






 文章探讨了如何通过改进位置编码策略和评估方法来扩展大语言模型(LLM)的上下文长度。研究者比较了不同外推技术,发现线性缩放是最有效的,并介绍了新模型Giraffe。文章还强调了困惑度在衡量长上下文性能的局限性,提出了新的评估任务和数据集。
文章探讨了如何通过改进位置编码策略和评估方法来扩展大语言模型(LLM)的上下文长度。研究者比较了不同外推技术,发现线性缩放是最有效的,并介绍了新模型Giraffe。文章还强调了困惑度在衡量长上下文性能的局限性,提出了新的评估任务和数据集。
摘要
依赖于注意力机制的现代大语言模型(LLM)通常使用固定的上下文长度进行训练,这对它们在评估时可以处理的输入序列的长度施加了上限。为了在比训练上下文长度更长的序列上使用模型,人们可以采用不断更新的上下文长度外推方法系列中的技术——其中大多数集中于修改注意力机制中使用的位置编码系统,以表明token或激活位于输入序列的哪个位置。 我们对基于 LLaMA 或 LLaMA 2 模型的现有上下文长度外推方法进行了广泛的调查,并介绍了我们自己的一些设计,特别是用于修改位置编码基础的truncation策略。
我们使用三个新的评估任务(FreeFormQA、AlteredNumericQA 和 LongChat-Lines)以及困惑度来测试这些方法,我们发现困惑度作为LLM长上下文性能的衡量标准缺少细粒度。我们将这三个任务作为数据集公开发布在 HuggingFace 上。我们发现线性缩放是扩展上下文长度的最佳方法,并表明在评估时使用更长的缩放可以实现进一步的增益。我们还在截断的基础上发现了有希望的外推能力。为了支持该领域的进一步研究,我们发布了三个新的 13B 参数的长上下文模型,我们称之为 Giraffe:从基础 LLaMA-13B 训练的 4k 和 16k 上下文模型,以及从基础 LLaMA2-13B 训练的 32k 上下文模型。我们还开源了代码来复现我们的结果。
1.介绍
近年来,Transformer 凭借其灵活性和在超大数据集上训练的适应性,已成为各种自然语言建模任务中的主要神经网络结构。随后,对于这些神经网络采用了一个流行术语,即“大语言模型”(LLM)——“大”指的是训练数据集大小及其参数数量(实际上,还有相关的训练和环境成本)。
标准transformer架构的一个关键要素是其对输入序列的顺序不敏感。注意力操作是一种类似集合的操作,其中元素的位置并不重要。然而,序列中元素的顺序对于许多任务(例如解析自然语言、编码、预测等)至关重要。因此,有必要将位置信息以位置编码的形式注入到 LLM 的输入中。
位置编码方案的一个可能的需求是上下文长度外推:能够使用 LLM 对比训练时长度更长的输入序列进行推理。由于 Transformer 中注意力机制的复杂度呈二次方增长,因此在大上下文长度上进行训练通常是不可行的。增加上下文长度的好处是多种多样的——允许阅读更长的文档和论文、在 LLM 支持的聊天机器人中与用户进行长时间对话时获得更多的内部一致性、处理更大的代码库等等。我们可以将上下文长度外推分为两个主要框架。首先,是finetuned extrapolation,其允许首先在较短上下文上预训练模型,然后基于较长上下文长度进行微调或更新模型权重。此外,还存在zero-shot extrapolation,其中首先在短上下文上预训练模型,并使用与较短上下文模型相同的权重,在较长上下文长度上进行评估。
在本文中,我们主要关注zero-shot extrapolation,并做出以下关键贡献:
Benchmark of different context extrapolation schemes。我们对使用一个预训练基础模型进行上下文长度外推的方法进行了调查,并尝试了一些我们自己的发明。特别是,我们为位置编码提出了新的truncated基础。本文对预训练模型的关注也不同于文献中的其他工作,后者倾向于使用选定的位置编码方案从头开始训练。如上所述,虽然LLM取得了成功,但训练他们是一项成本高昂的过程。著名的闭源模型包括 GPT-4 和 Claude。最近,Meta AI 的团队发布了开源的 LLaMA,随后又发布了改进的 LLaMA2。我们认为,训练这种性质的竞争基础模型所需的资源仍将仅限于少数大型玩家。因此,必须能够根据最终用户的需要修改模型——理想情况下,只需应用一小部分计算能力。
我们的主要发现是:
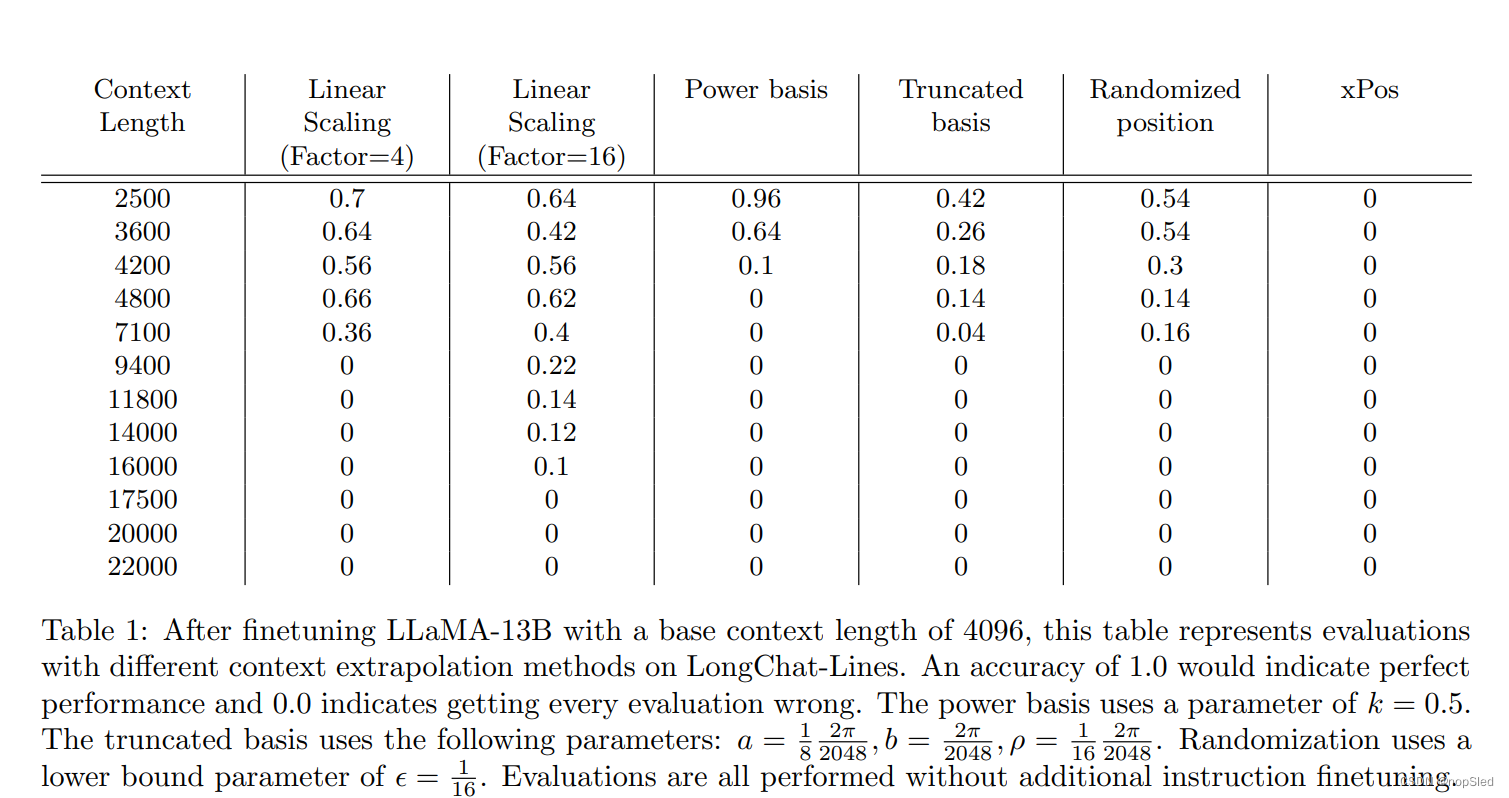
- 线性插值是最好的上下文长度外推方法。
- 所有上下文长度外推方法都显示出了任务准确性的下降,即使对于它们提供了一致输出的长度(并且困惑度分数仍然合理)。
- 通过在评估时使用比微调时更高的缩放因子,可以实现上下文长度的进一步增加,但似乎最多只能达到 2 倍。
Public release of LLM weights and evaluation datasets。我们在 HuggingFace 上发布了从基础 LLaMA 训练的两个新 13B 模型的权重,扩展上下文长度分别为 16k和4k。我们还发布了一个 13B 模型,从基础 LLaMA 2 训练到长度为 32k。我们将这个模型家族称为 Giraffe。此外,我们还发布了三个数据集(LongChat-Lines FreeFormQA 和 AlteredNumericQA)来评估这些模型和其他模型的长上下文性能。LongChat-Lines 是一个key-value细粒度检索任务。FreeFormQA 和 AlteredQA 是基于自然问题数据集的问答数据集。一些现有的工作仅关注文档语料库评估集的困惑度作为外推性能的衡量标准。我们发现,困惑度分数并不像我们引入的任务那样敏感地衡量长上下文性能。
2.Related Work
RoPE。在这项工作中,我们检查了 LLaMA 选择的位置编码在使用比训练基本模型更长的上下文序列时的有效性。LLaMA 使用的位置编码是 RoPE (Rotary Position Embedding)。RoPE 的工作原理是以不同的速度旋转query矩阵和key矩阵的切片。因此,例如,即使query和key被投影到相同的编码,它们也会根据它们在序列中的位置而旋转不同的量。如果它们随后未对齐,则它们的点积将比根本不旋转时的点积更小。相反,它们可能会变得更加一致,从而产生更大的点积和注意力得分。在 RoPE 中,这种旋转在嵌入维度的quey和key的所有 2 个切片上以不同的速度发生,从而允许模型构建随距离变化的注意力分数的复杂函数。利用 RoPE 方法的主要吸引力之一是它在数学上确保注意力评分函数仅依赖于query和key之间的相对距离,而不是它们的绝对位置。这被认为是LLM的一个理想特性。
ALiBi。尽管 RoPE 在这一目标上取得了成功,但 ALiBi 上的工作表明 RoPE 无法执行零样本上下文长度外推。ALiBi 论文表明,当RoPE在比模型训练期间看到的上下文长度更长的上下文长度上进行测试时,很快就会发生退化;该工作还提出了自己的替代方案,该替代方案在其基准上显示出卓越的外推能力。然而ALiBi也有其自身的缺点;它使用简单的线性函数来调节随距离改变的注意力分数,这意味着它不能像 RoPE 的傅里叶基那样表示复杂的距离注意力函数。此外,ALiBi 每个头使用一个这样的函数,进一步降低了表达能力。这也许可以解释为什么,尽管 ALiBi 确实进行了外推,但使用它的模型在 MMLU 和测量人类偏好的 LMSys arena 等基准上的性能比基于 RoPE 的模型要差。
xPos。Sun et al. [7]检查了 RoPE 未能成功外推的原因,并确定这是由于高频分量的影响导致了注意力分数中的残留噪声,即使token相隔很远也是如此。他们试图通过在 RoPE 中添加指数衰减幅度项来解决这个问题。这种称为 xPos 的新方法比低频分量更快地衰减这些嘈杂的高频分量。该方法在LLM的从头开始训练中显示出良好的效果,并且这与我们对 RoPE 缺陷的假设相一致。然而,Sun et al. 没有在我们感兴趣的设置中进行实验:采用 RoPE 预训练的模型,看看是否可以引导它(通过有限的微调)来学习 xPos 编码。此外,他们的实验表明,Blockwise因果注意力对于他们实现外推是必要的。
Linear Scaling/Positional Interpolation。这种简单但有效的上下文长度外推技术由 kaiokendev 和 Meta 的团队同时报告。这里使用的方法是简单地将位置向量除以适合原始模型上下文长度内输入的缩放因子。这种技术的直觉是利用LLM的插值能力,而不是依赖于外推法。众所周知的现象是,神经网络倾向于在先前看到的取值范围内进行插值,而不是在该范围之外进行外推(例如[18])。在位置编码的特定情况下,使用位置插值避免了与外推相关的注意力值出现大规模数值爆炸的风险。我们对该方案及其变体进行了许多实验,并在本文中报告了结果。
Randomized Positional Encodings。Ruoss et al 在 [19] 中介绍了这种方法。在训练过程中,它们通过从范围
[
1
,
L
]
[1, L]
[1,L] 中均匀地抽取
N
N
N 个样本而不进行替换来随机生成位置向量,其中
N
N
N 是训练上下文长度,
L
L
L 是大于最大评估上下文长度的值(假设事先已知)。然后,这些采样位置按升序排序,并充当模型在评估时看到的位置输入。在评估期间,位置输入
[
1
,
.
.
.
,
M
]
[1, ..., M]
[1,...,M] 被提供给模型。作者声称上下文长度外推的性能得到了提高。我们独立地得出了与该论文类似的想法,但通过从大约
[
1
,
N
]
[1, N]
[1,N] 范围内的子整数位置进行随机抽取;详细信息请参见第 4 节。我们还注意到,Ruoss 等人研究了使用这种方案从头开始训练 LLM,而我们主要感兴趣的是通过随机化对预训练的 LLM 进行事后微调,以实现上下文长度外推。
3.Assessing Long Context Extrapolation
4.Context Length Extrapolation Techniques
我们研究了几种上下文长度外推技术,包括现有的方法(或它们的细微变化)以及我们自己新提出的方法。
4.1 Existing Context Length Extrapolation Techniques
有几种方法可以使 RoPE 位置编码适应更长的上下文长度。我们评估了以下技术。
Linear Scaling/Positional Interpolation。其中,位置矢量除以缩放因子。因此,如果原始模型在一系列位置
[
0
,
1
,
.
.
.
,
2048
]
[0, 1, ..., 2048]
[0,1,...,2048] 上进行训练,那么新模型将看到
[
0
x
,
1
x
,
.
.
.
,
2048
x
]
[\frac{0}{x},\frac{1}{x}, ...,\frac{2048}{x}]
[x0,x1,...,x2048],其中
x
x
x 是缩放因子 。
xPos。我们想要检查基于基本模型 RoPE 编码方案训练的检查点是否可以针对 xPos 方案进行微调。除了修补整个注意力模块以处理 xPos 独特的key和query转换的编程障碍之外,这种适应带来的主要问题是 xPos 对浮点精度的敏感性。该方法依赖于通过具有大(绝对)指数的数值来缩放key;这些稍后会在query的点积中取消。然而,对于长上下文,大值实际上可能超过 float16 支持的大小。我们选择通过在 float32 中执行核心注意力操作来解决这个问题,但代价是训练速度减慢了 2 倍。
Randomized Position Encodings。这里,我们在
[
ϵ
,
2
]
,
0
<
ϵ
≪
1
[ϵ, 2], 0 < ϵ ≪ 1
[ϵ,2],0<ϵ≪1的范围内均匀地随机化位置值之间的距离 ,而不是使用具有固定大小为
1
1
1 的间隔距离
[
0
,
1
,
.
.
.
,
n
]
[0, 1, ..., n]
[0,1,...,n]。这种方法背后的直觉是,通过在微调时向模型显示许多不同的内部位置距离,该模型将能够在评估时推广到任何细粒度位置的选择,从而通过选择更小的距离来有效增加上下文长度。这与 Ruoss et al. [19] 中描述的过程有一些相似之处。我们设置上限为
2
2
2,以便模型期望看到最终位置
n
n
n(对于
X
∼
U
(
ϵ
,
2
)
,
E
[
X
]
≈
1
X ∼ U(ϵ, 2),\mathbb E[X] ≈ 1
X∼U(ϵ,2),E[X]≈1)。我们还设置了一个正的、非零的
ϵ
ϵ
ϵ 下界,以避免由于数值精度有限而导致位置混叠问题。
4.2 Newly Proposed Context Length Extrapolation Techniques
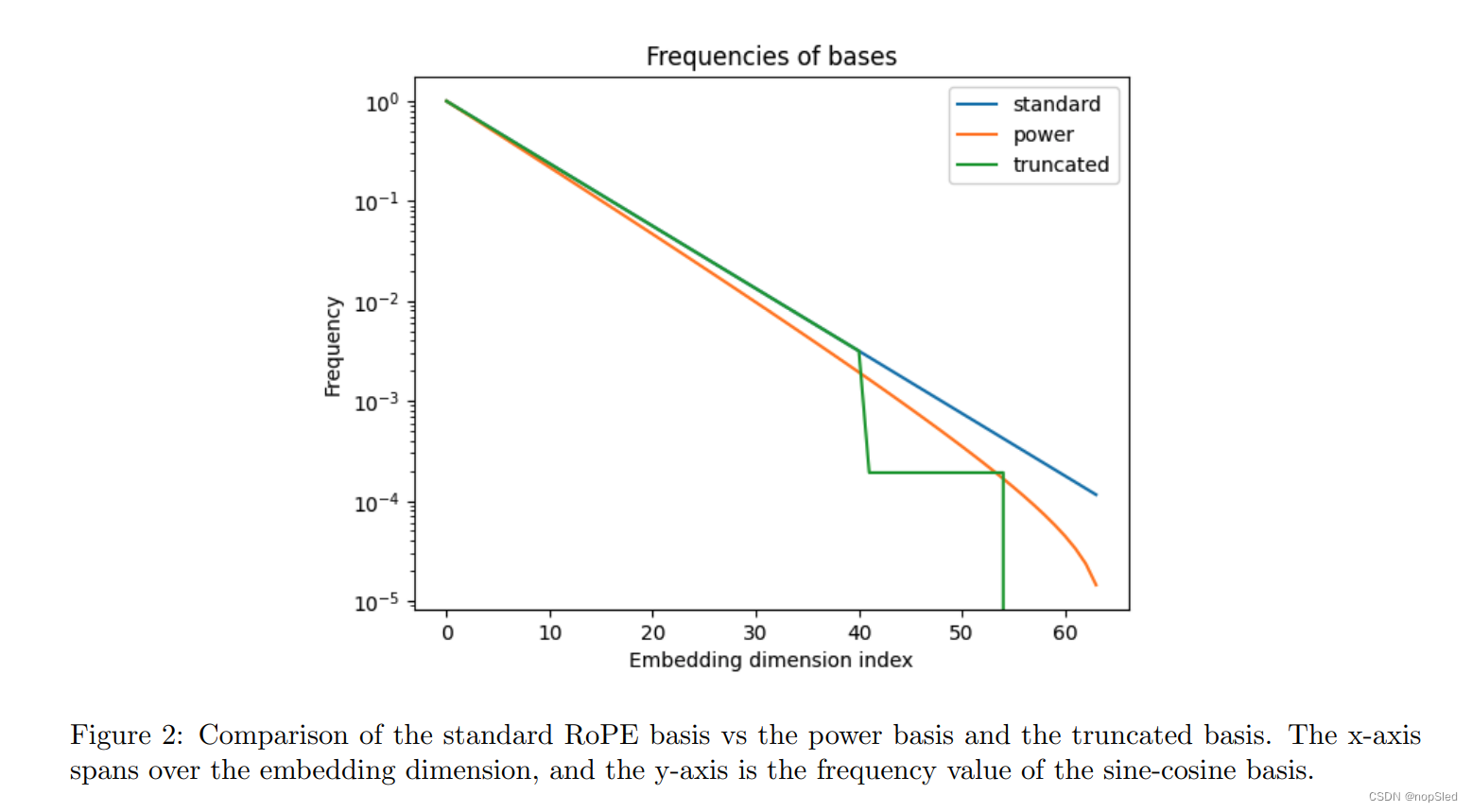
Power Scaling。在原始 RoPE 中,所使用的基础由下式给出:
Θ
=
{
θ
i
=
1000
0
−
2
(
i
−
1
)
d
∣
i
∈
{
1
,
2
,
.
.
.
,
d
2
}
}
(1)
\Theta=\{\theta_i=10000^{-\frac{2(i-1)}{d}}|i\in\{1,2,...,\frac{d}{2}\}\}\tag{1}
Θ={θi=10000−d2(i−1)∣i∈{1,2,...,2d}}(1)
其中
d
d
d 是嵌入维度。 我们使用以下给出的基础:
Θ
∗
=
{
θ
i
∗
=
θ
i
(
1
−
2
i
d
)
k
∣
i
∈
{
1
,
2
,
.
.
.
,
d
2
}
}
(2)
\Theta^*=\bigg\{\theta^*_i=\theta_i(1-\frac{2i}{d})^k|i\in\{1,2,...,\frac{d}{2}\}\bigg\}\tag{2}
Θ∗={θi∗=θi(1−d2i)k∣i∈{1,2,...,2d}}(2)
其中
k
k
k 是要设置的参数。通过应用这种变换,基础的高频(短距离)元素比低频(长距离)元素受到的影响更小,低频(长距离)元素的频率甚至更低 - 见图 2。通过这样做,我们希望 模型必须对低频执行不太复杂的外推,因为在训练期间它没有看到周期函数的全部范围,从而更好地外推。然而,一个潜在的问题是,该模型依赖于线性变换保留但非线性变换破坏的跨频率的特定关系。
Truncated Basis。从公式 1 开始,我们改为使用通过应用以下给出的基础:

5.Results & Discussion


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









