






 LENS是一种模块化方法,通过视觉模块的文本描述利用LLM进行计算机视觉任务,如目标识别和V&L任务,无需多模态预训练或额外数据。这种方法使用预训练的视觉模块和LLM,展示出在zero-shot和few-shot设置中的有效性。
LENS是一种模块化方法,通过视觉模块的文本描述利用LLM进行计算机视觉任务,如目标识别和V&L任务,无需多模态预训练或额外数据。这种方法使用预训练的视觉模块和LLM,展示出在zero-shot和few-shot设置中的有效性。
摘要
我们提出了LENS,这是一种通过利用大语模型(LLM)的力量来解决计算机视觉问题的模块化方法。我们的系统基于一组独立和高度描述化的视觉模块的输出,以使用语言模型来推理,这些模块提供了有关图像的详尽信息。我们评估了纯计算机视觉设置的方法,例如zero-shot和few-shot目标识别以及视觉语言问题。可以将LENS应用于任何现成的LLM,我们发现带有LENS的LLM在更大,更复杂的系统中表现出色,而无需任何多模态训练。我们在 https://github.com/ContextualAI/lens 上开放了代码,并提供交互式演示demo。
1.介绍
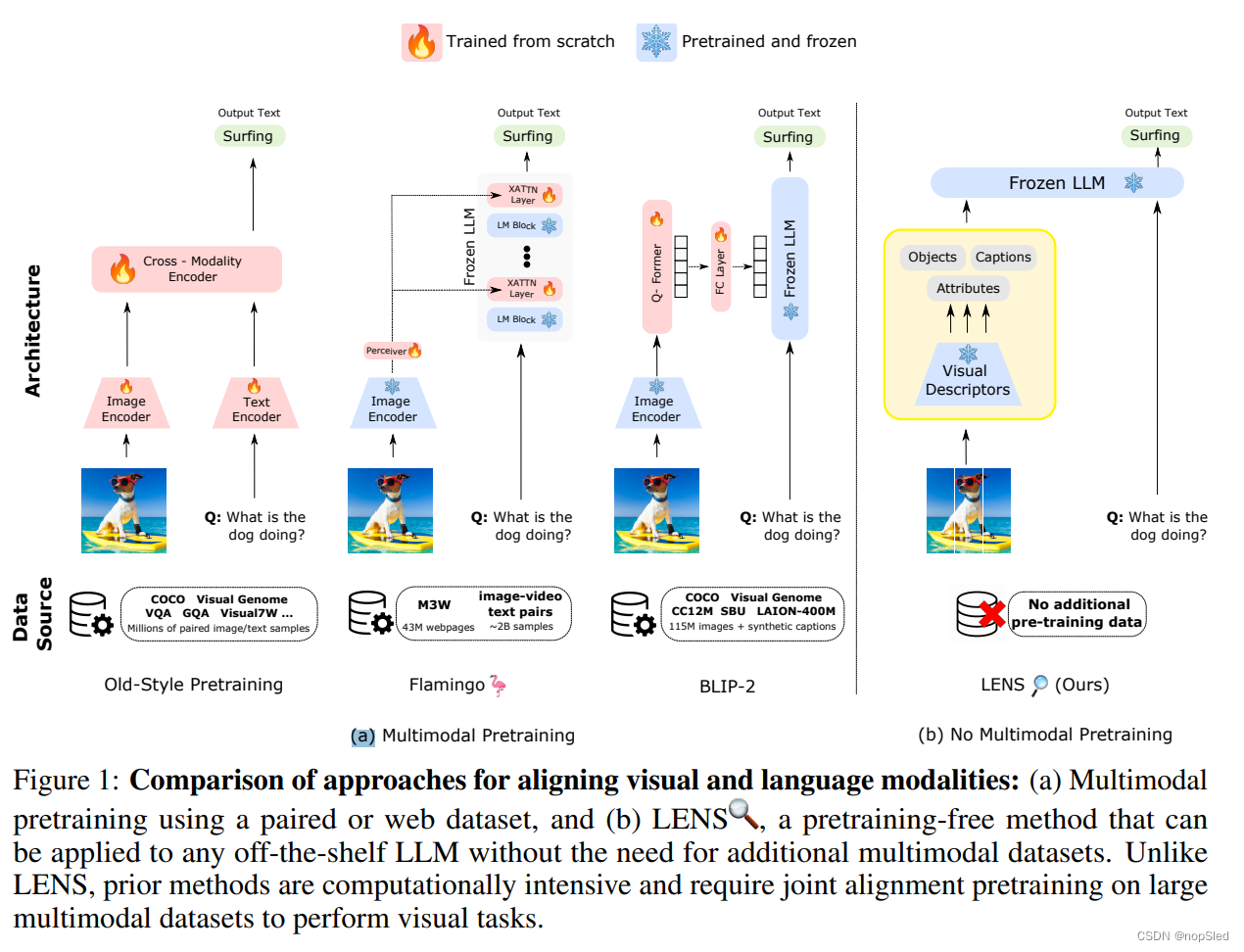
近年来,大型语言模型(LLM)彻底改变了自然语言理解,并在语义理解,问答和文本生成方面展示了显着能力,尤其是在zero-shot和few-shot的设置中。如图1(a)所示,已经提出了几种在视觉相关任务上使用LLM的方法。一种技术涉及训练视觉编码器以将每个图像表示为连续嵌入的序列,从而实现LLM的理解。另一个种采用了一个参数固定的视觉编码器,该编码器已受过对比训练,同时将新的层引入参数固定的LLM,这些层随后从头开始进行训练。此外,另一种方法表明,同时使用参数固定的视觉编码器(进行了对比预训练)和LLM,并通过训练轻量级transformer进行对齐。
尽管我们已经在上述研究方向上看到了进步,但与其他预训练阶段相关的计算费用仍然是一个挑战。此外,还需要大量包含图像/视频以及文本的数据集,以在现有LLM之上使视觉和语言模态对齐。一个例子是Flamingo,它将新的交叉注意力层引入LLM中以结合视觉特征,然后将其进行预训练。尽管使用了参数个定的预训练图像编码器和预训练LLM,但多模态的预训练阶段仍然需要惊人的20亿张图像文本对以及4300万个网页,这项工作可以持续约15天。取而代之的是,如图1(b)所示,我们可以使用一组“视觉模块”,从视觉输入中提取信息,并生成详细的文本表示(例如标签,属性,动作,关系等),然后直接将此信息直接带入到LLM中,以避免其进行多模态训练。
我们介绍了LENS (Large Language Models ENnhanced to See),这是一种模块化方法,该方法利用LLM作为“推理模块”,并在独立的“视觉模块”上运行。在LENS方法中,我们首先使用预训练的视觉模块(例如对比模型和图像释义模型)提取丰富的文本信息。随后,文本被带入LLM,允许其执行目标识别,视觉和语言(V&L)任务。LENS消除了对额外多模态预训练阶段或数据的需求,以零成本桥接了模态之间的差距。通过集成LENS,我们获得了一个模型,该模型没有任何其他跨领域间的预训练,且开箱即用。此外,这种开箱即用的集成使我们能够利用最新的计算机视觉和自然语言处理中模型,从而最大程度地利用从这些领域获得的好处。
总的来说,我们的贡献如下:
- 我们提出了LENS,这是一种模块化方法,该方法通过视觉输入的自然语言描述来利用语言模型的few-shot,ICL的能力来解决计算机视觉任务。
- LENS使任何现成的LLM都能具有视觉能力,而无需辅助训练或数据。我们利用参数固定的LLM来处理目标识别和视觉推理任务,而无需其他视觉和语言对齐或多模态数据。
- 实验结果表明,我们的方法在zero-shot设置上实现了可比或优于端到端的共同训练模型,例如Kosmos和Flamingo。
2.Related Work
2.1 Large Language Models capabilities
LLM已表现出出色的自然语言理解和推理能力。GPT-3是此类模型的一个代表示例,可以以zero-shot或few-shot设置准确地解决复杂的任务,包括翻译,自然语言推理和常识推理。最近,更强大的版本(例如GPT-3.5和GPT-4)旨在理解,交互和生成类似人类的响应。这些模型还以其在提示中使用一些样例来执行各种任务的能力而闻名。最近还做出了开发可以与GPT-3竞争的开源LLM,例如BLOOM,OPT,LLaMA,FlanT5等。但是,所有这些模型都无法直接解决需要从视觉输入中进行推理的任务。我们的工作利用这些LLM作为参数固定的语言模型,并为它们提供从“视觉模块”获得的文本信息,从而使它们可以执行目标识别和V&L任务。
2.2 Contrastive Models for Solving Vision and Language tasks
[47, 50, 23, 13, 61] 之类的基础模型已经证明了基于外部词表的任何视觉分类的能力,而无需限制有监督模型中的类或标签。但是,以前的工作表明,这些对比模型无法直接解决zero-shot或few-shot设置的任务。为了解决这个问题,[51]在VQA任务中提出了CLIP,其通过将问题转换为CLIP可以回答的mask模板,但是他们的方法需要微调以将模型的功能扩展到其他任务,例如visual entailment。在我们的工作中,我们提出利用对比模型的能力,并将它们与众包标注的开源词表结合使用,以分配图像中存在的标签和属性,这些标签和属性与参数固定的LLM结合可以解决多样化的V&L任务。
2.3 Large Language Models for Vision Applications
2.3.1 Image Captioning
近年来,图像释义的领域引起了巨大的兴趣,其目标是为图像生成自然语言描述。为此,已经提出了各种深度学习模型。值得注意的是,最近的模型包括BLIP和BLIP-2,它们在NoCaps和COCO数据集上具有出色的性能。同时,在BLIP-2中,ChatGPT被利用来生成更丰富的视觉描述。在另一项工作中,Socratic Models和Visual Clues还使用文本数据来桥接视觉语言模型和语言模型之间的领域差距。特别是,Visual Clues使用结构化文本提示构建图像的语义表示,其中包括图像标签,目标属性/位置和释义。这种方法利用GPT-3大语言模型来生成图像释义。我们的工作灵感来自Visual Clues,但是我们没有生成释义,而是使用参数固定的LLM,以利用原始的视觉信息来解决视觉任务。
2.3.2 Vision and Language tasks
可以通过多种方式利用LLM来执行V&L任务,主要分为两个部分。
Multimodal pretraining。这些方法以不同的方式使视觉和语言模态保持对齐。例如,Tsimpoukelli et al. [55],选择仅微调视觉编码器并生成能带入参数固定的LLM的嵌入。其他的,例如Flamingo,训练额外的交叉注意力层以进行对齐。BLIP2和Mini-GPT4之类的工作在固定视觉编码器参数的同时,降低了额外层的大小并预训练一个轻量化模块。但是,在所有情况下,视觉和语言的联合对齐都需要大量的计算资源和训练数据,这使得利用最先进的LLM成为挑战。此外,这些方法可能会阻碍LLM的推理能力。
Language-driven Modular Alignment。这些方法将LLM与不同的模块相耦合,以使视觉和语言模态对齐。同期工作Guo et al. [17]使用现成的LLM来求解纯视觉问答任务,例如VQA 2.0 和OK-VQA。相比之下,LENS扩展了LLM的能力来解决目标识别任务,并且也不涉及任何问题引导的信息提取。另一项工作,PromptCap使用GPT-3的合成示例训练一个基于问题的释义模型,以求解VQA任务。相比之下,LENS利用“视觉模块”,而无需任何额外的训练阶段。同样,ViperGPT也利用黑盒LLM(例如Instruct-GPT和CodeX)在不同的VQA基准上取得了出色的结果,但在很大程度上依赖BLIP2,这需要额外的多模态预训练。 此外,上述所有方法都依赖于一种“自上而下”的方法,在这种方法中,注意力机制是由非视觉或特定于任务的上下文驱动的。但是,我们提出的方法与这些方法不同,因为我们采用了“自下而上”的方法。我们的方法不涉及任何问题引导的信息提取,这是一项更具挑战性的任务。尽管如此,LENS还是取得了与这些基于问题的模型可比的结果。
3.Method
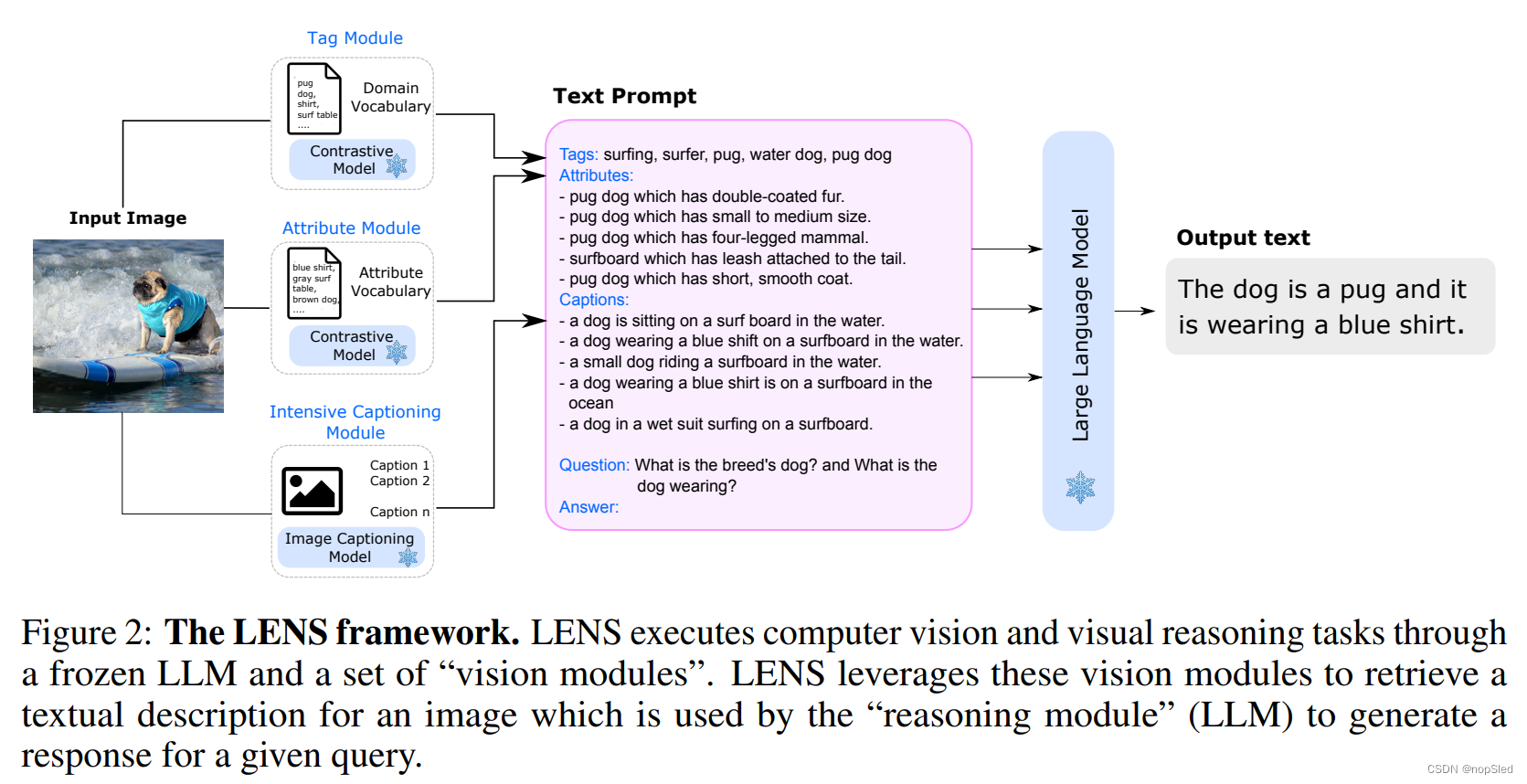
我们提出了一个名为LENS的新框架(图2),旨在通过使其能够在现有的自然语言理解能力之上处理视觉以及视觉语言任务来增强LLM的能力。与现有方法相比,LENS提供了一个统一的框架,可以促进LLM的"推理模块"对从一组独立且高度描述性的“视觉模块”中提取的文本数据进行操作。更重要的是,它通过在多模态数据上进行额外的联合预训练来消除了将视觉域与文本域对齐的计算开销,这是解决V&L任务在先前工作中的要求。
总而言之,给定一个图像
I
I
I,我们利用视觉模块来提取所有可以描述图像所包含对象,属性和释义的可能的文本信息
T
T
T,而无需将其限制为特定的任务指令。随后,参数固定的LLM可以处理与特定于任务的提示拼接后的通用提示
T
T
T,并执行目标识别或视觉推理任务。在本节中,我们介绍了“视觉模块”的基本要素,概述了LENS的主要组成部分,然后讨论提示设计。
3.1 Visual Vocabularies
对于LENS,视觉词表充当将图像转换为文本信息的桥梁,然后可以由现有LLM处理。我们为常见目标和属性开发词表。
Tags:为了为对比模型的图像标签创建多样化,全面的标签词表,我们从各种来数据源收集标签。 其中包括多个图像分类数据集,例如[48、33、46、41、4、4、57、28],目标检测和语义分割数据集以及视觉基因组数据集。
Attributes:遵循Menon & Vondrick [40]中提出的方法,我们采用了大语言模型GPT-3来生成视觉特征的描述,以区分我们目标词表中的每个目标类别。
3.2 LENS Components
LENS由3个不同的视觉模块和1个推理模块组成,每一个模块都提供特定目标输出。这些组件如下:
Tag Module。给定图像,该模块将识别标签并分配给图像。为此,我们采用了一个视觉编码器(CLIP),该编码器为每个图像选择最合适的标签。在我们的工作中,我们采用了一个常见的提示:“A photo of {classname}”进行目标标记,以使我们的框架在各种领域中更灵活,而无需手动/集合提示微调。我们将在第3.1节中构建的目标词表作为我们的tag选项。
Attributes Module。我们利用此模块来识别并将相关属性分配给图像中存在的目标。为此,我们采用了一个对比预训练的视觉编码器,称为CLIP,同时合并了[40]中概述的特定任务提示。视觉编码器根据第3.1节中生成的词表对目标进行分类。
Intensive Captioner。我们利用一个称为BLIP的图像释义模型,并应用随机top-K采样来生成每个图像的N个释义。这种方法使我们能够捕获包含在图像视觉中内容的各个方面。然后,这些不同的释义直接传递给“推理模块”而没有任何修改。
Reasoning Module。我们采用参数的LLM作为我们的推理模块,该模块能够根据视觉模块提供的文本描述以及特定于任务的指令来生成答案。LENS可以与任何黑盒LLM无缝集成,从而简化了为其增加视觉能力并加快整体速度的过程。
3.3 Prompt Design
通过从视觉模块获得的文本信息,我们通过组合他们来构建完整的提示。我们将标签模块格式化为Tags: {Top-k tags},属性模块格式化为Attributes: {Top-K attributes},释义模块格式化为Captions: {Top-N Captions}。 特别是,对于hateful-memes的任务,我们将OCR提示形式化为 OCR: this is an image with written “{meme text}” on it。最后,我们在提示末尾附加了特定的问题提示:Question: {task-specific prompt} \n Short Answer:。您可以在我们的演示中看到此提示。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









