






摘要
对预训练的大型语言模型 (LLM) 进行微调对于使其与人类价值观和意图保持一致至关重要。此过程通常使用成对比较和与参考 LLM 进行 KL 散度等方法,重点是评估模型生成的完整答案。但是,这些响应的生成发生在 token 级别,遵循顺序、自回归的方式。在本文中,我们介绍了 Token 级直接偏好优化 (TDPO),这是一种通过在 token 级别优化策略使 LLM 与人类偏好保持一致的新方法。与以前面临散度效率挑战的方法不同,TDPO 为每个 token 合并了前向 KL 散度约束,从而提高了对齐和多样性。利用 Bradley-Terry 模型作为基于 token 的奖赏系统,TDPO 增强了 KL 散度的调节,同时保持了简单性,而无需显式的奖赏建模。在各种文本任务的实验结果表明,TDPO 在平衡对齐与生成多样性方面表现出色。值得注意的是,在可控情感生成和单轮对话数据集中,使用 TDPO 进行微调比 DPO 取得了更好的平衡,并且与基于 DPO 和 PPO 的 RLHF 方法相比,生成的响应质量显著提高。我们的代码已在 https://github.com/Vance0124/Tokenlevel-Direct-Preference-Optimization 上开源。
1.介绍
大型语言模型 (LLM) 已在各种领域展现出显著的泛化能力,包括文本摘要、代码编写,甚至遵循人类指令。为了使 LLM 与人类意图保持一致,来自人类反馈的强化学习 (RLHF) 已成为一种非常有效的方法,体现了风格和道德价值观。这些方法通常涉及奖赏模型的训练,然后使用强化学习 (RL) 对策略模型进行微调。
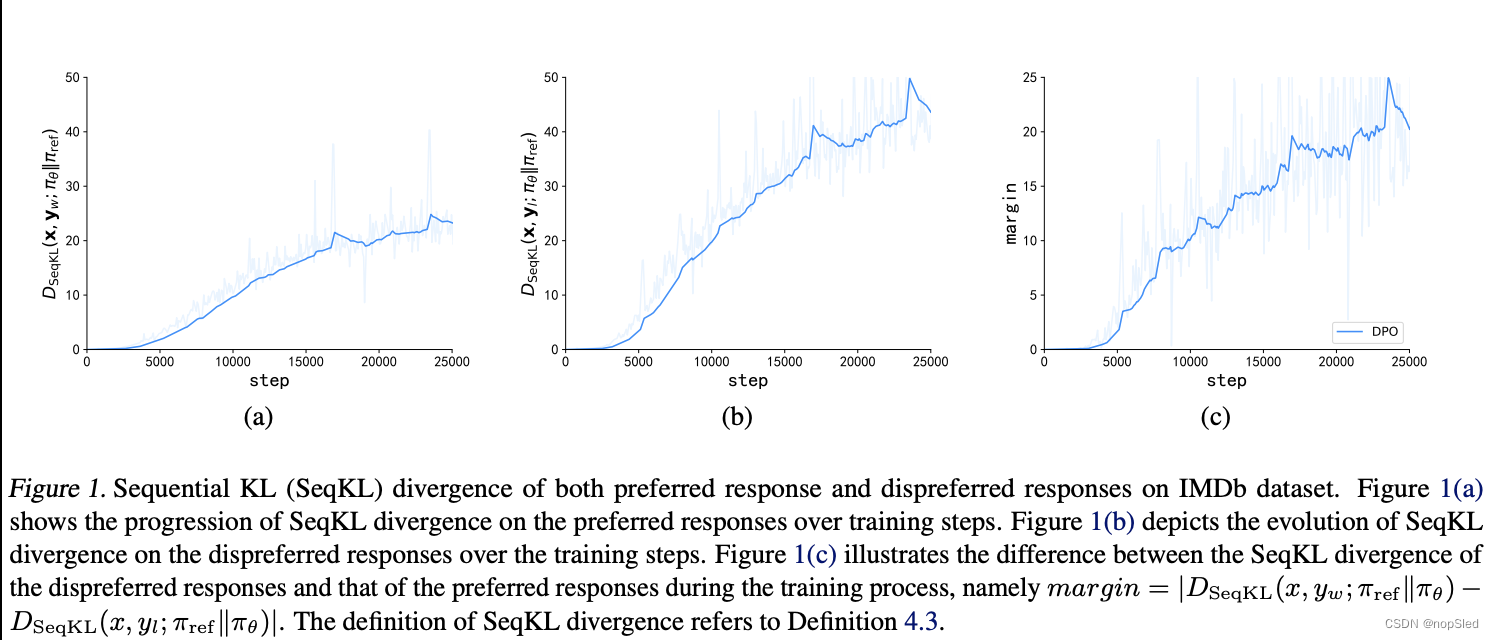
直接偏好优化 (DPO) 引入了一种直接有效的技术,使用成对比较来训练 LLM,而无需明确建立奖赏模型。DPO 利用 KL 散度来确保训练过程与参考大型语言模型 (LLM) 保持紧密一致,从而防止出现重大偏差。在 DPO 中,KL 散度是在句子级别进行评估的,这反映了评估基于完整的响应(答案),通常一个响应中包含几个句子。但是,这些响应的生成是按顺序进行的,遵循自回归方法。一个潜在的好处是可以更细致地逐个token地检查与参考 LLM 相关的散度。一种方法是使用序列 KL 散度(如定义 4.3 中所定义),它监视生成的响应的轨迹。如图 1 所示,与优选响应子集相比,DPO 在非优选响应子集中的 KL 散度增加速度明显更快。这导致两个子集之间的差距不断扩大,也表明 DPO 无法有效控制非优选响应子集的 KL 散度。这会影响模型的散度效率,并最终影响其语言能力和生成多样性。这种限制凸显了在 DPO 框架内使用 KL 散度的有效性下降,表明其方法论存在改进空间。
连续 KL 散度增长率的不平衡可能与 DPO 所采用的反向 KL 散度约束有关。反向 KL 散度的模式寻求特性往往会导致生成过程中的多样性降低,从而限制模型产生多样化和有效响应的潜力。基于 DPO 的 f-DPO 方法研究了不同散度约束下 LLM 的对齐性能和生成多样性之间的权衡。它强调了前向 KL 散度的质量覆盖行为在增强模型多样性方面的优势,并探讨了不同散度约束的影响。然而,f-DPO 仅独立讨论了在反向 KL 散度或前向 KL 散度约束下模型行为的变化。本质上,它并没有从根本上增强 DPO 算法本身,而是通过简单地交换不同的 KL 散度约束来在对齐性能和生成多样性之间取得平衡。
受上述观察的启发,我们从序列和 token 级别的角度定义和研究了与人类偏好对齐的问题。在这个方向上也有一些并行的工作。我们引入了一种新方法,称为 Token 级直接偏好优化(TDPO),旨在通过控制每个 token 的 KL 散度在对齐性能和生成多样性之间取得更好的平衡。为了实现这一点,我们重新定义了以序列方式最大化限制性奖赏的目标。使用贝尔曼方程建立了句子级奖赏和 token 级生成之间的联系。之后,Bradley-Terry 模型被转换为 token 级别的表示,证明了它与 Regret Preference Model 的密切关系。通过利用这种方法,我们在最终的目标函数中有效地集成了每个 token 的前向 KL 散度限制,从而改善了 KL 散度的调节。
TDPO 保留了 DPO 的简单性,同时提供了改进的 KL 散度调节,以使 LLM 与人类偏好保持一致。与 DPO 的策略相呼应,我们的方法直接优化策略,而无需在整个训练阶段进行显式奖赏模型学习或策略采样。我们的实验结果证明了 TDPO 在多个文本任务中的有效性,并且与基于 DPO 和 PPO 的 RLHF 方法相比,生成的响应质量得到了显着提升。总之,TDPO 不仅能够有效解决 KL 散度过大的问题,而且还能大大提高散度效率,因此脱颖而出。
2.Related Works
ChatGPT 的出现催化了大型语言模型 (LLM) 领域的重大进步,例如 OpenAI 的 GPT-4、Mistral 和 Google 的 Gemini。一般来说,LLM 的训练包括三个阶段:最初在海量文本语料库上进行无监督预训练以掌握语言结构,然后使用特定于任务的数据集进行有监督微调以提高 LLM 产生所需响应的概率。然而,由于在有监督微调阶段标记数据集的可用性通常有限且昂贵,该模型可能会保留偏见和不准确性,表现为社会偏见、道德问题、毒性和幻觉,这需要后续的 AI 校准阶段。Zephyr 和 GPT-4 等实现显著校准的值得注意的模型已经证明了从人类反馈进行强化学习 (RLHF) 和直接偏好优化 (DPO) 算法等技术的有效性。
基于人类反馈的强化学习 (RLHF) 已成为 LLM 与人类价值观相对齐的基石,提供了一种基于定性反馈来优化模型输出的机制。这种方法通过人类反馈迭代改进模型性能,在使得模型在符合人类期望和道德考虑方面表现出了巨大的潜力。然而,实现 RLHF 的复杂性,加上人类生成的奖赏模型的不准确性,促使人们探索替代策略。奖赏排名微调 (RAFT) 和排名响应以对齐人类反馈 (RRHF) 等方法提供了简化的对齐方法,规避了 RLHF 的一些固有挑战。特别是,直接偏好优化 (DPO) 代表了直接策略优化的突破,通过细粒度的奖赏函数优化方法解决了平衡模型行为的复杂性。然而,在符合人类偏好的同时保持语言多样性的挑战仍然是一个关键关注点,这促使我们提出了 Token 级直接偏好优化 (TDPO),旨在协调模型输出中的对齐准确性和表达范围的双重目标。
3.Preliminaries
对于语言生成,语言模型 (LM) 会根据提示(问题)
x
x
x 生成响应(答案)
y
y
y,其中
x
x
x 和
y
y
y 均由一系列token组成。直接偏好优化 (DPO) 从 RLHF 的 RL 目标开始:
m
a
x
π
θ
E
x
∼
D
,
y
∼
π
θ
(
⋅
∣
x
)
[
r
(
x
,
y
)
−
β
D
K
L
(
π
θ
(
⋅
∣
x
)
∣
∣
π
r
e
f
(
⋅
∣
x
)
)
]
,
(1)
\mathop{max}\limits_{\pi_{\theta}}\mathbb E_{x\sim\mathcal D,y\sim\pi_{\theta}(\cdot|x)}[r(x,y)-\beta D_{KL}(\pi_{\theta}(\cdot|x)||\pi_{ref}(\cdot|x))],\tag{1}
πθmaxEx∼D,y∼πθ(⋅∣x)[r(x,y)−βDKL(πθ(⋅∣x)∣∣πref(⋅∣x))],(1)
其中
D
\mathcal D
D 表示人类偏好数据集,
r
(
x
,
y
)
r(x, y)
r(x,y) 表示奖赏函数,
π
r
e
f
(
⋅
∣
x
)
π_{ref}(·|x)
πref(⋅∣x) 作为参考模型,通常选择有监督微调后的语言模型,
π
θ
π_θ
πθ 表示进行 RL 微调的模型,用
π
θ
=
π
r
e
f
π_θ = π_{ref}
πθ=πref 初始化,
β
β
β 是反向 KL 散度惩罚的系数
通过直接推导等式1,DPO在逆KL散度下建立了奖赏模型与最优策略之间的映射,得到了关于策略的奖赏函数的表示:
r
(
x
,
y
)
=
β
l
o
g
π
θ
(
y
∣
x
)
π
r
e
f
(
y
∣
x
)
+
β
l
o
g
Z
(
x
)
.
(2)
r(x,y)=\beta log\frac{\pi_{\theta}(y|x)}{\pi_{ref}(y|x)}+\beta log~Z(x).\tag{2}
r(x,y)=βlogπref(y∣x)πθ(y∣x)+βlog Z(x).(2)
这里,
Z
(
x
)
Z(x)
Z(x) 是配分函数。
为了符合人类偏好,DPO 使用 BradleyTerry 模型进行成对比较:
P
B
T
(
y
1
≻
y
2
∣
x
)
=
e
x
p
(
r
(
x
,
y
1
)
)
e
x
p
(
r
(
x
,
y
1
)
)
+
e
x
p
(
r
(
x
,
y
2
)
)
.
(3)
P_{BT}(y_1\succ y_2|x)=\frac{exp(r(x,y_1))}{exp(r(x,y_1))+exp(r(x,y_2))}.\tag{3}
PBT(y1≻y2∣x)=exp(r(x,y1))+exp(r(x,y2))exp(r(x,y1)).(3)
通过将公式 2 代入公式 3 并利用负对数似然损失,DPO 得出目标函数:
u
(
x
,
y
w
,
y
l
)
=
β
l
o
g
π
θ
(
y
w
∣
x
)
π
r
e
f
(
y
w
∣
x
)
−
β
l
o
g
π
θ
(
y
l
∣
x
)
π
r
e
f
(
y
l
∣
x
)
,
L
D
P
O
(
π
θ
;
π
r
e
f
)
=
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
l
o
g
σ
(
u
(
x
,
y
w
,
y
l
)
)
]
,
(4)
\begin{array}{cc} u(x,y_w,y_l)=\beta log\frac{\pi_{\theta}(y_w|x)}{\pi_{ref}(y_w|x)}-\beta log\frac{\pi_{\theta}(y_l|x)}{\pi_{ref}(y_l|x)},\\ \mathcal L_{DPO}(\pi_{\theta};\pi_{ref})=-\mathbb E_{(x,y_w,y_l)\sim\mathcal D}[log~\sigma(u(x,y_w,y_l))], \end{array}\tag{4}
u(x,yw,yl)=βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x),LDPO(πθ;πref)=−E(x,yw,yl)∼D[log σ(u(x,yw,yl))],(4)
并且导数如下所示:
∇
θ
L
D
P
O
(
π
θ
;
π
r
e
f
)
=
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
σ
(
−
u
)
∇
θ
u
]
,
(5)
\nabla_{\theta}\mathcal L_{DPO}(\pi_{\theta};\pi_{ref})=-\mathbb E_{(x,y_w,y_l)\sim\mathcal D}[\sigma(-u)\nabla_{\theta}u],\tag{5}
∇θLDPO(πθ;πref)=−E(x,yw,yl)∼D[σ(−u)∇θu],(5)
其中
u
u
u 是
u
(
x
,
y
w
,
y
l
)
u(x, y_w, y_l)
u(x,yw,yl) 的缩写,
y
w
y_w
yw 和
y
l
y_l
yl 表示偏好和非偏好响应。
4.Methodology
在本节中,我们首先将有KL散度约束的奖赏最大化问题重新表述为 token 级形式。由此,我们推导出状态-动作函数与最优策略之间的映射。随后,我们将 Bradley-Terry 模型转换为 token 级表示,建立其与遗憾偏好模型的等价性。通过将映射关系代入 token 级的奖赏模型,我们得到仅与策略相关的优化目标。最后,我们对该优化目标进行导数形式化分析,并在此基础上推导出 TDPO 的最终损失函数。
4.1 Markov Decision Process under Token Rewards
为了对连续的自回归生成进行建模,我们扩展了第 3 节中的句子级公式,认为响应由
T
T
T 个token
y
=
y
<
T
+
1
:
=
[
y
1
,
y
2
,
.
.
.
,
y
T
]
y = y^{<T+1} := [y^1, y^2, ..., y^T]
y=y<T+1:=[y1,y2,...,yT] 组成,其中
y
t
∈
Y
y^t ∈\mathcal Y
yt∈Y,
Y
\mathcal Y
Y 代表字母表(词表)。此外,我们假设
y
<
1
=
[
]
y^{<1}=[ ]
y<1=[]。给定提示
x
x
x 和响应
y
y
y 的前
t
−
1
t−1
t−1 个token
y
<
t
y^{<t}
y<t,LM 预测下一个token的概率分布
π
θ
(
⋅
∣
[
x
,
y
<
t
]
)
π_θ(·|[x, y^{<t}])
πθ(⋅∣[x,y<t])。
当将文本生成建模为马尔可夫决策过程时,状态是提示
x
x
x和到当前步骤为止生成的响应的组合,表示为
s
t
=
[
x
,
y
<
t
]
s_t=[x, y^{<t}]
st=[x,y<t]。动作对应于下一个生成的token,表示为
a
t
=
y
t
a_t = y^t
at=yt,并且token奖励定义为
R
t
:
=
R
(
s
t
,
a
t
)
=
R
(
[
x
,
y
<
t
]
,
y
t
)
R_t := R(s_t, a_t) = R([x, y^{<t}], y^t)
Rt:=R(st,at)=R([x,y<t],yt)。
扩展所提供的定义,我们为策略
π
π
π 建立状态动作函数
Q
π
Q_π
Qπ、状态价值函数
V
π
V_π
Vπ 和优势函数
A
π
A_π
Aπ:
Q
π
(
[
x
,
y
<
t
]
,
y
t
)
=
E
π
[
∑
k
=
0
∞
R
t
+
k
∣
s
t
=
[
x
,
y
<
t
]
,
a
t
=
y
t
]
,
V
π
(
[
x
,
y
<
t
]
)
=
E
π
[
Q
π
(
[
x
,
y
<
t
]
,
y
t
)
∣
s
t
=
[
x
,
y
<
t
]
]
,
A
π
(
[
x
,
y
<
t
]
,
y
t
)
=
Q
π
(
[
x
,
y
<
t
]
,
y
t
)
−
V
π
(
[
x
,
y
<
t
]
)
.
(6)
\begin{array}{cc} Q_{\pi}([x,y^{<t}],y^t)=\mathbb E_{\pi}[\sum^{∞}_{k=0}R_{t+k}|s_t=[x,y^{<t}],a_t=y^t],\\ V_{\pi}([x,y^{<t}])=\mathbb E_{\pi}[Q_{\pi}([x,y^{<t}], y^t)|s_t=[x,y^{<t}]],\\ A_{\pi}([x,y^{<t}],y^t)=Q_{\pi}([x,y^{<t}],y^t)-V_{\pi}([x,y^{<t}]). \end{array}\tag{6}
Qπ([x,y<t],yt)=Eπ[∑k=0∞Rt+k∣st=[x,y<t],at=yt],Vπ([x,y<t])=Eπ[Qπ([x,y<t],yt)∣st=[x,y<t]],Aπ([x,y<t],yt)=Qπ([x,y<t],yt)−Vπ([x,y<t]).(6)
其中,
γ
γ
γ 表示衰减因子。本文取
γ
=
1
γ = 1
γ=1。
4.2 Token-Level Optimization
公式 1 中的 DPO 目标函数在句子级别运行。相比之下,我们提出了另一种 token 级别的目标函数:
m
a
x
π
θ
E
(
x
,
y
<
t
)
∼
D
,
z
∼
π
θ
(
⋅
∣
[
x
,
y
<
t
]
)
[
A
π
r
e
f
(
[
x
,
y
<
t
]
,
z
)
−
β
D
K
L
(
π
θ
(
⋅
∣
[
x
,
y
<
t
]
)
∣
∣
π
r
e
f
(
⋅
∣
[
x
,
y
<
t
]
)
)
.
(7)
\mathop{max}\limits_{\pi_{\theta}}\mathbb E_{(x,y^{<t})\sim\mathcal D,z\sim\pi_{\theta}(\cdot|[x,y^{<t}])}[A_{\pi_{ref}}([x,y^{<t}], z)-\beta D_{KL}(\pi_{\theta}(\cdot|[x,y^{<t}])||\pi_{ref}(\cdot|[x,y^{<t}])).\tag{7}
πθmaxE(x,y<t)∼D,z∼πθ(⋅∣[x,y<t])[Aπref([x,y<t],z)−βDKL(πθ(⋅∣[x,y<t])∣∣πref(⋅∣[x,y<t])).(7)
该目标函数的灵感来自信赖区域策略优化 (TRPO)。如引理 4.1 所示,最大化等式 7 中的目标函数将导致期望回报方面的策略改进。
Lemma 4.1 给定两个策略
π
π
π 和
π
~
\tilde π
π~,如果对于任何状态
s
t
=
[
x
,
y
<
t
]
s_t = [x, y^{<t}]
st=[x,y<t],
E
z
∼
π
~
[
A
π
(
[
x
,
y
<
t
]
,
z
)
]
≥
0
\mathbb E_{z∼\tilde π} [A_π([x, y^{<t}], z)] ≥ 0
Ez∼π~[Aπ([x,y<t],z)]≥0,那么我们可以得出结论:
E
x
∼
D
[
V
π
~
(
[
x
]
)
]
≥
E
x
∼
D
[
V
π
(
[
x
]
)
]
,
\mathbb E_{x\sim\mathcal D}[V_{\tilde π}([x])]\geq \mathbb E_{x\sim\mathcal D}[V_{\pi}([x])],
Ex∼D[Vπ~([x])]≥Ex∼D[Vπ([x])],
证明见附录 A.1。
值得注意的是,为了保持生成多样性并防止模型破解一些高奖赏答案,我们在 token 级目标函数中为每个 token 加入了反向 KL 散度,这防止模型偏离参考模型分布太远。
从公式7中的token级目标函数出发,我们可以直接推导出状态动作函数
Q
π
Q_π
Qπ与最优策略
π
θ
∗
π^∗_θ
πθ∗之间的映射。我们在以下引理中总结了这种关系。
Lemma 4.2 公式 7 中的约束问题有闭式解:
π
θ
∗
(
z
∣
[
x
,
y
<
t
]
)
=
π
r
e
f
(
z
∣
[
x
,
y
<
t
]
)
e
x
p
(
1
β
Q
π
r
e
f
(
[
x
,
y
<
t
]
,
z
)
)
Z
(
[
x
,
y
<
t
]
;
β
)
,
(8)
\pi^*_{\theta}(z|[x,y^{<t}])=\frac{\pi_{ref}(z|[x,y^{<t}])exp(\frac{1}{\beta}Q_{\pi_{ref}}([x,y^{<t}],z))}{Z([x,y^{<t}];\beta)},\tag{8}
πθ∗(z∣[x,y<t])=Z([x,y<t];β)πref(z∣[x,y<t])exp(β1Qπref([x,y<t],z)),(8)
其中
Z
(
[
x
,
y
<
t
]
;
β
)
=
E
z
∼
π
r
e
f
(
⋅
∣
[
x
,
y
<
t
]
)
e
1
β
Q
π
r
e
f
(
[
x
,
y
<
t
]
,
z
)
Z([x,y^{<t}];\beta)=\mathbb E_{z\sim\pi_{ref}(\cdot|[x,y^{<t}])}e^{\frac{1}{\beta}Q_{\pi_{ref}}([x,y^{<t}],z)}
Z([x,y<t];β)=Ez∼πref(⋅∣[x,y<t])eβ1Qπref([x,y<t],z)是配分函数。
更多详细信息请参阅附录 A.2。
为了从公式 8 得到最优策略
π
θ
∗
π^∗_θ
πθ∗,我们必须估计状态-动作函数
Q
π
r
e
f
Q_{π_{ref}}
Qπref 和配分函数
Z
(
⋅
)
Z(·)
Z(⋅)。然而,准确估计状态-动作函数
Q
π
Q_π
Qπ 在每个状态和动作上的准确性具有挑战性,估计配分函数
Z
(
⋅
)
Z(·)
Z(⋅) 也很困难。因此,我们重新整理公式 8,得到状态动作函数在策略方面的表达式:
Q
r
e
f
(
[
x
,
y
<
t
]
,
z
)
=
β
l
o
g
π
θ
∗
(
z
∣
[
x
,
y
<
t
]
)
π
r
e
f
(
z
∣
[
x
,
y
<
t
]
)
+
β
l
o
g
Z
(
[
x
,
y
<
t
]
;
β
)
.
(9)
Q_{ref}([x,y^{<t}],z)=\beta log\frac{\pi^*_{\theta}(z|[x,y^{<t}])}{\pi_{ref}(z|[x,y^{<t}])}+\beta log Z([x,y^{<t}];\beta).\tag{9}
Qref([x,y<t],z)=βlogπref(z∣[x,y<t])πθ∗(z∣[x,y<t])+βlogZ([x,y<t];β).(9)
4.3 BT Model Reformulation via Advantage Function
为了方便后续推导,我们首先引入连续 KL 散度,其定义见 Definition 4.3。
Definition 4.3。给定两个语言模型
π
1
π_1
π1 和
π
2
π_2
π2,输入提示
x
x
x 和输出响应
y
y
y,连续 KL 散度定义为:
D
S
e
q
K
L
(
x
,
y
,
π
1
∣
∣
π
2
)
=
∑
t
=
1
T
D
K
L
(
π
1
(
⋅
∣
[
x
,
y
<
t
]
)
∣
∣
π
2
(
⋅
∣
[
x
,
y
<
t
]
)
)
.
(10)
D_{SeqKL}(x,y,π_1||π_2)=\sum^T_{t=1}D_{KL}(π_1(\cdot|[x,y^{<t}])||π_2(\cdot|[x,y^{<t}])).\tag{10}
DSeqKL(x,y,π1∣∣π2)=t=1∑TDKL(π1(⋅∣[x,y<t])∣∣π2(⋅∣[x,y<t])).(10)
给定提示
x
x
x 和成对的回答
(
y
1
,
y
2
)
(y_1, y_2)
(y1,y2),Bradley-Terry 模型表达了人类的偏好概率。然而,由于 Bradley-Terry 模型是在句子级别上表述的,因此无法与公式 9 中给出的 token 级别映射建立联系。因此,我们需要推导出 token 级别的偏好模型。从 Bradley-Terry 模型出发,我们将其转化为 token 级别的表述,并证明其与遗憾偏好模型的等价性,如引理 4.4 所示。
Lemma 4.4。给定一个奖赏函数
r
(
x
,
y
)
r(x, y)
r(x,y),假设 token 级奖赏与奖励函数之间的关系为
r
(
x
,
y
)
=
∑
t
=
1
T
γ
t
−
1
R
(
[
x
,
y
<
t
]
,
y
t
)
r(x, y) =\sum^T_{t=1} γ^{t−1}R([x, y^{<t}], y^t)
r(x,y)=∑t=1Tγt−1R([x,y<t],yt),我们可以在文本生成对齐任务中建立 Bradley-Terry 模型与遗憾偏好模型之间的等价性,即:
P
B
T
(
y
1
≻
y
2
∣
x
)
=
σ
(
∑
t
=
1
T
1
γ
t
−
1
A
π
(
[
x
,
y
1
<
t
]
,
y
1
<
t
)
−
∑
t
=
1
T
2
γ
t
−
1
A
π
(
[
x
,
y
2
<
t
]
,
y
2
<
t
)
)
,
(11)
P_{BT}(y_1 ≻ y_2|x) =\sigma(\sum^{T_1}_{t=1}\gamma^{t-1}A_{\pi}([x,y^{<t}_1],y^{<t}_1)-\sum^{T_2}_{t=1}\gamma^{t-1}A_{\pi}([x,y^{<t}_2],y^{<t}_2)),\tag{11}
PBT(y1≻y2∣x)=σ(t=1∑T1γt−1Aπ([x,y1<t],y1<t)−t=1∑T2γt−1Aπ([x,y2<t],y2<t)),(11)
其中
σ
(
x
)
=
1
/
(
1
+
e
x
p
(
−
x
)
)
σ(x) = 1/(1 + exp(−x))
σ(x)=1/(1+exp(−x)) 是sigmoid函数。
我们在附录A.3中证明了这个引理。
在引理 4.4 中,我们假设
r
(
x
,
y
)
=
∑
t
=
1
T
γ
t
−
1
R
(
[
x
,
y
<
t
]
,
y
t
)
r(x, y) = \sum^T_{t=1} γ^{t−1}R([x, y^{<t}], y^t)
r(x,y)=∑t=1Tγt−1R([x,y<t],yt)。这个假设在 RL 的背景下是自然的,其中
r
(
x
,
y
)
r(x, y)
r(x,y) 表示在给定提示
x
x
x 的情况下对
y
y
y 的响应的总体奖励。将文本生成视为一个序列决策问题,
r
(
x
,
y
)
r(x, y)
r(x,y) 可以看作是生成文本的累积奖励。
根据 4.1 节中优势函数的定义,我们可以直接建立式 9 中的最优解与式 11 中的偏好优化目标之间的关系。一个难点是状态动作函数
Q
π
Q_π
Qπ 依赖于一个配分函数,而该配分函数既取决于输入提示
x
x
x,又取决于输出响应
y
<
t
y^{<t}
y<t。这会导致一对响应
(
y
w
,
y
l
)
(y_w, y_l)
(yw,yl) 的配分函数值不相同,具体为
Z
(
[
x
,
y
w
<
t
]
;
β
)
≠
Z
(
[
x
,
y
l
<
t
]
;
β
)
Z([x, y^{<t}_w]; β) \neq Z([x, y^{<t}_l]; β)
Z([x,yw<t];β)=Z([x,yl<t];β)。因此,我们不能采用类似于 DPO 的取消策略,该策略依赖于 Bradley-Terry 模型仅取决于两次补全之间的奖赏差异的属性。
幸运的是,通过扩展优势函数
A
π
A_π
Aπ 并将状态价值函数
V
π
V_π
Vπ 转换为仅与状态动作函数
Q
π
Q_π
Qπ 相关的形式,我们可以自然地抵消配分函数。通过这种方式,我们最终将 Bradley-Terry 模型重新表述为直接与最优策略
π
θ
∗
π^∗_θ
πθ∗ 和参考策略
π
r
e
f
π_{ref}
πref 相关。这总结在以下定理中。
Theorem 4.5。在对应于式7的KL约束优势函数最大化问题中,Bradley-Terry模型用最优策略
π
θ
∗
π^∗_θ
πθ∗和参考策略
π
r
e
f
π_{ref}
πref来表达人类偏好概率:
P
B
T
∗
(
y
1
≻
y
2
∣
x
)
=
σ
(
u
∗
(
x
,
y
1
,
y
2
)
−
δ
∗
(
x
,
y
1
,
y
2
)
)
,
(12)
P^*_{BT}(y_1 ≻ y_2|x)=\sigma(u^*(x,y_1,y_2)-δ^*(x,y_1,y_2)),\tag{12}
PBT∗(y1≻y2∣x)=σ(u∗(x,y1,y2)−δ∗(x,y1,y2)),(12)
其中,
u
(
x
,
y
1
,
y
2
)
u(x, y_1, y_2)
u(x,y1,y2) 表示语言模型
π
θ
π_θ
πθ 和参考模型
π
r
e
f
π_{ref}
πref 隐式定义的奖赏差异,表示为:
u
(
x
,
y
1
,
y
2
)
=
β
l
o
g
π
θ
(
y
1
∣
x
)
π
r
e
f
(
y
1
∣
x
)
−
β
l
o
g
π
θ
(
y
2
∣
x
)
π
r
e
f
(
y
2
∣
x
)
,
(13)
u(x,y_1,y_2)=\beta log\frac{\pi_{\theta}(y_1|x)}{\pi_{ref}(y_1|x)}-\beta log\frac{\pi_{\theta}(y_2|x)}{\pi_{ref}(y_2|x)},\tag{13}
u(x,y1,y2)=βlogπref(y1∣x)πθ(y1∣x)−βlogπref(y2∣x)πθ(y2∣x),(13)
并且
δ
(
x
,
y
1
,
y
2
)
δ(x, y_1, y_2)
δ(x,y1,y2) 表示两对
(
x
,
y
1
)
(x, y_1)
(x,y1) 和 (x, y_2) 之间的连续前向 KL 散度差,以
β
β
β 加权,表示为:
δ
(
x
,
y
1
,
y
2
)
=
β
D
S
e
q
K
L
(
x
,
y
2
;
π
r
e
f
∣
∣
π
θ
)
−
β
D
S
e
q
K
L
(
x
,
y
1
;
π
r
e
f
∣
∣
π
θ
)
.
(14)
δ(x,y_1,y_2)=\beta D_{SeqKL}(x,y_2;\pi_{ref}||\pi_{\theta})-\beta D_{SeqKL}(x,y_1;\pi_{ref}||\pi_{\theta}). \tag{14}
δ(x,y1,y2)=βDSeqKL(x,y2;πref∣∣πθ)−βDSeqKL(x,y1;πref∣∣πθ).(14)
证明见附录A.4。
4.4 Loss Function and Formal Analysis
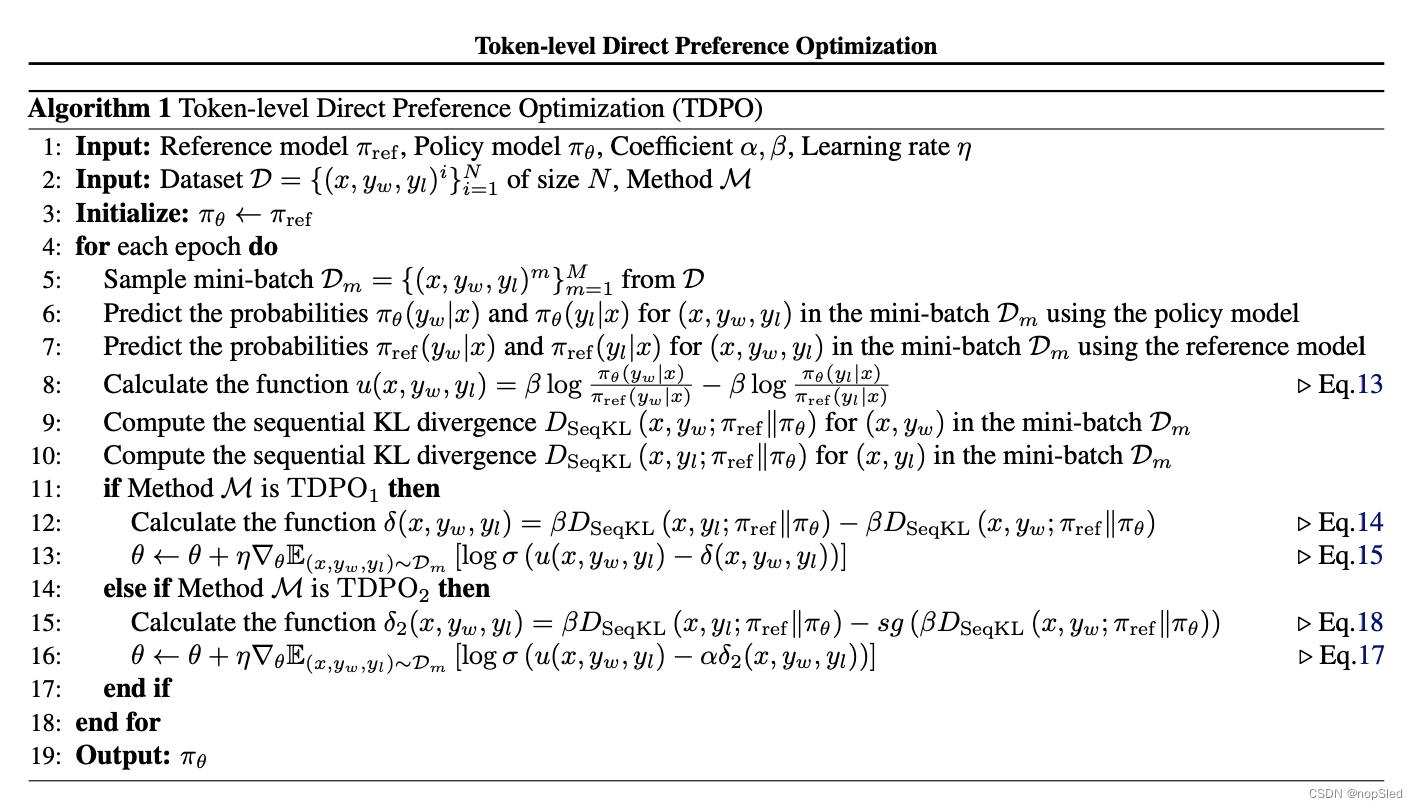
基于公式 12,我们将 Bradley-Terry 模型重新表述为仅与策略相关的结构。这使我们能够为参数化策略
π
θ
π_θ
πθ 制定似然最大化目标,从而推导出我们方法初始版本的损失函数
T
D
P
O
1
TDPO_1
TDPO1:
L
T
D
P
O
1
(
π
θ
′
π
r
e
f
)
=
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
l
o
g
σ
(
u
(
x
,
y
w
,
y
l
)
−
δ
(
x
,
y
w
,
y
l
)
)
]
.
(15)
\mathcal L_{TDPO_1}(\pi_{\theta}'\pi_{ref})=-\mathbb E_{(x,y_w,y_l)\sim\mathcal D}[log~\sigma(u(x,y_w,y_l)-δ(x,y_w,y_l))].\tag{15}
LTDPO1(πθ′πref)=−E(x,yw,yl)∼D[log σ(u(x,yw,yl)−δ(x,yw,yl))].(15)
通过这种方法,我们显式地将顺序前向 KL 散度引入损失函数。再加上隐式集成的反向 KL 散度,我们增强了平衡 LLM 对齐性能和生成多样性的能力。
随后,我们对该方法进行导数分析,并对 TDPO 的损失函数进行具体修改。为方便起见,我们使用
u
u
u 表示
u
(
x
,
y
w
,
y
l
)
u(x, y_w, y_l)
u(x,yw,yl),使用
δ
δ
δ 表示
δ
(
x
,
y
w
,
y
l
)
δ(x, y_w, y_l)
δ(x,yw,yl)。利用公式 15 中给出的损失函数公式,我们计算损失函数关于参数
θ
θ
θ 的梯度:
∇
θ
L
T
D
P
O
1
(
π
θ
;
π
r
e
f
)
=
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
σ
(
−
u
+
δ
)
[
∇
θ
u
−
∇
θ
δ
]
]
.
(16)
\nabla_{\theta}\mathcal L_{TDPO_1}(\pi_{\theta};\pi_{ref})=-\mathbb E_{(x,y_w,y_l)\sim\mathcal D}[\sigma(-u+δ)[\nabla_{\theta}u-\nabla_{\theta}δ]].\tag{16}
∇θLTDPO1(πθ;πref)=−E(x,yw,yl)∼D[σ(−u+δ)[∇θu−∇θδ]].(16)
在等式 16 中,
σ
(
−
u
+
δ
)
σ(-u + δ)
σ(−u+δ) 是梯度的权重因子。第一部分
(
−
u
)
(-u)
(−u) 对应于 DPO 损失函数中的权重因子。当语言模型在预测人类偏好时出错时,即
l
o
g
π
θ
(
y
l
∣
x
)
π
r
e
f
(
y
l
∣
x
)
>
l
o
g
π
θ
(
y
w
∣
x
)
π
r
e
f
(
y
w
∣
x
)
log \frac{π_θ(y_l|x)}{π_{ref} (y_l|x)} > log\frac{π_θ(y_w|x)}{π_{ref} (y_w|x)}
logπref(yl∣x)πθ(yl∣x)>logπref(yw∣x)πθ(yw∣x),
(
−
u
)
(-u)
(−u) 的值将变得更大,对响应对
(
y
w
,
y
l
)
(y_w, y_l)
(yw,yl) 应用更强的更新。而第二部分
δ
δ
δ 是我们方法的一个独特组成部分。如图 1 所示,非偏好响应子集的 KL 散度增长率快于偏好响应子集。随着差异的增加,相应的
δ
δ
δ 值上升,从而放大权重因子
σ
(
−
u
+
δ
)
σ(-u + δ)
σ(−u+δ)。结合后续的梯度项,我们的目标函数可以有效抑制 KL 散度差异较大的响应对之间的 KL 散度差异。我们的方法通过权重因子
δ
δ
δ和梯度项
(
−
∇
θ
δ
)
(−∇_θδ)
(−∇θδ) 的协同影响,达到了自动控制KL散度平衡的目的。
等式16中的损失函数梯度也由两个分量组成,
∇
θ
u
∇_θu
∇θu 和
(
−
∇
θ
δ
)
(−∇_θδ)
(−∇θδ)。
∇
θ
u
∇_θu
∇θu 表示DPO中梯度的优化方向。直观上看,
∇
θ
u
∇_θu
∇θu 增加了优选补全
y
w
y_w
yw的似然,降低了非优选补全
y
l
y_l
yl的似然。而
(
−
∇
θ
δ
)
(−∇_θδ)
(−∇θδ) 倾向于缩小
D
S
e
q
K
L
(
x
,
y
w
;
π
r
e
f
∥
π
θ
)
D_{SeqKL}(x,y_w;π_{ref}∥π_θ)
DSeqKL(x,yw;πref∥πθ) 和
D
S
e
q
K
L
(
x
,
y
l
;
π
r
e
f
∥
π
θ
)
D_{SeqKL}(x,y_l;π_{ref}∥π_θ)
DSeqKL(x,yl;πref∥πθ) 之间的差距。
然而,如果单独考虑,损失函数中
D
S
e
q
K
L
(
x
,
y
w
;
π
r
e
f
∣
π
θ
)
D_{SeqKL}(x, y_w; π_{ref}|π_θ)
DSeqKL(x,yw;πref∣πθ) 的梯度在优化过程中往往会增加
(
x
,
y
w
)
(x, y_w)
(x,yw) 在
π
r
e
f
π_{ref}
πref 和
π
θ
π_θ
πθ 之间的连续 KL 散度。这是因为损失函数中的连续前向 KL 散度是通过状态价值函数
V
π
V_π
Vπ 引入的,固有地在每个 token 上引入了一个期望
E
z
∼
π
r
e
f
[
l
o
g
π
θ
(
z
∣
[
x
,
y
<
t
]
)
π
r
e
f
(
z
∣
[
x
,
y
<
t
]
)
]
\mathbb E_{z∼π_{ref}}[log\frac{π_θ(z|[x,y^{<t}])}{π_{ref} (z|[x,y^{<t}])}]
Ez∼πref[logπref(z∣[x,y<t])πθ(z∣[x,y<t])] 作为基线。这个期望的负值恰好对应于一个前向 KL 散度
D
K
L
(
π
r
e
f
(
⋅
∣
[
x
,
y
<
t
]
)
∣
π
θ
(
⋅
∣
[
x
,
y
<
t
]
)
)
D_{KL} (π_{ref}(·|[x, y^{<t}])|π_θ(·|[x, y^{<t}]))
DKL(πref(⋅∣[x,y<t])∣πθ(⋅∣[x,y<t])),它可以用来约束 KL 散度的不均衡增长。对于提示
x
x
x 和首选响应
y
w
y_w
yw,在每个 token 上,等式 16 中的损失函数倾向于增加
l
o
g
π
(
y
w
t
∣
[
x
,
y
w
<
t
]
)
π
r
e
f
(
y
w
t
∣
[
x
,
y
w
<
t
]
)
log\frac{π(y^t_w|[x,y^{<t}_w ])}{π_{ref} (y^t_w|[x,y^{<t}_w])}
logπref(ywt∣[x,yw<t])π(ywt∣[x,yw<t]) 的似然,同时降低期望,扩大指定项
y
w
t
y^t_w
ywt 与基线之间的差距以加快训练。降低期望的影响是每个 token 的前向 KL 散度
D
K
L
(
π
r
e
f
(
⋅
∣
[
x
,
y
w
<
t
]
)
∣
π
θ
(
⋅
∣
[
x
,
y
w
<
t
]
)
)
D_{KL}(π_{ref}(·|[x, y^{<t}_w ])|π_θ(·|[x, y^{<t}_w ]))
DKL(πref(⋅∣[x,yw<t])∣πθ(⋅∣[x,yw<t])) 增加,从而导致
D
S
e
q
K
L
(
x
,
y
w
;
π
r
e
f
∣
π
θ
)
D_{SeqKL} (x, y_w; π_{ref}|π_θ)
DSeqKL(x,yw;πref∣πθ) 增加。由于我们的目标不是加快训练速度而是确保训练稳定性,我们通过停止
D
S
e
q
K
L
(
x
,
y
w
;
π
r
e
f
∣
π
θ
)
D_{SeqKL} (x, y_w; π_{ref}|π_θ)
DSeqKL(x,yw;πref∣πθ) 的梯度传播并将其视为
D
S
e
q
K
L
(
x
,
y
l
;
π
r
e
f
∣
π
θ
)
D_{SeqKL} (x, y_l; π_{ref}|π_θ)
DSeqKL(x,yl;πref∣πθ) 对齐的基线项来修改损失函数。
与
D
S
e
q
K
L
(
x
,
y
w
;
π
r
e
f
∣
π
θ
)
D_{SeqKL}(x, y_w; π_{ref}|π_θ)
DSeqKL(x,yw;πref∣πθ) 不同,
D
S
e
q
K
L
(
x
,
y
l
;
π
r
e
f
∣
π
θ
)
D_{SeqKL}(x, y_l; π_{ref}|π_θ)
DSeqKL(x,yl;πref∣πθ) 的梯度倾向于减少
(
x
,
y
l
)
(x, y_l)
(x,yl) 处
π
r
e
f
π_{ref}
πref 和
π
θ
π_θ
πθ 之间的连续 KL 散度。对于提示
x
x
x 和被拒绝的响应
y
l
y_l
yl,等式 16 中的损失函数倾向于降低每个 token 处
l
o
g
π
(
y
l
t
∣
[
x
,
y
l
<
t
]
)
π
r
e
f
(
y
l
t
∣
[
x
,
y
l
<
t
]
)
log\frac{π(y^t_l|[x,y^{<t}_l])}{π_{ref}(y^t_l|[x,y^{<t}_l])}
logπref(ylt∣[x,yl<t])π(ylt∣[x,yl<t]) 的似然,同时增加期望
E
z
∼
π
r
e
f
[
l
o
g
π
θ
(
z
[
x
,
y
l
<
t
]
)
π
r
e
f
(
z
∣
[
x
,
y
l
<
t
]
)
E_{z∼π_{ref}}[log\frac{π_θ(z[x,y^{<t}_l])}{π_{ref}(z|[x,y^{<t}_l])}
Ez∼πref[logπref(z∣[x,yl<t])πθ(z[x,yl<t])。期望的增加意味着该 token 处的前向 KL 散度更小,从而起到限制连续前向 KL 散度增长率的作用。因此,对于这一项,我们选择保留其梯度更新。
综上所述,我们只在
(
−
∇
θ
δ
)
(−∇_θδ)
(−∇θδ) 中传播
D
S
e
q
K
L
(
x
,
y
l
;
π
r
e
f
∣
π
θ
)
D_{SeqKL}(x, y_l; π_{ref}|π_θ)
DSeqKL(x,yl;πref∣πθ) 的梯度,当第二部分权重因子
δ
δ
δ变大时,对
D
S
e
q
K
L
(
x
,
y
l
;
π
r
e
f
∣
∣
π
θ
)
D_{SeqKL}(x, y_l; π_{ref}||π_θ)
DSeqKL(x,yl;πref∣∣πθ) 施加更强的抑制,以控制KL散度的平衡。
此外,为了在 TDPO 中实现对齐性能和生成多样性之间的更好平衡,我们在损失函数中引入了一个附加参数
α
α
α,通过调整
α
α
α 的大小可以控制
D
S
e
q
K
L
(
x
,
y
w
;
π
r
e
f
∣
∣
π
θ
)
D_{SeqKL} (x, y_w; π_{ref}||π_θ)
DSeqKL(x,yw;πref∣∣πθ) 和
D
S
e
q
K
L
(
x
,
y
l
;
π
r
e
f
∣
∣
π
θ
)
D_{SeqKL} (x, y_l; π_{ref}||π_θ)
DSeqKL(x,yl;πref∣∣πθ) 之间的偏差。
利用参数
β
β
β 来调节语言模型与基础参考模型的偏差,以及利用
α
α
α 来控制语言模型中顺序 KL 散度的平衡,我们的方法实现了与人类偏好的出色一致性,同时有效地保留了模型生成的多样性。我们在算法 1 中提供了伪代码,并在附录 B 中提供了 TDPO 损失的 Pytorch 实现版本。

5.Experiments


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









