






 本文介绍了一种名为Mini-Gemini的框架,通过高分辨率视觉处理、高质量数据集和VLM引导生成,提升多模态视觉语言模型性能,使之接近GPT-4和Gemini等高级模型。通过双编码器系统和改进的数据集,Mini-Gemini在零样本基准测试中表现出色,支持大规模语言模型实例化。
本文介绍了一种名为Mini-Gemini的框架,通过高分辨率视觉处理、高质量数据集和VLM引导生成,提升多模态视觉语言模型性能,使之接近GPT-4和Gemini等高级模型。通过双编码器系统和改进的数据集,Mini-Gemini在零样本基准测试中表现出色,支持大规模语言模型实例化。
摘要
在这项工作中,我们介绍了 Mini-Gemini,这是一个增强多模态视觉语言模型(VLM)的简单而有效的框架。尽管 VLM 的进步促进了基本的视觉对话和推理,但与 GPT-4 和 Gemini 等高级模型相比,性能差距仍然存在。我们试图从高分辨率视觉token、高质量数据和 VLM 引导生成三个方面挖掘 VLM 的潜力,以实现更好的性能和任意工作流程,从而缩小差距。为了增强视觉token,我们提出利用额外的视觉编码器进行高分辨率细化,而不增加视觉token数量。我们进一步构建了一个高质量的数据集,促进精确的图像理解和基于推理的生成,扩大了当前 VLM 的操作范围。总的来说,Mini-Gemini 进一步挖掘了 VLM 的潜力,并同时为现有框架提供图像理解、推理和生成的能力。Mini-Gemini 支持一系列从 2B 到 34B 的密集和 MoE 大型语言模型 (LLM)。它在多个零样本基准测试中表现出领先的性能,甚至超越了已开发的私有模型。 代码和模型可在 https://github.com/dvlab-research/MiniGemini 获取。
1.介绍

随着大型语言模型 (LLM) 的快速发展,为多模态输入提供令人印象深刻的功能正在成为当前视觉语言模型 (VLM) 的重要组成部分。为了弥合模态之间的差距,开展了几项研究,将视觉与从图像到视频的LLM结合起来。尽管取得了这些进步,学术研究与 GPT-4 和 Gemini 等经过大量数据和资源训练的成熟模型的实力之间仍然存在巨大差距。
对于视觉本身来说,图像分辨率是明确的核心部分,尽管周围环境具有最小的视幻觉。为此,人们进行了更多的尝试来进一步提高当前 VLM 的视觉理解。例如,提出了LLaVA-Next和Otter-HD,以通过提高图像分辨率来增强基于先前工作的能力。毫无疑问,通过更高分辨率的图像增加视觉token的数量可以丰富LLM中的视觉嵌入。然而,这种改进伴随着计算需求和相关成本的不断增加,特别是在处理多个图像时。此外,现有的数据质量、模型能力和应用范围仍然不足以加速培训和开发过程。这种情况引发了一个关键的问题:如何在学术环境中以可接受的成本推动 VLM 接近成熟的模型?
为了回答这个问题,我们从三个战略方面探讨了VLM的潜力,即高效的高分辨率解决方案、高质量的数据和可扩展的应用。首先,我们利用 ConvNet 有效生成更高分辨率的候选,从而增强视觉细节,同时保持LLM的视觉token数。为了提高数据质量,我们合并来自不同公共来源的高质量数据集,确保丰富多样的数据基础。此外,我们的方法将这些增强功能与SOTA的LLM和生成模型相结合,旨在提升 VLM 性能和用户体验。这种多方面的策略使我们能够更深入地研究 VLM 的功能,在可管理的资源限制内取得重大进展。
一般来说,我们的方法采用任意到任意的范式,它擅长处理图像和文本作为输入和输出。特别是,我们为输入图像引入了一种高效的视觉token增强管道,具有双编码器系统。它由双编码器组成,一个用于高分辨率图像,另一个用于低分辨率视觉嵌入,反映了Gemini的协作功能。在推理过程中,它们在一种注意力机制中工作,其中低分辨率的生成视觉query,而高分辨率的对应项提供候选key和value以供参考。为了提高数据质量,我们根据公共资源收集和生成更多数据,包括高质量的回复、面向任务的指令和与生成相关的数据。数量和质量的增加提高了整体性能并扩展了模型的能力。此外,我们的 VLM 与高级生成模型的无缝集成促进了我们的模型支持并发图像和文本生成。它通过提供 LLM 生成的文本,利用 VLM 指导进行图像生成。
Mini-Gemini 框架可以使用从 2B 到 34B 参数范围的一系列 LLM 轻松实例化,如第 3 节中详细阐述的那样。第 4 节中进行了广泛的实证研究,以揭示所提出方法的有效性。值得注意的是,我们的方法在各种设置中都取得了领先的性能,甚至在复杂的 MMB 和 MMU 数据集中分别超越了成熟的 Gemini Pro、Qwen-VL-Plus 和 GPT 4V。这些结果强调了 Mini-Gemini 在 VLM 领域树立新基准的潜力,凸显了其处理复杂多模式任务的先进能力。
2.相关工作
Large Language Models。大型语言模型 (LLM) 的进步极大地加速了自然语言处理 (NLP) 的最新进展。Transformer 框架的开创性引入是其基石,它推动了 BERT 和 OPT 等新一波语言模型的诞生,这些模型表现出了深刻的语言理解能力。生成式预训练 Transformer (GPT) 的诞生通过自回归语言建模引入了一种新范式,建立了一种强大的语言预测和生成方法。ChatGPT、GPT-4、LLaMA 和 Mixtral 等模型的出现进一步证明了该领域的快速发展,每个模型在复杂的语言处理任务上都表现出了增强的性能,这归功于它们在大量文本数据集上的训练。指令微调已成为改进预训练 LLM 输出的关键技术,其在 Alpaca 和 Vicuna 等开源模型开发中的应用就是证明。他们使用自定义指令集对 LLaMA 进行迭代。此外,LLM 与特定视觉任务工具的集成凸显了其适应性和广泛应用的潜力,凸显了 LLM 在超越传统文本处理以包含多模态交互方面的实用性。在这项工作中,我们以几个预训练的 LLM 为基准,并在其基础上构建多模态框架,以进一步扩展令人印象深刻的推理能力。
Vision Language Models。计算机视觉和自然语言处理的融合催生了 VLM,它将视觉和语言模型结合起来,以实现跨模态理解和推理能力。这种整合对于推进需要视觉理解和语言处理的任务至关重要,这一点可以从在不同数据集上训练的理解和推理模型中看出。诸如 CLIP 之类的突破性模型进一步弥合了语言模型和视觉任务之间的差距,展示了跨模态应用的可行性。最近的发展突显了一种日益增长的趋势,即在 VLM 领域利用 LLM 的强大功能。Flamingo 和 BLIP-2 等创新利用大量的图像文本对集合来微调跨模态对齐,从而显著提高学习效率。在这些进步的基础上,一些模型专注于基于 BLIP-2 生成高质量的指令数据,从而显著提高了性能。此外,LLaVA 采用简单的线性投影层,以最少的可学习参数促进图像文本空间对齐。它利用定制的指令数据,并举例说明一种有效的策略,以展示该模型的强大功能。与它们不同,我们的目标是探索理解和生成的潜力。
LLM as Generation Assistant。将 LLM 与图像输出相结合已成为近期多模态研究的一个关键领域。InternLM-XComposer 等方法利用图像检索来生成交错的文本和图像输出,从而绕过直接生成。相反,以 EMU 和 SEED 为代表的自回归token预测方法使 LLM 能够直接通过大量图像文本数据解码图像。这些方法需要大量的训练资源,而且它们的自回归性质会导致不良的延迟。最近的研究力求与潜在扩散模型保持一致,以简化图像生成。它们通常需要设计文本嵌入和额外的优化才能达到所需的生成效果。这种联合训练可能会损害 VLM 在文本生成中的性能。Mini-Gemini 的独特之处在于采用文本数据驱动的方法,使模型能够生成高质量的图像。我们仅利用 13K 纯文本数据来激活 LLM 作为高质量re-captioner的能力,而不会损害 VLM 的基本性能。
3.Mini-Gemini
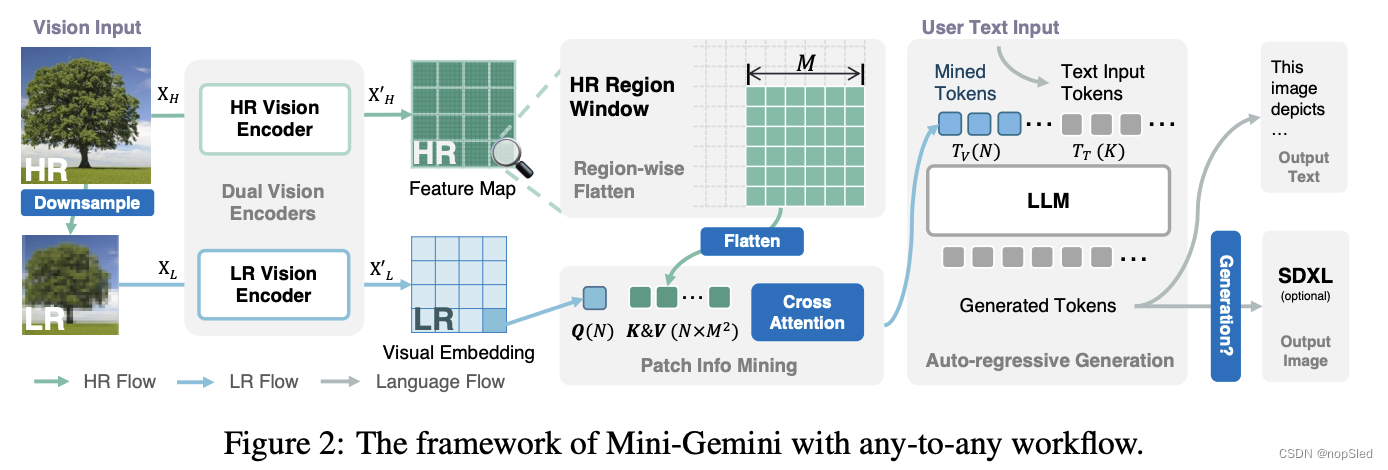
Mini-Gemini 的框架在概念上很简单:利用双视觉编码器提供低分辨率视觉嵌入和高分辨率候选;提出使用patch信息挖掘在高分辨率区域和低分辨率视觉query之间进行patch级挖掘;利用 LLM 将文本与图像结合起来,以便同时进行理解和生成。
3.1 Dual Vision Encoders
在 Mini-Gemini 框架中,可以处理文本和图像输入,可以选择单独处理或组合处理。为了便于说明,我们考虑同时处理这两种模态。如图 2 所示,处理从高分辨率图像 X H ∈ R H × W × 3 X_H ∈ \mathbb R^{H×W×3} XH∈RH×W×3 开始,通过双线性插值生成相应的低分辨率图像 X L ∈ R H ′ × W ′ × 3 X_L ∈ \mathbb R^{H′×W′×3} XL∈RH′×W′×3,确保 H ′ ≤ H H′≤H H′≤H。然后,我们处理它们并在两个并行图像流中编码为多网格视觉嵌入。特别是,对于低分辨率 (LR) 流,我们保留传统管道并使用 CLIP 预训练的 ViT 来编码视觉嵌入 X L ′ ∈ R N × C X^′_L ∈ \mathbb R^{N×C} XL′∈RN×C ,其中 N N N 表示视觉块的数量。这样, N N N 个视觉块之间的长距离关系可以很好地保留,以便随后在 LLM 中进行交互。对于高分辨率 (HR) 流,我们采用基于 CNN 的编码器进行自适应和高效的 HR 图像处理。例如,为了与 LR 视觉嵌入保持一致,LAION 预训练的 ConvNeXt 可用作 HR 视觉编码器。因此,我们可以通过将来自不同卷积阶段的特征上采样并拼接到 1/4 输入比例来获得 HR 特征图 X H ′ ∈ R N ′ × N ′ × C X^′_H ∈ \mathbb R^{N^′×N^′×C} XH′∈RN′×N′×C。这里, N ′ = H / 4 × W / 4 = N × M 2 N^′ = H/4 × W/4 = N×M^2 N′=H/4×W/4=N×M2 表示 HR 特征的数量,其中 M M M 反映每个 HR 段内的逐像素特征计数,如图 2 所示。
3.2 Patch Info Mining
利用上面生成的 LR 嵌入
X
L
′
X^′_L
XL′ 和 HR 特征
X
H
′
X^′_H
XH′,我们提出了patch信息挖掘,以通过增强视觉token来扩展 VLM 的潜力。具体而言,为了保持 LLM 中的最终视觉token数量以提高效率,我们将低分辨率视觉嵌入
X
L
′
X^′_L
XL′ 作为query
Q
∈
R
N
×
C
Q ∈ \mathbb R^{N×C}
Q∈RN×C ,旨在从 HR 候选中检索相关的视觉线索。同时,HR 特征图
X
H
′
X^′_H
XH′ 被视为key
K
∈
R
N
×
M
2
×
C
K ∈ \mathbb R^{N×M^2×C}
K∈RN×M2×C 和value
V
∈
R
N
×
M
2
×
C
V ∈ \mathbb R^{N×M^2×C}
V∈RN×M2×C,如图 2 所示。这里,
Q
Q
Q 中的低分辨率patch与
K
K
K 和
V
V
V 中相应的高分辨率子区域相关,包含
M
2
M^2
M2 个像素级特征。因此,patch信息挖掘过程可以表述为:
T
V
=
M
L
P
(
Q
+
S
o
f
t
m
a
x
(
ϕ
(
Q
)
×
ϕ
(
K
)
T
)
×
ϕ
(
V
)
)
,
(1)
T_V=MLP(Q+Softmax(\phi(Q)\times\phi(K)^T)\times\phi(V)),\tag{1}
TV=MLP(Q+Softmax(ϕ(Q)×ϕ(K)T)×ϕ(V)),(1)
其中
ϕ
\phi
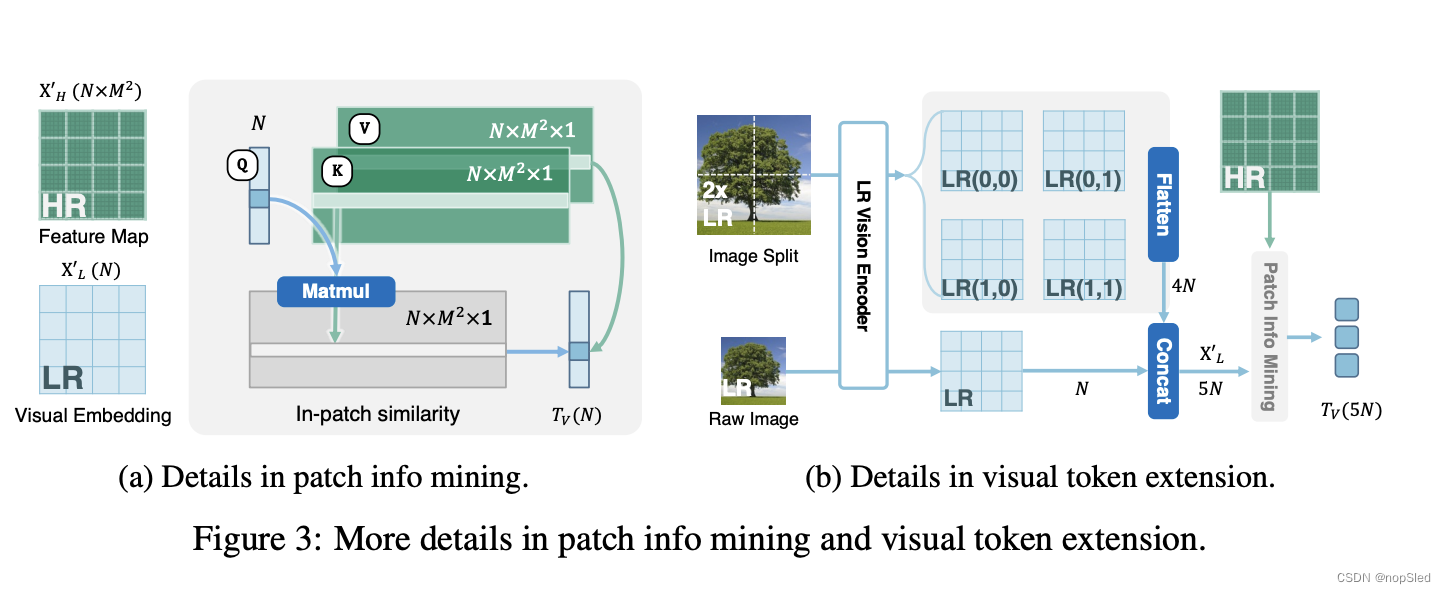
ϕ 和 MLP 分别表示投影层和多层感知器。如图 3a 所示,该公式概括了合成和细化视觉线索的过程,从而生成增强的视觉token
T
V
T_V
TV 以供后续的 LLM 处理。它确保每个query的挖掘都仅局限于 X′H 中具有
M
2
M^2
M2 特征的相应子区域,从而保持效率。这种设计允许提取 HR 细节而不扩大
T
V
T_V
TV 的视觉token数量,从而在细节丰富度和计算可行性之间保持平衡。
此外,所设计的patch信息挖掘还支持视觉token扩展。如图 3b 所示,我们可以将视觉token扩展到
5
N
5N
5N 以捕获更多细节。这是通过将原始图像与其 2 倍放大后的对应图像合并来实现的,从而产生分批输入
X
L
∈
R
5
×
H
′
×
W
′
×
3
X_L ∈ \mathbb R^{5×H^′×W^′×3}
XL∈R5×H′×W′×3。并且我们可以使用 LR 视觉编码器获得编码的视觉嵌入
X
L
′
∈
R
5
×
N
×
C
X^′_L ∈\mathbb R^{5×N×C}
XL′∈R5×N×C,如第 3.1 节所述。由于基于 CNN 的 HR 视觉编码器设计灵活,它可以灵活地处理patch信息挖掘期间增加的视觉token数量。上述过程中的唯一区别是
X
H
′
X^′_H
XH′ 中的子区域应根据扩展的视觉嵌入
X
L
′
X^′_L
XL′ 进行更改。如果需要,我们还可以对 HR 输入进行上采样以更好地支持更高的分辨率,如表 2 中的实验分析所示。
3.3 Text and Image Generation

利用挖掘出的视觉token
T
V
T_V
TV 和输入文本token
T
T
T_T
TT ,我们将它们拼接起来作为 LLM 的输入进行自回归生成,如图 2 所示。与传统的 VLM 不同,所提出的 Mini-Gemini 支持纯文本和文本图像生成作为输入和输出,即任意到任意的推理。尽管具有图像理解能力,我们仍将 Mini-Gemini 生成图像的能力锚定在其出色的图像文本理解和推理能力上。与最近的研究解决 LLM 的文本嵌入和生成式模型之间的领域差距不同,我们选择优化语言提示领域的差距。确切地说,Mini-Gemini 将用户指令转换为高质量提示,这些提示在潜在扩散模型中生成与上下文相关的图像。这种方法反映在后续的高质量图像生成框架中,例如 DALLE 3 和 SORA,它们利用 VLM 的生成和理解能力来获得更高质量的文本条件以用于生成任务。
Text-image Instructions。为了更好地进行跨模态对齐和指令微调,我们从公开来源收集了高质量的数据集。具体来说,对于跨模态对齐,我们利用了来自 LLaVA 过滤的 CC3M 数据集的 558K 个图像-释义对和来自 ALLaVA 数据集的 695K 个采样的 GPT-4V 响应。它为投影层预训练带来了总共约 1.2M 个图像释义。至于指令微调,我们从 LLaVA 数据集中采样了 643K 个单轮和多轮对话(不包括 21K 个 TextCaps 数据),从 ShareGPT4V 中采样了 100K 个 QA 对,从 ALLaVA 数据集中采样了 10K 个 LAION-GPT-4V 释义,700K 个 GPT-4V 响应指令对,并从 LIMA 和 OpenAssistant2 中采样了 6K 个纯文本多轮对话。为了增强与 OCR 相关的能力,我们进一步收集了 28K QA 对,其中包括 10K DocVQA、4K ChartQA、10K DVQA 和 4K AI2D 数据。一般来说,图像理解大约有 1.5M 条与指令相关的对话。此外,我们还收集了 13K 对用于与图像相关的生成,稍后将详细说明。
Generation-related Instructions。为了支持图像生成,我们进一步使用 GPT-4 Turbo 构建了一个 13K 指令遵循数据集。如图 4 所示,训练数据包含两个任务:(a)简单指令重释义:我们采用来自 LAION-GPT-4V 的 8K 描述性图像指令,并让 GPT-4 在稳定扩散 (SD) 域中反向推断相应用户的短输入和目标指令。(b)上下文提示生成:基于 LIMA 和 OpenAssistant2 中的一些高质量真实世界对话上下文,我们生成适合对话上下文的图像提示,总共带来 5K 条指令。对于这两种数据,在对 GPT-4 的每个query中,我们从 GigaSheet 中随机抽取 5 个高质量 SD 文本到图像提示作为上下文示例,以获得生成的目标提示。我们将数据格式化为使用 作为触发器来启动生成过程,并将目标指令包装在 … 中。文本生成后,Mini-Gemini 提取目标释义并利用 SDXL 生成相应的图像。更多详细信息请参阅附录 A。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









