






摘要
生成式大型语言模型 (LLM),例如 ChatGPT,提供交互式 API,可以回答人类专家级别的常见问题。然而,当面对需要训练语料库中未涵盖的特定领域或特定专业知识的问题时,这些模型通常会给出不准确或不正确的响应。此外,许多最先进的LLM不是开源的,这使得仅通过模型 API 注入知识变得具有挑战性。在这项工作中,我们介绍了 KnowGPT,这是一种针对LLM问答的黑盒知识注入框架。KnowGPT 利用深度强化学习 (RL) 从知识图 (KG) 中提取相关知识,并使用 Multi-Armed Bandit (MAB) 为每个问题构建最合适的提示。我们对三个基准数据集进行的广泛实验表明,KnowGPT 显着增强了现有方法。值得注意的是,KnowGPT 比 ChatGPT 平均提高了 23.7%,比 GPT-4 平均提高了 2.9%。此外,KnowGPT 在 OpenbookQA 官方排行榜上获得了 91.6% 的准确率,可与人类水平相媲美。
1.介绍
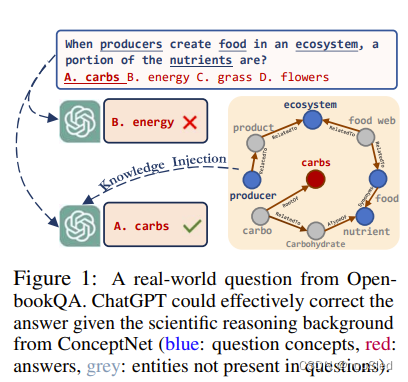
生成式大语言模型 (LLM) 以其卓越的性能令世界惊叹不已,特别是随着 ChatGPT 和 GPT4 的出现。尽管如此,LLM经常因其有限的事实知识和产生幻觉的倾向而受到批评,其中模型对超出其知识和感知范围的任务做出了错误的陈述。考虑 OpenbookQA 提出的一个生态领域特定问题,如图 1 所示。当询问营养素的比例时,ChatGPT 错误地提供了“能量”响应。这种不准确可能源于其对碳水化合物及其与营养物质关系的潜在缺乏了解。
解决上述问题的一个有希望的途径是将知识图谱(KG)集成到LLM中,例如 Yago、Freebase 和 ConceptNet,这是一种以三元组(head, relation, tail)的结构化形式表示现实世界实体之间的关系。知识图谱中存储的大量事实知识有可能显着提高LLM回答的准确性。例如,在图 1 中,ChatGPT 可以利用 ConceptNet 中的相关背景知识进行自我纠正。
最近,人们提出了各种白盒知识注入方法来将知识图谱合并到LLM中。这些方法假设我们了解LLM的一切,例如模型架构和参数。人们已经提出了许多算法将 KG 集成到 LLM 中。早期研究直接将知识图谱中的实体与文本句子拼接起来,作为基于跨模态表示对齐训练LLM的输入。后来的研究通过将文本表示和 KG 嵌入与注意力机制相结合,或者设计各种融合方法,通过定制的编码器来集成 KG 和文本,从而在隐式层面上整合 KG。
不幸的是,许多最先进的LLM在实际应用中仅通过黑盒方式。例如,ChatGPT 和 GPT-4 专门通过其 API 授予访问权限,这意味着我们只能通过提交文本输入来检索模型响应,而无法访问模型详细信息。由于缺乏访问权限,我们无法采用上述白盒知识注入技术。尽管白盒方法可以应用于开源 LLM,例如 BLOOM 和 LLaMA,但由于更新模型权重,它们通常会产生大量计算成本。因此,我们的问题是:我们是否可以开发一个黑盒知识注入框架,仅通过API就可以高效地将KG集成到LLM中?
实现这一目标并非易事,因为构建模型输入或提示面临两个挑战。❶ 识别最相关的知识很困难。现实世界的 KG 通常由数百万个三元组组成,而 LLM 通常受到有限输入长度的限制(例如,ChatGPT 为 2048 个token,GPT-4 为 4096 个token)。因此,从知识图谱中仔细选择信息最丰富的三元组变得至关重要。❷ 有效编码KG知识是很困难的。据观察,即使是传达相同语义的提示的微小变化也可能会导致LLM 产生截然不同的响应。因此,通常需要采用定制方法来从每个问题提取的知识图谱中编码事实知识,以实现最佳性能。
在这项工作中,我们提出了 KnowGPT,一种用于LLM问答的黑盒知识注入框架。为了解决挑战❶,我们利用深度强化学习(RL)来提取从问题中提到的源实体到潜在答案中的目标实体的路径。为了鼓励agent发现更多信息的路径,我们设计了一个量身定制的奖赏方案,以提高所提取路径的可达性、上下文相关性和简洁性。然后,使用训练的问题训练策略网络以最大化奖赏,并将其应用于未见过的问题。为了应对挑战❷,我们引入了基于多臂赌博机(MAB)的快速构建策略。给定几种路径提取策略和提示模板,MAB 会通过平衡探索和利用来学习为每个问题选择最有效的组合。然后将学习到的 MAB 应用于新问题,以自动选择路径提取策略和提示模板。我们的主要贡献总结如下:
- 正式定义LLM的黑盒知识注入问题,即仅通过模型API将KG集成到LLM中。
- 提出 KnowGPT,这是一个针对LLM的黑盒知识注入框架,它利用深度强化学习在 KG 和 MAB 中进行路径提取以进行快速构建。
- 使用 ChatGPT API 在两个现实世界的知识图谱(ConceptNet 和 USMLE)上实施 KnowGPT。在三个 QA 基准的实验表明,KnowGPT 的性能大幅优于最先进的基准。值得注意的是,KnowGPT 在 OpenbookQA 排行榜上达到了 91.6% 的准确率,与人类的表现相当。
2. Problem Statement
我们正式定义了LLM在复杂问答中的黑盒知识注入问题。我们将每个问题表示为一个问题上下文
Q
=
{
Q
s
,
Q
t
}
\mathcal Q=\{\mathcal Q_s, \mathcal Q_t\}
Q={Qs,Qt},其中
Q
s
=
{
e
1
,
e
2
,
.
.
.
,
e
m
}
\mathcal Q_s =\{e_1, e_2, ..., e_m\}
Qs={e1,e2,...,em} 是
m
m
m 个源实体的集合,并且
Q
t
=
{
e
1
,
e
2
,
.
.
.
,
e
n
}
\mathcal Q_t = \{e_1, e_2, ..., e_n\}
Qt={e1,e2,...,en} 是一组
n
n
n 个目标实体。根据先前的工作,
Q
s
Q_s
Qs 是通过概念识别提取的,我们假设它在我们的问题中给出。类似地,
Q
t
Q_t
Qt 中的每个目标实体都是从相应的候选答案中提取的。我们将LLM表示为
f
f
f,将现实世界的KG表示为
G
\mathcal G
G,它由三元组(头实体,关系,尾实体)组成,表示为
(
h
,
r
,
t
)
(h,r,t)
(h,r,t)。在我们的设置中,我们只能访问
f
f
f 的 API。但是,我们可以使用开源轻量级语言模型(不是
f
f
f),例如 Bert-Base,来获得文本嵌入。使用上面的符号,我们在下面描述我们的问题。
给定一个问题上下文
Q
\mathcal Q
Q、一个 LLM
f
f
f和一个 KG
G
\mathcal G
G,我们的目标是学习一个提示函数
f
p
r
o
m
p
t
(
Q
,
G
)
f_{prompt}(\mathcal Q, \mathcal G)
fprompt(Q,G),它生成一个提示
x
x
x,其中包含 KaTeX parse error: Undefined control sequence: \mathcla at position 1: \̲m̲a̲t̲h̲c̲l̲a̲ ̲Q 的上下文和
G
\mathcal G
G 中的事实知识,这样 LLM
f
(
x
)
f(x)
f(x)的预测可以输出
Q
\mathcal Q
Q 的正确答案。
3.KnowGPT Framework
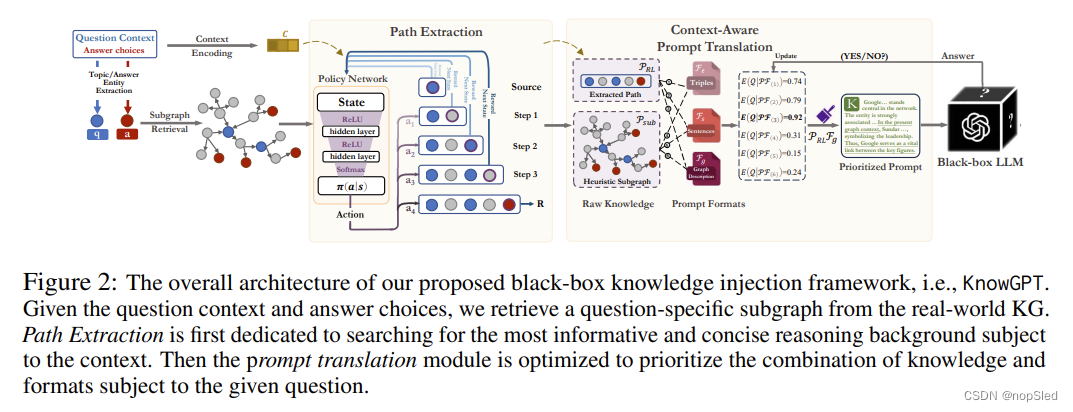
学习提示函数
f
p
r
o
m
p
t
(
Q
,
G
)
f_{prompt}(\mathcal Q,\mathcal G)
fprompt(Q,G)涉及两个挑战,即应该使用
G
\mathcal G
G中的哪些知识,以及如何构造提示。为了解决这些挑战,我们提出了 KnowGPT,它使用深度 RL 提取子图(路径),然后使用 MAB 构建提示。我们的框架概述如图 2 所示。
3.1 Path Extraction with Deep Reinforcement Learning
直观上,相关的推理背景位于特定问题的子图
G
s
u
b
\mathcal G_{sub}
Gsub 中,该子图中应包含所有源实体
Q
s
\mathcal Q_s
Qs、目标实体
Q
t
\mathcal Q_t
Qt 及其邻居。一个理想的子图
G
s
u
b
\mathcal G_{sub}
Gsub 预计具有以下属性:(i)
G
s
u
b
\mathcal G_{sub}
Gsub 包含尽可能多的源实体和目标实体,(ii)
G
s
u
b
\mathcal G_{sub}
Gsub内的实体和关系与问题上下文表现出很强的相关性,(iii)
G
s
u
b
\mathcal G_{sub}
Gsub是简洁的,冗余信息很少,因此可以输入到长度有限的LLM中。
然而,为了找到这样的
G
s
u
b
\mathcal G_{sub}
Gsub 是具有挑战性的,因为提取子图是 NP-hard 的。为了有效且高效地找到令人满意的
G
s
u
b
\mathcal G_{sub}
Gsub,我们开发了一种名为
P
R
L
\mathcal P_{RL}
PRL 的定制路径提取方法,该方法采用深度 RL 以试错方式对推理路径进行采样。具体来说,我们假设
G
s
u
b
\mathcal G_{sub}
Gsub 是基于一组推理路径
P
=
{
P
1
,
P
2
,
.
.
.
,
P
m
}
\mathcal P=\{\mathcal P_1,\mathcal P_2, ...,\mathcal P_m\}
P={P1,P2,...,Pm} 构建的,其中每个路径
P
i
=
{
(
e
i
,
r
1
,
t
1
)
,
(
t
1
,
r
2
,
t
2
)
,
.
.
.
,
(
t
∣
P
i
∣
−
1
,
r
∣
P
i
∣
,
t
∣
P
i
∣
)
}
\mathcal P_i =\{(e_i, r_1, t_1),(t_1, r_2, t_2), ...,(t_{|\mathcal P_i|−1}, r_{|\mathcal P_i|}, t_{|\mathcal P_i|})\}
Pi={(ei,r1,t1),(t1,r2,t2),...,(t∣Pi∣−1,r∣Pi∣,t∣Pi∣)} 是
Q
s
\mathcal Q_s
Qs中第
i
i
i 个源实体在
G
\mathcal G
G中开始的路径,并且
∣
P
i
∣
|\mathcal P_i|
∣Pi∣ 是路径长度。
G
s
u
b
\mathcal G_{sub}
Gsub 包含
P
\mathcal P
P 中出现的所有实体和关系。我们将每个推理路径的采样方法建模为具有状态、动作、转换和奖赏的马尔可夫决策过程(MDP),定义如下。
- State:状态表示KG中的当前位置,即KG中的实体之一。具体来说,它表示从实体
h
h
h到
t
t
t的空间变化。受先前研究的启发,我们将状态向量
s
\textbf s
s 定义为:
s t = ( e t , e t a r g e t − e t ) , (1) \textbf s_t=(\textbf e_t,\textbf e_{target}-\textbf e_t),\tag{1} st=(et,etarget−et),(1)
其中 e t e_t et和 e t a r g e t e_{target} etarget 是当前实体和目标实体的嵌入向量。为了获得从背景知识图谱中提取的实体的初始节点嵌入,我们采用了先前研究提出的方法。具体来说,我们将 KG 中的知识三元组转换为句子,并将它们输入到预训练的 LM 中以获得节点嵌入。 - Action:动作空间包含当前实体的所有相邻实体,使agent能够灵活地探索 KG。通过选择一个动作,agent将从当前实体移动到所选的相邻实体。
- Transition:转移模型 P P P 测量在给定现有状态 ( s ′ s' s′) 和选择的动作 ( a a a) 的情况下转移到新状态 ( s ′ s' s′) 的概率。在 KG 中,如果 s s s 通过动作 a a a 指向 s ′ s' s′,则转换模型采用 P ( s ′ ∣ s , a ) = 1 P(s′|s, a) = 1 P(s′∣s,a)=1 的形式; 否则, P ( s ′ ∣ s , a ) = 0 P(s′|s, a) = 0 P(s′∣s,a)=0。
- Reward:为了确定所形成路径的质量,我们根据可达性定义奖赏函数:
r r e a c h = { + 1 , i f t a r g e t ; − 1 , o t h e r w i s e ; (2) r_{reach}=\begin{cases} +1, & if~target;\\ -1, & otherwise; \end{cases}\tag{2} rreach={+1,−1,if target;otherwise;(2)
该奖赏函数代表路径是否最终在有限步内到达目标。具体来说,如果agent能够在 K K K 个动作内达到目标,它将获得 + 1 +1 +1 的奖赏。否则,它将获得-1作为奖赏。
是否到达目标节点并不是我们唯一的关注点。为了避免路径过长和繁琐,我们还设计了两种辅助奖赏函数来促进上下文相关性和路径简洁性。
3.1.1 Context-relatedness Auxiliary Reward
关键动机是鼓励搜索到与给定问题上下文密切相关的路径。具体来说,我们评估路径
P
i
\mathcal P_i
Pi 与上下文
Q
\mathcal Q
Q 的语义相关性。受当前研究的启发,应用固定但训练好的矩阵
W
\textbf W
W 将路径嵌入
P
\mathcal {\textbf P}
P 映射到与上下文嵌入
c
\textbf c
c 相同的语义空间。为此,该辅助奖赏定义为:
r
c
r
=
1
∣
i
∣
∑
s
o
u
r
c
e
i
c
o
s
(
W
×
P
i
,
c
)
,
(3)
r_{cr}=\frac{1}{|i|}\sum^i_{source}cos(\textbf W\times\textbf P_i,\textbf c),\tag{3}
rcr=∣i∣1source∑icos(W×Pi,c),(3)
其中
c
\textbf c
c 是我们从预训练的 LM 获得的上下文
Q
\mathcal Q
Q 的嵌入,路径
P
i
\mathcal P_i
Pi 的嵌入是我们遍历到
i
i
i 之前的所有实体和关系的嵌入的平均值,即
A
v
g
(
e
s
o
u
r
c
e
+
r
e
1
.
.
.
+
e
i
)
Avg(\textbf e_{source} +\textbf re_1.. .+\textbf e_i)
Avg(esource+re1...+ei),其中
i
≤
l
e
n
g
t
h
(
P
t
a
r
g
e
t
)
i ≤ length(\mathcal P_{target})
i≤length(Ptarget)。这种循序渐进的奖赏设计提供了在达到目标之前的奖赏。
3.1.2 Conciseness Auxiliary Reward
对于候选推理背景来说,还有另外两个重大挑战。(i) 黑盒LLM对较长上下文理解的自然限制约束了prompt的长度,其中提取的路径期望足够简洁以确保黑盒LLM的充分理解。(ii) 调用黑盒LLM士 API 的成本高昂,从而需要提示更加简洁。通过限制步长,我们鼓励策略在最短路径长度内找到尽可能多的有价值的信息。
考虑到从在线语料库中构建的大规模现实世界知识图谱不可避免的同质性,最终路径中的每一步在理想情况下都是必要的。具体来说,我们评估路径的简洁性,以减少冗余实体(例如同义词)。因此,对路径
P
i
\mathcal P_i
Pi 的简洁性奖赏公式如下:
r
c
s
=
1
P
i
.
(4)
r_{cs}=\frac{1}{\mathcal P_i}.\tag{4}
rcs=Pi1.(4)
最后,我们使用权衡参数来平衡每个奖赏的重要性:
r
t
o
t
a
l
=
λ
1
r
r
e
a
c
h
+
λ
2
r
c
r
+
λ
3
r
c
s
r_{total} = λ_1r_{reach}+λ_2r_{cr} + λ_3r_{cs}
rtotal=λ1rreach+λ2rcr+λ3rcs,其中
λ
1
λ_1
λ1、
λ
2
λ_2
λ2和
λ
3
λ_3
λ3是超参数。
3.1.3 Training Policy Network
为了解决上面定义的 MDP,训练了一个定制的策略网络 π θ ( s , a ) = p ( a ∣ s ; θ ) π_θ(s, a) = p(a|s; θ) πθ(s,a)=p(a∣s;θ) 以提取 KG 中的推理路径。我们通过策略梯度优化网络。最优策略将agent从源实体导航到目标实体,同时最大化期望累积奖赏。
3.2 Prompt Construction with Multi-armed Bandit
在本小节中,我们设计了一种基于多臂赌博机(Multi-Armed Bandit, MAB)的定制提示构建策略。关键思想是学习在元级别选择最佳路径提取方法和提示模板。我们将首先概述总体策略,然后通过两种路径提取方法和三个模板详细说明其示例。
假设我们有几种路径提取策略
{
P
1
,
P
2
,
.
.
.
,
P
m
}
\{\mathcal P_1,\mathcal P_2,...,\mathcal P_m\}
{P1,P2,...,Pm}和几种候选提示模板
F
=
{
F
1
,
F
2
,
.
.
.
,
F
n
}
\mathcal F=\{\mathcal F_1,\mathcal F_2,...,\mathcal F_n\}
F={F1,F2,...,Fn}。每个路径提取策略
P
i
\mathcal P_i
Pi 是一种在给定问题上下文的情况下选择子图的方法,例如上面讨论的基于 RL 的策略。每个提示模板
F
j
\mathcal F_j
Fj 都代表一种将子图中的三元组转换为用于 LLM 预测的提示的机制。
提示构造问题是针对一个给定的问题来确定
P
\mathcal P
P 和
F
\mathcal F
F 的最佳组合。我们将选择的整个过程定义为奖赏最大化问题
m
a
x
∑
r
p
f
max\sum r_{pf}
max∑rpf ,其中
r
p
f
r_{pf}
rpf 的获得方式为:
σ
(
f
(
P
F
(
i
)
)
)
=
{
1
i
f
a
c
c
u
r
a
t
e
;
0
o
t
h
e
r
w
i
s
e
.
(5)
\sigma(f(\mathcal P\mathcal F_{(i)}))=\begin{cases} 1 & if~accurate;\\ 0 & otherwise. \end{cases}\tag{5}
σ(f(PF(i)))={10if accurate;otherwise.(5)
具体来说,
P
F
(
i
)
,
i
∈
{
0
,
1
,
⋅
⋅
⋅
,
m
×
n
}
\mathcal P\mathcal F_{(i)},i∈\{0, 1,···, m×n\}
PF(i),i∈{0,1,⋅⋅⋅,m×n} 是其中一种组合,
r
p
f
∈
{
0
,
1
}
r_{pf}∈\{0, 1\}
rpf∈{0,1} 表示LLM的输出在回答当前问题时的表现。
为了捕获问题与不同知识和提示模板组合之间的上下文相关性,我们用期望函数
E
(
⋅
)
E(·)
E(⋅) 制定了 MAB 的选择机制。它自适应地测量不同问题组合的潜在期望。
E
(
Q
∣
P
F
(
i
)
)
=
c
×
α
(
i
)
+
β
(
i
)
.
(6)
E(\mathcal Q|\mathcal P\mathcal F_{(i)})=\textbf c\times\textbf α_{(i)}+\beta_{(i)}.\tag{6}
E(Q∣PF(i))=c×α(i)+β(i).(6)
这里,
c
\textbf c
c 表示
Q
\mathcal Q
Q 的嵌入。向量
α
(
i
)
\textbf α_{(i)}
α(i) 对应于与
P
F
(
i
)
\mathcal P\mathcal F_{(i)}
PF(i) 相关的一组非负参数,这些参数是在之前的
k
−
1
k-1
k−1 次迭代中学习到的。另外,
β
(
i
)
β_{(i)}
β(i)代表根据高斯分布引入噪声的平衡因子。
经验上最大化
c
×
α
(
i
)
\textbf c\times\textbf α_{(i)}
c×α(i) 可以鼓励对最佳组合的利用,我们可以通过对锚问题
c
i
\textbf c_i
ci 的上下文嵌入与前
k
k
k步中特定组合
P
F
(
i
)
\mathcal P\mathcal F_{(i)}
PF(i) 的所有先前选择的上下文
C
(
i
)
\textbf C_{(i)}
C(i) 之间的相关性,以及从当前组合的选择中获得的奖赏
r
p
f
(
i
)
\textbf r^{(i)}_{pf}
rpf(i),进行建模来有效地更新
α
(
i
)
\textbf α_{(i)}
α(i)。具体来说,
β
(
b
)
\textbf β^{(b)}
β(b)更新为:
J
(
C
(
i
)
(
k
)
,
r
p
f
(
i
)
(
k
)
)
=
∑
k
=
1
K
(
r
p
f
(
i
)
(
k
)
−
C
(
i
)
(
k
)
α
(
i
)
)
2
+
λ
i
∣
∣
α
(
i
)
∣
∣
2
2
.
→
α
(
i
)
=
(
(
C
(
i
)
(
k
)
)
T
C
(
i
)
(
k
)
+
λ
i
I
)
−
1
(
C
(
i
)
(
k
)
)
T
r
p
f
(
i
)
(
k
)
.
(7)
J(\textbf C^{(k)}_{(i)},\textbf r^{(i)(k)}_{pf})=\sum^K_{k=1}(\textbf r^{(i)(k)}_{pf}-\textbf C^{(k)}_{(i)}\textbf α^{(i)})^2+\lambda^i||\textbf α^{(i)}||^2_2.\\ \rightarrow \textbf α^{(i)}=((\textbf C^{(k)}_{(i)})^T\textbf C^{(k)}_{(i)}+\lambda^i\textbf I)^{-1}(\textbf C^{(k)}_{(i)})^T\textbf r^{(i)(k)}_{pf}.\tag{7}
J(C(i)(k),rpf(i)(k))=k=1∑K(rpf(i)(k)−C(i)(k)α(i))2+λi∣∣α(i)∣∣22.→α(i)=((C(i)(k))TC(i)(k)+λiI)−1(C(i)(k))Trpf(i)(k).(7)
这里,
J
J
J 表示 OLS 训练损失。
I
∈
R
d
×
d
\textbf I ∈ \mathbb R^{d×d}
I∈Rd×d 是单位矩阵,
λ
i
λ^i
λi 是控制模型复杂度的正则化因子。
同样,为了鼓励在较少选择的配对中进行探索,我们采用置信上限方法来平衡探索和利用。这是通过引入参数
β
(
i
)
β^{(i)}
β(i) 来实现的。受现有研究的启发,我们可以推导出以下探索项
β
(
i
)
β^{(i)}
β(i):
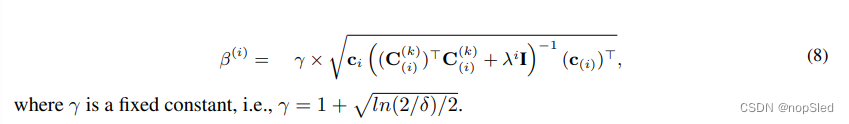
当模型选择
c
×
α
i
\textbf c×\textbf α_i
c×αi 较大的组合时,就意味着一个利用过程。同样,当模型选择具有较大
β
(
i
)
β^{(i)}
β(i) 的组合时,由于模型对当前组合的选择较少,因此该方差表示探索过程。因此,联合最大化
c
×
α
i
+
β
(
i
)
\textbf c × \textbf α_i + β^{(i)}
c×αi+β(i) 可以帮助我们摆脱探索和利用的困境。
因此,我们的 MAB 设计可以利用LLM的反馈来优化选择政策。通过最大化期望函数
E
(
⋅
)
E(·)
E(⋅),它学会平衡利用和探索,以针对特定问题上下文优先考虑最有希望的提示。
3.2.1 Implementation

4.实验


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









