






摘要
最近,大型语言模型 (LLM) 因其在广泛任务中的出色表现而备受关注,尤其是在文本分析方面。然而,金融行业面临着独特的挑战,因为它依赖时间序列数据来完成复杂的预测任务。在本研究中,我们引入了一个名为 LLMFactor 的新框架,该框架采用序列知识引导的提示 (Sequential Knowledge-Guided Prompting, SKGP) 来使用 LLM 识别影响股票走势的因素。与以前依赖关键短语或情绪分析的方法不同,这种方法侧重于提取与股市动态更直接相关的因素,为复杂的时间变化提供清晰的解释。我们的框架指导 LLM 通过填空策略创建背景知识,然后从相关新闻中辨别影响股价的潜在因子。在背景知识和已识别因子的指导下,我们利用文本格式的历史股价来预测股价走势。对来自美国和中国股票市场的四个基准数据集的 LLMFactor 框架进行的广泛评估证明了其优于现有的最先进方法以及在金融时间序列预测中的有效性。
1.介绍

人工智能 (AI) 已成为金融领域的重要应用,可解决各种挑战,例如预测股票走势、提供机器人咨询服务和管理风险。在这些任务中,预测股票趋势尤为重要,因为它可以利用历史数据来制定交易策略并确定买入或卖出股票的机会。
尤金·法玛提出的有效市场假说 (EMH) 认为,股票价格反映了所有可用信息,因此很难预测未来的价格走势。然而,后续研究发现了市场效率的局限性,强调了信息不对称和非理性行为等现象如何导致偏离完美效率。这些观察为研究人员通过识别和利用市场低效率来寻求超额市场回报铺平了道路。
在此基础上,人们越来越有兴趣探索各种数据类型以增强预测能力。一些研究强调了与股票相关的新闻在揭示基本市场见解方面的重要性,而另一些研究则强调了了解公司和行业之间相互联系的重要性。最近的研究通过实证证明了公众情绪对市场趋势的影响,并努力从新闻和社交媒体数据中提取情绪和关键短语。
然而,如图 1 所示,这些方法遇到了各种限制。我们提出了一项新任务,通过使用“因子”来增强股票走势预测。图 1 描述了关键短语、情感词和 LLM 生成的因子之间的区别。对于给定的股票相关新闻,关键短语可能概述了内容,但与股价没有直接关联。相反,情绪与股价相关,但缺乏人类解释的清晰度。因此,因子在三个方面具有优势:新闻可解释性、人类可读性和股价可解释性。
为了将因子纳入财务预测,我们引入了一个新的框架 LLMFactor,它通过序列知识引导提示 (SKGP) 从 LLM 中获取因子,然后解释股价趋势。LLMFactor 代表了一种将 LLM 集成到金融应用中的整体方法。最初,我们提出的 SKGP 策略提示 LLM 生成与股票相关的因子。SKGP 从填空策略开始,以引出与股票相关的背景知识(例如公司关系)。随后,我们提示 LLM 从新闻文章中识别可靠的因子。最后,我们用这些因子和知识编译文本格式的时间序列数据来预测股价趋势。在四个数据集上的实验表明,LLMFactor 产生了卓越的预测结果,并可以解释这些预测背后的原理。此外,获得的因子有助于以人类可访问和可理解的格式动态呈现随时间变化的市场变化。
本研究的主要贡献总结如下:
- New Task - Factor Extraction:我们引入了一项新任务——因子提取,旨在从文本数据中提取重要因子,以帮助预测时间序列数据。这项任务在三个关键领域超越了传统的基于关键词和基于情绪的方法:新闻内容的可解释性、人类的可读性以及解释股价走势的能力。
- New Strategy - SKGP:我们提出了序列知识引导提示 (SKGP) 作为利用背景知识预测股票走势的创新策略。与基本提示方法不同,SKGP 采用填空方法,利用最少的背景知识来增强提示模板的丰富性。
- New Framework - LLMFactor:本研究开发的 LLMFactor 框架利用 LLM 衍生的因子来阐明动态时间变化。该框架已被证明是金融应用中的宝贵工具,可深入了解市场趋势并促进因子分析。
2.Related Work
2.1 Stock Movement Prediction using Textual Data
随着自然语言处理 (NLP) 技术的进步,许多研究人员利用文本数据来预测股市趋势。(Xu and Cohen, 2018) 使用推文和历史价格根据股票数据进行时间相关的预测。(Luo et al., 2023) 模拟金融文本数据和因果关系增强的股票相关性之间的多模态性。这些努力旨在开发复杂的模型来提高预测准确性并将文本数据作为一个整体来考虑。
此外,某些研究专注于从文本数据中提取更细粒度的见解。(Zhou et al., 2021) 将公司事件确定为股票走势背后的驱动力,而 (Wan et al., 2021) 则证明了强劲的媒体情绪与市场回报之间存在显着关联。(Wang et al., 2020) 通过纳入从各种来源汇总的专家意见来增强股票走势预测。这些见解为理解市场动态提供了更清晰的思路。
2.2 Time-series Forecasting with LLMs
LLM(例如 Generative Pretrained Transformer 的变体)由广泛而多样的数据集构建而成,大大丰富了其广泛的知识库。然而,它们的基础结构基于 Transformer 架构,本质上并非为分析时间序列数据而设计。这一限制引起了学者们对探索定制 LLM 以实现高效的时间序列预测的方法的兴趣。
(Xue and Salim, 2023) 提出了一种基于提示的方法,将数字输入和输出转换为文本提示,将预测任务定义为句子到句子的转换。这种方法允许将语言模型直接应用于预测任务。对于金融时间序列预测,(Yu et al., 2023) 使用提示从 LLM 生成摘要和关键短语,结合多种数据源来增强时间序列预测。他们的方法为股市趋势提供了宝贵的见解。然而,他们的提示包含过多的信息,导致 LLM 的响应相对缺乏细节。
2.3 Prompt Engineering
提示工程使 LLM 能够通过精心设计的提示有效地解决各种任务。然而,确定每个特定任务的最佳提示是一项挑战。这一挑战导致了对各种提示策略的探索。例如,(Wei et al., 2022) i 引入了一种思维链 (CoT) 方法,该方法涉及一系列中间推理步骤,以增强 LLM 在复杂推理任务中的能力。同时,(Liu et al., 2022) 提出了一种生成知识提示技术,该技术涉及通过语言模型生成知识,然后将这些生成的知识用作回答问题的补充输入。另一种流行的技术称为检索增强生成 (RAG),它通过检索-增强-生成流程将外部知识整合到 LLM 中。受这些技术的启发,我们提出了一种新的序列知识引导提示,旨在提高财务预测的准确性。
3.LLMFactor
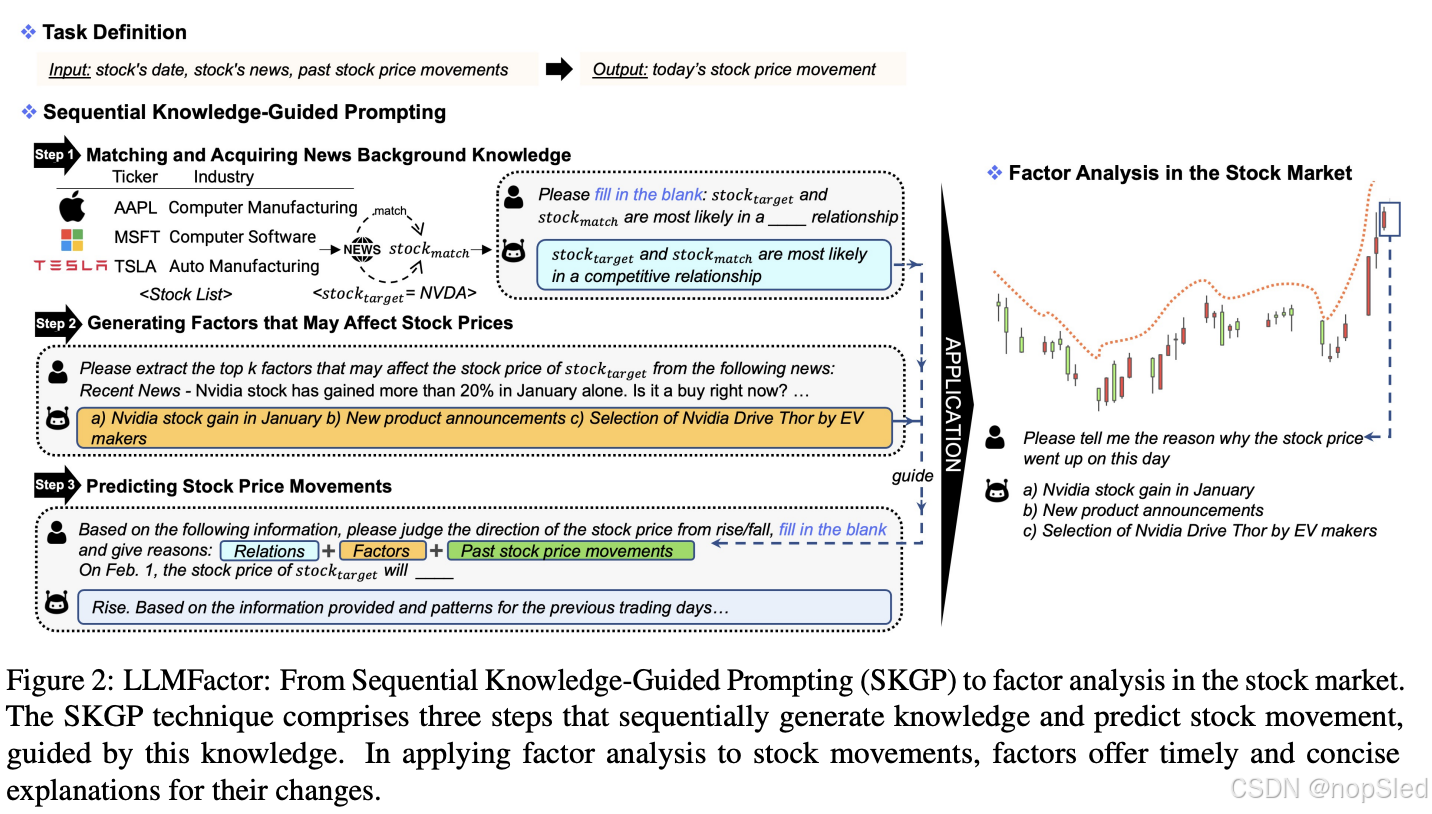
提出的 LLMFactor 是一个预测和解释股票市场趋势的综合框架,如图 2 所示。
3.1 Task Definition
对于给定的股票(表示为 s t o c k t a r g e t stock_{target} stocktarget),我们考虑在目标预测日期 d a t e t a r g e t date_{target} datetarget 上发布的相关新闻(称为 n e w s t a r g e t news_{target} newstarget)及其历史股价序列 P = { P 1 , P 2 , . . . , P t } P = \{P_1, P_2, ..., P_t\} P={P1,P2,...,Pt},其中 t t t 表示窗口大小。预测股票走势的任务被表述为二分类问题,其中股票价格序列被转换为一系列股票走势, P ^ = { P ^ 1 , P ^ 2 , . . . , P ^ t } \hat P = \{\hat P_1, \hat P_2, ..., \hat P_t\} P^={P^1,P^2,...,P^t}。在这个系列中, P ^ i = 1 \hat P_i = 1 P^i=1 表示股价从 P i − 1 P_{i-1} Pi−1 上涨到 P i P_i Pi,而 P ^ i = 0 \hat P_i = 0 P^i=0 表示下跌。我们的目标是根据 d a t e t a r g e t date_{target} datetarget、 n e w s t a r g e t news_{target} newstarget 和 P ^ \hat P P^ 预测 P ^ t + 1 \hat P_{t+1} P^t+1。
3.2 Sequential Knowledge-Guided Prompting
3.2.1 Matching and Acquiring News Background Knowledge
我们的方法的基础是序列知识引导提示 (SKGP) 策略,该策略包括三个主要阶段。以 Nvidia (NVDA) 为例,初始阶段涉及将股票与相关新闻进行匹配并获取背景知识。
令
S
=
{
(
C
i
,
T
i
,
I
i
)
∣
i
∈
N
,
i
≤
n
}
S = \{(C_i, T_i, I_i) | i ∈ \mathbb N, i ≤ n\}
S={(Ci,Ti,Ii)∣i∈N,i≤n} 为股票列表,其中每个元组
(
C
i
,
T
i
,
I
i
)
(C_i, T_i, I_i)
(Ci,Ti,Ii) 由公司
C
i
C_i
Ci、股票代码
T
i
T_i
Ti 和行业
I
i
I_i
Ii 组成。这些元组从纽约证券交易所和纳斯达克交易所收集,
n
n
n 为正整数,表示此类元组的总数。我们将
S
S
S 与
n
e
w
s
t
a
r
g
e
t
news_{target}
newstarget 匹配得到
s
t
o
c
k
m
a
t
c
h
=
{
S
∩
n
e
w
s
t
a
r
g
e
t
}
stock_{match} = \{S ∩ news_{target}\}
stockmatch={S∩newstarget}。随后,我们提示 LLM 获得
s
t
o
c
k
t
a
r
g
e
t
stock_{target}
stocktarget 和
s
t
o
c
k
m
a
t
c
h
stock_{match}
stockmatch 之间的关系。提示方法定义为
L
L
M
:
S
t
r
i
n
g
→
S
t
r
i
n
g
LLM: String → String
LLM:String→String,其中输入是 RelationTemplate “Please fill in the blank:
s
t
o
c
k
t
a
r
g
e
t
stock_{target}
stocktarget and
s
t
o
c
k
m
a
t
c
h
stock_{match}
stockmatch are most likely in a ___ relationship”,输出是关系的类型,表示为
r
e
l
a
t
i
o
n
relation
relation。
这种获取有关
n
e
w
s
t
a
r
g
e
t
news_{target}
newstarget 背景知识的方法大大提高了我们对新闻内容的理解。例如,如果
s
t
o
c
k
t
a
r
g
e
t
stock_{target}
stocktarget 和
s
t
o
c
k
m
a
t
c
h
stock_{match}
stockmatch 被确定为竞争对手,那么有关
s
t
o
c
k
m
a
t
c
h
stock_{match}
stockmatch 的信息可能会对 KaTeX parse error: Expected '}', got 'EOF' at end of input: stock_{target 产生负面影响。此外,许多研究强调了公司关系在预测股市走势方面的关键作用。因此,我们的填空技术旨在限制响应格式,促进直接和明确地识别关系。
3.2.2 Generating Factors that May Affect Stock Prices
SKGP 的下一步是从
n
e
w
s
t
a
r
g
e
t
news_{target}
newstarget 生成因子。这些因子的重要性有三点:1) 它们与股票走势的关联性比关键短语、情绪、新闻摘要或整篇新闻文章更密切,因此更有可能预测出有利的市场趋势。2) 与从其他来源获得的因子相比,从新闻文本中得出的因子可以更直接、更详细地洞察股价波动。3) 它们提高了股价趋势的可解释性以及 LLM 预测背后的原理。
为了生成可靠的因子,我们提示 LLM 分析新闻内容并识别可能影响股价的因子。这种方法充分利用了 LLM 的内在知识。考虑到我们旨在为给定的
s
t
o
c
k
t
a
r
g
e
t
stock_{target}
stocktarget 和
n
e
w
s
t
a
r
g
e
t
news_{target}
newstarget 提取 top-k 个因子,提示方法描述为
L
L
M
(
F
a
c
t
o
r
T
e
m
p
l
a
t
e
)
=
f
a
c
t
o
r
LLM(FactorTemplate) = factor
LLM(FactorTemplate)=factor,其中 FactorTemplate 是一个结构化的句子:“Please extract the top k factors that may affect the stock price of
s
t
o
c
k
t
a
r
g
e
t
stock_{targe}t
stocktarget from the following news”,后面是
n
e
w
s
t
a
r
g
e
t
news_{target}
newstarget,输出是 LLM 生成的因子。LLM 生成的因子不仅限于新闻中的单词;相反,LLM 会考虑新闻的内容及其对股票走势的潜在影响,通常会总结内容中的重要元素。例如,图 2 中提到的因子“Nvidia stock gain in January”表明该事件是 Nvidia 过去的股票表现,影响是收益,这可能会对 Nvidia 未来的股价产生积极影响。
3.2.3 Predicting Stock Price Movements
为了预测股票走势,我们整合了新闻背景知识和因子来指导 LLM。同时,我们将时间序列数据转换为 LLM 可以理解的文本格式。在股票走势序列
P
^
=
{
P
^
1
,
P
^
2
,
.
.
.
,
P
^
t
}
\hat P=\{\hat P_1, \hat P_2, ..., \hat P_t\}
P^={P^1,P^2,...,P^t} 中,我们引入一个函数,其中
f
(
P
^
i
=
0
)
f(\hat P_i=0)
f(P^i=0) 被赋予值“下跌”,
f
(
P
^
i
=
1
)
f(\hat P_i=1)
f(P^i=1) 被赋予值“上涨”,从而将
P
^
\hat P
P^ 转换为一系列结果
T
e
x
t
M
o
v
e
m
e
n
t
=
{
f
(
P
^
i
)
∣
i
∈
{
1
,
2
,
.
.
.
,
t
}
,
f
(
P
^
i
)
=
"
f
e
l
l
"
i
f
P
^
i
=
0
a
n
d
"
r
o
s
e
"
i
f
P
^
i
=
1
)
}
TextMovement = \{f(\hat P_i) | i ∈ \{1, 2, . . ., t\}, f(\hat P_i)="fell"~if~\hat P_i=0~and~"rose"~if~\hat P_i=1)\}
TextMovement={f(P^i)∣i∈{1,2,...,t},f(P^i)="fell" if P^i=0 and "rose" if P^i=1)}。给定文本股票走势序列 TextMovement 及其日期序列
d
a
t
e
=
{
d
a
t
e
1
,
d
a
t
e
2
,
.
.
.
,
d
a
t
e
t
}
date =\{date_1, date_2, ..., date_t\}
date={date1,date2,...,datet},过去的股票价格走势被转换为
T
i
m
e
T
e
m
p
l
a
t
e
TimeTemplate
TimeTemplate,结构为“On
d
a
t
e
i
date_i
datei, the stock price of
s
t
o
c
k
t
a
r
g
e
t
stock_{target}
stocktarget
f
(
P
^
i
)
f(\hat P_i)
f(P^i).””。
随后,我们构建一个
P
r
i
c
e
T
e
m
p
l
a
t
e
PriceTemplate
PriceTemplate,其中包含一个初始指令,“Based on the following information, please judge the direction of the stock price as rise or fall, fill in the blank and give reasons”,然后是结论指令,“On
d
a
t
e
i
date_i
datei, the stock price of
s
t
o
c
k
t
a
r
g
e
t
stock_{target}
stocktarget will ___.”。通过整合关系、因子、
T
i
m
e
T
e
m
p
l
a
t
e
TimeTemplate
TimeTemplate和
P
r
i
c
e
T
e
m
p
l
a
t
e
PriceTemplate
PriceTemplate,我们将提示方法表达为
L
L
M
(
r
e
l
a
t
i
o
n
,
f
a
c
t
o
r
,
T
i
m
e
T
e
m
p
l
a
t
e
,
P
r
i
c
e
T
e
m
p
l
a
t
e
)
=
p
r
e
d
i
c
t
i
o
n
LLM(relation, factor, TimeTemplate, PriceTemplate) = prediction
LLM(relation,factor,TimeTemplate,PriceTemplate)=prediction。预测结果指定股票价格是“上涨”还是“下跌”,以及这种推断的理由。有关模板的更多详细信息,请参阅附录 A。
3.3 Factor Analysis in the Stock Market
SKGP 提供了一种预测股票走势的强大技术,从 SKGP 得出的因子为股市趋势提供了更多见解。例如,如图 2 所示,因子分析可以应用于股市。以 Nvidia 的股价趋势为例,在过去五天持续上涨之后,用蓝色框突出显示的一天也呈现上升趋势。为了解释这一现象,我们的 LLMFactor 确定了一组简明的因子,例如“Nvidia 股价在 1 月份上涨、新产品发布以及电动汽车制造商选择 Nvidia Drive Thor”。
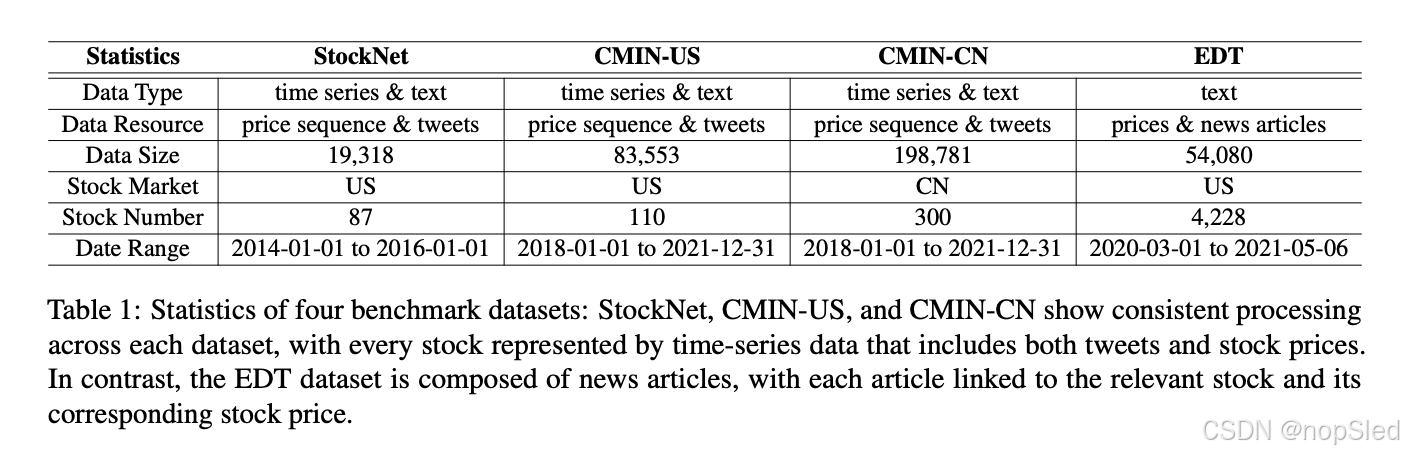
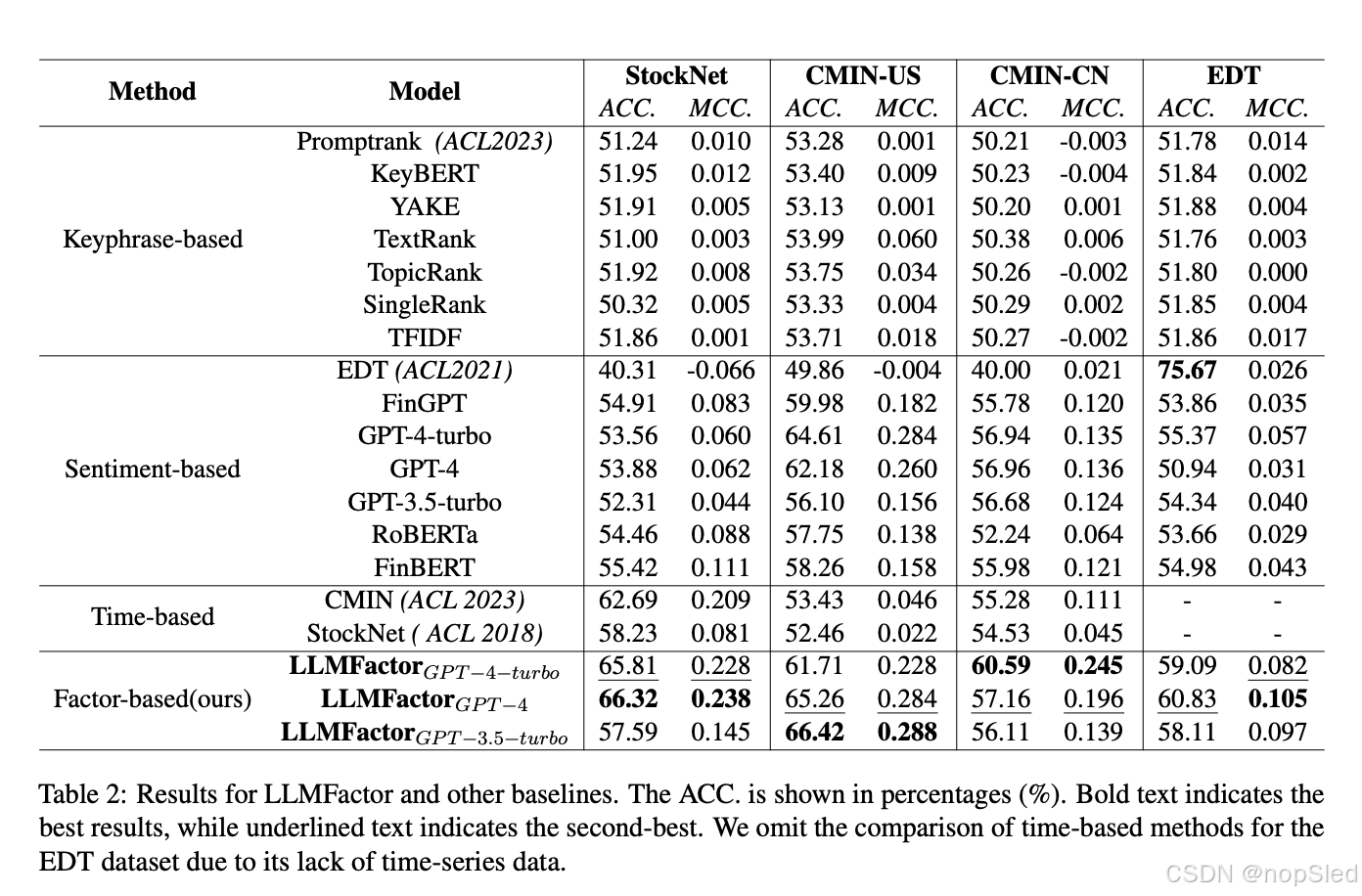
4.Experiments


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









