






摘要
此前人们认为,数学能力只能在非常大规模的通用语言模型中出现,或者需要大量与数学相关的预训练。本文表明,经过普通预训练的 LLaMA-2 7B 模型已经表现出了强大的数学能力,从 256 个随机生成中选择最佳响应时,其在 GSM8K 和 MATH 基准上分别达到 97.7% 和 72.0% 的令人印象深刻的准确率就证明了这一点。当前base模型的主要问题是难以一致性地激活其固有的数学能力(即生成能力的一致性)。值得注意的是,只生成一个答案的准确度在 GSM8K 和 MATH 基准上分别下降至 49.5% 和 7.9%。我们发现,简单地扩展 SFT 数据就可以显着提高生成正确答案的可靠性。然而,广泛扩展的潜力受到公开可用的数学问题稀缺的限制。为了克服这一限制,我们采用了合成数据,事实证明,合成数据几乎与真实数据一样有效,并且当扩展到大约一百万个样本时,没有显示出明显的饱和度。这种简单的方法使用 LLaMA-2 7B 模型在 GSM8K 上实现了 82.6% 的准确率,在 MATH 上实现了 40.6% 的准确率,分别超过了之前的模型 14.2% 和 20.8%。我们还提供了跨不同推理复杂性和错误类型的扩展行为的见解。
1.介绍
长期以来,数学能力一直被认为非常具有挑战性,以至于它们被认为只能大规模地出现在通用语言模型中。例如,(Wei et al., 2022a,b) 的研究表明,只有参数大小超过 500 亿的模型才能获得有意义的准确性或从数学问题的思维链处理中受益。为较小的语言模型配备数学能力的策略包括创建特定于数学的基础模型,并在数千亿个与数学相关的预训练数据上进行训练。然而,此类模型的准确性仍然较低。例如,Llemma-7B 在 GSM8K 数据集上仅达到 36.4%,在 MATH 数据集上仅达到 18.0%。
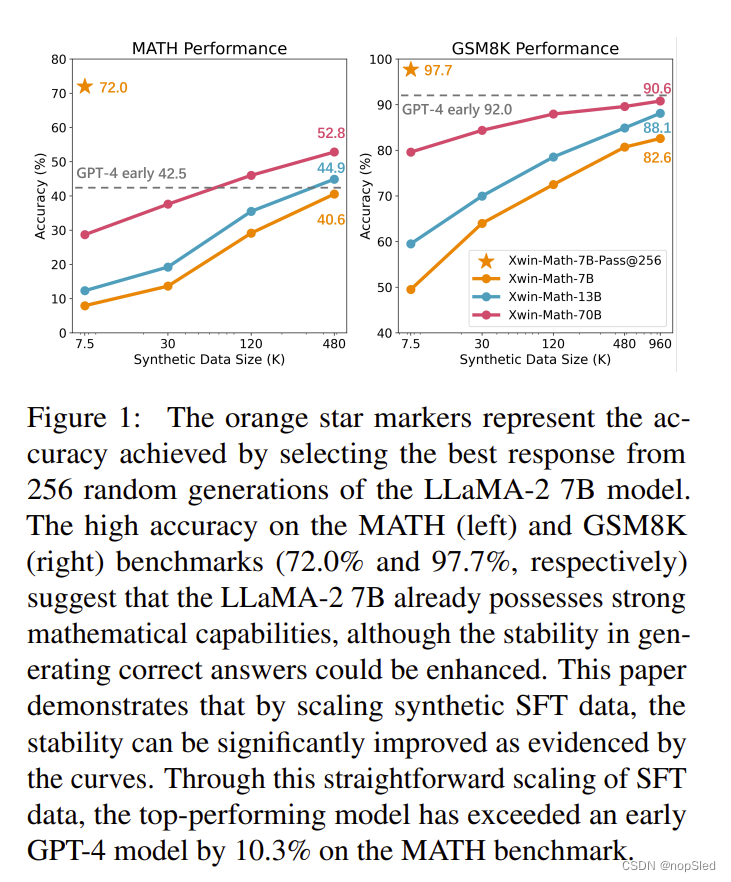
在本文中,我们证明了小规模的通用语言模型,例如LLaMA-2 7B模型,已经具备强大的数学能力,而无需对数学相关数据进行特定的预训练。令人惊讶的是,我们发现,通过对数千个数学问题进行有监督微调(请注意,SFT 阶段并没有增强(Bai et al., 2022; Ouyang et al., 2022) 中所述的能力),并且模型通过从 256 个随机生成中选择最佳答案,就解决了 97.7% 的 GSM8K 问题和 72.0% 的数学问题,如图 1 中的橙色星标记所示。值得注意的是,其准确性甚至超过了 GPT-4 报告的模型,GPT-4模型在 GSM8K 上达到 92.0%,在 MATH 上达到 42.5%。因此,我们得出结论,LLaMA-2 7B模型确实发展出了强大的数学能力。主要问题是缺乏保证能够挖掘出正确答案,因为大多数生成都是错误的。事实上,如果我们只考虑每个问题的任意一个随机生成,那么 GSM8K 上的准确率会下降到 49.5%,数学上的准确率会下降到 7.9%。我们将此称为不稳定问题。
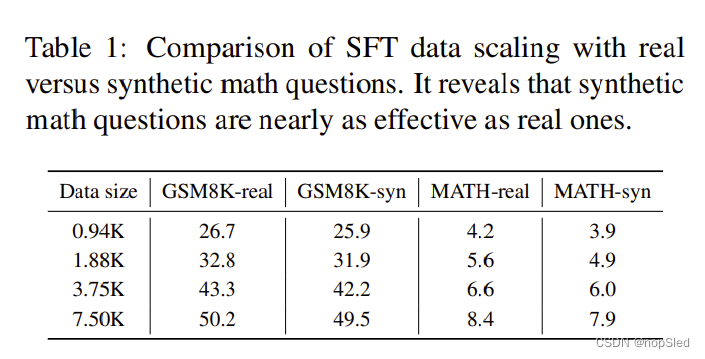
为了解决不稳定问题,我们首先观察到随着有监督微调(SFT)数据呈指数增加,精度几乎呈线性甚至超线性提高。此外,我们注意到,在利用所有可用的 GSM8K 和 MATH 训练数据时,准确性还远未达到稳定水平(如表 1 所示)。这一观察结果鼓励我们进一步扩大 SFT 数据的规模。然而,我们面临着挑战,因为缺乏公开可访问的真实数据来支持这种持续扩展。
为了克服这一限制,我们转向合成数据,采用著名的语言模型(即 GPT-4 Turbo)来生成合成数学问题。我们发现,一种简单的“全新”生成策略非常有效,它促使 GPT-4 Turbo 根据偏好问题创建一个全新的问题,然后应用一个简单的验证器(也基于 GPT-4 Turbo)。具体来说,如表 1 所示,使用合成生成的数学问题可以达到几乎与真实问题相当的准确性,凸显了合成 SFT 数学问题在扩展目的方面的潜力。
利用合成数据,我们能够显着扩展 SFT 数据,例如,在 GSM8K 上从 7.5K 到 960K,在 MATH 上从 7.5K 到 480K。这种数据缩放显示了近乎完美的缩放行为,如图 1 所示。具体来说,通过简单地缩放 SFT 数据,我们的模型已成为第一个使用标准 LLaMA- 在 GSM8K 和 MATH 上分别超过 80% 和 40% 准确度的模型 2 7B 基础模型(分别达到 82.6% 和 40.6%)。
事实证明,简单的合成 SFT 数据在更强大的基础模型中也很有效,例如 LLaMA-2 70B,它在 GSM8K 上达到 90.6%,在 MATH 上达到 52.8%。据我们所知,这是第一个在 GSM8K 上准确率超过 90% 的开源模型。它也是第一个在 MATH 基准上优于 GPT-4(即 GPT-4-0314)的开源模型,证明了我们简单的合成缩放方法的有效性。
除了强有力的结果之外,我们还深入了解了我们方法的有效性:1)随着 SFT 数据规模的增加,模型的准确性在使用 256 次尝试时趋于稳定;然而,当仅使用 1 个响应时,结果显着增加。这表明,虽然模型的能力上限保持相当恒定,但性能提升主要是由于生成正确答案的稳定性增强。2) 解决数学问题的准确性遵循关于不同 SFT 数据量的思维链 (CoT) 步骤数量的幂律。扩展的 SFT 数据集提高了每个推理步骤的可靠性。通过重采样进一步增加CoT步长较长的训练样本比例,可以显着提高模型对于疑难问题的准确率。 3)对缩放过程中的错误类型的分析表明,与推理错误相比,计算错误更容易减轻。
2.Examine Math Capability of Language Models
Metrics。我们采用两个指标来检查语言模型的数学能力。
第一个是Pass@N指标:
P
a
s
s
@
N
=
E
P
r
o
b
l
e
m
s
[
m
i
n
(
c
,
1
)
]
,
(1)
Pass@N=\mathop{\mathbb E}\limits_{Problems}[min(c,1)],\tag{1}
Pass@N=ProblemsE[min(c,1)],(1)
其中
c
c
c 表示 N 个响应中正确答案的数量。如果从 N 个随机生成中产生至少一个正确答案,则该指标认为问题已得到解决。我们使用这个指标来反映模型解决数学问题的潜力或能力。为了增强N次生成的多样性,我们将生成过程的温度设置为0.7。
第二个是PassRatio@N指标:
P
a
s
s
R
a
t
i
o
@
N
=
E
P
r
o
b
l
e
m
s
[
c
N
]
,
(2)
PassRatio@N=\mathop{\mathbb E}\limits_{Problems}[\frac{c}{N}],\tag{2}
PassRatio@N=ProblemsE[Nc],(2)
它衡量
N
N
N 个生成答案中正确答案的百分比。该指标在某种程度上相当于
P
a
s
s
@
1
Pass@1
Pass@1,但方差较小。
Observations。基于这两个指标,我们检查了 LLaMA-2 模型在 GSM8K 和 MATH 基准上的性能,如图 1 所示。为了在指令遵循设置中调整模型以适应这两个基准,我们使用它们的 SFT 版本,它们是使用有限数量的 SFT 数据(即 7.5K)进行训练。正如(Bai et al., 2022; Ouyang et al., 2022)所证明的,SFT阶段不会增强能力(甚至可能导致能力减少,如“alignment taxes”中提到的)。因此,采用 SFT 版本可以对模型的数学能力进行公平的评估。
我们首先观察到 LLaMA-2 7B 模型在两个基准测试中的 Pass@256 指标都非常高:GSM8K 为 97.7%,MATH 为 72.0%。 这表明LLaMA-2 7B模型具有很强的解决数学问题的能力。
然后我们注意到 PassRatio@256 明显低于 Pass@256,在 GSM8K 上为 48.2%,在 MATH 上为 7.9%。这表明,虽然大多数数学问题的正确答案都存在于 256 个随机生成中,但不能保证正确答案将始终如一地被提取,这种现象我们称为“不稳定问题”。
接下来,我们将提出一种简单的方法来显着减少不稳定问题。
3.Scaling SFT Data using Synthetic Math Questions
在本节中,我们首先证明扩大有限的真实 SFT 数据可以显着缓解不稳定问题。我们还观察到,使用完整可用的 GSM8K 和 MATH 训练数据时,准确性尚未达到稳定水平。我们考虑使用合成数学问题进一步扩展 SFT 数据。为此,我们引入了一种利用 GPT-4 Turbo API 生成合成数据的直接方法。事实证明,合成数据与真正的数学问题一样有效。因此,我们大胆地将合成 SFT 数据分别在 GSM8K 上缩放至 960K,在 MATH 上缩放至 480K,从而实现近乎完美的缩放行为,并达到最先进的精度。
Scaling using Real Math Questions。我们首先检查整个 GSM8K 和 MATH 训练集上实际数学问题的缩放行为。 如表 1 所示,我们观察到准确率持续提高,GSM8K 上从 26.7% 增加到 50.2%,MATH 上从 4.2% 增加到 8.4%,没有饱和的迹象。
Synthetic SFT Data Generation。由于真实数据已经用尽,我们考虑使用合成生成的数学问题进一步扩展 SFT 数据。
我们在 GPT-4 Turbo API 的帮助下引入了一个简单的三步方法:
- Step 1. Generate a new math question。我们请求 GPT-4 Turbo API 以参考数学问题为起点生成一个全新的问题。为了提高新问题的有效性,我们在提示中加入了三个规则:第一,新问题必须遵循常识;其次,它应该可以独立于原始问题来解决;第三,它不得包含任何答案。此外,我们还针对各种目标数据集针对问题和答案设置了具体的格式要求。
- Step 2. Verify the question。我们通过尝试解决方案来验证和完善生成的问题,从而进一步提高生成的问题的质量。通过将解决和验证步骤集成到单个提示中,我们发现这种方法一致地提高了不同基准问题的有效性。
- Step 3. Generate chain-of-thought (CoT) answers。我们要求 GPT-4 Turbo 为每个新生成的问题生成一个思路链 (CoT) 答案。
详细的提示设计见附录A。
Comparison of Synthetic SFT Data versus Real Data。为了评估生成的数学问题的质量,我们利用 LLaMA-2 7B 模型评估了它们针对 GSM8K 和 MATH 训练集中的实际问题的有效性,如表 1 所示。结果表明,合成数学问题几乎与和真实的一样有效。
我们还探索了先前作品中提出的各种其他合成方法。 这些方法也被证明是有效的,尽管略低于我们的方法,如图 6 所示。
Scaling to about a Million SFT Math Data。考虑到合成方法的有效性,我们将 GSM8K 和 MATH 问题的 SFT 数据规模分别大幅增加到 960K 和 480K。图 1 显示了使用不同尺寸的 LLaMA2 系列的主要结果。简单的缩放策略可实现最先进的精度。
还值得注意的是,准确性尚未达到顶峰。探索额外缩放的影响将留作我们未来的研究。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









