






摘要
基于人类反馈的强化学习 (RLHF) 可以通过使大型语言模型 (LLM) 的输出与人类偏好保持对齐来提高其输出的质量。我们提出了一种简单的算法,使LLM与人类偏好保持对齐,其灵感来自不断增长的批量强化学习(RL),我们称之为Reinforced Self-Training (ReST)。给定初始 LLM 策略,ReST 通过策略生成样本来生成数据集,然后使用离线 RL 算法将数据集用于改进 LLM 策略。ReST 比典型的在线 RLHF 方法更有效,因为训练数据集是离线生成的,这允许数据重用。虽然 ReST 是可应用于所有生成式学习的通用方法,但我们重点关注其在机器翻译中的应用。我们的结果表明,ReST 可以显着提高翻译质量,这是通过以计算和样本高效的方式对机器翻译基准进行自动和人工评估来衡量的。
1.介绍
大型语言模型(LLM)在生成高质量文本和解决众多语言任务方面表现出了令人印象深刻的能力。这些模型经过使用大量文本的训练,可以用来自回归地最大化下一个token的似然。然而,Perez et al. (2022) 表明,生成具有高似然的文本不一定与人类在各种任务上的偏好完全对齐。如果没有适当的对齐,语言模型还可能输出不安全的内容,从而产生有害的后果。此外,对齐LLM有助于改进其他下游任务。来自人类反馈的强化学习(RLHF)旨在通过利用人类偏好来解决对齐问题。通常,人类反馈被用于训练一个奖赏模型,然后使用强化学习 (RL) 目标对 LLM 进行微调。
RLHF 方法通常依赖于在线 RL 方法,例如 PPO 和 A2C。在线训练需要从更新后的策略中进行采样,并在训练过程中多次使用奖赏模型对样本进行评分。处理这种连续新样本的计算成本成为在线方法的限制,特别是当策略和奖赏网络的规模增长时。此外,这些方法很容易被“黑客攻击”,之前的工作探索了模型正则化来缓解这个问题。或者,离线强化学习方法从固定的样例数据集中学习,因此它们的计算效率更高,并且不太容易受到奖赏黑客攻击。然而,离线学习后的策略质量不可避免地取决于离线数据集的属性。因此,精心设计的数据集对于离线强化学习的成功变得非常重要。否则,有监督学习的性能提升可能会受到限制。与我们工作同期,(Rafailov et al., 2023) 提出了一种称为 DPO(直接偏好优化)的方法,该方法可以利用离线数据使 LM 与人类偏好保持一致。
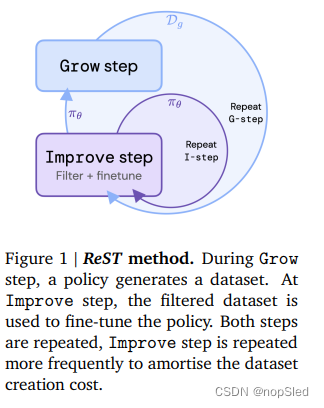
我们将语言模型的对齐问题视为一个不断增长的批量强化学习问题。具体来说,我们的Reinforced Self-Training (ReST) 方法包括两个循环:在内循环(Improve)中,我们在固定数据集上改进策略,在外循环(Grow)中,我们通过从最新策略中采样来增长数据集 (见图 1)。在这项工作中,我们考虑条件语言建模,那么ReST的步骤如下:
- Grow (G): 语言模型策略(最初是有监督策略)用于为每个上下文生成多个输出预测,以扩充训练数据集。
- Improve (I):我们使用评分函数对增强数据集进行排名和过滤。我们使用在人类偏好数据赏训练的奖赏模型作为实验中的评分函数。然后,使用离线 RL 目标基于过滤后的数据集对语言模型进行微调。可以通过增加过滤阈值来重复该步骤。最终的策略将用于下一个Grow步骤。
ReST 是一种通用方法,允许在 Improve 步骤中使用不同的离线 RL 损失。为了付诸实践,人们只需要具备以下能力:i)高效地从模型中采样,ii)对模型的样本进行评分。与在线或离线 RL 的典型 RLHF 方法相比,ReST 具有多种优势:
- 与在线 RL 相比,由于在多个 Improve 步骤中利用了 Grow 步骤的输出,计算负担显着减少。
- 策略的质量不受原始数据集质量的限制(如离线强化学习),因为新的训练数据是在 Grow 步骤中从改进的策略中采样的。
- 由于 Improve 和 Grow 步骤是分离的,因此可以轻松检查数据质量并诊断潜在的一致性问题,例如奖赏攻击。
- 该方法简单、稳定,只需调整少量超参数。
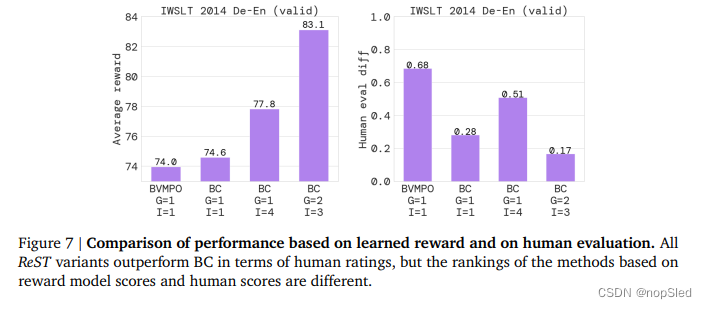
我们在第 3 节中描述了我们提出的 ReST 方法的细节。然后,我们在第 4 节中介绍了我们在机器翻译基准上的实验结果。机器翻译是一个序列到序列的学习问题,通常被表述为条件语言模型,其中条件上下文是一个外语句子(source)。我们选择机器翻译是因为: i) 它是一个有影响力的应用,具有强大的基线和明确的评估程序,ii) 几种现有的可靠评分和评估方法可用作奖赏模型。在我们的实验中,我们在 IWSLT 2014 和 WMT 2020 基准测试以及 Web Domain 上更具竞争力的高保真内部基准测试上比较了几种离线 RL 算法。在我们的实验中,ReST 显着提高了测试和验证集上的奖赏模型分数。此外,根据人类评估者的说法,与有监督学习基线相比,ReST 生成的翻译质量更高。
2.Preliminaries
给定上下文(或源输入)
x
=
(
x
1
,
x
2
,
.
.
.
x
L
)
\textbf x=(x_1, x_2, ...x_L)
x=(x1,x2,...xL),条件语言模型会生成输出序列
y
=
(
y
1
,
y
2
,
.
.
.
.
y
T
)
\textbf y=(y_1, y_2, ....y_T)
y=(y1,y2,....yT),其中token
x
l
x_l
xl,
y
t
y_t
yt属于选择的词表中。自回归模型中的语言生成策略
π
\pi
π的特征是由
θ
\theta
θ参数化的条件概率分布:
π
θ
(
y
∣
x
)
=
∏
t
=
1
T
π
θ
(
y
t
∣
y
1
:
t
−
1
,
x
)
,
\pi_{\theta}(\textbf y|\textbf x)=\prod^T_{t=1}\pi_{\theta}(y_t|\textbf y_{1:t-1},\textbf x),
πθ(y∣x)=t=1∏Tπθ(yt∣y1:t−1,x),
其中,
y
1
:
0
=
∅
\textbf y_{1:0}=\emptyset
y1:0=∅,并且
y
1
:
t
−
1
=
(
y
1
,
y
2
,
.
.
.
,
y
t
−
1
)
\textbf y_{1:t-1}=(y_1,y_2,...,y_{t-1})
y1:t−1=(y1,y2,...,yt−1)。
令
p
(
x
,
y
)
=
p
(
x
)
p
(
y
∣
x
)
p(\textbf x,\textbf y)=p(\textbf x)p(\textbf y|\textbf x)
p(x,y)=p(x)p(y∣x)表示数据分布。一个给定的数据集
D
\mathcal D
D由服从下面分布的样例组成:
D
=
{
(
x
i
,
y
i
)
∣
i
=
1
N
s
u
c
h
t
h
a
t
x
i
∼
p
(
x
)
,
y
i
∼
p
(
y
∣
x
=
x
i
)
}
.
\mathcal D=\{(\textbf x^i,\textbf y^i)|^N_{i=1}~such~that~\textbf x^i\sim p(x),\textbf y^i\sim p(\textbf y|\textbf x=\textbf x^i)\}.
D={(xi,yi)∣i=1N such that xi∼p(x),yi∼p(y∣x=xi)}.
给定数据集,有监督策略通过最小化负对数似然损失来训练:
L
N
L
L
(
θ
)
=
−
E
(
x
,
y
)
∼
D
[
∑
t
=
1
T
l
o
g
π
θ
(
y
t
∣
y
1
:
t
−
1
,
x
)
]
(1)
\mathcal L_{NLL}(\theta)=-\mathbb E_{(x,y)\sim\mathcal D}\bigg[\sum^T_{t=1}log~\pi_{\theta}(y_t|\textbf y_{1:t-1},\textbf x)\bigg]\tag{1}
LNLL(θ)=−E(x,y)∼D[t=1∑Tlog πθ(yt∣y1:t−1,x)](1)
我们将用NLL损失进行训练的模型称为行为克隆(BC),这遵循RL文献。
3.Reinforced Self-Training (ReST)
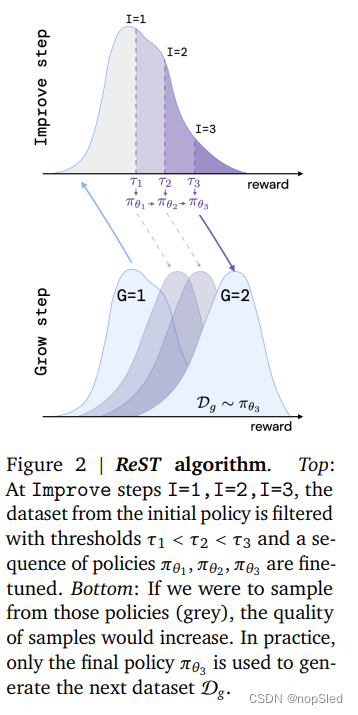
我们提出了 ReST,这是一种 RLHF 算法,可以将语言模型的输出与人类偏好保持对齐。人类对生成序列的偏好是使用一个可学习的奖赏函数来建模的(参见附录 A.4)。在条件语言建模的底层马尔可夫决策过程中,状态是部分序列,动作是生成的token(参见附录 A.1)。
ReST 算法将典型 RL 管道(数据集增加和策略提升)解耦为单独的离线阶段(图 1 和 2)。我们首先训练一个初始模型
π
θ
(
y
∣
x
)
\pi_{\theta}(\textbf y|\textbf x)
πθ(y∣x),以使用等式(1)中的 NLL 损失将给定的序列对数据集
D
\mathcal D
D中的输入序列
x
\textbf x
x映射输出序列
y
\textbf y
y。接下来,Grow 步骤构建一个新的数据集
D
g
\mathcal D_g
Dg,它使用模型中的样本来扩充初始训练数据集:
D
g
=
{
(
x
i
,
y
i
)
∣
i
=
1
N
g
s
u
c
h
t
h
a
t
x
i
∼
D
,
y
i
∼
π
θ
(
y
∣
x
i
)
}
∪
D
D_g=\{(\textbf x^i,\textbf y^i)|^{N_g}_{i=1}such~that~\textbf x^i\sim\mathcal D,\textbf y^i\sim\pi_{\theta}(\textbf y|\textbf x^i)\}\cup \mathcal D
Dg={(xi,yi)∣i=1Ngsuch that xi∼D,yi∼πθ(y∣xi)}∪D
其中,条件输入是从原始数据集
x
i
∼
D
\textbf x^i\sim\mathcal D
xi∼D 中重新采样的,就像self-training一样,但在可以访问
p
(
x
)
p(\textbf x)
p(x) 的情况下,他们可以直接从中采样,即
x
i
∼
p
(
x
)
\textbf x^i\sim p(\textbf x)
xi∼p(x)。例如,考虑一个根据文本描述生成图像的模型,在这种情况下,文本输入的分布可以从语言模型
p
(
x
)
p(\textbf x)
p(x) 中采样。
随后,Improve步骤使用
D
g
\mathcal D_g
Dg 来微调策略
π
θ
\pi_{\theta}
πθ。请注意,我们将原始数据集保留在训练混合数据中,以确保策略不会发散。下面,我们将更详细地描述“Grow和Improve”步骤。
3.1 Grow
Grow 步骤对应于强化学习中的操作或数据生成步骤。我们通过从当前策略 π θ \pi_{\theta} πθ中采样许多输出序列来创建轨迹的增强数据集 D g D_g Dg,即 x ∼ D , y ∼ π θ ( y ∣ x ) \textbf x\sim\mathcal D, \textbf y\sim\pi_{\theta}(\textbf y|\textbf x) x∼D,y∼πθ(y∣x)。然后使用奖赏函数 R ( x , y ) R(\textbf x,\textbf y) R(x,y)对新的数据序列进行评分。奖赏高于阈值分数的数据用于更新策略(见下文)。一旦策略得到改进,就可以再次创建质量更好的新数据集(图 2,底部)。
3.2 Improve

在Improve步骤(强化学习术语中的策略提升),目标是使用新的数据集
D
g
\mathcal D_g
Dg 来微调策略
π
θ
\pi_{\theta}
πθ。我们首先定义一个过滤函数,该函数仅保留奖赏高于特定阈值
τ
\tau
τ的样本:
F
(
x
,
y
,
τ
)
=
1
R
(
x
,
y
)
>
τ
.
F(\textbf x,\textbf y, \tau)=\mathbb 1_{R(\textbf x,\textbf y)\gt \tau}.
F(x,y,τ)=1R(x,y)>τ.
我们注意到,基于阈值的过滤函数可能会导致学习次优行为,这些行为容易在随机动态环境中产生具有高方差的结果。然而,在这项工作中,我们将语言建模和翻译任务表述为确定性强化学习问题(附录 A.1)。
接下来,我们微调当前的最优策略,通常使用等式 1 中的有监督学习损失
L
N
L
L
\mathcal L_{NLL}
LNLL 或过滤数据上的离线 RL 损失
L
(
x
,
y
;
θ
)
\mathcal L(\textbf x,\textbf y;\theta)
L(x,y;θ)(例如 V-MPO 或离线 actor-critic)进行训练。综上所述,我们使用以下奖赏加权损失
J
J
J:
J
(
θ
)
=
E
(
x
,
y
)
∼
D
g
[
F
(
x
,
y
,
τ
)
L
(
x
,
y
;
θ
)
]
.
(2)
J(\theta)=\mathbb E_{(x,y)\sim\mathcal D_g}[F(\textbf x,\textbf y,\tau)\mathcal L(\textbf x,\textbf y;\theta)].\tag{2}
J(θ)=E(x,y)∼Dg[F(x,y,τ)L(x,y;θ)].(2)
4.Experiments and analysi


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









