代码在https://github.com/google-research/deduplate-text-datasets上发布。
1.介绍
自然语言处理最近进展的一个关键因素是用于训练越来越大语言模型的大规模文本语料的发展。在过去的几年中,这些数据集已从单个千兆字节增长到万亿字节。由于在大规模数据集上进行人工审查和设计非常昂贵,所以与较小的数据相比,它们往往会受到质量的困然。使用困惑度和验证损失等指标来进行评估远远是不行的,因为学习的模型反映了其训练数据中存在的偏见。因此,定量和定性地理解这些数据集本身就是一项研究挑战。
我们表明,一个特定的包含偏见的来源,重复的训练数据是普遍的:我们研究的所有四个常见的NLP数据集都包含重复。此外,所有四个相应的验证集都包含训练集中重复的文本。虽然简单的数据去重是一种直接的方式(我们认为这些数据集已经执行某种简单的去重),但在大规模数据上进行彻底的数据去重既是计算上的挑战,又需要复杂的技术。
我们提出了两种可扩展技术来检测和删除重复的训练数据。Exact substring matching可以识别重复的逐字字符串。这使我们能够识别训练数据中的的部分重复情况(第4.1节)。 Approximate full document matching使用基于哈希的技术来识别具有很高n-gram重叠的文档对(§4.2)。
我们确定在彻底去重的数据集上训练的四个不同的优势。
- 在这些数据上训练的语言模型有超过1%的未被提示的输出是从训练集中逐字复制的(参见第6.2节),即使15亿参数模型参数量远小于用于训练的350GB数据量。通过数据去重的训练数据集,我们将记忆训练数据的发射率降低了10倍。
- 训练测试重叠在没有去重的数据集中很常见。例如,我们在C4中找到一个包含61个字的序列,该序列在训练数据中逐字重复61,036次,在验证集中重复61次(每个数据集的0.02%)。这种训练测试的重叠不仅会导致研究人员过度估计模型的准确性,而且还使模型选择偏向于过度拟合其训数据集的模型和超参数。
- 在去重后的数据集训练模型更有效。使用我们的框架处理数据集需要仅CPU的线性时间算法。因此,由于这些数据集将减少原来的19%,甚至在去重数据上训练时,能降低模型训练的成本。
- 去重数据训练数据不会伤害困惑度:与在原始数据集中训练的基线模型相比,在去重数据集中训练的模型困惑度没有变差。在某些情况下,去重甚至能使困惑度降低10%。此外,由于最近的LM通常仅训练几个epoch,因此通过对高质量数据进行训练,模型可以更快地达到更高的精度。
总而言之,数据去重具有很大的优势,而没有观察到的缺点。在本文的其余部分中,我们在第4节介绍了文本去重框架,并在第5节研究了中常见的NLP数据集(例如C4,Wiki-40B和LM1B)中重复内容的程度。然后,我们验证了数据去重对测试集困惑度(第6.1节)的影响以及输出记忆内容的频率(§6.2)。最后,我们分析了由于训练和测试/验证集之间的重叠而导致的现有模型的困惑度在多大程度上被偏斜(第6.3节)。
2.Related Work
Large language model datasets。尽管我们认为我们的结果与模型结构无关,但我们对基于Transformer的纯解码器语言模型进行了分析,该模型被训练用于开放领域的文本生成。这些当前的SOTA模型经过互联网文本的训练。例如,GPT-2模型系统在WebText上进行了训练,WebText是一个在Reddit上排名较高的Web文档数据集,但该数据集未公开提供。一个常见的数据集是CommonCrawl,这是公开网页的索引。在CommonCrawl训练的模型中,包括添加额外书籍数据集的GPT-3,在被过滤Realnews的新闻领域的子集上的GROVER,以及在通用爬网的清洁版本C4上进行训练的T5。其他模型使用了详细设计的互联网源的训练,例如Guo et al. (2020) 使用来自40种不同语言的高质量处理的Wikipedia文本来训练单语141.4m参数的语言模型。非英语模型必然使用不同的数据集;例如Zeng et al. (2021),引入了PANGU-α,这是一个具有多达200B参数的模型家族,这些模型是在清洗过滤后的中文CommonCrawl和其他来源非公开语料库上训练的。由于这些数据集中的许多不是公开的,因此我们基于以下三个数据集进行去重:Wiki-40B,C4和RealNews,以及One Billion Word Language Model Benchmark,这是一个常用于评估的较小数据集。
Contamination of downstream tasks。当模型在通过爬取互联网而构建的数据集上训练时,模型可能也会在下游目标任务的测试集上进行训练。例如,Radford et al. (2019, §4) 进行了分析,以确定GPT-2的训练集与用于评估的数据集之间的8-gram重叠,Dodge et al. (2021b) 分析了C4,发现数据集中包含各种标准任务的测试示例中多达14.4%。一种更加主动的方法可以消除受污染的数据。Trinh and Le (2018, Appendix B) 从基于CommonCrawl的训练集中删除了文档,这些文档与用于评估的常识性推理基本上重叠。并且GPT-3(Brown et al., 2020, §5)通过保守地滤除训练集中任何与评估示例具有13-gram重叠的训练示例,以从其训练数据删除了下游评估示例。多达90%的任务被标记为潜在污染。
在我们的研究中,我们不专注于重复文本在验证模型对下游基准测试任务中的影响;相反,我们解决了在LM训练和验证集中重复文本如何影响模型的困惑度以及生成的文本包含记忆内容的程度。
Memorizing training data。Carlini et al. (2020) 强调了数据记忆引发的隐私风险,例如提取敏感数据(例如有效的电话号码和IRC用户名)的能力。尽管他们的论文发现了604个从其训练集中生成的GPT-2样本,但我们表明,超过1%生成的数据是被记住的训练数据。在计算机视觉中,已经从各个角度研究了训练数据的记忆。
Duplicate text in training data。根据 Bandy and Vincent (2021) 的说法,Book Corpus 这一用于训练BERT之类的模型的数据,有大量潜在的重复文档。Allamanis(2019)表明,代码数据集中的重复示例会导致代码理解任务的性能恶化。
3.Language Modeling Datasets
4.Methods for Identifying Duplicates
发现重复样例的最简单技术是在所有样例对之间执行完全字符串匹配,但是正如我们将展示的那样,这是不充分的。 我们介绍了两种用于执行数据去重的互补方法。首先,使用一个后缀数组,如果其逐字出现在不只一个样例中,则我们从数据集中删除了该重复的子字符串。其次,我们使用一种有效的算法MinHash来估计语料库中所有示例对之间的n-gram相似性,如果它们与任何其他示例有较高的n-gram重叠,则从数据集中删除整个示例。
我们考虑了一个数据集
D
=
{
x
i
}
i
=
1
N
D=\{x_i\}^N_{i=1}
D={xi}i=1N,其是样例
x
i
x_i
xi的集合。这些示例中的每一个本身都是字符序列:
x
i
=
[
x
i
1
,
x
i
2
,
⋅
⋅
⋅
x
i
s
i
]
x_i=[x^1_i,x^2_i,···x^{s_i}_i]
xi=[xi1,xi2,⋅⋅⋅xisi]。
4.1 Exact Substring Duplication
由于人类语言能力的多样性,除非一个表达从另一种表达得出或者两者都从共同来源引用,否则在多个文档中描述同一想法的表达完全一样是很稀少的。该观察结果激发了去重特定的子字符串。我们称我们的方法为EXACTSUBSTR。当两个样例 x j x_j xj和 x j x_j xj共享一个足够长的子字符串(即子字符串 x i a . . a + k = x j b . . b + k x^{a..a+k}_i=x^{b..b+k}_j xia..a+k=xjb..b+k)时,则从其中一个删除子字符串。基于统计分析(§B),我们选择 k = 50 k=50 k=50作为最小匹配的子字符串长度。可以在附录B中找到这种方法所需的计算分解。
4.1.1 Suffix Arrays
这种精确的子字符串匹配标准虽然在概念上很简单,但在计算上却是简洁的(二次)全对匹配。为了提高效率,我们将整个数据集
D
D
D的所有样例串联成一个巨型序列
S
\mathcal S
S,并构造一个
S
\mathcal S
S的后缀数组
A
\mathcal A
A。该后缀数组是一颗后缀树的表示,该树可以在线性时间
∣
∣
S
∣
∣
||\mathcal S||
∣∣S∣∣内被构建,且可以有效地计算许多子字符串查询;特别是,它们使我们能够在线性时间内识别重复的训练样例。后缀数组比后缀树具有优势,因为它们具有10–100倍的内存高效,每个输入token只需要8个字节,尽管它们在某些查询方面的效率降低了。它们已在NLP中被广泛使用,例如高效TF-IDF计算和文档聚类。
序列
S
S
S的后缀数组
A
\mathcal A
A是一个包含序列中所有后缀的词典排序列表。形式化为:
A
(
S
)
=
a
r
g
s
o
r
t
a
l
l
_
s
u
f
f
i
x
e
s
(
S
)
\mathcal A(\mathcal S)=arg~sort~all\_suffixes(\mathcal S)
A(S)=arg sort all_suffixes(S)
例如,序列“banana”的后缀为(“banana”,“ anana”,“nana”,“ana”,“na”,“na”,“a”),因此后缀数组是序列(6 4 2 1 5 3)。 实际上,我们从文本的BPE来构建
S
\mathcal S
S。
4.1.2 Substring matching
构建
A
\mathcal A
A后,识别重复训练样例是很简单的。假设在训练数据集位置
i
i
i和
h
h
h处序列
s
s
s中重复了两次,也就是说,
S
i
.
.
i
+
∣
s
∣
=
S
j
.
.
j
+
∣
s
∣
\mathcal S_{i..i+|s|}=\mathcal S_{j..j+|s|}
Si..i+∣s∣=Sj..j+∣s∣。那么,索引
i
,
j
i,j
i,j将在后缀数组
A
\mathcal A
A中相邻。
因此,查找所有重复序列是从头到尾线性扫描后缀数组的问题,并寻找序列
A
i
,
A
i
+
1
\mathcal A_i,\mathcal A_{i+1}
Ai,Ai+1,这两个序列共享长度超过某一阈值的共同前缀。记录所有满足的序列。该算法是平行的,因此我们可以有效地处理数据集。根据实验(附录B),我们为所有实验选择了50个BPE token的阈值长度。
4.2 Approximate Matching with MinHash
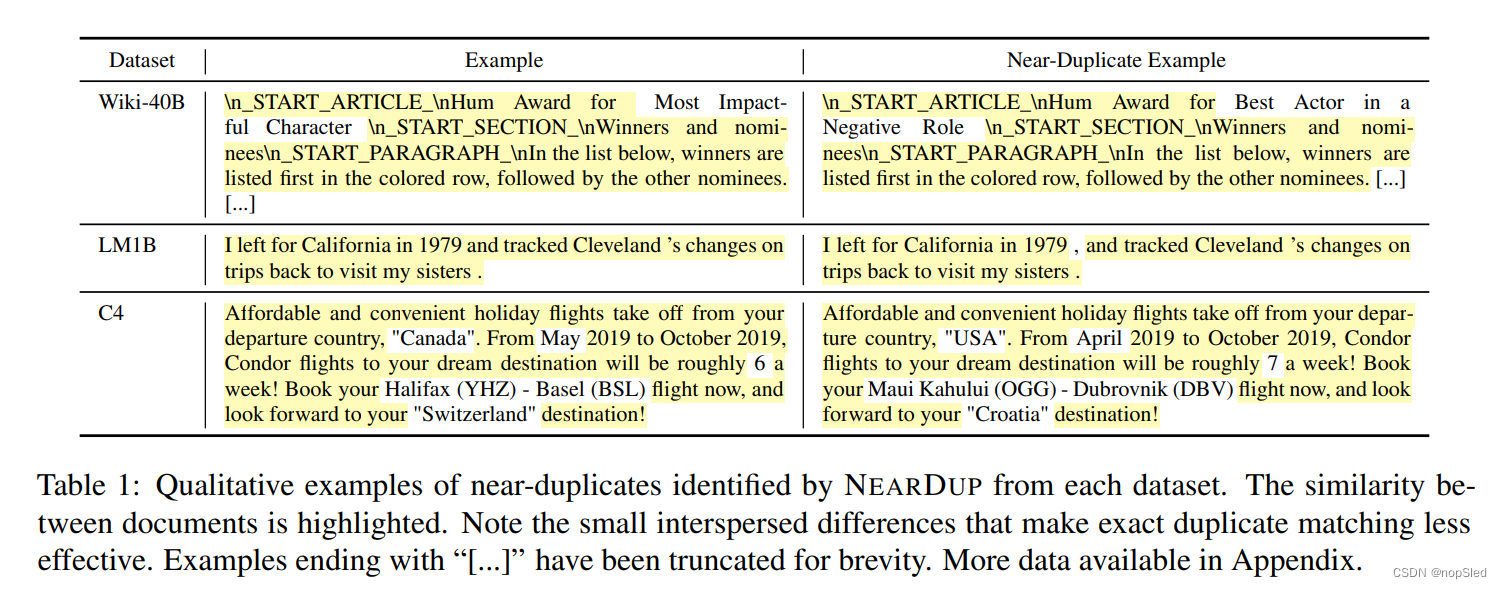
我们还基于匹配整个样例进行模糊去重。我们将该方法称为NEARDUP,其是对完全子字符串匹配的一个很好的补充,尤其是对于Web Crawl文本,因为它处理了非常常见的文档案例,例如模板文档(例如表1的最后一行) 。
MinHash是一种广泛用于大规模去重任务的模糊匹配算法,包括为大型中文LM的训练集进行去重。给定两个文档
x
i
x_i
xi和
x
j
x_j
xj,主要思想是通过其各自的
n
−
g
r
a
m
n-gram
n−gram集
d
i
d_i
di和
d
j
d_j
dj表示每个文档。然后,我们可以使用哈希函数来近似jaccard索引:
J
a
c
c
a
r
d
(
d
i
,
d
j
)
=
∣
d
i
∩
d
j
∣
/
∣
d
i
∪
d
j
∣
Jaccard(d_i, d_j)=|d_i∩d_j|/|d_i∪d_j|
Jaccard(di,dj)=∣di∩dj∣/∣di∪dj∣
如果
d
i
d_i
di和
d
j
d_j
dj之间的Jaccard索引足够高,则文档很可能是彼此近似匹配。为了有效地近似jaccard索引,Minhash通过通过哈希函数对每个n-gram进行排序,然后仅保留
k
k
k个最小哈希的n-gram来构造文档签名。有多种方法可以通过这些签名构建Jaccard索引的估计器。
在我们的实现中,我们使用5-gram和9000大小的签名。将两个文档视为潜在匹配的概率是:
P
r
(
d
i
,
d
j
∣
J
a
c
c
a
r
d
(
d
i
,
d
j
)
=
s
i
,
j
)
=
1
−
(
1
−
s
i
,
j
b
)
r
Pr(d_i, d_j|Jaccard(d_i, d_j)=s_{i,j})=1-(1-s^b_{i,j})^r
Pr(di,dj∣Jaccard(di,dj)=si,j)=1−(1−si,jb)r
其中
b
=
20
b=20
b=20和
r
=
450
r=450
r=450,这是用户可以设置的参数,以控制过滤的长度。更多细节请看附录A。
对于每对被确定为潜在匹配的文档,可以将更昂贵的计算相似性指标用作后续的过滤步骤。特别是,如果通过MinHash算法匹配,并且它们的编辑相似度大于0.8,则我们将两个文档识别为重复。 令牌序列
x
i
x_i
xi和
x
j
x_j
xj之间的编辑相似度定义为:
E
d
i
t
S
i
m
(
x
i
,
x
j
)
=
1
−
E
d
i
t
D
i
s
t
a
n
c
e
(
x
i
,
x
j
)
m
a
x
(
∣
x
i
∣
,
∣
x
j
∣
)
EditSim(x_i, x_j)=1-\frac{EditDistance(x_i, x_j)}{max(|x_i|,|x_j|)}
EditSim(xi,xj)=1−max(∣xi∣,∣xj∣)EditDistance(xi,xj)
为了构建相似文档的类簇,我们构造了一个图,如果两个文档被认为是匹配的,则在两个文档之间具有边。然后,我们使用Ł˛acki et al. (2018) 中引入的方法,确定连接的组件。附录A中给出了所需的计算分解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









